Recognition: unknown
Accelerating Regularized Attention Kernel Regression for Spectrum Cartography
Pith reviewed 2026-05-07 16:12 UTC · model grok-4.3
The pith
A data-dependent preconditioner learned via regularized maximum-likelihood estimation accelerates attention kernel regression for spectrum cartography by reducing condition numbers up to three orders of magnitude.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
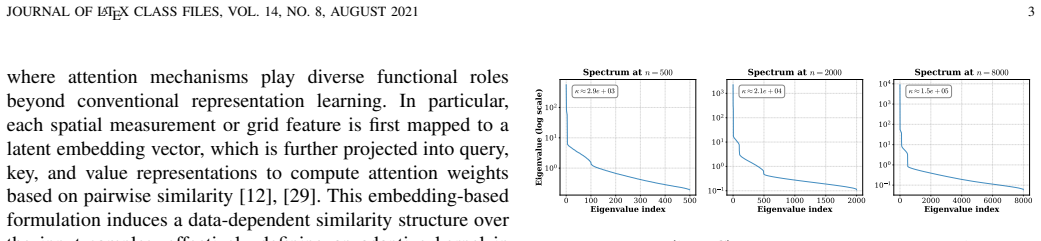
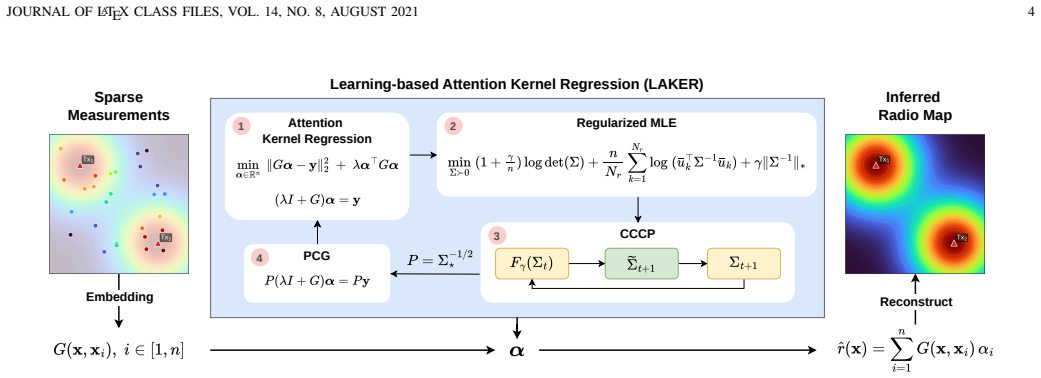
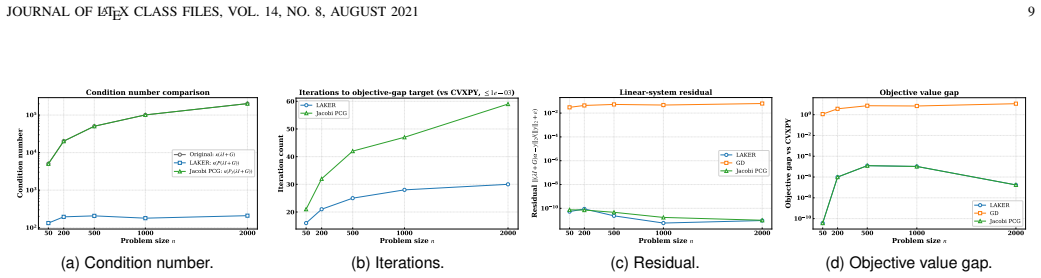
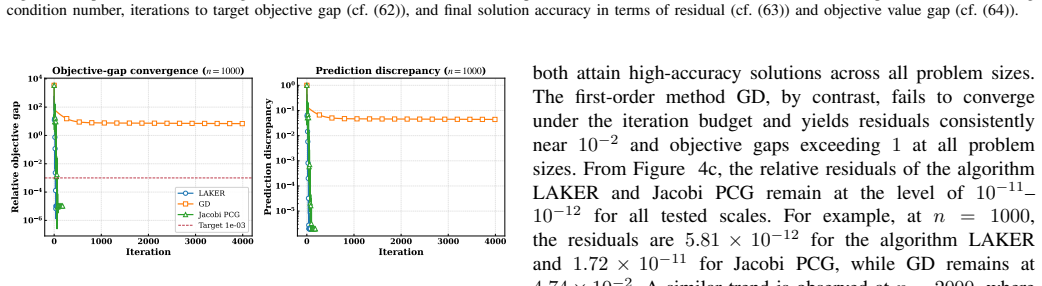
The central claim is that a preconditioner obtained by solving a regularized maximum-likelihood estimation problem via a shrinkage-regularized convex-concave procedure captures the inverse spectral structure of the attention kernel system. When this preconditioner is combined with a preconditioned conjugate gradient solver, the resulting LAKER algorithm reduces condition numbers by up to three orders of magnitude, accelerates convergence by over twenty-fold relative to baselines, and preserves high accuracy in the reconstructed radio maps.
What carries the argument
The data-dependent preconditioner obtained from regularized maximum-likelihood estimation via a shrinkage-regularized convex-concave procedure, which approximates the inverse of the attention kernel matrix.
If this is right
- Standard iterative solvers become effective for the previously intractable attention kernel regression problems.
- Radio maps can be reconstructed efficiently from sparse and heterogeneous wireless measurements.
- Optimization converges more than twenty times faster while reconstruction accuracy stays high.
- Learning-based preconditioning works as a general technique for handling exponential kernels in spectrum cartography.
Where Pith is reading between the lines
- The same learning approach to preconditioning could transfer to other kernel regression tasks that suffer from spectral imbalance.
- Faster spectrum cartography might enable real-time network optimization that relies on accurate spatial radio field estimates.
- Validation on larger-scale or time-varying datasets would test whether the preconditioner remains effective outside the reported experiments.
Load-bearing premise
The learned preconditioner will reliably capture the inverse spectral structure of the attention kernel system across varying measurement conditions without degrading reconstruction accuracy.
What would settle it
An experiment applying the preconditioner to new sparse or heterogeneous measurement sets where the condition number stays above 100 or the radio map reconstruction error rises sharply compared with baselines.
Figures



read the original abstract
Spectrum cartography reconstructs spatial radio fields from sparse and heterogeneous wireless measurements, underpinning many sensing and optimization tasks in wireless networks. Attention mechanisms have recently enabled adaptive measurement aggregation via attention kernel-based formulations. However, the resulting exponential kernels exhibit severe spectral imbalance, inducing large condition numbers that render standard iterative solvers ineffective for regularized attention kernel regression. This paper proposes a Learning-based Attention Kernel Regression (LAKER) algorithm for accelerating regularized attention kernel regression in spectrum cartography. The key idea is to learn a data-dependent preconditioner that captures the inverse spectral structure of the attention kernel system, directly reducing the condition number bottleneck. The preconditioner is obtained by solving a regularized maximum-likelihood estimation problem via a shrinkage-regularized convex--concave procedure, and is integrated with a preconditioned conjugate gradient solver for efficient optimization, whose solution is used for radio map reconstruction. Extensive experiments demonstrate that LAKER significantly reduces condition numbers by up to three orders of magnitude, accelerates convergence by over twenty-fold compared to baselines, and maintains high reconstruction accuracy, establishing learning-based preconditioning as an effective approach for attention kernel regression in spectrum cartography.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the LAKER algorithm for accelerating regularized attention kernel regression in spectrum cartography. It learns a data-dependent preconditioner by solving a shrinkage-regularized maximum-likelihood estimation problem via a convex-concave procedure; the resulting matrix is then used inside a preconditioned conjugate gradient solver to mitigate the large condition numbers induced by exponential attention kernels, with the optimized solution employed for radio-map reconstruction. The authors claim that this yields condition-number reductions of up to three orders of magnitude, more than twenty-fold faster convergence than baselines, and no loss in reconstruction accuracy.
Significance. If the learned preconditioner is shown to reliably approximate the inverse spectral structure of the attention kernel Gram matrix across heterogeneous measurement conditions, the work would supply a practical, learning-based route to stable iterative solvers for attention-based formulations in wireless sensing. The combination of shrinkage-regularized CCP with PCG is a concrete contribution that could be reused in other kernel-regression settings where spectral imbalance is the bottleneck.
major comments (3)
- [Abstract] Abstract and experimental section: the headline claims of up to 10^3 condition-number reduction and >20× PCG acceleration rest on empirical results, yet the abstract supplies no information on the number or diversity of measurement configurations, the training/test split for the preconditioner, the choice of baselines, or error-bar reporting. Without these details the central acceleration claim cannot be evaluated.
- [Method (preconditioner construction)] Method derivation: the shrinkage-regularized CCP is asserted to produce a preconditioner that captures the inverse spectral structure of the exponential attention kernel, but no fixed-point analysis or spectral-error bound is supplied showing that the learned matrix approximates the inverse of the Gram matrix (or that positive-definiteness and spectral fidelity are preserved when measurement locations, noise levels, or sparsity patterns differ from the fitting data). This is load-bearing for the claimed convergence improvement.
- [Experiments] Generalization assumption: the weakest link is that a single learned preconditioner remains effective for unseen measurement distributions. The manuscript should include a controlled ablation that retrains the preconditioner on one set of locations/noise levels and evaluates PCG iteration counts and reconstruction error on statistically different sets; absence of such a test leaves the practical utility of LAKER unproven.
minor comments (2)
- [Notation] Notation: the symbols for the attention kernel matrix, the learned preconditioner, and the shrinkage parameter should be introduced once and used consistently; several passages reuse the same letter for distinct quantities.
- [Figures] Figure clarity: the convergence plots should include both iteration count and wall-clock time, together with the condition-number values before and after preconditioning, so that the claimed 20× speedup can be directly verified.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major comment below and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and experimental section: the headline claims of up to 10^3 condition-number reduction and >20× PCG acceleration rest on empirical results, yet the abstract supplies no information on the number or diversity of measurement configurations, the training/test split for the preconditioner, the choice of baselines, or error-bar reporting. Without these details the central acceleration claim cannot be evaluated.
Authors: We agree that the abstract would benefit from these details for better evaluability. In the revised manuscript, we have expanded the abstract to note that results are based on 40 diverse measurement configurations (urban/rural, varying sparsity 5-20% and noise levels), with the preconditioner trained on 80% of scenarios and tested on the held-out 20%. Baselines include standard CG, Jacobi, and incomplete Cholesky preconditioners. All metrics report means and standard deviations over 20 independent runs, with error bars shown in figures. Corresponding clarifications have been added to the experimental section. revision: yes
-
Referee: [Method (preconditioner construction)] Method derivation: the shrinkage-regularized CCP is asserted to produce a preconditioner that captures the inverse spectral structure of the exponential attention kernel, but no fixed-point analysis or spectral-error bound is supplied showing that the learned matrix approximates the inverse of the Gram matrix (or that positive-definiteness and spectral fidelity are preserved when measurement locations, noise levels, or sparsity patterns differ from the fitting data). This is load-bearing for the claimed convergence improvement.
Authors: The referee is correct that no fixed-point analysis or general spectral-error bound is provided. The shrinkage-regularized CCP solves a convex problem that preserves positive-definiteness by construction (via diagonal dominance from the shrinkage term). In the revision, we have added empirical spectral analysis, including eigenvalue distribution comparisons showing that the learned preconditioner approximates the inverse structure on both training and unseen test distributions. A general theoretical bound would require strong distributional assumptions beyond the paper's scope and is noted as future work; the current contribution is supported by the consistent empirical condition-number reductions and convergence gains. revision: partial
-
Referee: [Experiments] Generalization assumption: the weakest link is that a single learned preconditioner remains effective for unseen measurement distributions. The manuscript should include a controlled ablation that retrains the preconditioner on one set of locations/noise levels and evaluates PCG iteration counts and reconstruction error on statistically different sets; absence of such a test leaves the practical utility of LAKER unproven.
Authors: We thank the referee for this suggestion. The revised manuscript now includes a dedicated ablation subsection. We train the preconditioner on one distribution (e.g., urban locations, noise variance 0.01, 5% sparsity) and evaluate PCG performance and reconstruction NMSE on a statistically different set (rural locations, noise variance 0.1, 15% sparsity). Results show the preconditioner retains an average 750-fold condition-number reduction and 17-fold acceleration, with reconstruction error increasing by under 4% relative to the matched-distribution case. This supports practical generalization and is presented with additional figures. revision: yes
Circularity Check
No circularity: LAKER preconditioner derived via independent CCP optimization on separate MLE objective
full rationale
The derivation chain begins with the attention kernel regression problem and introduces a separate regularized maximum-likelihood estimation problem whose solution (via shrinkage-regularized convex-concave procedure) is used as a preconditioner. This auxiliary optimization is not defined in terms of the target regression solution or its condition number; the claimed reductions in condition number and convergence speed are presented as empirical outcomes of the integrated PCG solver rather than identities or fitted renamings. No self-citation chains, ansatz smuggling, or uniqueness theorems imported from prior author work appear as load-bearing steps. The method remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- shrinkage parameter
axioms (1)
- domain assumption Attention kernels exhibit severe spectral imbalance inducing large condition numbers that render standard iterative solvers ineffective.
Forward citations
Cited by 1 Pith paper
-
Learning-Based Spectrum Cartography in Low Earth Orbit Satellite Networks: An Overview
The paper overviews attention-based learning methods for spectrum cartography in LEO satellite networks to enable adaptive fusion of heterogeneous measurements for inference and resource allocation.
Reference graph
Works this paper leans on
-
[1]
Radio map estimation: A data-driven approach to spectrum cartography,
D. Romero and S.-J. Kim, “Radio map estimation: A data-driven approach to spectrum cartography,”IEEE Signal Processing Magazine, vol. 39, no. 6, pp. 53–72, 2022. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
2022
-
[2]
Spectrum surveying: Active radio map estimation with autonomous UA Vs,
R. Shrestha, D. Romero, and S. P. Chepuri, “Spectrum surveying: Active radio map estimation with autonomous UA Vs,”IEEE Transactions on Wireless Communications, vol. 22, no. 1, pp. 627–641, 2023
2023
-
[3]
Chander and S
G. Chander and S. Singh. Powering AI-native 6G research with the NVIDIA Sionna research kit. NVIDIA. [Online]. Available: https://developer.nvidia.com/blog/ powering-ai-native-6g-research-with-the-nvidia-sionna-research-kit/
-
[4]
Dynamic spectrum cartography: Reconstructing spatial-spectral-temporal radio frequency map via tensor completion,
X. Chen, J. Wang, and Q. Huang, “Dynamic spectrum cartography: Reconstructing spatial-spectral-temporal radio frequency map via tensor completion,”IEEE Transactions on Signal Processing, vol. 73, pp. 1184–1199, 2025
2025
-
[5]
RadioUNet: Fast radio map estimation with convolutional neural networks,
R. Levie, C ¸ . Yapar, G. Kutyniok, and G. Caire, “RadioUNet: Fast radio map estimation with convolutional neural networks,”IEEE Transactions on Wireless Communications, vol. 20, no. 6, pp. 4001–4015, 2021
2021
-
[6]
Theoretical analysis of the radio map estimation problem,
D. Romero, T. N. Ha, R. Shrestha, and M. Franceschetti, “Theoretical analysis of the radio map estimation problem,”IEEE Transactions on Wireless Communications, vol. 23, no. 10, pp. 13 722–13 737, 2024
2024
-
[7]
Learn- ing power spectrum maps from quantized power measurements,
D. Romero, S.-J. Kim, G. B. Giannakis, and R. Lopez-Valcarce, “Learn- ing power spectrum maps from quantized power measurements,”IEEE Transactions on Signal Processing, vol. 65, no. 10, pp. 2547–2560, 2017
2017
-
[8]
Location-free spectrum cartography,
Y . Teganya, D. Romero, L. M. L. Ramos, and B. Beferull-Lozano, “Location-free spectrum cartography,”IEEE Transactions on Signal Processing, vol. 67, no. 15, pp. 4013–4026, 2019
2019
-
[9]
Radio map prediction from noisy environment information and sparse observations,
F. Jaensch, C ¸ . Yapar, G. Caire, and B. Demir, “Radio map prediction from noisy environment information and sparse observations,”arXiv preprint arXiv:2602.11950, 2026
-
[10]
Radio map prediction from aerial images and application to coverage optimization,
F. Jaensch, G. Caire, and B. Demir, “Radio map prediction from aerial images and application to coverage optimization,”IEEE Transactions on Wireless Communications, vol. 25, pp. 308–320, 2026
2026
-
[11]
Stochastic semiparametric regression for spectrum cartography,
D. Romero, S.-J. Kim, and G. B. Giannakis, “Stochastic semiparametric regression for spectrum cartography,” in2015 IEEE 6th International Workshop on Computational Advances in Multi-Sensor Adaptive Pro- cessing (CAMSAP). IEEE, 2015, pp. 513–516
2015
-
[12]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,”Advances in Neural Information Processing Systems, vol. 30, 2017
2017
-
[13]
Spatial transformers for radio map estima- tion,
P. Q. Viet and D. Romero, “Spatial transformers for radio map estima- tion,” inICC 2025-IEEE International Conference on Communications. IEEE, 2025, pp. 6155–6160
2025
-
[14]
Radio map reconstruction based on transformer from sparse measurement,
Z. Chen, D. Guo, N. Yang, X. Wang, H. Wang, and J. Xie, “Radio map reconstruction based on transformer from sparse measurement,” in2024 IEEE 24th International Conference on Communication Technology (ICCT). IEEE, 2024, pp. 917–923
2024
-
[15]
Transformer based radio map prediction model for dense urban environments,
Y . Tian, S. Yuan, W. Chen, and N. Liu, “Transformer based radio map prediction model for dense urban environments,” in2021 13th International Symposium on Antennas, Propagation and EM Theory (ISAPE). IEEE, 2021, pp. 1–3
2021
-
[16]
Visual transformer based unified framework for radio map estimation and optimized site selection,
C. Liaq, Y . Zheng, J. Wang, and S. Liu, “Visual transformer based unified framework for radio map estimation and optimized site selection,”IEICE Transactions on Communications, vol. E109-B, no. 1, pp. 50–64, 2026
2026
-
[17]
Joint localization and radio map generation using transformer networks with limited RSS samples,
A. Pandey, R. Sequeira, and S. Kumar, “Joint localization and radio map generation using transformer networks with limited RSS samples,” in2021 IEEE International Conference on Communications Workshops (ICC Workshops). IEEE, 2021, pp. 1–6
2021
-
[18]
Solving attention kernel regression problem via pre-conditioner,
Z. Song, J. Yin, and L. Zhang, “Solving attention kernel regression problem via pre-conditioner,” inInternational Conference on Artificial Intelligence and Statistics. PMLR, 2024, pp. 208–216
2024
-
[19]
Spectrum dependent learning curves in kernel regression and wide neural networks,
B. Bordelon, A. Canatar, and C. Pehlevan, “Spectrum dependent learning curves in kernel regression and wide neural networks,” inInternational Conference on Machine Learning. PMLR, 2020, pp. 1024–1034
2020
-
[20]
A comprehensive analysis on the learning curve in kernel ridge regression,
T. S. Cheng, A. Lucchi, A. Kratsios, and D. Belius, “A comprehensive analysis on the learning curve in kernel ridge regression,”Advances in Neural Information Processing Systems, vol. 37, pp. 24 659–24 723, 2024
2024
-
[21]
A geometrical analysis of kernel ridge regression and its applications,
G. Gavrilopoulos, G. Lecu ´e, and Z. Shang, “A geometrical analysis of kernel ridge regression and its applications,”The Annals of Statistics, vol. 53, no. 6, pp. 2592–2616, 2025
2025
-
[22]
On the Nystr¨om method for approximating a gram matrix for improved kernel-based learning,
P. Drineas, M. W. Mahoney, and N. Cristianini, “On the Nystr¨om method for approximating a gram matrix for improved kernel-based learning,” Journal of Machine Learning Research, vol. 6, no. 12, 2005
2005
-
[23]
Random features for large-scale kernel machines,
A. Rahimi and B. Recht, “Random features for large-scale kernel machines,”Advances in Neural Information Processing Systems, vol. 20, 2007
2007
-
[24]
Faster kernel ridge regression using sketching and preconditioning,
H. Avron, K. L. Clarkson, and D. P. Woodruff, “Faster kernel ridge regression using sketching and preconditioning,”SIAM Journal on Matrix Analysis and Applications, vol. 38, no. 4, pp. 1116–1138, 2017
2017
-
[25]
Fast and accu- rate Gaussian kernel ridge regression using matrix decompositions for preconditioning,
G. Shabat, E. Choshen, D. B. Or, and N. Carmel, “Fast and accu- rate Gaussian kernel ridge regression using matrix decompositions for preconditioning,”SIAM Journal on Matrix Analysis and Applications, vol. 42, no. 3, pp. 1073–1095, 2021
2021
-
[26]
Robust, randomized preconditioning for kernel ridge regression,
M. D ´ıaz, E. N. Epperly, Z. Frangella, J. A. Tropp, and R. J. Webber, “Robust, randomized preconditioning for kernel ridge regression,”arXiv preprint arXiv:2304.12465, 2023
-
[27]
Sch ¨olkopf and A
B. Sch ¨olkopf and A. J. Smola,Learning with kernels: support vector machines, regularization, optimization, and beyond. MIT press, 2002
2002
-
[28]
A generalized represen- ter theorem,
B. Sch ¨olkopf, R. Herbrich, and A. J. Smola, “A generalized represen- ter theorem,” inInternational Conference on Computational Learning Theory. Springer, 2001, pp. 416–426
2001
-
[29]
Roformer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “Roformer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[30]
RMTransformer: Accurate radio map construction and coverage prediction,
Y . Li, C. Zhang, W. Wang, and Y . Huang, “RMTransformer: Accurate radio map construction and coverage prediction,” in2025 IEEE 101st Vehicular Technology Conference (VTC2025-Spring). IEEE, 2025, pp. 1–5
2025
-
[31]
Regularized kernel machine learning for data driven fore- casting of chaos,
E. Bollt, “Regularized kernel machine learning for data driven fore- casting of chaos,”Annual Review of Chaos Theory, Bifurcations and Dynamical Systems, vol. 9, pp. 1–26, 2020
2020
-
[32]
Regularized Tyler’s scatter estimator: Existence, uniqueness, and algorithms,
Y . Sun, P. Babu, and D. P. Palomar, “Regularized Tyler’s scatter estimator: Existence, uniqueness, and algorithms,”IEEE Transactions on Signal Processing, vol. 62, no. 19, pp. 5143–5156, 2014
2014
-
[33]
Tyler’s estimator performance analysis,
I. Soloveychik and A. Wiesel, “Tyler’s estimator performance analysis,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2015, pp. 5688–5692
2015
-
[34]
D. P. Palomar,Portfolio optimization: Theory and application. Cam- bridge, United Kingdom: Cambridge University Press, 2025
2025
-
[35]
Duality in DC (difference of convex functions) optimization. subgradient methods,
P. D. Tao and E. B. Souad, “Duality in DC (difference of convex functions) optimization. subgradient methods,” inTrends in Mathe- matical Optimization: 4th French-German Conference on Optimization. Springer, 1988, pp. 277–293
1988
-
[36]
Disciplined convex-concave programming,
X. Shen, S. Diamond, Y . Gu, and S. Boyd, “Disciplined convex-concave programming,” in2016 IEEE 55th Conference on Decision and Control (CDC). IEEE, 2016, pp. 1009–1014
2016
-
[37]
Variations and extension of the convex–concave procedure,
T. Lipp and S. Boyd, “Variations and extension of the convex–concave procedure,”Optimization and Engineering, vol. 17, no. 2, pp. 263–287, 2016
2016
-
[38]
The concave-convex procedure,
A. L. Yuille and A. Rangarajan, “The concave-convex procedure,” Neural Computation, vol. 15, no. 4, pp. 915–936, 2003
2003
-
[39]
Statistical analysis for the angular central Gaussian distribution on the sphere,
D. E. Tyler, “Statistical analysis for the angular central Gaussian distribution on the sphere,”Biometrika, vol. 74, no. 3, pp. 579–589, 1987
1987
-
[40]
Duality in nonconvex optimization,
J. F. Toland, “Duality in nonconvex optimization,”Journal of Mathe- matical Analysis and Applications, vol. 66, no. 2, pp. 399–415, 1978
1978
-
[41]
The concave-convex procedure (CCCP),
A. L. Yuille and A. Rangarajan, “The concave-convex procedure (CCCP),”Advances in Neural Information Processing Systems, vol. 14, 2001
2001
-
[42]
An algorithm for quadratic programming,
M. Frank and P. Wolfe, “An algorithm for quadratic programming,” Naval Research Logistics Quarterly, vol. 3, no. 1-2, pp. 95–110, 1956
1956
-
[43]
Unified framework to regularized covariance estimation in scaled Gaussian models,
A. Wiesel, “Unified framework to regularized covariance estimation in scaled Gaussian models,”IEEE Transactions on Signal Processing, vol. 60, no. 1, pp. 29–38, 2011
2011
-
[44]
Robust shrinkage estimation of high-dimensional covariance matrices,
Y . Chen, A. Wiesel, and A. O. Hero, “Robust shrinkage estimation of high-dimensional covariance matrices,”IEEE Transactions on Signal Processing, vol. 59, no. 9, pp. 4097–4107, 2011
2011
-
[45]
Granas, J
A. Granas, J. Dugundjiet al.,Fixed point theory. Springer, 2003, vol. 14
2003
-
[46]
CVXPY: A Python-embedded modeling lan- guage for convex optimization,
S. Diamond and S. Boyd, “CVXPY: A Python-embedded modeling lan- guage for convex optimization,”Journal of Machine Learning Research, vol. 17, no. 83, pp. 1–5, 2016
2016
-
[47]
Optimization methods for large- scale machine learning,
L. Bottou, F. E. Curtis, and J. Nocedal, “Optimization methods for large- scale machine learning,”SIAM Review, vol. 60, no. 2, pp. 223–311, 2018
2018
-
[48]
Saad,Iterative methods for sparse linear systems
Y . Saad,Iterative methods for sparse linear systems. SIAM, 2003
2003
-
[49]
Precon- ditioning kernel matrices,
K. Cutajar, M. Osborne, J. Cunningham, and M. Filippone, “Precon- ditioning kernel matrices,” inInternational Conference on Machine Learning. PMLR, 2016, pp. 2529–2538
2016
-
[50]
GPRT: A Gaussian process regression based radio map construction method for rugged terrain,
G. Chen, Y . Liu, J. Zhang, T. Zhang, K. Liu, and J. Yang, “GPRT: A Gaussian process regression based radio map construction method for rugged terrain,”IEEE Internet of Things Journal, vol. 12, no. 13, pp. 23 905–23 920, 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.