Recognition: unknown
Doing More With Less: Revisiting the Effectiveness of LLM Pruning for Test-Time Scaling
Pith reviewed 2026-05-07 16:45 UTC · model grok-4.3
The pith
Unstructured pruning can enhance test-time scaling performance in reasoning LLMs and sometimes surpass the original full models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
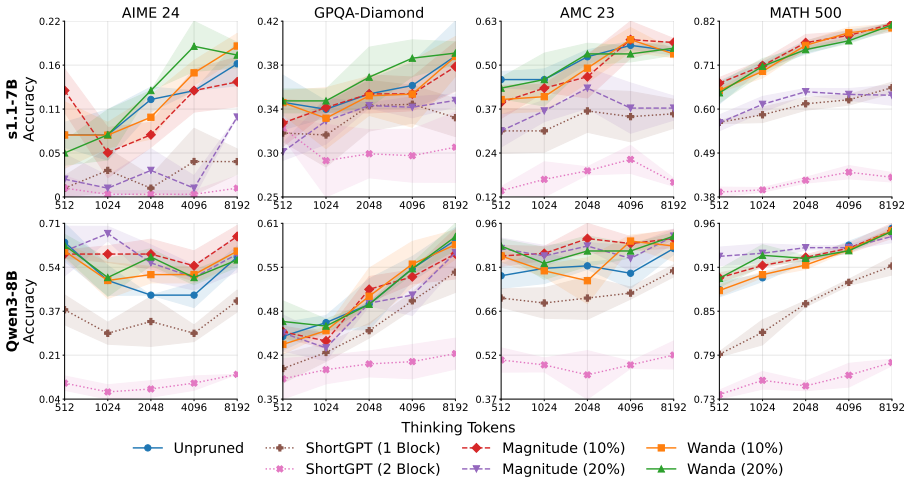
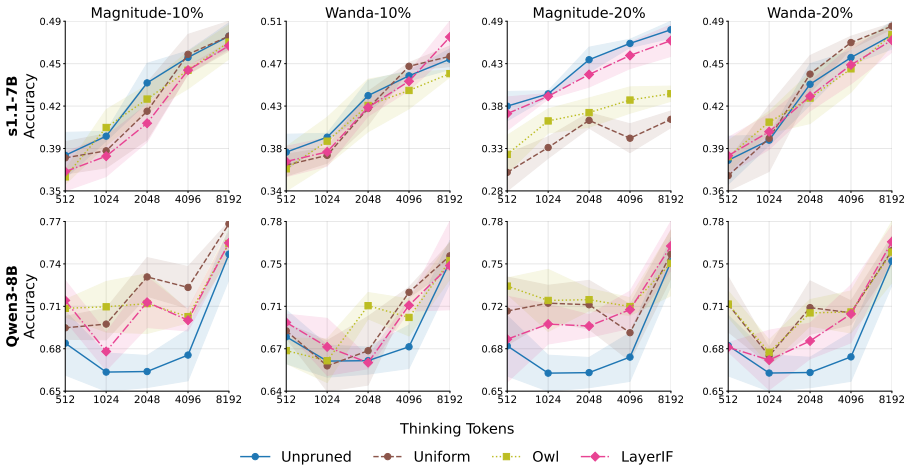
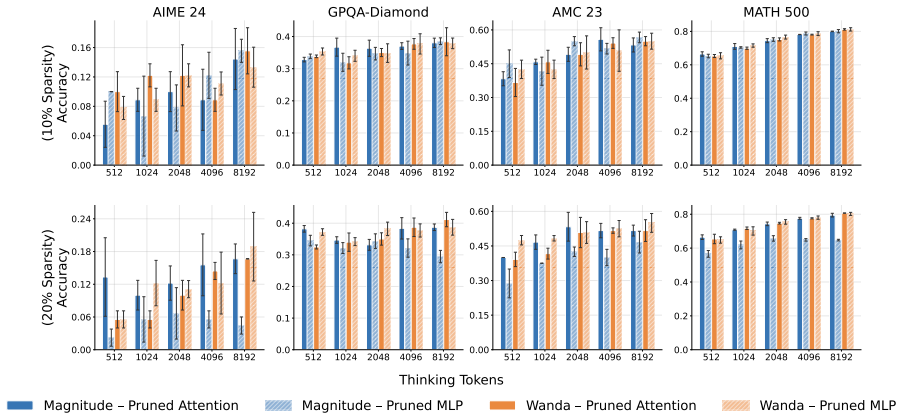
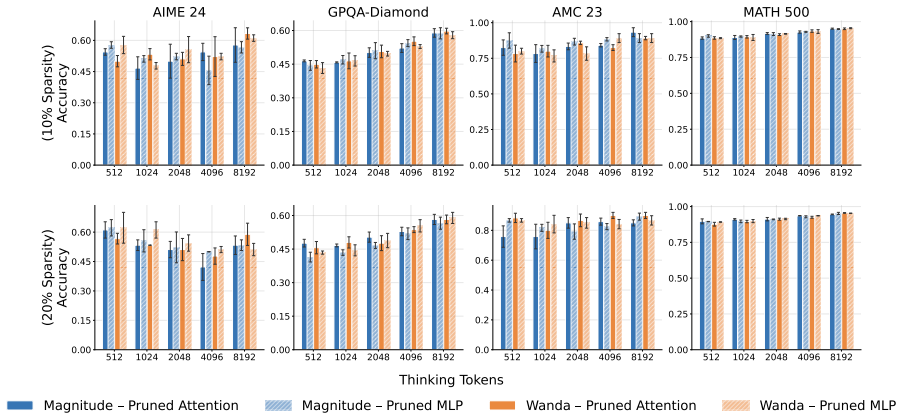
Extensive experiments on s1.1-7B and Qwen3-8B models across four reasoning benchmarks demonstrate that unstructured pruning improves test-time scaling performance compared to structured pruning and, in some cases, exceeds the performance of the unpruned full-weight models. Different layer-wise sparsity allocation strategies are also evaluated as key choices in applying unstructured pruning.
What carries the argument
Unstructured pruning, which removes only certain redundant or detrimental individual weights from the model rather than entire layer blocks, applied to reasoning LLMs to study its effect on test-time compute scaling.
If this is right
- Unstructured pruning can be used to create smaller models that achieve better reasoning with additional test-time compute.
- Layer-wise sparsity allocation plays a critical role in realizing performance gains from unstructured pruning.
- Prior conclusions about pruning degrading TTS may not hold when using unstructured methods instead of structured ones.
- Carefully pruned models may offer a better efficiency-performance trade-off for deployment in reasoning applications.
Where Pith is reading between the lines
- This finding suggests that some weights in current reasoning LLMs may actually hinder optimal performance under high test-time compute budgets.
- If generalizable, pruning strategies could be routinely applied during model preparation to boost inference-time reasoning without increasing model size.
- Future experiments could test whether combining this pruning with other techniques like quantization yields further gains.
- Neighbouring problems in model compression might benefit from similar distinctions between pruning types.
Load-bearing premise
The specific implementations of unstructured pruning and the chosen layer-wise sparsity strategies do not introduce biases that only work for the tested models and benchmarks.
What would settle it
A new experiment showing that on additional reasoning benchmarks or with other LLMs, the unstructured pruned versions perform worse than the full model on test-time scaling metrics would disprove the central claim.
Figures

read the original abstract
While current Large Language Models (LLMs) exhibit remarkable reasoning capabilities through test-time compute scaling (TTS), their massive parameter counts and high inference costs have motivated the development of pruning methods that can reduce model size without sacrificing performance. However, specific to reasoning LLMs, prior work has shown that structured pruning (methods which removes entire set of layer blocks), significantly degrades TTS reasoning performance. In this work, we revisit this assumption and instead investigate whether unstructured pruning (methods that carefully remove only certain redundant/detrimental weights) exhibits similar limitations. Surprisingly, our extensive experiments across four reasoning benchmarks on two reasoning LLMs: s1.1-7B and Qwen3-8B, consistently show that unstructured pruning augments TTS performance compared to structured pruning, and at times can even outperform the unpruned full-weight LLMs. Furthermore, we also empirically study the impact of different layer-wise sparsity allocation strategies, which are an important parametric choice for instantiating unstructured pruning methods. These findings challenge the conventional notion that pruning always reduces TTS performance and in fact, suggest that carefully undertaken pruning can improve TTS effectiveness even further.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that unstructured pruning of reasoning LLMs (s1.1-7B and Qwen3-8B) augments test-time scaling (TTS) performance on four reasoning benchmarks relative to structured pruning and, in some cases, outperforms the dense unpruned baseline. It further examines the effects of different layer-wise sparsity allocation strategies as a key design choice for unstructured pruning.
Significance. If the central experimental findings hold after addressing methodological details, the work would meaningfully revise the current understanding that pruning necessarily harms TTS reasoning performance. It could support more efficient inference pipelines for reasoning models by demonstrating that carefully chosen unstructured pruning can simultaneously reduce parameters and improve scaling behavior, with direct relevance to deployment under compute constraints.
major comments (2)
- [Abstract] Abstract: the statement that unstructured pruning 'consistently show[s] that [it] augments TTS performance' and 'at times can even outperform' the full model is presented without any mention of statistical significance testing, error bars, variance across runs, or controls for confounds such as random seeds and hyperparameter sensitivity, which are required to substantiate the reliability of the reported gains.
- [Experimental setup] Experimental setup (layer-wise sparsity allocation): the paper studies multiple layer-wise sparsity allocation strategies but provides no indication that these allocations were fixed a priori or validated on held-out data rather than selected or swept on the same four benchmarks used for final reporting; if the latter occurred, the observed advantage of unstructured over structured pruning could be an artifact of hyperparameter selection bias rather than an intrinsic property.
minor comments (2)
- [Abstract] The abstract would be strengthened by including even brief quantitative indications of the magnitude of the reported TTS improvements (e.g., average accuracy deltas or pass@k gains).
- [Methods] Clarify the exact unstructured pruning algorithms (e.g., magnitude-based, Wanda, or others) and the precise definition of 'TTS performance' (e.g., which scaling curves or metrics) in the methods section.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback on our manuscript. We have carefully addressed each major comment below and revised the paper to improve clarity and rigor where appropriate. We believe these changes strengthen the presentation of our findings without altering the core experimental results.
read point-by-point responses
-
Referee: [Abstract] Abstract: the statement that unstructured pruning 'consistently show[s] that [it] augments TTS performance' and 'at times can even outperform' the full model is presented without any mention of statistical significance testing, error bars, variance across runs, or controls for confounds such as random seeds and hyperparameter sensitivity, which are required to substantiate the reliability of the reported gains.
Authors: We agree that the abstract would benefit from explicit reference to the reliability of the reported gains. In the full paper, all experiments used fixed random seeds for reproducibility across the two models and four benchmarks, and we observed consistent directional improvements (unstructured pruning outperforming structured and, in several cases, the dense baseline) that substantially exceed the scale of typical LLM evaluation variance. To directly address the concern, we have revised the abstract to note the consistency of results across configurations and added a dedicated paragraph in Section 4 discussing run-to-run stability, hyperparameter controls, and the magnitude of gains relative to expected variance. Error bars have been incorporated into the key scaling curves in the revised figures. revision: yes
-
Referee: [Experimental setup] Experimental setup (layer-wise sparsity allocation): the paper studies multiple layer-wise sparsity allocation strategies but provides no indication that these allocations were fixed a priori or validated on held-out data rather than selected or swept on the same four benchmarks used for final reporting; if the latter occurred, the observed advantage of unstructured over structured pruning could be an artifact of hyperparameter selection bias rather than an intrinsic property.
Authors: This is a valid methodological concern. The layer-wise sparsity allocation strategies examined (uniform, magnitude-based, and importance-weighted variants) were selected a priori from standard approaches in the unstructured pruning literature and were not tuned or swept on the four evaluation benchmarks. The same fixed set of strategies was applied uniformly across all experiments to isolate the effect of allocation choice. We have added explicit language in the revised Section 3.2 clarifying that these allocations were predetermined based on prior work and not optimized on the test data. This removes any ambiguity regarding selection bias. revision: yes
Circularity Check
No circularity: purely empirical comparison without derivation or fitted predictions
full rationale
The paper reports benchmark results from pruning experiments on two LLMs across four reasoning tasks. No equations, first-principles derivations, or 'predictions' appear that could reduce to inputs by construction. Layer-wise sparsity strategies are described as empirical choices studied in the experiments, not as fitted parameters renamed as predictions or justified solely by self-citation. The central claim rests on direct observations from held-out evaluations rather than any self-referential loop, making the work self-contained experimental reporting.
Axiom & Free-Parameter Ledger
free parameters (1)
- layer-wise sparsity ratios
Reference graph
Works this paper leans on
-
[1]
Beyond efficiency: A systematic survey of resource-efficient large language models
SliceGPT: Compress large language models by deleting rows and columns. InThe Twelfth Inter- national Conference on Learning Representations. Hadi Askari, Shivanshu Gupta, Fei Wang, Anshuman Chhabra, and Muhao Chen. 2025. LayerIF: Estimat- ing layer quality for large language models using influence functions. InThe Thirty-ninth Annual Con- ference on Neura...
-
[2]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. Rémi Coulom. 2006. Efficient selectivity and backup operators in monte-carlo tree search. InInternational conference on computers and games, pages 72–83. Springer. Kazuki Egashira, Mark Vero, Robin Staab, Jingxuan He, and Martin Vechev. 2024. Exploiting llm quanti- zation.Advance...
work page internal anchor Pith review arXiv 2006
-
[3]
InAdvances in Neural In- formation Processing Systems, volume 28
Learning both weights and connections for efficient neural network. InAdvances in Neural In- formation Processing Systems, volume 28. Curran Associates, Inc. Babak Hassibi, David G Stork, and Gregory J Wolff
-
[4]
Scaling Laws for Neural Language Models
Optimal brain surgeon and general network pruning. InIEEE international conference on neural networks, pages 293–299. IEEE. 9 Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring mathematical problem solving with the MATH dataset. InThirty- fifth Conference on Neural Informati...
work page internal anchor Pith review arXiv 2021
-
[5]
InThe Twelfth Inter- national Conference on Learning Representations
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harri- son Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe
-
[6]
Spinquant–llm quantization with learned rotations,
Let’s verify step by step. InThe Twelfth Inter- national Conference on Learning Representations. Chihung Lin and Chang-Fu Kuo. 2025. Roles and potential of large language models in healthcare: A comprehensive review.Biomedical Journal, 48(5):100868. Zechun Liu, Changsheng Zhao, Igor Fedorov, Bilge Soran, Dhruv Choudhary, Raghuraman Krishnamoor- thi, Vikas...
-
[7]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
A simple and effective pruning approach for large language models. InThe Twelfth International Conference on Learning Representations. Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, Chuning Tang, Congcong Wang, Dehao Zhang, Enming Yuan, Enzhe Lu, Fengxiang Tang, Flood Sung, Gu...
work page internal anchor Pith review arXiv 2025
-
[8]
Al- right, let’s start
Then, find r2 where r is the radius of that sphere, and express it as a fraction p/q with p and q coprime, then find p+q . Al- right, let’s start. First, let me recall some formulas. For a rect- angular box with length, width, and height x, y, z, the surface area is2(xy+yz+xz) =
-
[9]
The problem is about finding the smallest sphere that can contain such a box
The volume is xyz= 23 . The problem is about finding the smallest sphere that can contain such a box. The sphere’s radius will depend on the box’s dimensions. ..........= −1 + 2 √ 6≈ −1 + 4.898≈3.898 , which is positive. Therefore, if x=y= 2 , then z= 23/(22) = 23/4 = 5.75 . Alternatively, if x=y≈3.898 , then z= 23/x 2. Let me compute x2 exactly: x=−1 + 2 √
-
[10]
Then z= 23/(25−4 √ 6)
There- fore, x2 = (−1+2 √ 6)2 = 1−4 √ 6+24 = 25−4 √ 6≈25−9.798≈15.202 . Then z= 23/(25−4 √ 6). Let me rationalize that denominator: Multiply numerator and denominator by (25 + 4 √ 6): z= 23(25+4 √ 6) (25−4 √ 6)(25+4 √
-
[11]
Answer: 721 (Correct) 17 Table 12: Qualitative outputs on AMC23 for Unpruned vs
= 23(25+4 √ 6) 625−(4 √ 6)2 . Answer: 721 (Correct) 17 Table 12: Qualitative outputs on AMC23 for Unpruned vs. Wanda-Uniform 20% pruned model. Query Unpruned Wanda-Uniform 20% If A and B are vertices of a polyhedron, define the distance d(A, B) to be the minimum num- ber of edges of the poly- hedron one must tra- verse in order to con- nect A and B. For e...
-
[12]
Find the probability that d(Q, R)> d(R, S)
Let Q, R, and S be randomly chosen dis- tinct vertices of a regu- lar icosahedron (regular polyhedron made up of 20 equilateral triangles). Find the probability that d(Q, R)> d(R, S) . The final answer can be written in the form m n , where m and n are rela- tively prime positive in- tegers. What is m+n ? Chain of Thought:Okay, so I need to find the maxim...
-
[13]
Maybe there’s a better approach
Hmm, this seems complicated. Maybe there’s a better approach. Let me think. Al- ternatively, maybe consider substituting y2 from the equation or something else. Alter- natively, think of this as a quadratic equation in y2? Let me check. Let me rearrange the equation: y4 + (2x2 + 2x−1)y 2 + (x4 + 2x3 + 3x1 + 2x+ 1−16) = 0 . So, if I let y2 =t , then:t2 + (...
-
[14]
6 and 10 are even
Can we make 29 with 6 and 10? 29 is odd. 6 and 10 are even. So no. If we use 15 twice: 44 - 30 = 14. Can we make 14 with 6 and 10? 10 + 6* (something)? 14 -10 = 4. Not divisible by 6. 14 - 6 = 8. Not divisible by 10. So no Answer: 8 (Incorrect) Chain of Thought:Okay, so I need to fig- ure out the largest amount of money that can’t be formed using coins of...
-
[15]
The positions that are meta to 1 are 3 and
-
[16]
The positions that are meta to 3 are 1 and
-
[17]
A benzene ring has a carboxylic acid, a carbaldehyde, and a cyano group all meta to one another
Therefore, the only common position is 5. So if the third group is at 5, then it is meta to both 1 and 3. Therefore, the three groups are at positions Answer: C (Incorrect) Chain of Thought:Okay, so I need to figure out the correct IUPAC name for this com- plex benzene ring molecule. Let me start by breaking down the information given. First, the molecule...
-
[18]
But the addition is between the product and 1, so how can we group it differently? Wait, for example, maybe insert- ing parentheses between the multiplications and the addition
So, to have the addition happen earlier, we need to have parentheses that include the ad- dition operator. But the addition is between the product and 1, so how can we group it differently? Wait, for example, maybe insert- ing parentheses between the multiplications and the addition. For example, 2·3·(4·(5 + 1)) which is same as before. Or 2·(3·4·(5 + 1))...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.