Recognition: unknown
AHASD: Asynchronous Heterogeneous Architecture for LLM Adaptive Drafting Speculative Decoding on Mobile Devices
Pith reviewed 2026-05-07 14:25 UTC · model grok-4.3
The pith
AHASD runs draft generation and verification in parallel on mobile NPU-PIM hardware to cut idle time and wasted work in speculative decoding.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AHASD achieves parallel drafting on the PIM and verification on a single NPU through task-level DLM-TLM decoupling, incorporating Entropy-History-Aware Drafting Control and Time-Aware Pre-Verification Control to dynamically manage adaptive drafting algorithm execution and pre-verification timing while suppressing invalid drafts based on low-confidence signals, plus Attention Algorithm Units and Gated Task Scheduling Units inside LPDDR5-PIM for attention link localization and sub-microsecond task switching.
What carries the argument
Entropy-History-Aware Drafting Control and Time-Aware Pre-Verification Control, which read model confidence signals to decide when to launch or cancel draft tasks, together with the added Attention Algorithm Units and Gated Task Scheduling Units that localize attention work and enable fast switching on the PIM side.
If this is right
- Mobile devices can sustain higher token generation rates while staying within the same power and thermal limits.
- Speculative decoding becomes practical on single-NPU-PIM chips instead of requiring separate GPU and PIM boards.
- Energy cost per generated token drops enough to extend battery life during prolonged on-device chat or summarization.
- Hardware additions stay small enough that they do not force redesign of the DRAM stack or increase chip area significantly.
Where Pith is reading between the lines
- Similar entropy-based early-exit logic could be applied to other variable-length inference tasks such as image captioning or speech recognition on the same hardware.
- The task-level decoupling might allow the PIM to stay busy on other background work when drafting pauses, improving overall system utilization.
- If the controls prove robust across more model sizes, mobile chip designers could standardize the added units rather than treating them as custom extensions.
Load-bearing premise
The two control mechanisms can correctly identify and drop low-value drafts without discarding useful ones or creating extra overhead that wipes out the gains from running the models in parallel.
What would settle it
Fabricate or emulate the proposed Attention Algorithm Units and Gated Task Scheduling Units on real LPDDR5-PIM silicon, run the same LLMs and adaptive drafting algorithms, and measure whether throughput, energy per token, and DRAM area overhead match the reported 4.2x, 5.6x, and sub-3 percent figures.
Figures




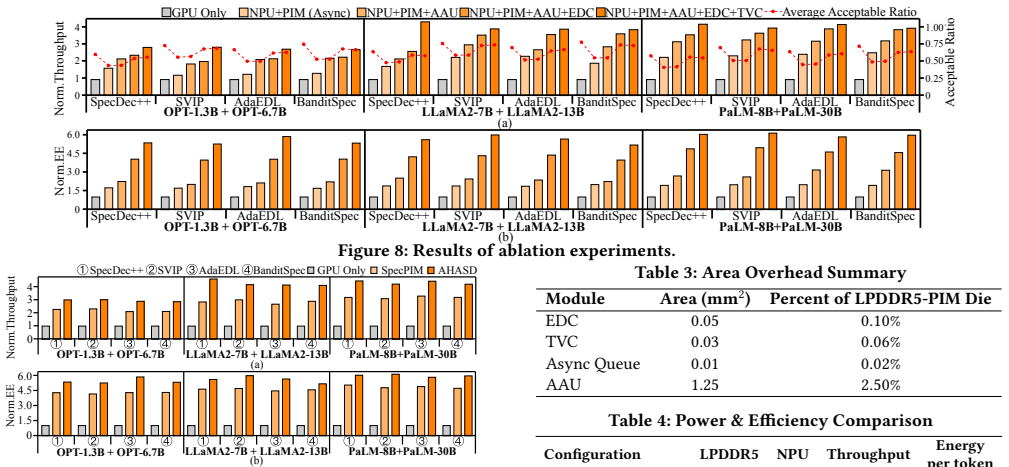
read the original abstract
Speculative decoding enhances the inference efficiency of large language models (LLMs) by generating drafts using a small draft language model (DLM) and verifying them in batches with a large target language model (TLM). However, adaptive drafting inference on a mobile single-NPU-PIM system faces idle overhead in traditional operator-level synchronous execution and wasted computation in asynchronous execution due to fluctuations in draft length. This paper introduces AHASD, a task-level asynchronous mobile NPU-PIM heterogeneous architecture for speculative decoding. Notably, AHASD achieves parallel drafting on the PIM and verification on a single NPU through task-level DLM-TLM decoupling and specifically, it incorporates Entropy-History-Aware Drafting Control and Time-Aware Pre-Verification Control to dynamically manage adaptive drafting algorithm execution and pre-verification timing, suppressing invalid drafting based on low-confidence drafts. Additionally, AHASD integrates Attention Algorithm Units and Gated Task Scheduling Units within LPDDR5-PIM to enable attention link localization and sub-microsecond task switching on the PIM side. Experimental results for different LLMs and adaptive drafting algorithms show that AHASD achieves up to 4.2$\times$ in throughput and 5.6$\times$ in energy efficiency improvements over a GPU-only baseline, and 1.5$\times$ in throughput and 1.24$\times$ in energy efficiency gains over the state-of-the-art GPU+PIM baseline, with hardware overhead below 3% of the DRAM area.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AHASD, a task-level asynchronous heterogeneous NPU-PIM architecture for adaptive speculative decoding of LLMs on mobile devices. It decouples DLM drafting (on PIM) from TLM verification (on NPU) to enable parallelism, introduces Entropy-History-Aware Drafting Control and Time-Aware Pre-Verification Control to suppress low-confidence drafts, and adds Attention Algorithm Units plus Gated Task Scheduling Units inside LPDDR5-PIM for localized attention and sub-microsecond switching. Experiments on various LLMs and drafting algorithms report up to 4.2× throughput and 5.6× energy efficiency versus a GPU-only baseline, plus 1.5× throughput and 1.24× energy versus a GPU+PIM baseline, with <3% DRAM area overhead.
Significance. If the controls and hardware integration are shown to deliver net gains without hidden overheads, the work would be significant for practical mobile LLM deployment: it directly tackles idle time in synchronous execution and wasted work in naive asynchronous speculative decoding by moving to task-level asynchrony and PIM specialization. The emphasis on sub-3% area overhead and dynamic control mechanisms addresses real constraints in edge hardware, and the heterogeneous NPU-PIM focus is timely given growing interest in PIM for AI acceleration.
major comments (3)
- [Abstract / Experimental Results] Abstract and Experimental Results: The headline gains (4.2× throughput, 5.6× energy vs. GPU; 1.5×/1.24× vs. GPU+PIM) are stated to arise from the Entropy-History-Aware Drafting Control and Time-Aware Pre-Verification Control suppressing invalid drafts without discarding useful tokens or eroding parallelism; however, no ablation results (e.g., performance with controls disabled), draft-acceptance statistics, or latency breakdowns are supplied to confirm that the controls produce net benefit rather than merely shifting overhead.
- [Hardware Architecture] Hardware Architecture section: The claim that Attention Algorithm Units and Gated Task Scheduling Units integrate into LPDDR5-PIM with sub-microsecond switching and <3% DRAM area overhead is load-bearing for the mobile feasibility argument, yet the manuscript provides neither area/power models, synthesis results, nor cycle-accurate timing measurements to substantiate these numbers.
- [Experimental Results] Comparison to baselines: The reported improvements over the state-of-the-art GPU+PIM baseline rest on the assumption that the added PIM units and controls do not introduce switching or control latency that offsets the task-level parallelism; without explicit overhead measurements or sensitivity analysis, it is impossible to verify that the 1.5×/1.24× gains are robust.
minor comments (2)
- [Abstract] Notation for speedups (e.g., 4.2×) should be used consistently in both abstract and body text; the LaTeX rendering of × is clear but should be checked for uniformity.
- [Experimental Results] The manuscript would benefit from a brief table summarizing the exact model sizes, draft lengths, and adaptive algorithms tested, as these details are referenced but not enumerated in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which highlights opportunities to strengthen the empirical support for our claims. We address each major comment below with plans for targeted revisions.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: The headline gains (4.2× throughput, 5.6× energy vs. GPU; 1.5×/1.24× vs. GPU+PIM) are stated to arise from the Entropy-History-Aware Drafting Control and Time-Aware Pre-Verification Control suppressing invalid drafts without discarding useful tokens or eroding parallelism; however, no ablation results (e.g., performance with controls disabled), draft-acceptance statistics, or latency breakdowns are supplied to confirm that the controls produce net benefit rather than merely shifting overhead.
Authors: We agree that ablation studies, acceptance statistics, and latency breakdowns are necessary to rigorously demonstrate the net benefit of the controls. In the revised manuscript we will add (i) ablations with each control disabled individually and jointly, (ii) draft-acceptance rates and token-level statistics, and (iii) per-component latency breakdowns that isolate drafting, verification, and control overheads, confirming that the reported speedups and energy gains are not offset by the added mechanisms. revision: yes
-
Referee: [Hardware Architecture] Hardware Architecture section: The claim that Attention Algorithm Units and Gated Task Scheduling Units integrate into LPDDR5-PIM with sub-microsecond switching and <3% DRAM area overhead is load-bearing for the mobile feasibility argument, yet the manuscript provides neither area/power models, synthesis results, nor cycle-accurate timing measurements to substantiate these numbers.
Authors: The quoted figures were derived from our internal synthesis flow and area modeling for the LPDDR5-PIM integration. To substantiate them, the revised Hardware Architecture section will include the area/power models, synthesis results, and cycle-accurate timing data that support the sub-microsecond switching latency and the <3% DRAM area overhead. revision: yes
-
Referee: [Experimental Results] Comparison to baselines: The reported improvements over the state-of-the-art GPU+PIM baseline rest on the assumption that the added PIM units and controls do not introduce switching or control latency that offsets the task-level parallelism; without explicit overhead measurements or sensitivity analysis, it is impossible to verify that the 1.5×/1.24× gains are robust.
Authors: We acknowledge that explicit quantification of control and switching latencies is required to confirm robustness. The revised Experimental Results section will report the measured latencies of the Gated Task Scheduling Units and control logic, together with a sensitivity analysis that varies these latencies to demonstrate that the 1.5× throughput and 1.24× energy gains remain positive across the observed range. revision: yes
Circularity Check
No circularity: claims rest on experimental results without self-referential derivations
full rationale
The paper proposes the AHASD architecture and reports throughput/energy gains from experiments on LLMs and drafting algorithms. No equations, fitted parameters, or derivation chains are present in the provided text. Performance numbers are presented as direct experimental outcomes rather than predictions derived from inputs by construction, self-citations, or renamed known results. The Entropy-History-Aware Drafting Control and hardware units are described as design choices whose efficacy is asserted via measurements, not reduced to tautological fits or prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Sudhanshu Agrawal, Wonseok Jeon, and Mingu Lee. 2024. AdaEDL: Early Draft Stopping for Speculative Decoding of Large Language Models via an Entropy- based Lower Bound on Token Acceptance Probability. InNeurIPS Efficient Nat- ural Language and Speech Processing Workshop, 14 December 2024, Vancouver, British Columbia, Canada (Proceedings of Machine Learning...
2024
-
[2]
Kahng, Naveen Muralimanohar, Ali Shafiee, and Vaishnav Srinivas
Rajeev Balasubramonian, Andrew B. Kahng, Naveen Muralimanohar, Ali Shafiee, and Vaishnav Srinivas. 2017. CACTI 7: New Tools for Interconnect Exploration in Innovative Off-Chip Memories.ACM Trans. Archit. Code Optim.14, 2 (2017), 14:1–14:25
2017
-
[3]
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, et al. 2023. PaLM: Scaling Language Modeling with Pathways.J. Mach. Learn. Res.24 (2023), 240:1–240:113
2023
-
[4]
2025.Coral NPU: A machine learning accelerator core designed for energy-efficient AI at the edge
Google Coral. 2025.Coral NPU: A machine learning accelerator core designed for energy-efficient AI at the edge
2025
-
[5]
Hyungkyu Ham, Wonhyuk Yang, Yunseon Shin, Okkyun Woo, Guseul Heo, Sangyeop Lee, Jongse Park, and Gwangsun Kim. 2024. ONNXim: A Fast, Cycle- Level Multi-Core NPU Simulator.IEEE Comput. Archit. Lett.23, 2 (2024), 219–222
2024
-
[6]
Guseul Heo, Sangyeop Lee, Jaehong Cho, Hyunmin Choi, Sanghyeon Lee, Hyungkyu Ham, Gwangsun Kim, Divya Mahajan, and Jongse Park. 2024. Ne- uPIMs: NPU-PIM Heterogeneous Acceleration for Batched LLM Inferencing. In Proceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS 2...
2024
-
[7]
Yunlong Hou, Fengzhuo Zhang, Cunxiao Du, Xuan Zhang, Jiachun Pan, Tianyu Pang, Chao Du, Vincent Y. F. Tan, and Zhuoran Yang. 2025. BanditSpec: Adaptive Speculative Decoding via Bandit Algorithms. InForty-second International Con- ference on Machine Learning, ICML 2025, Vancouver, BC, Canada, July 13-19, 2025 (Proceedings of Machine Learning Research), Aar...
2025
-
[8]
Kaixuan Huang, Xudong Guo, and Mengdi Wang. 2025. SpecDec++: Boosting Speculative Decoding via Adaptive Candidate Lengths. InConference on Language Modeling (COLM)
2025
-
[9]
Jin Hyun Kim, Shinhaeng Kang, Sukhan Lee, Hyeonsu Kim, Yuhwan Ro, Se- ungwon Lee, David Wang, Jihyun Choi, Jinin So, YeonGon Cho, Joon-Ho Song, Jeonghyeon Cho, Kyomin Sohn, and Nam Sung Kim. 2022. Aquabolt-XL HBM2- PIM, LPDDR5-PIM With In-Memory Processing, and AXDIMM With Accelera- tion Buffer.IEEE Micro42, 3 (2022), 20–30
2022
-
[10]
Hyoukjun Kwon, Prasanth Chatarasi, Vivek Sarkar, Tushar Krishna, Michael Pellauer, and Angshuman Parashar. 2020. MAESTRO: A Data-Centric Approach to Understand Reuse, Performance, and Hardware Cost of DNN Mappings.IEEE Micro40, 3 (2020), 20–29
2020
-
[11]
Yongkee Kwon, Kornijcuk Vladimir, Nahsung Kim, Woojae Shin, Jongsoon Won, Minkyu Lee, Hyunha Joo, Haerang Choi, Guhyun Kim, Byeongju An, Jeong- bin Kim, Jaewook Lee, Ilkon Kim, Jaehan Park, Chanwook Park, Yosub Song, Byeongsu Yang, Hyungdeok Lee, Seho Kim, Daehan Kwon, Seong Ju Lee, Kyuy- oung Kim, Sanghoon Oh, Joonhong Park, Gimoon Hong, Dongyoon Ka, Kyu...
2022
-
[12]
Sukhan Lee, Shinhaeng Kang, Jaehoon Lee, Hyeonsu Kim, Eojin Lee, Seungwoo Seo, Hosang Yoon, Seungwon Lee, Kyounghwan Lim, Hyunsung Shin, Jinhyun Kim, Seongil O, Anand Iyer, David Wang, Kyomin Sohn, and Nam Sung Kim
-
[13]
In48th ACM/IEEE Annual International Symposium on Computer Architecture, ISCA 2021, Virtual Event / Valencia, Spain, June 14-18, 2021
Hardware Architecture and Software Stack for PIM Based on Commercial DRAM Technology : Industrial Product. In48th ACM/IEEE Annual International Symposium on Computer Architecture, ISCA 2021, Virtual Event / Valencia, Spain, June 14-18, 2021. IEEE, 43–56
2021
-
[14]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA (Proceedings of Machine Learning Research), Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlet...
2023
-
[15]
Cong Li, Zhe Zhou, Size Zheng, Jiaxi Zhang, Yun Liang, and Guangyu Sun
-
[16]
SpecPIM: Accelerating Speculative Inference on PIM-Enabled System via Architecture-Dataflow Co-Exploration. InProceedings of the 29th ACM Inter- national Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3, ASPLOS 2024, La Jolla, CA, USA, 27 April 2024- 1 May 2024, Rajiv Gupta, Nael B. Abu-Ghazaleh, Madan Musuvath...
2024
-
[17]
Tianyu Liu, Yun Li, Qitan Lv, Kai Liu, Jianchen Zhu, Winston Hu, and Xiao Sun
-
[18]
In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025
PEARL: Parallel Speculative Decoding with Adaptive Draft Length. In The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025. OpenReview.net
2025
-
[19]
Bradley McDanel. 2025. AMUSD: Asynchronous Multi-Device Speculative De- coding for LLM Acceleration. InIEEE International Symposium on Circuits and Systems, ISCAS 2025, London, United Kingdom, May 25-28, 2025. IEEE, 1–5
2025
-
[20]
Xupeng Miao, Gabriele Oliaro, Zhihao Zhang, Xinhao Cheng, Zeyu Wang, Zhengxin Zhang, Rae Ying Yee Wong, Alan Zhu, Lijie Yang, Xiaoxiang Shi, Chunan Shi, Zhuoming Chen, Daiyaan Arfeen, Reyna Abhyankar, and Zhihao Jia. 2024. SpecInfer: Accelerating Large Language Model Serving with Tree- based Speculative Inference and Verification. InProceedings of the 29t...
2024
-
[21]
Jaehyun Park, Jaewan Choi, Kwanhee Kyung, Michael Jaemin Kim, Yongsuk Kwon, Nam Sung Kim, and Jung Ho Ahn. 2024. AttAcc! Unleashing the Power of PIM for Batched Transformer-based Generative Model Inference. InProceedings of the 29th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 2(La Jolla, CA...
2024
-
[22]
2025.PIMSimulator: Processing-In-Memory (PIM) Simulator
SAITPublic. 2025.PIMSimulator: Processing-In-Memory (PIM) Simulator
2025
-
[23]
Seong Hoon Seo, Junghoon Kim, Donghyun Lee, Seonah Yoo, Seokwon Moon, Yeonhong Park, and Jae W. Lee. 2025. FACIL: Flexible DRAM Address Mapping for SoC-PIM Cooperative On-device LLM Inference. InIEEE International Symposium on High Performance Computer Architecture, HPCA 2025, Las Vegas, NV, USA, March 1-5, 2025. IEEE, 1720–1733
2025
-
[24]
Hashimoto
Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford Alpaca: An Instruction-following LLaMA model
2023
-
[25]
Hugo Touvron, Louis Martin, Kevin Stone, et al. 2023. Llama 2: Open Foundation and Fine-Tuned Chat Models.CoRRabs/2307.09288 (2023). arXiv:2307.09288
work page internal anchor Pith review arXiv 2023
-
[26]
Linye Wei, Shuzhang Zhong, Songqiang Xu, Runsheng Wang, Ru Huang, and Meng Li. 2025. SpecASR: Accelerating LLM-based Automatic Speech Recognition via Speculative Decoding. In62nd ACM/IEEE Design Automation Conference, DAC 2025, San Francisco, CA, USA, June 22-25, 2025. IEEE, 1–7
2025
-
[27]
Yinan Xu, Zihao Yu, Dan Tang, Guokai Chen, Lu Chen, Lingrui Gou, Yue Jin, Qianruo Li, Xin Li, Zuojun Li, Jiawei Lin, Tong Liu, Zhigang Liu, Jiazhan Tan, Huaqiang Wang, Huizhe Wang, Kaifan Wang, Chuanqi Zhang, Fawang Zhang, Linjuan Zhang, Zifei Zhang, Yangyang Zhao, Yaoyang Zhou, Yike Zhou, Jiangrui Zou, Ye Cai, Dandan Huan, Zusong Li, Jiye Zhao, Zihao Che...
2022
-
[28]
Minghao Yan, Saurabh Agarwal, and Shivaram Venkataraman. 2025. Decoding Speculative Decoding. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2025 - Volume 1: Long Papers, Albuquerque, New Mexico, USA, April 29 - May 4, 2025, Luis Chiruzzo, Ala...
2025
-
[29]
Jun Zhang, Jue Wang, Huan Li, Lidan Shou, Ke Chen, Gang Chen, and Sharad Mehrotra. 2024. Draft& Verify: Lossless Large Language Model Acceleration via Self-Speculative Decoding. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2024, Bangkok, Thailand, August 11-16, 2024, Lun-Wei Ku, And...
2024
-
[30]
Susan Zhang, Stephen Roller, Naman Goyal, et al. 2022. OPT: Open Pre-trained Transformer Language Models.CoRRabs/2205.01068 (2022). arXiv:2205.01068
work page internal anchor Pith review arXiv 2022
-
[31]
Ziyin Zhang, Jiahao Xu, Tian Liang, Xingyu Chen, Zhiwei He, Rui Wang, and Zhaopeng Tu. 2025. Draft Model Knows When to Stop: Self-Verification Specula- tive Decoding for Long-Form Generation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP 2025, Suzhou, China, November 4-9, 2025, Christos Christodoulopoulos,...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.