Recognition: unknown
Evaluation without Generation: Non-Generative Assessment of Harmful Model Specialization with Applications to CSAM
Pith reviewed 2026-05-07 16:51 UTC · model grok-4.3
The pith
Gaussian probing distinguishes harmful fine-tuning from benign adaptations by measuring internal representation responses to Gaussian latent ensembles without sampling any outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
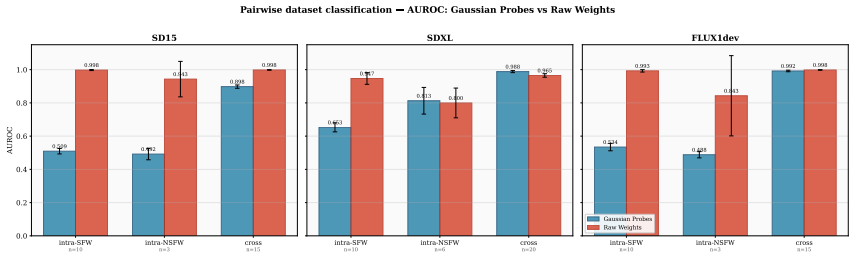
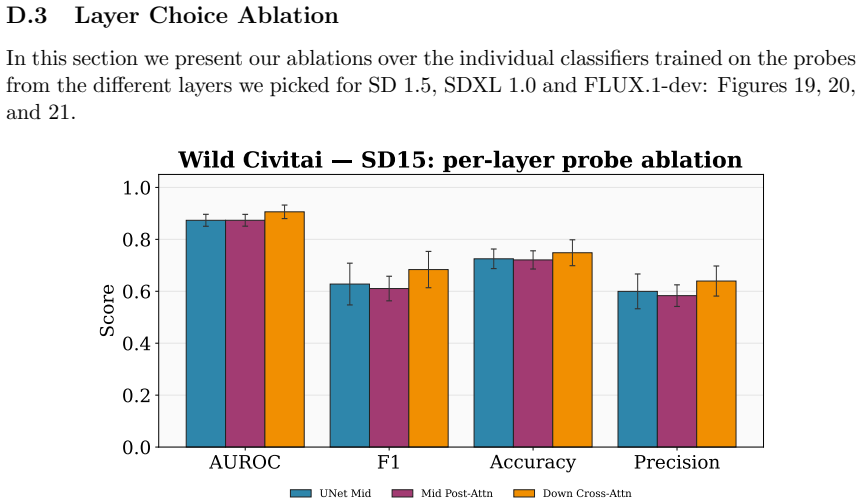
Gaussian probing characterizes how LoRA adaptors perturb a model's internal representations by quantifying their responses to Gaussian latent ensembles. Unlike raw-weight comparisons, this method reliably separates benign from harmful specializations without requiring output sampling and stays effective under weight rescaling as an adversarial change. The approach is shown to work for detecting CSAM-specialized models, supplying a non-generative route to evaluate high-risk generative systems.
What carries the argument
Gaussian probing, a technique that measures perturbations to internal representations induced by LoRA adaptors through their responses to Gaussian latent ensembles.
If this is right
- Auditing becomes possible at platform scale without ever producing restricted outputs.
- The method continues to work after weight rescaling is applied to the adapted weights.
- Evaluation extends to any high-risk domain where output generation is legally or ethically barred.
- Capability assessment can rely on internal states rather than curated prompts or red-teaming.
Where Pith is reading between the lines
- The same internal-probing logic could be adapted to flag other prohibited capabilities without direct generation tests.
- Hosting platforms could embed the check into release pipelines to filter dangerous fine-tunes automatically.
- If the signature proves general, non-generative methods might replace output sampling for many safety audits.
Load-bearing premise
The response patterns to Gaussian latent ensembles form a stable and distinct signature of harmful specialization that holds across domains and resists common evasions.
What would settle it
Observing a CSAM-specialized model whose Gaussian ensemble responses match those of a benign fine-tune, or a benign model whose responses trigger the harmful flag.
Figures























read the original abstract
Auditing the fine-tunes of open-weight generative models for harmful specialization has become a new governance challenge for model hosting platforms. The standard toolkit, generative evaluation via curated prompts or red-teaming, does not scale to platform-level auditing and breaks down entirely for domains like CSAM where generation is legally constrained. This motivates the Evaluation without Generation problem: assessing model capabilities without producing outputs. We argue that in such settings, capability must be inferred from the model's state, either its parameters or internal representations, rather than its outputs. We introduce Gaussian probing, a method that characterizes how LoRA adaptors perturb a model's internal representations by measuring responses to Gaussian latent ensembles. Unlike raw-weight baselines, Gaussian probing reliably distinguishes benign from harmful specialization without sampling outputs. We demonstrate effectiveness in high-risk domains, including detecting models specialized for child sexual abuse material (CSAM), where output-based evaluation is legally and ethically constrained. Our results show that Gaussian probing provides a scalable non-generative alternative for evaluating high-risk generative systems and remains robust to weight rescaling, a representative adversarial manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses the 'Evaluation without Generation' problem for auditing fine-tuned open-weight generative models for harmful specialization (e.g., CSAM) where output sampling is legally or ethically constrained. It proposes Gaussian probing, which infers capabilities from how LoRA adaptors perturb internal representations by measuring model responses to Gaussian latent ensembles. The central claim is that this non-generative approach reliably distinguishes harmful from benign specializations and remains robust to representative adversarial manipulations such as weight rescaling.
Significance. If the empirical claims hold, the work provides a scalable, state-based auditing tool that could fill a critical gap in AI governance for high-risk domains. By shifting evaluation from outputs to internal representations, it enables platform-level checks without violating constraints on generation. The robustness result and focus on LoRA-induced shifts are practical strengths for deployment.
major comments (2)
- Abstract: The assertion that Gaussian probing 'reliably distinguishes benign from harmful specialization without sampling outputs' and 'remains robust to weight rescaling' is presented without any experimental details, datasets, metrics, baselines, or statistical evidence. This is load-bearing for the central claim, as the reader's strongest claim and the paper's effectiveness demonstration cannot be evaluated from the given text.
- Method (Gaussian probing description): The claim that responses to Gaussian latent ensembles yield a stable, generalizable signature distinct from benign adaptations lacks concrete specification of ensemble construction, measured statistics, or quantitative separability criteria. Without these, it is impossible to verify whether the approach avoids the weakest assumption (evasion by other manipulations) or reduces to a fitted quantity.
minor comments (1)
- Abstract: Consider adding a one-sentence overview of the experimental scope (e.g., number of models or domains tested) to help readers gauge the strength of the 'high-risk domains' demonstration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline revisions that will strengthen the presentation of our central claims while preserving the paper's focus on non-generative evaluation.
read point-by-point responses
-
Referee: Abstract: The assertion that Gaussian probing 'reliably distinguishes benign from harmful specialization without sampling outputs' and 'remains robust to weight rescaling' is presented without any experimental details, datasets, metrics, baselines, or statistical evidence. This is load-bearing for the central claim, as the reader's strongest claim and the paper's effectiveness demonstration cannot be evaluated from the given text.
Authors: We agree that the abstract would be strengthened by incorporating high-level empirical support for the load-bearing claims. In the revised version, we will expand the abstract to reference the key experimental outcomes from our CSAM and benign specialization benchmarks, including the datasets used, the primary metric for distinction, and the robustness evaluation under weight rescaling. The full details on datasets, metrics, baselines, and statistical tests remain in Sections 4 and 5; the abstract revision will make these results visible at the outset without altering the manuscript's length constraints. revision: yes
-
Referee: Method (Gaussian probing description): The claim that responses to Gaussian latent ensembles yield a stable, generalizable signature distinct from benign adaptations lacks concrete specification of ensemble construction, measured statistics, or quantitative separability criteria. Without these, it is impossible to verify whether the approach avoids the weakest assumption (evasion by other manipulations) or reduces to a fitted quantity.
Authors: The manuscript's Section 3 defines Gaussian probing via responses to Gaussian latent ensembles, but we acknowledge that additional concrete details would improve verifiability. We will revise the method description to specify ensemble construction (sampling from a zero-mean unit-variance Gaussian in the model's latent space), the measured statistics (layer-wise shifts in internal activations), and the separability criteria (a threshold on the resulting probing vector that separates harmful from benign LoRA adaptations). These additions will clarify that the signature derives from general representation perturbations rather than task-specific fitting and will include a brief discussion of why the approach is not trivially evaded by the manipulations considered in our robustness experiments. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper introduces Gaussian probing as an empirical technique to infer harmful specialization from internal model representations via responses to Gaussian latent ensembles, without any derivation chain, equations, or first-principles results that reduce the claimed distinction to a fitted quantity or self-referential definition. The central claim is framed as an observable statistical separation between benign and harmful LoRA adaptations, supported by experimental results rather than by construction from the method's own inputs. No self-citations, ansatzes, or uniqueness theorems are invoked in a load-bearing manner that would collapse the evaluation to tautology. The approach remains self-contained as a non-generative inference method.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2404.14082 (2024)
Leonard Bereska and Efstratios Gavves. Mechanistic interpretability for ai safety – a review, 2024. URLhttps://arxiv.org/abs/2404.14082
-
[2]
kohya ss: Gui and cli for training diffusion models.https://github.com /bmaltais/kohya_ss, 2025
bmaltais. kohya ss: Gui and cli for training diffusion models.https://github.com /bmaltais/kohya_ss, 2025. Accessed: 2026-04-23
2025
-
[3]
Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts
Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 3558–3568, 2021
2021
-
[4]
Civitai. Introducing Civitai Green: Our Continued Commitment to Community Safety — Civitai — civitai.com.https://civitai.com/articles/7078/introduc ing-civitai-green-our-continued-commitment-to-community-safety, 2024. [Accessed 21-04-2026]
2024
-
[5]
Towards automated circuit discovery for mechanistic inter- pretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
Arthur Conmy, Augustine Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adri` a Garriga-Alonso. Towards automated circuit discovery for mechanistic inter- pretability.Advances in Neural Information Processing Systems, 36:16318–16352, 2023
2023
-
[6]
Ana-Maria Cretu, Klim Kireev, Amro Abdalla, Wisdom Obinna, Raphael Meier, Sarah Adel Bargal, Elissa M Redmiles, and Carmela Troncoso. Evaluating concept filtering defenses against child sexual abuse material generation by text-to-image mod- els.arXiv preprint arXiv:2512.05707, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Interpreting the weight space of customized diffusion models.Advances in Neural Information Processing Systems, 37:137334– 137371, 2024
Amil Dravid, Yossi Gandelsman, Kuan-Chieh Wang, Rameen Abdal, Gordon Wet- zstein, Alexei Efros, and Kfir Aberman. Interpreting the weight space of customized diffusion models.Advances in Neural Information Processing Systems, 37:137334– 137371, 2024
2024
-
[8]
arXiv preprint arXiv:2310.12508 (2023)
Chongyu Fan, Jiancheng Liu, Yihua Zhang, Eric Wong, Dennis Wei, and Sijia Liu. Salun: Empowering machine unlearning via gradient-based weight saliency in both image classification and generation.arXiv preprint arXiv:2310.12508, 2023
-
[9]
2024 cybertipline report.https: //www.missingkids.org/content/dam/missingkids/pdfs/cybertiplinedata202 4/2024-CyberTipline-Report.pdf, 2025
National Center for Missing & Exploited Children. 2024 cybertipline report.https: //www.missingkids.org/content/dam/missingkids/pdfs/cybertiplinedata202 4/2024-CyberTipline-Report.pdf, 2025
2024
-
[10]
Masane Fuchi and Tomohiro Takagi. Erasing concepts from text-to-image diffusion models with few-shot unlearning.arXiv preprint arXiv:2405.07288, 2024
-
[11]
Diffusion models and representation learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
Michael Fuest, Pingchuan Ma, Ming Gui, Johannes Schusterbauer, Vincent Tao Hu, and Bj¨ orn Ommer. Diffusion models and representation learning: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[12]
Eras- ing concepts from diffusion models
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau. Eras- ing concepts from diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2426–2436, 2023
2023
-
[13]
Unified concept editing in diffusion models
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzy´ nska, and David Bau. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 5111–5120, 2024
2024
-
[14]
Red Teaming Language Models to Reduce Harms: Methods, Scaling Behaviors, and Lessons Learned
Deep Ganguli, Liane Lovitt, Jackson Kernion, Amanda Askell, Yuntao Bai, Saurav Kadavath, Ben Mann, Ethan Perez, Nicholas Schiefer, Kamal Ndousse, et al. Red teaming language models to reduce harms: Methods, scaling behaviors, and lessons learned.arXiv preprint arXiv:2209.07858, 2022. 18
work page internal anchor Pith review arXiv 2022
-
[15]
Meta-unlearning on diffusion models: Preventing relearning unlearned concepts
Hongcheng Gao, Tianyu Pang, Chao Du, Taihang Hu, Zhijie Deng, and Min Lin. Meta-unlearning on diffusion models: Preventing relearning unlearned concepts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2131–2141, 2025
2025
-
[16]
Yale University Press, 2018
Tarleton Gillespie.Custodians of the Internet: Platforms, content moderation, and the hidden decisions that shape social media. Yale University Press, 2018
2018
-
[17]
Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.ICLR, 1(2):3, 2022
2022
-
[18]
Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers, 2024
Chi-Pin Huang, Kai-Po Chang, Chung-Ting Tsai, Yung-Hsuan Lai, Fu-En Yang, and Yu-Chiang Frank Wang. Receler: Reliable concept erasing of text-to-image diffusion models via lightweight erasers, 2024. URLhttps://arxiv.org/abs/2311.17717
-
[19]
Harm without limits: Ai child sexual abuse material through the eyes of our analysts, March 2026
Internet Watch Foundation (IWF). Harm without limits: Ai child sexual abuse material through the eyes of our analysts, March 2026. URLhttps://www.iwf.or g.uk/media/hl1nvdti/iwf-ai-csam-report-2026.pdf
2026
-
[20]
Invokeai, 2026
Invoke AI Contributors. Invokeai, 2026. URLhttps://github.com/invoke-ai/In vokeAI
2026
-
[21]
Jailbreakdiffbench: A comprehensive benchmark for jail- breaking diffusion models
Xiaolong Jin, Zixuan Weng, Hanxi Guo, Chenlong Yin, Siyuan Cheng, Guangyu Shen, and Xiangyu Zhang. Jailbreakdiffbench: A comprehensive benchmark for jail- breaking diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16461–16471, 2025
2025
-
[22]
Deep linear probe generators for weight space learning, 2024
Jonathan Kahana, Eliahu Horwitz, Imri Shuval, and Yedid Hoshen. Deep linear probe generators for weight space learning, 2024. URLhttps://arxiv.org/abs/2410.1 0811
2024
-
[23]
Child safety necessitates new ap- proaches to ai safety
Neil Kale*, Rebecca Portnoff*, Pratiksha Thaker, Michael Simpson, Robertson Wang, Kevin Kuo, Chhavi Yadav, and Virginia Smith. Child safety necessitates new ap- proaches to ai safety. 2026. URLhttps://papers.ssrn.com/sol3/papers.cfm?ab stract_id=6206860. * Equal contribution
2026
-
[24]
Diffguard: Text-based safety checker for diffusion models.arXiv preprint arXiv:2412.00064, 2024
Massine El Khader, Elias Al Bouzidi, Abdellah Oumida, Mohammed Sbaihi, Eliott Binard, Jean-Philippe Poli, Wassila Ouerdane, Boussad Addad, and Katarzyna Ka- pusta. Diffguard: Text-based safety checker for diffusion models.arXiv preprint arXiv:2412.00064, 2024
-
[25]
Boosting alignment for post- unlearning text-to-image generative models.Advances in Neural Information Pro- cessing Systems, 37:85131–85154, 2024
Myeongseob Ko, Henry Li, Zhun Wang, Jonathan Patsenker, Jiachen Tianhao Wang, Qinbin Li, Ming Jin, Dawn Song, and Ruoxi Jia. Boosting alignment for post- unlearning text-to-image generative models.Advances in Neural Information Pro- cessing Systems, 37:85131–85154, 2024
2024
-
[26]
Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale.International journal of computer vision, 128 (7):1956–1981, 2020
1956
-
[27]
Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960, 2022
Mingi Kwon, Jaeseok Jeong, and Youngjung Uh. Diffusion models already have a semantic latent space.arXiv preprint arXiv:2210.10960, 2022
-
[28]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024. 19
2024
-
[29]
Holistic evaluation of text-to-image models.Advances in Neural Information Process- ing Systems, 36:69981–70011, 2023
Tony Lee, Michihiro Yasunaga, Chenlin Meng, Yifan Mai, Joon Sung Park, Agrim Gupta, Yunzhi Zhang, Deepak Narayanan, Hannah Teufel, Marco Bellagente, et al. Holistic evaluation of text-to-image models.Advances in Neural Information Process- ing Systems, 36:69981–70011, 2023
2023
-
[30]
Shake to leak: Fine- tuning diffusion models can amplify the generative privacy risk
Zhangheng Li, Junyuan Hong, Bo Li, and Zhangyang Wang. Shake to leak: Fine- tuning diffusion models can amplify the generative privacy risk. In2024 IEEE Con- ference on Secure and Trustworthy Machine Learning (SaTML), pages 18–32. IEEE, 2024
2024
-
[31]
Zherui Li, Zheng Nie, Zhenhong Zhou, Yue Liu, Yitong Zhang, Yu Cheng, Qingsong Wen, Kun Wang, Yufei Guo, and Jiaheng Zhang. Diffuguard: How intrinsic safety is lost and found in diffusion large language models.arXiv preprint arXiv:2509.24296, 2025
-
[32]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ra- manan, Piotr Doll´ ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014
2014
-
[33]
When are concepts erased from diffusion models?arXiv preprint arXiv:2505.17013, 2025
Kevin Lu, Nicky Kriplani, Rohit Gandikota, Minh Pham, David Bau, Chinmay Hegde, and Niv Cohen. When are concepts erased from diffusion models?arXiv preprint arXiv:2505.17013, 2025
-
[34]
Mace: Mass concept erasure in diffusion models
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. Mace: Mass concept erasure in diffusion models. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition, pages 6430–6440, 2024
2024
-
[35]
Stable bias: Evaluating societal representations in diffusion models.Advances in Neural Information Processing Systems, 36:56338–56351, 2023
Sasha Luccioni, Christopher Akiki, Margaret Mitchell, and Yacine Jernite. Stable bias: Evaluating societal representations in diffusion models.Advances in Neural Information Processing Systems, 36:56338–56351, 2023
2023
-
[36]
Vbench: Comprehensive benchmark suite for video generative models
Mengyao Lyu, Yuhong Yang, Haiwen Hong, Hui Chen, Xuan Jin, Yuan He, Hui Xue, Jungong Han, and Guiguang Ding. One-dimensional adapter to rule them all: Concepts, diffusion models and erasing applications. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7559–7568, 2024. doi: 10.1109/CVPR52733.2024.00722
-
[37]
Jailbreaking prompt attack: A controllable adversarial attack against diffusion models
Jiachen Ma, Yijiang Li, Zhiqing Xiao, Anda Cao, Jie Zhang, Chao Ye, and Junbo Zhao. Jailbreaking prompt attack: A controllable adversarial attack against diffusion models. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 3141–3157, 2025
2025
-
[38]
Object segmentation dataset.https://huggingface.co/dataset s/amaye15/object-segmentation, 2025
Andrew Mayes. Object segmentation dataset.https://huggingface.co/dataset s/amaye15/object-segmentation, 2025. Accessed: 2024-04-08
2025
-
[39]
Opennsfw: A dataset for nsfw image classification
Andres Morelli et al. Opennsfw: A dataset for nsfw image classification. Yahoo open source project, 2016. URLhttps://github.com/yahoo/open_nsfw
2016
-
[40]
Danbooru2023.https://huggingface.co/datasets/nyanko7/danbooru 2023, 2023
Nyanko. Danbooru2023.https://huggingface.co/datasets/nyanko7/danbooru 2023, 2023. Accessed: 2024-04-08
2023
-
[41]
Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models
Bryan A Plummer, Liwei Wang, Chris M Cervantes, Juan C Caicedo, Julia Hocken- maier, and Svetlana Lazebnik. Flickr30k entities: Collecting region-to-phrase corre- spondences for richer image-to-sentence models. InProceedings of the IEEE interna- tional conference on computer vision, pages 2641–2649, 2015. 20
2015
-
[42]
Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models
Yiting Qu, Xinyue Shen, Xinlei He, Michael Backes, Savvas Zannettou, and Yang Zhang. Unsafe diffusion: On the generation of unsafe images and hateful memes from text-to-image models. InProceedings of the 2023 ACM SIGSAC conference on computer and communications security, pages 3403–3417, 2023
2023
-
[43]
Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610, 2022
Javier Rando, Daniel Paleka, David Lindner, Lennart Heim, and Florian Tram` er. Red-teaming the stable diffusion safety filter.arXiv preprint arXiv:2210.04610, 2022
-
[44]
Yale University Press, 2019
Sarah T Roberts.Behind the screen. Yale University Press, 2019
2019
-
[45]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨ orn Om- mer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684– 10695, 2022
2022
-
[46]
Large-scale classifica- tion of fine-art paintings: Learning the right metric on the right feature
Babak Saleh and Ahmed Elgammal. Large-scale classification of fine-art paintings: Learning the right metric on the right feature, 2015. URLhttps://arxiv.org/ab s/1505.00855
-
[47]
Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278– 25294, 2022
Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models.Advances in neural information processing systems, 35:25278– 25294, 2022
2022
-
[48]
Self-supervised rep- resentation learning on neural network weights for model characteristic prediction
Konstantin Sch¨ urholt, Dimche Kostadinov, and Damian Borth. Self-supervised rep- resentation learning on neural network weights for model characteristic prediction. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors,Advances in Neural Information Processing Systems, volume 34, pages 16481– 16493. Curran Associates, Inc...
2021
-
[49]
Towards scalable and versatile weight space learning
Konstantin Sch¨ urholt, Michael W Mahoney, and Damian Borth. Towards scalable and versatile weight space learning. InProceedings of the 41st International Conference on Machine Learning, pages 43947–43966, 2024
2024
-
[50]
arXiv preprint arXiv:2305.15324 , year=
Toby Shevlane, Sebastian Farquhar, Ben Garfinkel, Mary Phuong, Jess Whittlestone, Jade Leung, Daniel Kokotajlo, Nahema Marchal, Markus Anderljung, Noam Kolt, Lewis Ho, Divya Siddarth, Shahar Avin, Will Hawkins, Been Kim, Iason Gabriel, Vijay Bolina, Jack Clark, Yoshua Bengio, Paul Christiano, and Allan Dafoe. Model evaluation for extreme risks, 2023. URLh...
-
[51]
The psychological well-being of content moderators: the emotional labor of commercial moderation and avenues for improving support
Miriah Steiger, Timir J Bharucha, Sukrit Venkatagiri, Martin J Riedl, and Matthew Lease. The psychological well-being of content moderators: the emotional labor of commercial moderation and avenues for improving support. InProceedings of the 2021 CHI conference on human factors in computing systems, pages 1–14, 2021
2021
-
[52]
Unstable unlearning: The hidden risk of concept resurgence in diffu- sion models
Vinith Menon Suriyakumar, Rohan Alur, Ayush Sekhari, Manish Raghavan, and Ashia C Wilson. Unstable unlearning: The hidden risk of concept resurgence in diffu- sion models. InICLR 2025 Workshop on Navigating and Addressing Data Problems for Foundation Models, 2024
2025
-
[53]
Generative ml and csam: Im- plications and mitigations.Stanford Digital Repository, 2023
David Thiel, Melissa Stroebel, and Rebecca Portnoff. Generative ml and csam: Im- plications and mitigations.Stanford Digital Repository, 2023
2023
-
[54]
Safety by design three-month progress report #3: November 2024 to january 2025.https://info.thorn.org/hubfs/Thorn-SafetybyDesign-ThreeMonthProgr essReport-3.pdf?, 2025
Thorn. Safety by design three-month progress report #3: November 2024 to january 2025.https://info.thorn.org/hubfs/Thorn-SafetybyDesign-ThreeMonthProgr essReport-3.pdf?, 2025. 21
2024
-
[55]
Safety by design for generative ai: Preventing child sexual abuse.https://info.thorn.org/hubfs/thorn-safety-by-design-for-g enerative-AI.pdf, 2024
Thorn and All Tech is Human. Safety by design for generative ai: Preventing child sexual abuse.https://info.thorn.org/hubfs/thorn-safety-by-design-for-g enerative-AI.pdf, 2024
2024
-
[56]
Attacks and defenses for gen- erative diffusion models: A comprehensive survey.ACM Computing Surveys, 57(8): 1–44, 2025
Vu Tuan Truong, Luan Ba Dang, and Long Bao Le. Attacks and defenses for gen- erative diffusion models: A comprehensive survey.ACM Computing Surveys, 57(8): 1–44, 2025
2025
-
[57]
Unsplash lite dataset.https://github.com/unsplash/datasets, 2017
Unsplash. Unsplash lite dataset.https://github.com/unsplash/datasets, 2017
2017
-
[58]
Predicting neural network accuracy from weights, 2021
Thomas Unterthiner, Daniel Keysers, Sylvain Gelly, Olivier Bousquet, and Ilya Tol- stikhin. Predicting neural network accuracy from weights, 2021. URLhttps: //arxiv.org/abs/2002.11448
-
[59]
Diffusers: State-of-the-art diffusion models, 2022
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models, 2022
2022
-
[60]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review arXiv 2025
-
[61]
Jailbroken: How does llm safety training fail?Advances in neural information processing systems, 36:80079– 80110, 2023
Alexander Wei, Nika Haghtalab, and Jacob Steinhardt. Jailbroken: How does llm safety training fail?Advances in neural information processing systems, 36:80079– 80110, 2023
2023
-
[62]
Scissorhands: Scrub data influence via connection sensitivity in networks
Jing Wu and Mehrtash Harandi. Scissorhands: Scrub data influence via connection sensitivity in networks. InEuropean Conference on Computer Vision, pages 367–384. Springer, 2024
2024
-
[63]
Erasediff: Erasing data influence in diffusion models.arXiv preprint arXiv:2401.05779, 2024
Jing Wu, Trung Le, Munawar Hayat, and Mehrtash Harandi. Erasediff: Erasing data influence in diffusion models.arXiv preprint arXiv:2401.05779, 2024
-
[64]
Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
Ling Yang, Zhilong Zhang, Yang Song, Shenda Hong, Runsheng Xu, Yue Zhao, Wen- tao Zhang, Bin Cui, and Ming-Hsuan Yang. Diffusion models: A comprehensive survey of methods and applications.ACM computing surveys, 56(4):1–39, 2023
2023
-
[65]
Sneakyprompt: Jailbreaking text-to-image generative models
Yuchen Yang, Bo Hui, Haolin Yuan, Neil Gong, and Yinzhi Cao. Sneakyprompt: Jailbreaking text-to-image generative models. In2024 IEEE symposium on security and privacy (SP), pages 897–912. IEEE, 2024
2024
-
[66]
What lurks within? concept auditing for shared diffusion models at scale
Xiaoyong Yuan, Xiaolong Ma, Linke Guo, and Lan Zhang. What lurks within? concept auditing for shared diffusion models at scale. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security, pages 4154– 4168, 2025
2025
-
[67]
Defensive unlearning with adversarial training for robust concept erasure in diffusion models, 2024
Yimeng Zhang, Xin Chen, Jinghan Jia, Yihua Zhang, Chongyu Fan, Jiancheng Liu, Mingyi Hong, Ke Ding, and Sijia Liu. Defensive unlearning with adversarial training for robust concept erasure in diffusion models, 2024. URLhttps://arxiv.org/ab s/2405.15234
-
[68]
Understanding and im- proving adversarial attacks on latent diffusion model
Boyang Zheng, Chumeng Liang, Xiaoyu Wu, and Yan Liu. Understanding and im- proving adversarial attacks on latent diffusion model. 2023. 22 A Consistency of Gaussian Probing The population object underlying Gaussian probing is given by (1), and the empirical representation (2) is its Monte Carlo approximation. The following result shows that this approxima...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.