Recognition: unknown
Sample-efficient Neuro-symbolic Proximal Policy Optimization
Pith reviewed 2026-05-07 16:32 UTC · model grok-4.3
The pith
Partial logical policy specifications transferred from easier tasks guide a neuro-symbolic extension of PPO to faster learning and higher returns in sparse-reward environments with long horizons.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is a neuro-symbolic extension of PPO that transfers partial logical policy specifications from easier task instances to more difficult ones. This is achieved through H-PPO-Product, which biases the policy's action distribution at sampling time, and H-PPO-SymLoss, which incorporates a symbolic regularization term into the PPO objective. The approach yields faster learning and higher returns at convergence on the OfficeWorld, WaterWorld, and DoorKey environments compared to standard PPO and reward machine baselines, and remains effective under imperfect symbolic knowledge.
What carries the argument
H-PPO-Product and H-PPO-SymLoss, the two ways of integrating transferred partial logical policy specifications to bias sampling or regularize the PPO loss.
If this is right
- Faster learning curves appear on OfficeWorld, WaterWorld, and DoorKey relative to plain PPO.
- Higher returns at convergence are achieved compared to both PPO and reward-machine baselines.
- Performance gains hold when the provided symbolic knowledge is imperfect rather than exact.
- The transfer mechanism applies to domains that combine multiple sub-goals with infrequent rewards.
Where Pith is reading between the lines
- The same partial-specification transfer could be tested with other policy-gradient algorithms beyond PPO.
- Logical abstractions obtained in simulation might reduce real-world trials needed for robotic control tasks.
- If the symbolic component can be learned online rather than pre-supplied, the approach might extend to fully end-to-end settings.
Load-bearing premise
Partial logical policy specifications learned or provided from easier task instances can be transferred to meaningfully guide and improve learning in more challenging settings with long horizons and sparse rewards.
What would settle it
An experiment on a new long-horizon sparse-reward task where the neuro-symbolic PPO variants show no improvement in convergence speed or final returns over standard PPO despite using the transferred partial specifications.
Figures








read the original abstract
Deep Reinforcement Learning (DRL) algorithms often require a large amount of data and struggle in sparse-reward domains with long planning horizons and multiple sub-goals. In this paper, we propose a neuro-symbolic extension of Proximal Policy Optimization (PPO) that transfers partial logical policy specifications learned in easier instances to guide learning in more challenging settings. We introduce two integrations of symbolic guidance: (i) H-PPO-Product, which biases the action distribution at sampling time, and (ii) H-PPO-SymLoss, which augments the PPO loss with a symbolic regularization term. We evaluate our methods on three benchmarks (OfficeWorld, WaterWorld, and DoorKey), showing consistently faster learning and higher return at convergence than PPO and a Reward Machine baseline, also under imperfect symbolic knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a neuro-symbolic extension of Proximal Policy Optimization (PPO) for improving sample efficiency in sparse-reward, long-horizon RL tasks. It introduces two integrations of partial logical policy specifications transferred from easier instances: H-PPO-Product, which biases the action distribution during sampling, and H-PPO-SymLoss, which augments the PPO loss with a symbolic regularization term. Empirical results on OfficeWorld, WaterWorld, and DoorKey benchmarks claim consistently faster learning and higher returns at convergence compared to standard PPO and a Reward Machine baseline, including under imperfect symbolic knowledge.
Significance. If the integrations are shown to preserve PPO's theoretical properties while delivering the reported gains, the work could provide a practical bridge between symbolic guidance and neural policy optimization, addressing key limitations in data efficiency for complex planning domains. The multi-benchmark evaluation offers initial support for the transfer approach, though its broader impact depends on resolving the validity concerns.
major comments (2)
- [Methods (H-PPO-Product integration)] In the methods section describing H-PPO-Product, the action distribution is explicitly biased at sampling time, but it is not stated whether the importance sampling ratio in the clipped PPO surrogate objective is recomputed with respect to the modified (biased) policy or retained from the original policy. If the ratio is unmodified, the estimator becomes off-policy without correction, violating the proximal guarantee and potentially attributing performance differences to uncontrolled distribution shift rather than symbolic guidance. This is load-bearing for the claim that both methods are valid extensions of PPO.
- [Experiments and evaluation setup] The central claim rests on transferring partial logical policy specifications learned from easier task instances to guide harder settings, yet the manuscript provides insufficient detail on the extraction process, completeness criteria, or sensitivity to specification quality. Without ablations isolating this transfer mechanism (e.g., comparing learned vs. provided specs or varying imperfection levels), it is difficult to verify that gains stem from the neuro-symbolic integration rather than other factors.
minor comments (2)
- [Abstract] The abstract refers to 'imperfect symbolic knowledge' without a concise definition; adding one sentence would improve accessibility for readers unfamiliar with the specific benchmarks.
- [Results] Tables or figures reporting returns should include standard deviations or confidence intervals across runs to allow assessment of consistency beyond mean values.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Methods (H-PPO-Product integration)] In the methods section describing H-PPO-Product, the action distribution is explicitly biased at sampling time, but it is not stated whether the importance sampling ratio in the clipped PPO surrogate objective is recomputed with respect to the modified (biased) policy or retained from the original policy. If the ratio is unmodified, the estimator becomes off-policy without correction, violating the proximal guarantee and potentially attributing performance differences to uncontrolled distribution shift rather than symbolic guidance. This is load-bearing for the claim that both methods are valid extensions of PPO.
Authors: We agree this clarification is essential for establishing that H-PPO-Product remains a valid on-policy extension of PPO. The implementation recomputes the importance sampling ratio using the biased policy at each update step, ensuring the surrogate objective stays proximal and the estimator does not introduce uncontrolled off-policy bias. We will revise the methods section to explicitly state this recomputation, include the updated importance ratio formula, and add a short paragraph discussing how the proximal guarantee is preserved under symbolic biasing. revision: yes
-
Referee: [Experiments and evaluation setup] The central claim rests on transferring partial logical policy specifications learned from easier task instances to guide harder settings, yet the manuscript provides insufficient detail on the extraction process, completeness criteria, or sensitivity to specification quality. Without ablations isolating this transfer mechanism (e.g., comparing learned vs. provided specs or varying imperfection levels), it is difficult to verify that gains stem from the neuro-symbolic integration rather than other factors.
Authors: We acknowledge that the current manuscript lacks sufficient detail on the specification extraction pipeline and does not include targeted ablations on transfer quality. In the revised version we will expand the methods section with a precise description of the extraction algorithm, the completeness criteria applied to the learned logical policies, and the procedure for transferring them across task instances. We will also add new ablation experiments that (i) compare performance when using the automatically extracted specifications versus hand-provided ones and (ii) systematically vary the degree of imperfection in the symbolic knowledge while measuring learning curves and final returns. These additions will isolate the contribution of the neuro-symbolic transfer mechanism. revision: yes
Circularity Check
No circularity: empirical method extensions rest on independent benchmarks
full rationale
The paper introduces two algorithmic modifications to PPO (H-PPO-Product biasing sampling and H-PPO-SymLoss adding a regularization term) and reports empirical results on OfficeWorld, WaterWorld, and DoorKey. No equations derive a prediction from a fitted parameter defined within the paper, no self-citations form load-bearing uniqueness claims, and no ansatz or renaming reduces the central performance claims to inputs by construction. The evaluation compares against PPO and Reward Machine baselines under imperfect knowledge, making the claims falsifiable on external benchmarks rather than self-referential.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Partial logical policy specifications learned on easier instances can be transferred to guide learning on harder instances
Reference graph
Works this paper leans on
-
[1]
Maxime Chevalier-Boisvert, Bolun Dai, Mark Towers, Rodrigo de Lazcano, Lucas Willems, Salem Lahlou, Suman Pal, Pablo Samuel Castro, and Jordan Terry. Minigrid & miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. CoRR, abs/2306.13831,
-
[2]
Phasic policy gradient
Karl W Cobbe, Jacob Hilton, Oleg Klimov, and John Schulman. Phasic policy gradient. In International Conference on Machine Learning, pages 2020–2027. PMLR,
2020
-
[3]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[4]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
URL https://arxiv.org/abs/1506.02438. Sarath Sreedharan and Michael Katz. Optimistic exploration in reinforcement learning using symbolic model estimates.Advances in Neural Information Processing Systems, 36:34519–34535,
work page internal anchor Pith review arXiv
-
[5]
Sample-Efficient Neurosymbolic Deep Reinforcement Learning
URLhttps: //proceedings.mlr.press/v284/veronese25a.html. Celeste Veronese, Daniele Meli, and Alessandro Farinelli. Sample-efficient neurosymbolic deep reinforcement learning.arXiv preprint arXiv:2601.02850,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
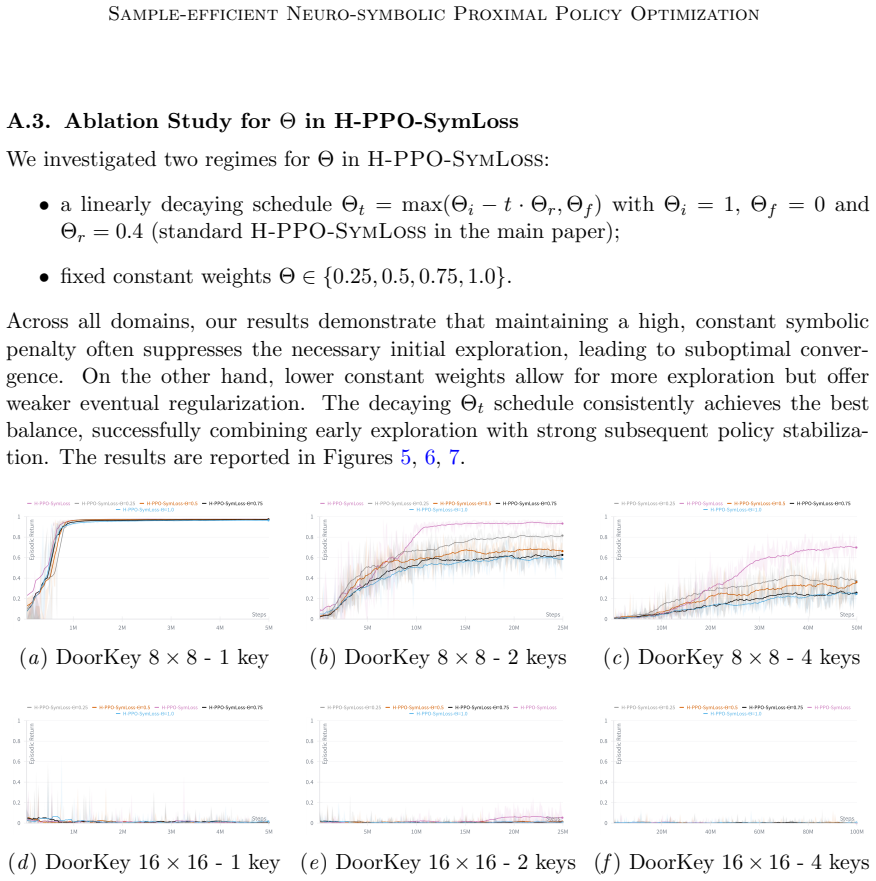
13 Murari Veronese Meli Appendix A. A.1. Domains A.1.1. DoorKey DoorKey is a partially observable grid navigation task (Figure 1(a)) where the agent (red arrow) must retrieve a key, unlock a door of the same color, and then reach the goal cell (green). The MDP observation covers a 7×7 area (light gray), with each cell encoded by object type, color and sta...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.