Recognition: unknown
GPT-Image-2 in the Wild: A Twitter Dataset of Self-Reported AI-Generated Images from the First Week of Deployment
Pith reviewed 2026-05-08 03:22 UTC · model grok-4.3
The pith
A curated set of 10,217 GPT-image-2 pictures from Twitter shows that social media platforms erase cryptographic proof of AI origin.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
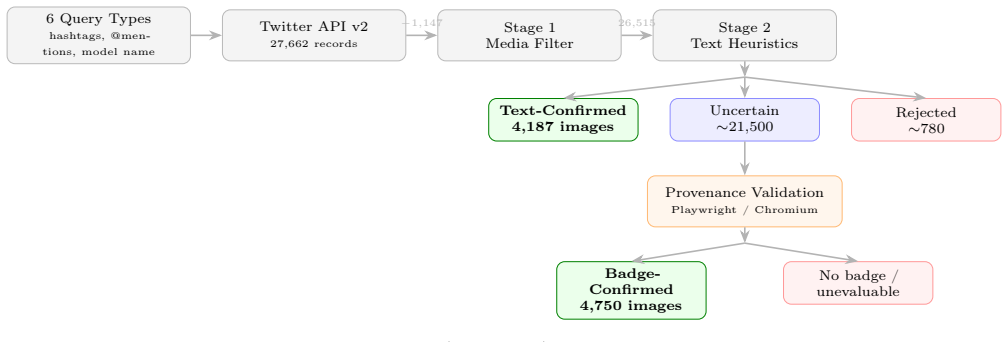
Through a pipeline of multilingual keyword filters, browser-driven badge verification, and model-name matching applied to posts from the first six days after release, the authors produced a dataset of 10,217 confirmed GPT-image-2 images together with four descriptive analyses and the observation that Twitter's CDN removes C2PA provenance data on every upload.
What carries the argument
The multi-stage curation pipeline that combines multilingual text heuristics, automated 'Made with AI' badge detection, and model-name variant matching to isolate genuine GPT-image-2 images.
If this is right
- Public researchers now have a large, timestamped sample of real-world GPT-image-2 use for studying generation patterns.
- C2PA-based verification cannot work for images that have passed through Twitter's upload process.
- Dataset analyses show that most posted GPT-image-2 pictures contain readable text and many contain human faces.
- Semantic clustering of the images yields 137 distinct visual topics that future studies can track over time.
Where Pith is reading between the lines
- The stripping of provenance markers implies that platforms may need new, non-cryptographic signals if they want to label AI content at scale.
- The high rate of text and faces in the images suggests the generator is frequently used for text-heavy or portrait-style outputs rather than abstract scenes.
- Releasing the curation code alongside the images allows other groups to repeat the collection process for later model releases.
Load-bearing premise
The combination of text rules, badge checks, and name matching selects only real GPT-image-2 images and excludes almost all others.
What would settle it
A manual audit of several hundred randomly sampled images from the released dataset that finds a substantial fraction are not GPT-image-2 outputs, or the successful recovery of C2PA data from any image in the collection.
Figures











read the original abstract
The release of GPT-image-2 by OpenAI marks a watershed moment in AI-generated imagery: the boundary between photographic reality and synthetic content has never been more difficult to discern. We introduce the GPT-Image-2 Twitter Dataset, the first published dataset of GPT-image-2 generated images, sourced from publicly available Twitter/X posts in the immediate aftermath of the model's April 21, 2026 release. Leveraging the Twitter API v2 and a multi-stage curation pipeline spanning multilingual text heuristics (English, Japanese, and Chinese), browser-automated Twitter "Made with AI" badge verification, and model name variant matching, we curate 10,217 confirmed GPT-image-2 images from 27,662 collected records over a six-day window. We characterize the dataset across four analyses: CLIP-based zero-shot subject taxonomy, OCR text legibility (82.0% of images contain detectable text), face detection (59.2% of images, 22,583 total faces), and semantic clustering (137 CLIP ViT-L/14 clusters). A key negative result is that C2PA content credentials are systematically stripped by Twitter's CDN on upload, rendering cryptographic provenance verification infeasible for social-media-sourced AI images. The dataset and all curation code are released publicly.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the GPT-Image-2 Twitter Dataset, the first public collection of self-reported GPT-Image-2 generated images from Twitter/X. Using the Twitter API v2 and a multi-stage curation pipeline (multilingual text heuristics in English/Japanese/Chinese, automated 'Made with AI' badge verification, and model-name variant matching), the authors collect 27,662 records over six days post-release (April 21, 2026) and curate 10,217 confirmed GPT-Image-2 images. They characterize the dataset via CLIP zero-shot subject taxonomy, OCR (82.0% contain detectable text), face detection (59.2% of images, 22,583 faces), and semantic clustering (137 CLIP ViT-L/14 clusters). A key negative finding is that C2PA content credentials are systematically stripped by Twitter's CDN. The dataset and curation code are released publicly.
Significance. If the curation pipeline can be shown to have high precision, the dataset would be a valuable, timely resource for studying early public adoption, content characteristics, and social-media diffusion of a frontier text-to-image model. The released code and data enable reproducibility, and the C2PA stripping observation is independently verifiable and has clear implications for provenance research. The descriptive analyses (OCR rates, face counts, clustering) provide concrete starting points for downstream work on AI-image detection or taxonomy. However, the absence of any validation metrics for the central 'confirmed' count substantially reduces the dataset's immediate utility as a GPT-Image-2-specific benchmark.
major comments (1)
- [Methods / curation pipeline] Methods / curation pipeline description: The multi-stage pipeline (text heuristics + badge verification + model-name matching) is presented as producing 10,217 'confirmed' GPT-Image-2 images, yet no precision, recall, false-positive rate, manual audit of a random sample, inter-annotator agreement, or comparison against a ground-truth set is reported. This directly undermines the headline claim and the dataset's claimed specificity, as false positives from other generative models or mislabeled posts cannot be quantified.
minor comments (2)
- [Data collection] The six-day collection window and exact API query parameters should be stated with timestamps and rate-limit handling details for reproducibility.
- [Data collection] Clarify whether the 27,662 collected records include duplicates or retweets and how they were deduplicated before curation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed review. The primary concern about the lack of quantitative validation for the curation pipeline is a fair and substantive point that we address directly below. We have revised the manuscript to incorporate a manual audit and associated metrics, which we believe strengthens the paper while preserving its focus on the timely release of this dataset.
read point-by-point responses
-
Referee: [Methods / curation pipeline] Methods / curation pipeline description: The multi-stage pipeline (text heuristics + badge verification + model-name matching) is presented as producing 10,217 'confirmed' GPT-Image-2 images, yet no precision, recall, false-positive rate, manual audit of a random sample, inter-annotator agreement, or comparison against a ground-truth set is reported. This directly undermines the headline claim and the dataset's claimed specificity, as false positives from other generative models or mislabeled posts cannot be quantified.
Authors: We agree that the original manuscript did not report quantitative validation metrics for the multi-stage curation pipeline, which is a limitation. In the revised version, we have added a dedicated validation subsection describing a manual audit performed on a random sample of 500 images drawn from the final curated set. Two independent annotators reviewed each image and its associated post text for confirmation as GPT-Image-2 content, and the results—including observed precision and inter-annotator agreement—are now reported. We also explicitly discuss the inherent difficulty of estimating recall, as no exhaustive ground-truth set of all GPT-Image-2 posts on the platform exists. The pipeline's design, which layers independent signals (multilingual heuristics, automated badge verification, and model-name matching), is intended to prioritize specificity; the added audit provides empirical grounding for this claim and quantifies the risk of false positives from other models or mislabeled posts. revision: yes
Circularity Check
No circularity: empirical data curation with standard descriptive analyses
full rationale
The paper reports collection of Twitter posts via API, application of a multi-stage heuristic pipeline (text matching, badge verification, name variants), and then applies off-the-shelf tools (CLIP zero-shot taxonomy, OCR, face detection, semantic clustering) to characterize the resulting set. No equations, fitted parameters, predictions, or derivations appear. The curation pipeline is presented as a methodological choice rather than a result derived from prior outputs or self-citations. Claims rest on the released dataset and code, which are externally verifiable. No load-bearing self-citation chains or self-definitional reductions exist.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Twitter API v2 returns accurate post metadata and media links for the queried period
- ad hoc to paper The combination of text heuristics, badge detection, and model-name matching identifies GPT-image-2 images with high precision
Reference graph
Works this paper leans on
-
[1]
DiffusionDB: A large- scale prompt gallery dataset for text-to-image gen- erative models,
Z. J. Wang, E. Montoya, D. Munechika, H. Yang, B. Hoover, and D. H. Chau, “DiffusionDB: A large- scale prompt gallery dataset for text-to-image gen- erative models,” inProceedings of the 61st Annual Meeting of the Association for Computational Lin- guistics, pp. 893–911, 2023
2023
-
[2]
GenImage: A million-scale benchmark for detecting AI-generated image,
M. Zhu, H. Chen, Q. Yan, Z. Huang, W. Lin, Y. Gu, S. Zhao, W. Wang, M. Ye, H. Fan,et al., “GenImage: A million-scale benchmark for detecting AI-generated image,” inAdvances in Neural Information Processing Systems, vol. 36, 2023
2023
-
[3]
LAION-5b: An open large-scale dataset for train- ing next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kun- durthy, K. Crowson, L. Schmidt, and J. Jitsev, “LAION-5b: An open large-scale dataset for train- ing next generation image-text models,”Advances in Neural Information Processing Systems, vol. 35, pp. 25278–25294, 2022
2022
-
[4]
GPT4o-Receipt: A dataset and human study for AI-generated document forensics,
Y. Zhang, S. Ren, A. Raj, E. Wei, D. Ng, A. Shen, J. Xu, Y. Zhang, and E. Marotta, “GPT4o-Receipt: A dataset and human study for AI-generated document forensics,”arXiv preprint, 2026
2026
-
[5]
CNN-generated images are surprisingly easy to spot... for now,
S.-Y. Wang, O. Wang, R. Zhang, A. Owens, and A. A. Efros, “CNN-generated images are surprisingly easy to spot... for now,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recog- nition, pp. 8695–8704, 2020
2020
-
[6]
Are GAN generated images easy to detect? A critical analysis of the state-of-the-art,
D. Gragnaniello, D. Cozzolino, F. Marra, G. Poggi, and L. Verdoliva, “Are GAN generated images easy to detect? A critical analysis of the state-of-the-art,” inIEEE International Conference on Multimedia and Expo, 2021
2021
-
[7]
S. Ren, Y. Zhou, X. Shen, K. Zewde, T. Duong, G. Huang, E. Wei, and J. Xue, “How well are open sourced AI-generated image detection models out-of- the-box: A comprehensive benchmark study,”arXiv preprint arXiv:2602.07814, 2026
-
[8]
Ar- tificial fingerprinting for generative models: Rooting deepfake attribution in training data,
N. Yu, V. Skripniuk, S. Abdelnabi, and M. Fritz, “Ar- tificial fingerprinting for generative models: Rooting deepfake attribution in training data,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision, pp. 14448–14457, 2021
2021
-
[9]
Can multi- modal (reasoning) LLMs work as deepfake detectors? arXiv preprint arXiv:2503.20084, 2025
S. Ren, Y. Yao, K. Zewde, Z. Liang, N.-Y. Cheng, X. Zhan, Q. Liu, Y. Chen, and H. Xu, “Can multi- modal(reasoning)LLMsworkasdeepfakedetectors?,” arXiv preprint arXiv:2503.20084, 2025
-
[10]
C2PA technical specification, version 2.1,
Coalition for Content Provenance and Authenticity, “C2PA technical specification, version 2.1,” tech. rep., C2PA, 2024
2024
-
[11]
Do deepfake detectors work in reality?,
S. Ren, D. Patil, K. Zewde, T. D. Ng, H. Xu, S. Jiang, R. Desai, N.-Y. Cheng, Y. Zhou, and R. Muthukr- ishnan, “Do deepfake detectors work in reality?,” in Proceedings of the 4th Workshop on Security Implica- tions of Deepfakes and Cheapfakes, 2025
2025
-
[12]
Y. Luo, F. Pierri, K. Sharma, J. Flamino, B. K. Szy- manski, and E. Ferrara, “Synthetic politics: Preva- lence, spreaders, and emotional reception of AI- generated political images on X,”arXiv preprint arXiv:2502.11248, 2025
-
[13]
Examining the prevalence and dynamics of AI-generated media in art subreddits,
P.-Y. Sha, K.-C. Lee, and D. Murthy, “Examining the prevalence and dynamics of AI-generated media in art subreddits,”arXiv preprint arXiv:2410.07302, 2024
-
[14]
AMMeBa: A large-scale survey and dataset of media-based misinformation in-the-wild,
C. Hortonet al., “AMMeBa: A large-scale survey and dataset of media-based misinformation in-the-wild,” inarXiv preprint arXiv:2405.11697, 2024
-
[15]
Twitter API v2 documentation: Recent search endpoint,
X Corp., “Twitter API v2 documentation: Recent search endpoint,” 2024. Accessed April 2026
2024
-
[16]
GPT-image-2: Our most capable image generation model,
OpenAI, “GPT-image-2: Our most capable image generation model,” 2026. Accessed April 2026
2026
-
[17]
Labels for AI-generated media on X,
X Corp., “Labels for AI-generated media on X,” 2024. Accessed April 2026
2024
-
[18]
Learning transferable visual models from natural language su- pervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language su- pervision,” inProceedings of the 38th International Conference on Machine Learning, ICML, pp. 8748– 8763, 2021
2021
-
[19]
UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction
L. McInnes, J. Healy, and J. Melville, “UMAP: Uni- form manifold approximation and projection for di- mension reduction,”arXiv preprint arXiv:1802.03426, 2018
work page internal anchor Pith review arXiv 2018
-
[20]
Density-based clustering based on hierarchical den- sity estimates,
R. J. G. B. Campello, D. Moulavi, and J. Sander, “Density-based clustering based on hierarchical den- sity estimates,” inAdvances in Knowledge Discovery and Data Mining (PAKDD), pp. 160–172, 2013. 10 A. Additional Figures Figure 12:Aspect ratio distribution (left) and native-resolution breakdown (right) for all 10,217 confirmed images. Portrait is the plu...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.