Recognition: unknown
HANDFUL: Sequential Grasp-Conditioned Dexterous Manipulation with Resource Awareness
Pith reviewed 2026-05-07 16:14 UTC · model grok-4.3
The pith
Treating fingers as a limited resource during initial grasps improves success on follow-up dexterous manipulation tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
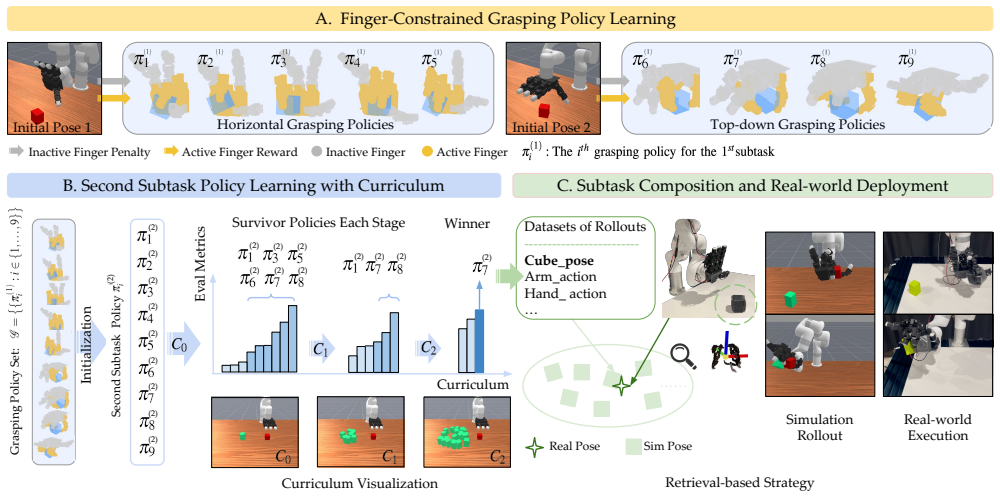
By modeling finger usage as a limited resource and applying finger-level contact rewards during grasp learning, the framework produces initial grasps that preserve both stability and finger availability; when these grasps are selected via curriculum-based policy learning for downstream subtasks, second-subtask success rates and robustness rise compared with baselines that greedily optimize only the initial grasp.
What carries the argument
Finger-level contact rewards that treat individual fingers as scarce resources during grasp optimization, combined with curriculum-based policy selection to favor grasps compatible with a second subtask.
If this is right
- Prioritizing resource conservation in the initial grasp directly raises the probability of completing the second subtask without dropping the object.
- Curriculum learning on resource-aware grasps produces policies that generalize better across pushing, pulling, and pressing objectives under the same grasp-conditioned setup.
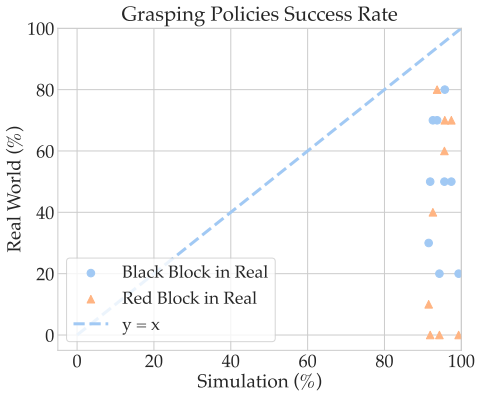
- The same principle yields measurable robustness gains in simulation and transfers to physical execution on a multi-fingered hand.
- A shared benchmark of sequential tasks provides a concrete testbed for comparing grasp strategies that account for future finger availability.
Where Pith is reading between the lines
- Longer task sequences beyond two subtasks would likely require extending the reward structure to track remaining finger budgets across multiple steps.
- The approach could be combined with perception modules so that grasp selection adapts online to object geometry variations not seen in simulation.
- Explicit resource modeling may reduce the need for frequent re-grasping in real deployments where finger fatigue or contact drift occurs.
Load-bearing premise
Finger-level contact rewards during the first grasp will consistently yield holds that remain stable while leaving the needed fingers free for the second subtask, even across different objects and real-world conditions.
What would settle it
A controlled comparison on the benchmark tasks in which the resource-aware method shows no gain or a loss in second-subtask success rate relative to the greedy initial-grasp baseline, under identical training budgets and object sets.
Figures





read the original abstract
Dexterous robot hands offer rich opportunities for multifunctional manipulation, where a robot must execute multiple skills in sequence while maintaining control over previously grasped objects. Most prior work in dexterous manipulation focuses on single-object, single-skill tasks. In contrast, our insight is that many sequential tasks require resource-aware grasps that conserve fingers for future actions. In this paper, we study sequential grasp-conditioned dexterous manipulation, where a robot first grasps an object and then performs a second, distinct manipulation subtask while preserving the initial grasp. We introduce HANDFUL, a learning framework that models finger usage as a limited resource and encourages exploration of resource-aware grasps through finger-level contact rewards. These grasps are subsequently selected for downstream tasks via curriculum-based policy learning. We further propose HANDFUL-Bench, a simulation benchmark that introduces sequential dexterous manipulation tasks across multiple secondsubtask objectives, including pushing, pulling, and pressing, under a shared grasp-conditioned setup. Extensive simulation results demonstrate that prioritizing resource-aware grasps improves second-subtask success and robustness compared to a baseline that greedily optimizes the initial grasp before attempting the second subtask. We additionally validate our approach on a real dexterous LEAP hand. Together, this work establishes resource-aware grasp planning as a key principle for multifunctional dexterous manipulation. Supplementary material is available on our website: https://handful-dex.github.io.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HANDFUL, a reinforcement learning framework for sequential grasp-conditioned dexterous manipulation. It models finger usage as a limited resource and employs finger-level contact rewards to encourage grasps that leave fingers available for a subsequent distinct subtask (e.g., pushing, pulling, or pressing an object). The method uses curriculum-based policy learning to select such grasps, is evaluated on the new HANDFUL-Bench simulation benchmark across multiple second-subtask objectives, and is validated on a real LEAP hand. The central empirical claim is that resource-aware grasps improve second-subtask success and robustness relative to a greedy baseline that optimizes only the initial grasp.
Significance. If the results hold under matched conditions, the work would usefully highlight resource awareness as a design principle for multifunctional dexterous manipulation, moving beyond single-skill tasks. The HANDFUL-Bench benchmark and the real-robot demonstration are concrete contributions that could support follow-on research. The approach is entirely empirical (RL with hand-crafted rewards and curriculum), so it does not offer parameter-free derivations or machine-checked proofs, but the reproducible experimental setup on a public benchmark is a positive feature.
major comments (3)
- [Results / baseline description] Results section (baseline comparison): The abstract and methods describe the greedy baseline only at a high level as one that 'greedily optimizes the initial grasp.' It is not stated whether this baseline uses the identical policy architecture, action space, curriculum stage thresholds, and exploration noise schedule as HANDFUL. Without this matching, the reported gains in second-subtask success cannot be unambiguously attributed to the finger-level contact rewards rather than differences in the overall learning procedure.
- [Methods / reward and curriculum] Methods (reward formulation): The finger contact reward scales and curriculum stage thresholds are listed as free parameters. The central claim that these rewards produce grasps preserving both stability and finger availability rests on the empirical outcomes; however, no ablation is described that varies these scales while holding all other components fixed, leaving open whether the reported robustness is sensitive to hyperparameter choice.
- [Experiments / real-robot] Real-robot validation paragraph: The abstract states that the approach is validated on a physical LEAP hand, yet no quantitative details (number of trials, success metric definitions, or sim-to-real transfer protocol) are provided in the summary. This information is load-bearing for the robustness claim that extends beyond simulation.
minor comments (2)
- [Abstract] The abstract refers to 'secondsubtask' without a hyphen or space; consistent hyphenation should be used throughout.
- [Figures and tables] Figure captions and table headers should explicitly state the number of random seeds and total episodes used for each reported success rate to allow readers to assess statistical reliability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, clarifying our approach and committing to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Results / baseline description] Results section (baseline comparison): The abstract and methods describe the greedy baseline only at a high level as one that 'greedily optimizes the initial grasp.' It is not stated whether this baseline uses the identical policy architecture, action space, curriculum stage thresholds, and exploration noise schedule as HANDFUL. Without this matching, the reported gains in second-subtask success cannot be unambiguously attributed to the finger-level contact rewards rather than differences in the overall learning procedure.
Authors: We agree that explicit matching details are necessary to isolate the contribution of the finger-level contact rewards. In the revised manuscript, we will expand the Methods and Results sections to state that the greedy baseline employs exactly the same policy architecture, action space, curriculum stage thresholds, and exploration noise schedule as HANDFUL. The only difference is the absence of the finger contact reward term, so that performance differences can be attributed directly to resource-aware grasp selection. revision: yes
-
Referee: [Methods / reward and curriculum] Methods (reward formulation): The finger contact reward scales and curriculum stage thresholds are listed as free parameters. The central claim that these rewards produce grasps preserving both stability and finger availability rests on the empirical outcomes; however, no ablation is described that varies these scales while holding all other components fixed, leaving open whether the reported robustness is sensitive to hyperparameter choice.
Authors: We acknowledge that an ablation on the reward scales and curriculum thresholds would strengthen the robustness claim. We will add such an ablation study to the revised manuscript (or supplementary material), systematically varying these hyperparameters while keeping the policy architecture, curriculum structure, and other components fixed. This will show that the reported gains in second-subtask success and robustness hold across reasonable ranges of these parameters. revision: yes
-
Referee: [Experiments / real-robot] Real-robot validation paragraph: The abstract states that the approach is validated on a physical LEAP hand, yet no quantitative details (number of trials, success metric definitions, or sim-to-real transfer protocol) are provided in the summary. This information is load-bearing for the robustness claim that extends beyond simulation.
Authors: We will revise the real-robot validation section to include the requested quantitative details: the number of trials performed, precise definitions of the success metrics used, and a description of the sim-to-real transfer protocol (including any domain randomization or calibration steps). These additions will make the physical validation reproducible and directly support the robustness claims. revision: yes
Circularity Check
No significant circularity: empirical RL framework with independent validation
full rationale
The paper proposes HANDFUL as an RL-based framework using finger-level contact rewards to encourage resource-aware grasps, followed by curriculum policy learning and evaluation on HANDFUL-Bench. The central claims rest on simulation results comparing to a greedy baseline and real-robot validation, with no mathematical derivations, first-principles predictions, or fitted parameters presented as outputs. No self-citations, ansatzes, or renamings reduce the method to its inputs by construction; the approach is a standard empirical pipeline relying on external benchmarks and matched experimental conditions.
Axiom & Free-Parameter Ledger
free parameters (2)
- Finger contact reward scales
- Curriculum stage thresholds
axioms (2)
- domain assumption Simulation physics sufficiently approximates real dexterous hand dynamics for policy transfer
- domain assumption RL can jointly optimize grasp and downstream manipulation under shared finger constraints
Reference graph
Works this paper leans on
-
[1]
Dexart: Benchmarking generalizable dex- terous manipulation with articulated objects,
C. Bao, H. Xu, Y . Qin, and X. Wang, “Dexart: Benchmarking generalizable dex- terous manipulation with articulated objects,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[2]
Sequential dexterity: Chaining dexterous policies for long-horizon manipulation,
Y . Chen, C. Wang, L. Fei-Fei, and C. K. Liu, “Sequential dexterity: Chaining dexterous policies for long-horizon manipulation,” in Conference on Robot Learning (CoRL), 2023
2023
-
[3]
PyBullet, a Python Module for Physics Simulation for Games, Robotics and Machine Learning,
E. Coumans and Y . Bai, “PyBullet, a Python Module for Physics Simulation for Games, Robotics and Machine Learning,” 2016–2020
2016
-
[4]
Mogrip: Gripper for multiobject grasping in pick-and-place tasks using translational movements of fingers,
J. Eom, S. Y . Yu, W. Kim, C. Park, K. Y . Lee, and K.-J. Cho, “Mogrip: Gripper for multiobject grasping in pick-and-place tasks using translational movements of fingers,” Science Robotics, 2024
2024
-
[5]
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,
T. Haarnoja, A. Zhou, P. Abbeel, and S. Levine, “Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor,” in International Conference on Machine Learning (ICML), 2018
2018
-
[6]
Sequential multi-object grasping with one dexterous hand,
S. He, Z. Shangguan, K. Wang, Y . Gu, Y . Fu, Y . Fu, and D. Seita, “Sequential multi-object grasping with one dexterous hand,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2025
2025
-
[7]
RLBench: The Robot Learning Benchmark & Learning Environment,
S. James, Z. Ma, D. Rovick Arrojo, and A. J. Davison, “RLBench: The Robot Learning Benchmark & Learning Environment,” in IEEE Robotics and Automation Letters (RA-L), 2020
2020
-
[8]
Learning to Singulate Objects in Packed Environments using a Dexterous Hand,
H. Jiang, Y . Wang, H. Zhou, and D. Seita, “Learning to Singulate Objects in Packed Environments using a Dexterous Hand,” in International Symposium on Robotics Research (ISRR), 2024
2024
-
[9]
Learning Geometry-Aware Non- prehensile Pushing and Pulling with Dexterous Hands,
Y . Li, Y . Ling, G. S. Sukhatme, and D. Seita, “Learning Geometry-Aware Non- prehensile Pushing and Pulling with Dexterous Hands,” in IEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[10]
Grasp multiple objects with one hand,
Y . Li, B. Liu, Y . Geng, P. Li, Y . Yang, Y . Zhu, T. Liu, and S. Huang, “Grasp multiple objects with one hand,” in IEEE Robotics and Automation Letters (RA-L), 2024
2024
-
[11]
SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation,
X. Lin, Y . Wang, J. Olkin, and D. Held, “SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation,” in Conference on Robot Learning (CoRL), 2020
2020
-
[12]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning,
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone, “LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning,” in Neural Information Processing Systems, 2023
2023
-
[13]
Deep differentiable grasp planner for high-dof grippers,
M. Liu, Z. Pan, K. Xu, K. Ganguly, and D. Manocha, “Deep differentiable grasp planner for high-dof grippers,” in Robotics: Science and Systems (RSS), 2020
2020
-
[14]
Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure estimator,
T. Liu, Z. Liu, Z. Jiao, Y . Zhu, and S.-C. Zhu, “Synthesizing diverse and physically stable grasps with arbitrary hand structures using differentiable force closure estimator,” in IEEE Robotics and Automation Letters (RA-L), 2022
2022
-
[15]
Grasping a handful: Sequential multi-object dexterous grasp generation,
H. Lu, Y . Dong, Z. Weng, F. T. Pokorny, J. Lundell, and D. Kragic, “Grasping a handful: Sequential multi-object dexterous grasp generation,” in IEEE Robotics and Automation Letters (RA-L), 2025
2025
-
[16]
Get a grip: Multi-finger grasp evaluation at scale enables robust sim-to-real transfer,
T. G. W. Lum, A. H. Li, P. Culbertson, K. Srinivasan, A. D. Ames, M. Schwager, and J. Bohg, “Get a grip: Multi-finger grasp evaluation at scale enables robust sim-to-real transfer,” in Conference on Robot Learning (CoRL), 2024
2024
-
[17]
Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning
V . Makoviychuk, L. Wawrzyniak, Y . Guo, M. Lu, K. Storey, M. Macklin, D. Hoeller, N. Rudin, A. Allshire, A. Handa, and G. State, “Isaac Gym: High Performance GPU-Based Physics Simulation For Robot Learning,” arXiv preprint arXiv:2108.10470, 2021
work page internal anchor Pith review arXiv 2021
-
[18]
Isaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
M. Mittal, P. Roth, J. Tigue, A. Richard et al., “Isaac Lab: A GPU- Accelerated Simulation Framework for Multi-Modal Robot Learning,” arXiv preprint arXiv:2511.04831, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots,
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Man- dlekar, and Y . Zhu, “RoboCasa: Large-Scale Simulation of Everyday Tasks for Generalist Robots,” in Robotics: Science and Systems (RSS), 2024
2024
-
[20]
Solving Rubik's Cube with a Robot Hand
OpenAI, I. Akkaya, M. Andrychowicz, M. Chociej, M. Litwin, B. McGrew, A. Petron, A. Paino, M. Plappert, G. Powell, R. Ribas, J. Schneider, N. Tezak, J. Tworek, P. Welinder, L. Weng, Q. Yuan, W. Zaremba, and L. Zhang, “Solving rubik’s cube with a robot hand,” arXiv preprint arXiv:1910.07113, 2019
work page internal anchor Pith review arXiv 1910
-
[21]
In-Hand Object Rotation via Rapid Motor Adaptation,
H. Qi, A. Kumar, R. Calandra, Y . Ma, and J. Malik, “In-Hand Object Rotation via Rapid Motor Adaptation,” in Conference on Robot Learning (CoRL), 2022
2022
-
[22]
General In-Hand Object Rotation with Vision and Touch,
H. Qi, B. Yi, S. Suresh, M. Lambeta, Y . Ma, R. Calandra, and J. Malik, “General In-Hand Object Rotation with Vision and Touch,” in Conference on Robot Learning (CoRL), 2023
2023
-
[23]
DexPoint: Generalizable Point Cloud Reinforcement Learning for Sim-to-Real Dexterous Manipulation,
Y . Qin, B. Huang, Z.-H. Yin, H. Su, and X. Wang, “DexPoint: Generalizable Point Cloud Reinforcement Learning for Sim-to-Real Dexterous Manipulation,” in Conference on Robot Learning (CoRL), 2022
2022
-
[24]
SAM 2: Segment Anything in Images and Videos
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. R ¨adle, C. Rolland, L. Gustafson, E. Mintun, J. Pan, K. V . Alwala, N. Carion, C.-Y . Wu, R. Girshick, P. Doll ´ar, and C. Feichtenhofer, “SAM 2: Segment Anything in Images and Videos,” arXiv preprint arXiv:2408.00714, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
In-Hand Dexterous Manipulation of Piecewise-Smooth 3-D Objects,
D. Rus, “In-Hand Dexterous Manipulation of Piecewise-Smooth 3-D Objects,” in International Journal of Robotics Research (IJRR), 1999
1999
-
[26]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal Policy Optimization Algorithms,” arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[27]
Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks,
D. Seita, P. Florence, J. Tompson, E. Coumans, V . Sindhwani, K. Goldberg, and A. Zeng, “Learning to Rearrange Deformable Cables, Fabrics, and Bags with Goal-Conditioned Transporter Networks,” in IEEE International Conference on Robotics and Automation (ICRA), 2021
2021
-
[28]
Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning,
K. Shaw, A. Agarwal, and D. Pathak, “Leap hand: Low-cost, efficient, and anthropomorphic hand for robot learning,” in Robotics: Science and Systems (RSS), 2023
2023
-
[29]
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T. kai Chan, Y . Gao, X. Li, T. Mu, N. Xiao, A. Gurha, Z. Huang, R. Calandra, R. Chen, S. Luo, and H. Su, “ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI,” arXiv preprint arXiv:2410.00425, 2024
-
[30]
MuJoCo: A Physics Engine for Model- Based Control,
E. Todorov, T. Erez, and Y . Tassa, “MuJoCo: A Physics Engine for Model- Based Control,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2012
2012
-
[31]
DexCap: Scal- able and Portable Mocap Data Collection System for Dexterous Manipulation,
C. Wang, H. Shi, W. Wang, R. Zhang, L. Fei-Fei, and C. K. Liu, “DexCap: Scal- able and Portable Mocap Data Collection System for Dexterous Manipulation,” in Robotics: Science and Systems (RSS), 2024
2024
-
[32]
Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation,
R. Wang, J. Zhang, J. Chen, Y . Xu, P. Li, T. Liu, and H. Wang, “Dexgraspnet: A large-scale robotic dexterous grasp dataset for general objects based on simulation,” in IEEE International Conference on Robotics and Automation (ICRA), 2023
2023
-
[33]
SAPIEN: A SimulAted Part-based Interactive ENvironment,
F. Xiang, Y . Qin, K. Mo, Y . Xia, H. Zhu, F. Liu, M. Liu, H. Jiang, Y . Yuan, H. Wang, L. Yi, A. X. Chang, L. J. Guibas, and H. Su, “SAPIEN: A SimulAted Part-based Interactive ENvironment,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[34]
Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy,
Y . Xu, W. Wan, J. Zhang, H. Liu, Z. Shan, H. Shen, R. Wang, H. Geng, Y . Weng, J. Chen et al., “Unidexgrasp: Universal robotic dexterous grasping via learning diverse proposal generation and goal-conditioned policy,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2023
2023
-
[35]
Static grasp stability analysis of multiple spatial objects,
T. Yamada and H. Yamamoto, “Static grasp stability analysis of multiple spatial objects,” Journal of Control Science and Engineering, vol. 3, 2015
2015
-
[36]
Exploiting kinematic redundancy for robotic grasping of multiple objects,
K. Yao and A. Billard, “Exploiting kinematic redundancy for robotic grasping of multiple objects,” in IEEE Transactions on Robotics, 2023
2023
-
[37]
Rotating without Seeing: Towards In-hand Dexterity through Touch,
Z.-H. Yin, B. Huang, Y . Qin, Q. Chen, and X. Wang, “Rotating without Seeing: Towards In-hand Dexterity through Touch,” in Robotics: Science and Systems (RSS), 2023
2023
-
[38]
Optimization of power grasps for multiple objects,
T. Yoshikawa, T. Watanabe, and M. Daito, “Optimization of power grasps for multiple objects,” inIEEE International Conference on Robotics and Automation (ICRA), 2001
2001
-
[39]
Computation of grasp internal forces for stably grasping multiple objects,
Y . Yu, K. Fukuda, and S. Tsujio, “Computation of grasp internal forces for stably grasping multiple objects,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2001
2001
-
[40]
MuJoCo Playground,
K. Zakka, B. Tabanpour, Q. Liao, M. Haiderbhai, S. Holt, J. Y . Luo, A. Allshire, E. Frey, K. Sreenath, L. A. Kahrs, C. Sferrazza, Y . Tassa, and P. Abbeel, “MuJoCo Playground,” in Robotics: Science and Systems (RSS), 2025
2025
-
[41]
MuJoCo Menagerie: A collection of high-quality simulation models for MuJoCo,
K. Zakka, Y . Tassa, and MuJoCo Menagerie Contributors, “MuJoCo Menagerie: A collection of high-quality simulation models for MuJoCo,” 2022
2022
-
[42]
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations,
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu, “3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations,” in Robotics: Science and Systems (RSS), 2024
2024
-
[43]
DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes,
J. Zhang, H. Liu, D. Li, X. Yu, H. Geng, Y . Ding, J. Chen, and H. Wang, “DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes,” in Conference on Robot Learning (CoRL), 2024
2024
-
[44]
robosuite: A Modular Simulation Framework and Benchmark for Robot Learning
Y . Zhu, J. Wong, A. Mandlekar, R. Mart ´ın-Mart´ın, A. Joshi, S. Nasiriany, and Y . Zhu, “robosuite: A Modular Simulation Framework and Benchmark for Robot Learning,” in arXiv preprint arXiv:2009.12293, 2020. XI. APPENDIX A. Candidate Grasp Selection V alidation on All Tasks We extend the case study from Section VI-C.3 to all tasks. Table V and Table VI ...
work page internal anchor Pith review arXiv 2009
-
[45]
Predictivity of Early Curriculum Stages:The pat- tern observed forPick Secondin the main paper holds broadly across tasks. The top-performing candidates in the final curriculum stage consistently rank among the leaders in earlier stages, confirming that early performance is a reliable signal for grasp selection. Early curriculum stages seem more predictiv...
-
[46]
The best-performing candidate grasp is never prematurely eliminated in any seed of any task, and the second and third-best candidates are often retained
Selection Stability Across Seeds:Selection stability is similarly strong across tasks. The best-performing candidate grasp is never prematurely eliminated in any seed of any task, and the second and third-best candidates are often retained. As inPick Second, there is some volatility in selecting these second and third-best grasps, but the impact is minor ...
-
[47]
In our experi- ments, candidates such asπ 1 andπ 8 perform strongly across nearly all tasks, which may reflect broad task compatibility, high grasp stability in this seed, or both
Limitations:Because we train only a single grasping seed per candidate strategy, it is difficult to cleanly attribute each grasp’s second-subtask performance to its intrinsic task suitability versus the stability of that particular grasp instance (which may vary with the training seed). In our experi- ments, candidates such asπ 1 andπ 8 perform strongly a...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.