Recognition: unknown
Cutscene Agent: An LLM Agent Framework for Automated 3D Cutscene Generation
Pith reviewed 2026-05-07 13:54 UTC · model grok-4.3
The pith
An LLM agent framework automates end-to-end 3D cutscene generation by linking agents bidirectionally to a game engine and coordinating specialist subagents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cutscene Agent is an LLM agent framework for automated end-to-end cutscene generation. It rests on three elements: a toolkit that gives agents two-way access to the game engine so they can both call operations and observe real-time scene state; a multi-agent setup in which a director coordinates subagents for animation, cinematography, and sound design and applies visual reasoning feedback for iterative improvement; and CutsceneBench, a hierarchical benchmark that measures success on long-horizon sequences of interdependent tool calls rather than isolated actions.
What carries the argument
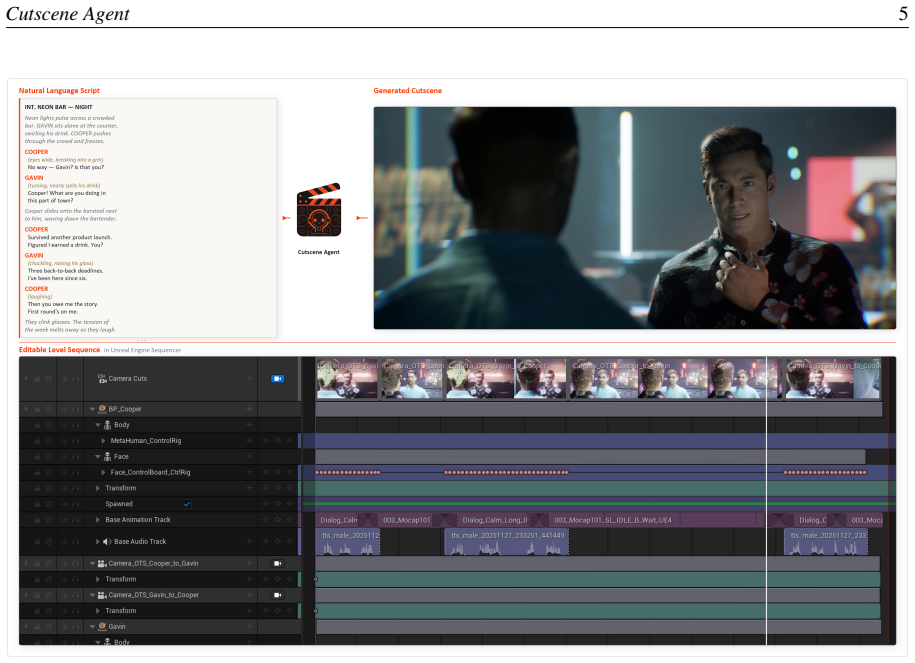
The Cutscene Toolkit on the Model Context Protocol, which creates bidirectional integration so LLM agents can invoke engine functions and continuously receive real-time scene state for closed-loop control.
If this is right
- Generated cutscenes remain native engine assets that stay editable after creation.
- The framework tests LLM performance on tasks requiring dozens of coordinated steps rather than single tool calls.
- Visual reasoning feedback lets agents perceive rendered scenes and adjust them without external guidance.
- CutsceneBench provides a standardized way to compare models on long-horizon cinematic planning.
- Different LLMs exhibit measurable differences in handling the ordering and dependency constraints of cutscene production.
Where Pith is reading between the lines
- The same bidirectional engine link could support on-the-fly generation of player-driven story moments during gameplay.
- CutsceneBench may become useful for evaluating planning skills in other domains that involve sequential physical actions, such as robotics or virtual production.
- Small development teams could use the system to prototype narrative sequences early in design without hiring full cinematic crews.
- Extending the multi-agent structure with additional specialists might allow automation of related tasks like dialogue timing or lighting setup.
Load-bearing premise
LLM agents can reliably perform long-horizon orchestration of dozens of interdependent tool invocations with strict ordering constraints inside a game engine.
What would settle it
Running the system on a complex cutscene script and checking whether the output follows the exact required sequence of animation, camera, and sound calls without human fixes or coherence breaks.
Figures






read the original abstract
Cutscenes are carefully choreographed cinematic sequences embedded in video games and interactive media, serving as the primary vehicle for narrative delivery, character development, and emotional engagement. Producing cutscenes is inherently complex: it demands seamless coordination across screenwriting, cinematography, character animation, voice acting, and technical direction, often requiring days to weeks of collaborative effort from multidisciplinary teams to produce minutes of polished content. In this work, we present Cutscene Agent, an LLM agent framework for automated end-to-end cutscene generation. The framework makes three contributions: (1)~a Cutscene Toolkit built on the Model Context Protocol (MCP) that establishes \emph{bidirectional} integration between LLM agents and the game engine -- agents not only invoke engine operations but continuously observe real-time scene state, enabling closed-loop generation of editable engine-native cinematic assets; (2)~a multi-agent system where a director agent orchestrates specialist subagents for animation, cinematography, and sound design, augmented by a visual reasoning feedback loop for perception-driven refinement; and (3)~CutsceneBench, a hierarchical evaluation benchmark for cutscene generation. Unlike typical tool-use benchmarks that evaluate short, isolated function calls, cutscene generation requires long-horizon, multi-step orchestration of dozens of interdependent tool invocations with strict ordering constraints -- a capability dimension that existing benchmarks do not cover. We evaluate a range of LLMs on CutsceneBench and analyze their performance across this challenging task.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cutscene Agent, an LLM agent framework for automated end-to-end 3D cutscene generation. It contributes (1) a Cutscene Toolkit on the Model Context Protocol (MCP) enabling bidirectional LLM-game engine integration with real-time state observation, (2) a multi-agent system with a director agent coordinating subagents for animation, cinematography, and sound design plus a visual reasoning feedback loop, and (3) CutsceneBench, a hierarchical benchmark targeting long-horizon orchestration of dozens of interdependent tool calls with strict ordering. The work evaluates multiple LLMs on this benchmark.
Significance. If validated, the framework could advance automated cinematic content creation in games by tackling a complex, multi-domain task beyond current short-horizon tool-use benchmarks. CutsceneBench addresses a genuine gap in evaluating long-horizon agentic orchestration, and the bidirectional MCP integration offers a concrete mechanism for closed-loop engine control. These elements have potential to influence both LLM agent research and practical game tooling if supported by reproducible results.
major comments (3)
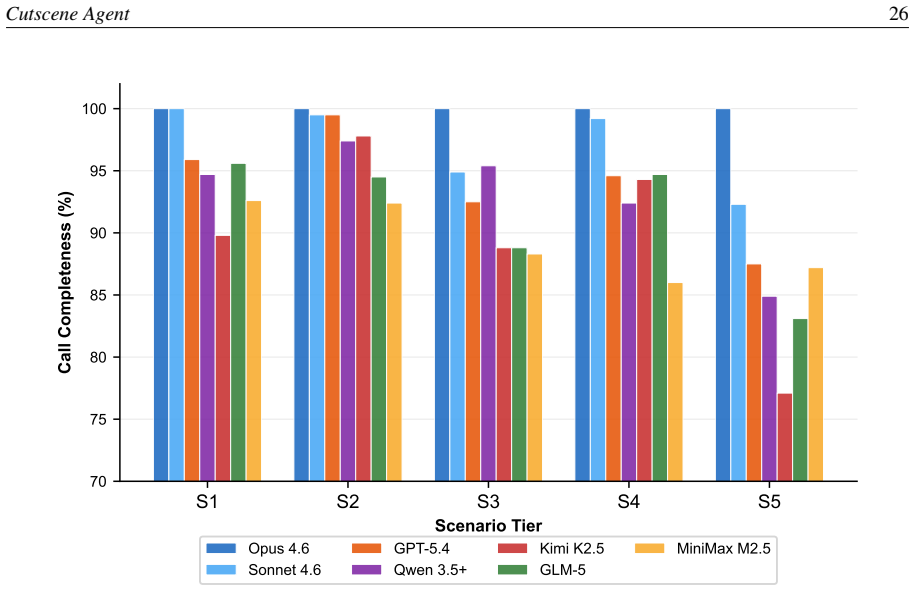
- [Evaluation] Evaluation section: The manuscript states that it evaluates a range of LLMs on CutsceneBench and analyzes performance, yet reports no quantitative metrics such as success rates, failure rates by horizon length, average number of tool invocations per task, or comparisons against non-agent baselines. This directly undermines assessment of the central claim that the multi-agent system reliably handles long-horizon orchestration.
- [Cutscene Toolkit] Cutscene Toolkit section: The description of MCP-based bidirectional integration lacks concrete details on the tool API surface, state query mechanisms, error recovery protocols, and how visual feedback is encoded back to the LLM agents. Without these, it is impossible to evaluate reproducibility or whether the closed-loop capability actually mitigates the ordering constraints highlighted in the abstract.
- [CutsceneBench] CutsceneBench section: The benchmark is positioned as testing dozens of interdependent calls with strict ordering, but provides no task statistics (e.g., distribution of horizon lengths, number of state-dependent branches, or recovery scenarios). This leaves the weakest assumption—that LLM agents can maintain reliable sequencing—unexamined by the evaluation design itself.
minor comments (2)
- [Abstract] Abstract: Mention of the evaluation is present but omits any summary statistics or key findings, which reduces the abstract's utility for readers.
- Terminology: 'Visual reasoning feedback loop' is introduced without a precise definition or pseudocode on first use, which could be clarified for readers unfamiliar with the subfield.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and commit to revisions that provide the requested quantitative metrics, technical details, and benchmark statistics to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: The manuscript states that it evaluates a range of LLMs on CutsceneBench and analyzes performance, yet reports no quantitative metrics such as success rates, failure rates by horizon length, average number of tool invocations per task, or comparisons against non-agent baselines. This directly undermines assessment of the central claim that the multi-agent system reliably handles long-horizon orchestration.
Authors: We agree that explicit quantitative metrics are necessary to fully substantiate our claims about long-horizon orchestration. While the manuscript includes a performance analysis across LLMs, it does not report the specific metrics listed. In the revised version we will add success rates, failure rates stratified by horizon length, average tool invocations per task, and comparisons against non-agent baselines, computed from the existing evaluation runs on CutsceneBench. These additions will directly support assessment of the multi-agent system's reliability. revision: yes
-
Referee: [Cutscene Toolkit] Cutscene Toolkit section: The description of MCP-based bidirectional integration lacks concrete details on the tool API surface, state query mechanisms, error recovery protocols, and how visual feedback is encoded back to the LLM agents. Without these, it is impossible to evaluate reproducibility or whether the closed-loop capability actually mitigates the ordering constraints highlighted in the abstract.
Authors: We will expand the Cutscene Toolkit section with concrete specifications: the full tool API surface (function names, parameters, and return types), state query mechanisms for real-time scene observation, error recovery protocols, and the precise encoding of visual feedback into agent prompts. These details will improve reproducibility and clarify how the bidirectional MCP integration supports closed-loop mitigation of ordering constraints. revision: yes
-
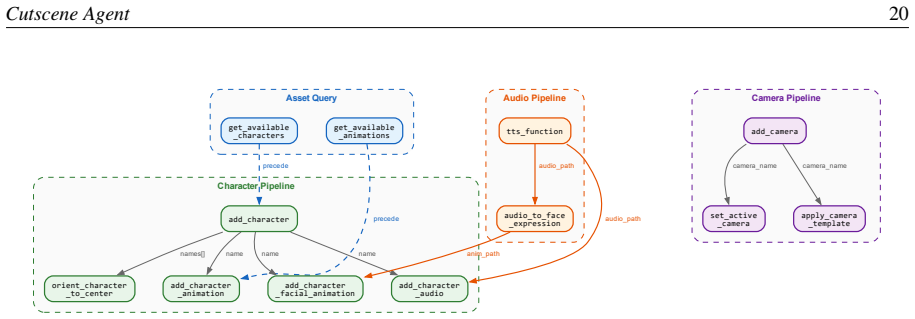
Referee: [CutsceneBench] CutsceneBench section: The benchmark is positioned as testing dozens of interdependent calls with strict ordering, but provides no task statistics (e.g., distribution of horizon lengths, number of state-dependent branches, or recovery scenarios). This leaves the weakest assumption—that LLM agents can maintain reliable sequencing—unexamined by the evaluation design itself.
Authors: We acknowledge that task-level statistics are required to examine sequencing reliability. In the revised manuscript we will include the distribution of horizon lengths, the count of state-dependent branches per task, and descriptions of recovery scenarios within CutsceneBench. This information will allow readers to evaluate how well the benchmark tests long-horizon orchestration and will be accompanied by the corresponding performance breakdowns. revision: yes
Circularity Check
No circularity: framework and benchmark are independently introduced without self-referential reductions
full rationale
The paper presents a new toolkit, multi-agent orchestration system, and CutsceneBench benchmark as contributions, then evaluates LLMs on the benchmark. No equations, fitted parameters, predictions, or derivations are described that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The central claims rest on external evaluation of the new components rather than any internal equivalence or renaming of known results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Model context protocol specification.https://modelcontextprotocol.io/, 2024
Anthropic. Model context protocol specification.https://modelcontextprotocol.io/, 2024
2024
-
[2]
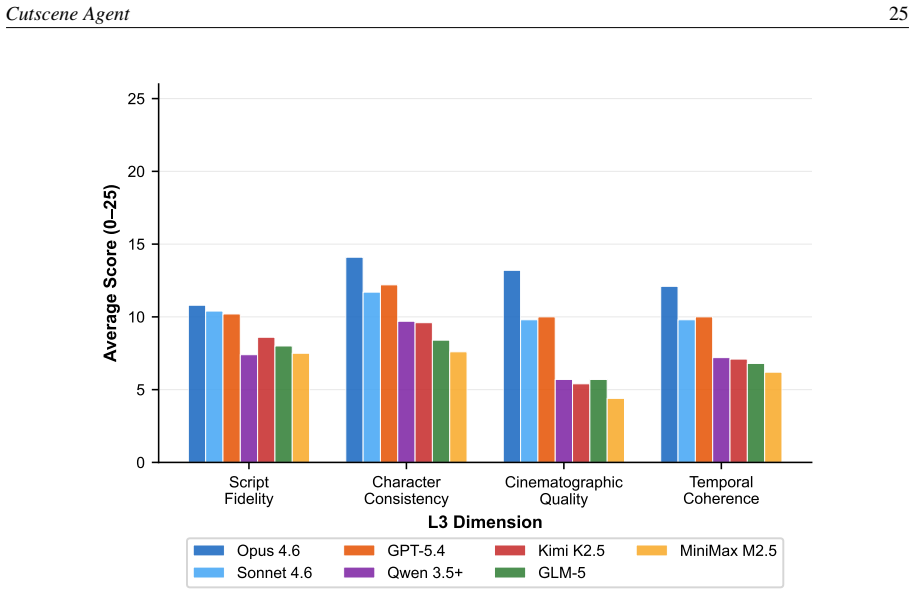
Align your latents: High-resolution video synthesis with latent diffusion models
Andreas Blattmann, Robin Rombach, Huan Ling, Tim Dockhorn, Seung Wook Kim, Sanja Fidler, and Karsten Kreis. Align your latents: High-resolution video synthesis with latent diffusion models. InIEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 22563–22575, 2023
2023
-
[3]
Camera control in computer graphics
Marc Christie, Patrick Olivier, and Jean-Marie Normand. Camera control in computer graphics. In Computer Graphics Forum, volume 27, pages 2197–2218. Wiley, 2008
2008
-
[4]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, and Tim Salimans. Imagen video: High definition video generation with diffusion models.arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review arXiv 2022
-
[5]
Motiongpt: Human motion as a foreign language
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign language. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[6]
Camera keyframing with style and control.ACM Transactions on Graphics (TOG), 40(6):1–13, 2021
Hongda Jiang, Marc Christie, Xi Wang, Libin Liu, Bin Wang, and Baoquan Chen. Camera keyframing with style and control.ACM Transactions on Graphics (TOG), 40(6):1–13, 2021
2021
-
[7]
Example-driven virtual cinematography by learning camera behaviors
Hongda Jiang, Bin Wang, Xi Wang, Marc Christie, and Baoquan Chen. Example-driven virtual cinematography by learning camera behaviors. InACM SIGGRAPH 2020 Papers, pages 1–14, 2020
2020
-
[8]
Cinematographic camera diffusion model
Hongda Jiang, Xi Wang, Marc Christie, Libin Liu, and Baoquan Chen. Cinematographic camera diffusion model. InComputer Graphics Forum (Eurographics), volume 43, 2024
2024
-
[9]
Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations (ICLR), 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues? InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[10]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
Kling: Video generation model.https://klingai.com/, 2024
Kuaishou. Kling: Video generation model.https://klingai.com/, 2024
2024
-
[12]
Api- bank: A comprehensive benchmark for tool-augmented llms
Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. Api- bank: A comprehensive benchmark for tool-augmented llms. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[13]
Yunxin Li et al. Anim-director: A large multimodal model powered agent for controllable animation video generation.arXiv preprint arXiv:2408.09787, 2024
-
[14]
arXiv preprint arXiv:2309.15091 (2023)
Han Lin, Abhay Zala, Jaemin Cho, and Mohit Bansal. Videodirectorgpt: Consistent multi-scene video generation via llm-guided planning.arXiv preprint arXiv:2309.15091, 2023
-
[15]
Intuitive and efficient camera control with the toric space.ACM Transactions on Graphics (Proceedings of SIGGRAPH), 34(4):82:1–82:12, 2015
Christophe Lino and Marc Christie. Intuitive and efficient camera control with the toric space.ACM Transactions on Graphics (Proceedings of SIGGRAPH), 34(4):82:1–82:12, 2015
2015
-
[16]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
Chatcam: Empowering camera control through conversational ai
Xinhang Liu, Yu-Wing Tai, and Chi-Keung Tang. Chatcam: Empowering camera control through conversational ai. InAdvances in Neural Information Processing Systems (NeurIPS), 2024. Cutscene Agent 30
2024
-
[18]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[19]
arXiv preprint arXiv:2408.04682 , year=
Jiarui Lu, Thomas Zhu, Hritik Mehta, et al. Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities.arXiv preprint arXiv:2408.04682, 2024
-
[20]
Function calling in the openai api
OpenAI. Function calling in the openai api. https://platform.openai.com/docs/guides/ function-calling, 2023
2023
-
[21]
Sora: Video generation model.https://openai.com/index/sora-is-here, 2024
OpenAI. Sora: Video generation model.https://openai.com/index/sora-is-here, 2024
2024
-
[22]
The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models
Shishir G Patil, Huanzhi Mao, Fanjia Yan, Charlie Cheng-Jie Ji, Vishnu Suresh, Ion Stoica, and Joseph E Gonzalez. The berkeley function calling leaderboard (BFCL): From tool use to agentic evaluation of large language models. InProceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[23]
Gorilla: Large Language Model Connected with Massive APIs
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. Gorilla: Large language model connected with massive apis.arXiv preprint arXiv:2305.15334, 2023
work page internal anchor Pith review arXiv 2023
-
[24]
Cinempc: A fully autonomous drone cinematography system incorporating zoom, focus, pose, and scene composition.IEEE Transactions on Robotics, 2024
Pablo Pueyo, Eduardo Montijano, Ana C Murillo, and Carlos Sagüés. Cinempc: A fully autonomous drone cinematography system incorporating zoom, focus, pose, and scene composition.IEEE Transactions on Robotics, 2024
2024
-
[25]
Toolllm: Facilitating large language models to master 16000+ real-world apis
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, et al. Toolllm: Facilitating large language models to master 16000+ real-world apis. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[26]
Zhongfei Qing, Zhongang Cai, Zhitao Yang, and Lei Yang. Story-to-motion: Synthesizing infinite and controllable character animation from long text.arXiv preprint arXiv:2311.07446, 2023
-
[27]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessi, Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[28]
Hugging- gpt: Solving ai tasks with chatgpt and its friends in hugging face
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. Hugging- gpt: Solving ai tasks with chatgpt and its friends in hugging face. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[29]
Taskbench: Benchmarking large language models for task automation
Yongliang Shen, Kaitao Song, Xu Tan, Wenqi Zhang, Kan Ren, Siyu Yuan, Weiming Lu, Dongsheng Li, and Yueting Zhuang. Taskbench: Benchmarking large language models for task automation. In Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[30]
Reflexion: Language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[31]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Uriel Singer, Adam Polyak, Thomas Hayes, Xi Yin, Jie An, Songyang Zhang, Qiyuan Hu, Harry Yang, Oron Ashual, Oran Gafni, Devi Parikh, Sonal Gupta, and Yaniv Taigman. Make-a-video: Text-to-video generation without text-video data.arXiv preprint arXiv:2209.14792, 2022
work page internal anchor Pith review arXiv 2022
-
[32]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InIEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[33]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025. Cutscene Agent 31
work page internal anchor Pith review arXiv 2025
-
[34]
Human motion diffusion model
Guy Tevet, Sigal Raab, Brian Gordon, Yonatan Shafir, Daniel Cohen-Or, and Amit H Bermano. Human motion diffusion model. InInternational Conference on Learning Representations (ICLR), 2023
2023
-
[35]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023
work page internal anchor Pith review arXiv 2023
-
[36]
Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, et al. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[37]
arXiv preprint arXiv:2503.07314 (2025)
Weijia Wu et al. Automated movie generation via multi-agent cot planning.arXiv preprint arXiv:2503.07314, 2025
-
[38]
Qiantong Xu et al. On the tool manipulation capability of open-source large language models.arXiv preprint arXiv:2305.16504, 2023
-
[39]
Zhenran Xu, Longyue Wang, Jifang Wang, Zhouyi Li, Senbao Shi, Xue Yang, Yiyu Wang, Baotian Hu, Jun Yu, and Min Zhang. Filmagent: A multi-agent framework for end-to-end film automation in virtual 3d spaces.arXiv preprint arXiv:2501.12909, 2025
-
[40]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains.arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review arXiv 2024
-
[41]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models.arXiv preprint arXiv:2210.03629, 2023
work page internal anchor Pith review arXiv 2023
-
[42]
Mengchen Zhang, Tong Wu, Jing Tan, Ziwei Liu, Gordon Wetzstein, and Dahua Lin. Gen- dop: Auto-regressive camera trajectory generation as a director of photography.arXiv preprint arXiv:2504.07083, 2025
-
[43]
Judging llm-as-a-judge with mt-bench and chatbot arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[44]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all.arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review arXiv 2024
-
[45]
static" or
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations (ICLR), 2024. Cutscene Agent 32 A Toolkit and MCP API Reference This appendix serves as...
2024
-
[46]
The agent or an external service calls import_dynamic_asset, specifying data_type (an im- portable type, e.g., audio_wav), data_source (the raw payload or reference), source_type (base64/file_path/url), and an optionalidentifier_hint
-
[47]
A normalized identifier is assigned following a{prefix}_{hint}_{hex_suffix}scheme
The toolkit resolves the data source: base64 payloads are decoded in memory; file paths are copied into the project’s Raw/dynamic/ directory; URLs are downloaded asynchronously via a generator-based non-blocking mechanism (yield-based suspension) to avoid freezing the editor. A normalized identifier is assigned following a{prefix}_{hint}_{hex_suffix}scheme
-
[48]
The receiver performs format-specific processing (e.g., W A V→Sound Wave import) and returns aReceiverResultcontaining the resulting UE asset path
The raw file is dispatched to the appropriate@register_receiver handler (selected bydata_type) via an ImportContext object. The receiver performs format-specific processing (e.g., W A V→Sound Wave import) and returns aReceiverResultcontaining the resulting UE asset path
-
[49]
" ) ->dict: defadd_character_facial_animation( character_name:str, identifier:str, start_time:float, gender: Literal[
The record—now carrying explicitimportable_type,loader_type, andasset_kindfields—is persisted in a JSON registry (dynamic_registry.json). Once registered, dynamic assets become queryable through the samequery_assets()interface, filtered byasset_kind. Agents can discover available import types and their expected metadata before importing: get_ importable_a...
-
[50]
Instructs the agent to consult the auto-injectedcurrent_cutscene_contentfor incremental operations
CutsceneCreation— Canonical workflow ordering: add characters → generate audio and facial expressions → add body animations → add cameras and apply templates. Instructs the agent to consult the auto-injectedcurrent_cutscene_contentfor incremental operations
-
[51]
Spacing heuristics:∼70 cm side-by-side,∼40 cm front-to-back
Actor Rules— Character spatial placement conventions with concrete coordinate examples for two-person (A at (−60,0,0) , B at (60,0,0) ) and three-person triangle formations ( A, B, C at prescribed offsets). Spacing heuristics:∼70 cm side-by-side,∼40 cm front-to-back
-
[52]
Dialogue parsing guidelines: strip narration, identify emotional beats, compute end_time = start_time + audio_duration
Audio Rules— Tone consistency requirements (same character uses the same voice tone throughout a scene). Dialogue parsing guidelines: strip narration, identify emotional beats, compute end_time = start_time + audio_duration
-
[53]
Duration-matching requirement: anima- tion length must cover dialogue duration
Animation Rules— Animation tag taxonomy ( timing: Speak/Gap/Solo; expressiveness: Light/Medium/Heavy; mood: emotional tone; duration). Duration-matching requirement: anima- tion length must cover dialogue duration. No temporal overlap on the same character
-
[54]
Dy- namic movement composition (Dolly push/pull, Orbit arc)
Camera Rules— Template-based camera positioning via apply_camera_template. Dy- namic movement composition (Dolly push/pull, Orbit arc). OTS variant selection guidelines (near/mid/high). Encourages shot variety for visual richness
-
[55]
custom" task:str, # Natural-language task description context:str=
Tool Usage— Sequential tool calling discipline, dependency ordering enforcement, and create- before-use prerequisites. B.1.3 Tool Access Scope The Director Agent has access to the full MCP tool surface (30+ tools across all four functional modules described in Section 3.1), with the following exceptions filtered out to prevent accidental misuse: •clear_se...
-
[56]
TTS generation: Call tts_function_tool to synthesize speech→ returns an audio_identifier andduration
-
[57]
Audio attachment: Call add_character_audio with the audio identifier and computedend_time = start_time + duration
-
[58]
Facial expression synthesis: Call audio_to_face_expression_tool with the audio identifier →returns aface_identifier
-
[59]
lighting review agent
Facial animation attachment: Call add_character_facial_animation with the face identifier. A critical behavioral constraint istone consistency: the system prompt requires the agent to call get_available_tone at the start of each session, assign a fixed tone to each character, and reuse that assignment across all dialogue lines. Emotional variation is achi...
-
[60]
Perceive: The VLA receives one or more screenshots captured via take_editor_screenshot or take_camera_screenshot, along with a structured task description and relevant cutscene metadata (character names, intended shot type, script excerpt)
-
[61]
Analyze: A vision-language model (e.g., multimodal LLMs or dedicated vision-language architec- tures) processes the visual input against task-specific evaluation criteria, producing a structured assessment
-
[62]
Alice stands to Bob’s left
Report/Act: The VLA returns either (a) adiagnostic report—structured JSON with quality scores, identified issues, and corrective suggestions—for the Director to act upon, or (b)direct tool callsto autonomously apply corrections. The key design principle isinterface uniformity: VLA agents plug into the same run_subagent dispatch mechanism as text-only spec...
-
[63]
Astoryboard prompt—the sole input provided to the cutscene agent
-
[64]
Aground-truth tool-call trajectory—the reference sequence of MCP tool invocations used for Layer 1 evaluation
-
[65]
Pass and destination
Aground-truth Level Sequence snapshot—the expected final timeline state used for Layer 2 evaluation. Only the storyboard (1) is visible to the agent during generation; components (2) and (3) serve exclusively as evaluation references. D.1 Storyboard Prompt The storyboard below is provided verbatim as the initial user message. It specifies participating ch...
-
[66]
0–5: No recognizable connection to the script; characters or dialogue entirely wrong
Script Fidelity (SF) Focus:Whether dialogue content and character actions specified in the storyboard are accurately reproduced. 0–5: No recognizable connection to the script; characters or dialogue entirely wrong. 6–10: Major dialogue lines missing or assigned to wrong characters; key actions absent. 11–15: Most dialogue present but with notable omission...
-
[67]
0–5: Characters constantly glitch, teleport, or are unrecognizable
Character Consistency (ChC) Focus:Whether characters maintain stable identities, spatial positions, and coherent behavior throughout. 0–5: Characters constantly glitch, teleport, or are unrecognizable. 6–10: Significant issues—characters swap positions, face wrong directions frequently. 11–15: Generally stable but with noticeable position jumps or animati...
-
[68]
0–5: Camera is broken, static, or completely fails to frame the action
Cinematographic Quality (CQ) Focus:Whether camera shot types, framing, and cutting patterns serve the narrative effectively. 0–5: Camera is broken, static, or completely fails to frame the action. 6–10: Poor shot selection; characters frequently out of frame or awkwardly framed. 11–15: Adequate framing but shot types don’t match the script; some jarring c...
-
[69]
script_fidelity
Temporal Coherence (TmpCoh) Focus:Whether timing and synchronization create a natural viewing experience. 0–5: Completely broken timing; audio and animation fully desynchronized. 6–10: Significant issues—dialogue stutters/repeats, long dead air, animations freeze. 11–15: Noticeable timing problems but generally followable; some sync drift. 16–20: Smooth p...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.