Recognition: unknown
SnapGuard: Lightweight Prompt Injection Detection for Screenshot-Based Web Agents
Pith reviewed 2026-05-07 15:44 UTC · model grok-4.3
The pith
SnapGuard detects prompt injection attacks on screenshot-based web agents by analyzing visual gradient smoothness and contrast-reversed text signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
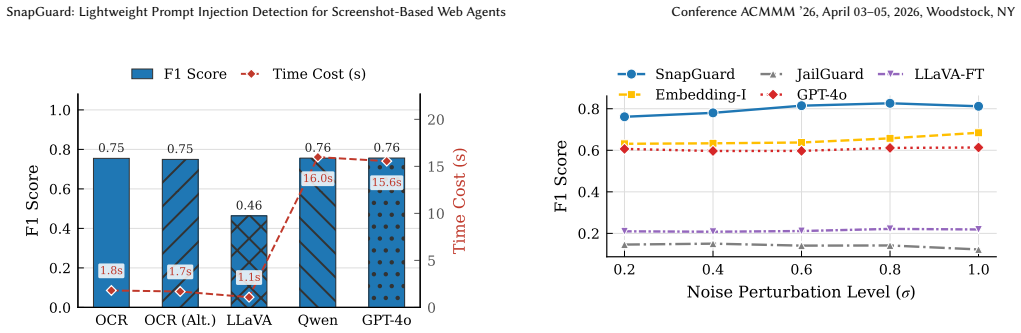
SnapGuard reformulates prompt injection detection as multimodal representation analysis over webpage screenshots. It identifies abnormally smooth gradient distributions induced by malicious content through a visual stability indicator and recovers action-oriented textual signals via contrast-polarity reversal. This yields an F1 score of 0.75 while running eight times faster than GPT-4o-prompt with no added memory use.
What carries the argument
Visual stability indicator for smooth gradients in screenshots paired with contrast-polarity reversal to recover action-oriented textual signals.
Load-bearing premise
Injected webpages reliably produce distinct visual stability traits and recoverable action-oriented text via contrast-polarity reversal that hold across the tested attacks without tuning.
What would settle it
Measuring detection performance on screenshots containing a new prompt injection attack type outside the eight evaluated ones to see if the F1 score drops below practical levels.
Figures




read the original abstract
Web agents have emerged as an effective paradigm for automating interactions with complex web environments, yet remain vulnerable to prompt injection attacks that embed malicious instructions into webpage content to induce unintended actions. This threat is further amplified for screenshot-based web agents, which operate on rendered visual webpages rather than structured textual representations, making predominant text-centric defenses ineffective. Although multimodal detection methods have been explored, they often rely on large vision-language models (VLMs), incurring significant computational overhead. The bottleneck lies in the complexity of modern webpages: VLMs must comprehend the global semantics of an entire page, resulting in substantial inference time and GPU memory usage. This raises a critical question: can we detect prompt injection attacks from screenshots in a lightweight manner? In this paper, we observe that injected webpages exhibit distinct characteristics compared to benign ones from both visual and textual perspectives. Building on this insight, we propose SnapGuard, a lightweight yet accurate method that reformulates prompt injection detection as multimodal representation analysis over webpage screenshots. SnapGuard leverages two complementary signals: a visual stability indicator that identifies abnormally smooth gradient distributions induced by malicious content, and action-oriented textual signals recovered via contrast-polarity reversal. Extensive evaluations across eight attacks and two benign settings demonstrate that SnapGuard achieves an F1 score of 0.75, outperforming GPT-4o-prompt while being 8x faster (1.81s vs. 14.50s) and introducing no additional memory overhead.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SnapGuard, a lightweight prompt injection detection method for screenshot-based web agents. It identifies injected webpages by analyzing abnormally smooth gradient distributions in screenshots for visual stability and recovering action-oriented textual signals through contrast-polarity reversal. The paper reports that this approach achieves an F1 score of 0.75 on eight attacks and two benign settings, while being 8 times faster than GPT-4o-prompt (1.81s vs. 14.50s) with no additional memory overhead.
Significance. If the results hold under rigorous evaluation, this work is significant for web agent security. It offers a practical, low-overhead alternative to VLM-based detection methods, addressing the computational bottlenecks that limit real-time protection in automated web interactions. The domain-specific insight into visual and textual characteristics of injected content could influence lightweight defenses in related multimodal security settings.
major comments (2)
- Evaluation section: The headline F1 score of 0.75, 8x speedup, and zero memory overhead are load-bearing claims, yet the manuscript provides no details on dataset construction (e.g., number of benign pages, total samples), attack implementations for the eight tested attacks, or statistical significance testing. Without these, it is impossible to determine whether the numbers reflect genuine generalization across attacks or post-hoc selection.
- Method section (signals description): The visual stability indicator (gradient smoothness) and action-oriented textual signals (via polarity reversal) are asserted to be reliably discriminative, but the paper supplies no quantitative separation metrics, ablation studies on each signal, or failure-case analysis on benign pages with heavy CSS gradients or form layouts. This leaves the central assumption unverified.
minor comments (2)
- Abstract: The phrase 'extensive evaluations across eight attacks and two benign settings' would be strengthened by briefly stating sample sizes or total page count to give readers immediate context for the reported F1.
- Figures: Ensure all visualizations of gradient distributions and contrast-reversed text include clear captions and axis labels so that the claimed distinctions are immediately interpretable without reference to the main text.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important areas where additional details and analysis are needed to strengthen the claims. We address each major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: Evaluation section: The headline F1 score of 0.75, 8x speedup, and zero memory overhead are load-bearing claims, yet the manuscript provides no details on dataset construction (e.g., number of benign pages, total samples), attack implementations for the eight tested attacks, or statistical significance testing. Without these, it is impossible to determine whether the numbers reflect genuine generalization across attacks or post-hoc selection.
Authors: We agree that the Evaluation section requires more transparency to support the reported results. In the revised manuscript, we will expand this section with a full description of the dataset, including the exact number of benign pages, total samples, and how the two benign settings were constructed. We will also provide implementation details for each of the eight attacks and include statistical significance testing (e.g., confidence intervals or p-values from appropriate tests) for the F1 score and runtime metrics. These additions will clarify the evaluation protocol and help demonstrate generalization. revision: yes
-
Referee: Method section (signals description): The visual stability indicator (gradient smoothness) and action-oriented textual signals (via polarity reversal) are asserted to be reliably discriminative, but the paper supplies no quantitative separation metrics, ablation studies on each signal, or failure-case analysis on benign pages with heavy CSS gradients or form layouts. This leaves the central assumption unverified.
Authors: We acknowledge that the current manuscript does not provide sufficient quantitative validation for the two signals. In the revision, we will add quantitative separation metrics (such as histograms or statistical comparisons of gradient smoothness and polarity-reversed text features between injected and benign pages). We will also include ablation studies isolating the contribution of each signal to the overall F1 score. Finally, we will incorporate a dedicated failure-case analysis examining benign pages with heavy CSS gradients or complex form layouts, discussing any observed limitations and their implications for the method's robustness. revision: yes
Circularity Check
No circularity; derivation rests on empirical observations of webpage characteristics without self-referential reduction.
full rationale
The paper's central claim begins with an empirical observation that injected webpages exhibit distinct visual stability (smooth gradients) and textual signals (via polarity reversal) compared to benign pages. SnapGuard is then constructed directly from these observed signals as a lightweight multimodal analysis method. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked that would make any result equivalent to its inputs by construction. Performance numbers (F1=0.75, 8x speedup) are presented as outcomes of separate evaluations across attacks rather than predictions derived from the same data or prior self-referential work. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023)
work page internal anchor Pith review arXiv 2023
-
[2]
Anthropic. 2025. Computer Use. https://docs.claude.com/en/docs/agents-and- tools/tool-use/computer-use-tool. Accessed: 2025-09-24
2025
- [3]
-
[4]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. 2025. Qwen2.5-VL Technical Rep...
work page internal anchor Pith review arXiv 2025
-
[5]
Tri Cao, Bennett Lim, Yue Liu, Yuan Sui, Yuexin Li, Shumin Deng, Lin Lu, Nay Oo, Shuicheng YAN, and Bryan Hooi. 2026. VPI-Bench: Visual Prompt Injection Attacks for Computer-Use Agents. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/forum?id=UMauKu2azg
2026
- [6]
-
[7]
Yurun Chen, Zeyi Liao, Ping Yin, Taotao Xie, Keting Yin, and Shengyu Zhang
- [8]
- [9]
- [10]
-
[11]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. 2024. Agentdojo: A dynamic environment to eval- uate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems37 (2024), 82895–82920
2024
-
[12]
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. 2023. Mind2Web: Towards a Generalist Agent for the Web. InThirty-seventh Conference on Neural Information Processing Systems. https: //openreview.net/forum?id=kiYqbO3wqw
2023
-
[13]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024)
work page internal anchor Pith review arXiv 2024
- [14]
-
[15]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. 2023. Not what you’ve signed up for: Compromising real- world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security. 79–90
2023
-
[16]
Zeyi Liao, Jaylen Jones, Linxi Jiang, Yuting Ning, Eric Fosler-Lussier, Yu Su, Zhiqiang Lin, and Huan Sun. 2026. RedTeamCUA: Realistic Adversarial Testing of Computer-Use Agents in Hybrid Web-OS Environments. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/ forum?id=yWwrgcBoK3
2026
-
[17]
Zeyi Liao, Lingbo Mo, Chejian Xu, Mintong Kang, Jiawei Zhang, Chaowei Xiao, Yuan Tian, Bo Li, and Huan Sun. 2025. EIA: ENVIRONMENTAL IN- JECTION ATTACK ON GENERALIST WEB AGENTS FOR PRIVACY LEAK- AGE. InThe Thirteenth International Conference on Learning Representations. https://openreview.net/forum?id=xMOLUzo2Lk
2025
-
[18]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InComputer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. Springer, 740– 755
2014
-
[19]
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2023. Improved Baselines with Visual Instruction Tuning
2023
-
[20]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual Instruc- tion Tuning
2023
-
[21]
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. 2024. Formalizing and benchmarking prompt injection attacks and defenses. In33rd USENIX Security Symposium (USENIX Security 24). 1831–1847
2024
-
[22]
Yupei Liu, Yuqi Jia, Jinyuan Jia, Dawn Song, and Neil Zhenqiang Gong. 2025. DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks. In2025 IEEE Symposium on Security and Privacy (SP). IEEE, 2190–2208
2025
- [23]
- [24]
-
[25]
Mykola Maslych, Mohammadreza Katebi, Christopher Lee, Yahya Hmaiti, Amirpouya Ghasemaghaei, Christian Pumarada, Janneese Palmer, Esteban Segarra Martinez, Marco Emporio, Warren Snipes, et al. 2025. Mitigating response delays in free-form conversations with LLM-powered intelligent virtual agents. InProceedings of the 7th ACM Conference on Conversational Us...
2025
-
[26]
Meta. 2025. Llama Prompt Guard 2 86M. https://huggingface.co/meta-llama/ Llama-Prompt-Guard-2-86M. Accessed: 2026
2025
- [27]
-
[28]
Yohei Nakajima. 2022. Post on X. https://x.com/yoheinakajima/status/ 1582844144640471040. Accessed: 2024-09-20
2022
-
[29]
Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al
-
[30]
Webgpt: Browser-assisted question-answering with human feedback.arXiv preprint arXiv:2112.09332(2021)
work page internal anchor Pith review arXiv 2021
-
[31]
Liangbo Ning, Ziran Liang, Zhuohang Jiang, Haohao Qu, Yujuan Ding, Wenqi Fan, Xiao-yong Wei, Shanru Lin, Hui Liu, Philip S Yu, et al. 2025. A survey of webagents: Towards next-generation ai agents for web automation with large foundation models. InProceedings of the 31st ACM SIGKDD Conference on Knowl- edge Discovery and Data Mining V. 2. 6140–6150
2025
- [32]
-
[33]
OpenAI. 2025. Browser-Use Agent: Introduction and Documentation. https: //docs.browser-use.com/introduction. Accessed: 2025-09-24
2025
-
[34]
Yujia Qin, Yining Ye, Junjie Fang, Haoming Wang, Shihao Liang, Shizuo Tian, Junda Zhang, Jiahao Li, Yunxin Li, Shijue Huang, et al. 2025. Ui-tars: Pioneering automated gui interaction with native agents.arXiv preprint arXiv:2501.12326 (2025)
work page internal anchor Pith review arXiv 2025
-
[35]
Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever
Alec Radford, Jong Wook Kim, Chris Hallacy, A. Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. InICML
2021
-
[36]
Revanth Gangi Reddy, Sagnik Mukherjee, Jeonghwan Kim, Zhenhailong Wang, Dilek Hakkani-Tur, and Heng Ji. 2025. Infogent: An agent-based framework for web information aggregation. InFindings of the Association for Computational Linguistics: NAACL 2025. 5745–5758
2025
-
[37]
Tianneng Shi, Kaijie Zhu, Zhun Wang, Yuqi Jia, Will Cai, Weida Liang, Haonan Wang, Hend Alzahrani, Joshua Lu, Kenji Kawaguchi, et al. 2025. Promptarmor: Simple yet effective prompt injection defenses.arXiv preprint arXiv:2507.15219 (2025). Conference ACMMM ’26, April 03–05, 2026, Woodstock, NY Trovato et al
- [38]
-
[39]
Qwen Team. 2025. Qwen3 Technical Report. arXiv:2505.09388 [cs.CL] https: //arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[40]
Haoming Wang, Haoyang Zou, Huatong Song, Jiazhan Feng, Junjie Fang, Junting Lu, Longxiang Liu, Qinyu Luo, Shihao Liang, Shijue Huang, et al. 2025. Ui-tars-2 technical report: Advancing gui agent with multi-turn reinforcement learning. arXiv preprint arXiv:2509.02544(2025)
work page internal anchor Pith review arXiv 2025
-
[41]
Wenhui Wang, Hangbo Bao, Shaohan Huang, Li Dong, and Furu Wei. 2021. Minilmv2: Multi-head self-attention relation distillation for compressing pre- trained transformers. InFindings of the Association for Computational Linguistics: ACL-IJCNLP 2021. 2140–2151
2021
-
[42]
Xilong Wang, John Bloch, Zedian Shao, Yuepeng Hu, Shuyan Zhou, and Neil Zhen- qiang Gong. 2025. Webinject: Prompt injection attack to web agents. InProceed- ings of the 2025 Conference on Empirical Methods in Natural Language Processing. 2010–2030
2025
- [43]
-
[44]
Yu Wang, Xiaogeng Liu, Yu Li, Muhao Chen, and Chaowei Xiao. 2024. Adashield: Safeguarding multimodal large language models from structure-based attack via adaptive shield prompting. InEuropean Conference on Computer Vision. Springer, 77–94
2024
-
[45]
Haoran Wei, Yaofeng Sun, and Yukun Li. 2025. DeepSeek-OCR: Contexts Optical Compression.arXiv preprint arXiv:2510.18234(2025)
work page internal anchor Pith review arXiv 2025
- [46]
- [47]
- [48]
- [49]
-
[50]
ZHANG Xiaoyu, Z Cen, L Tianlin, H Yihao, J Xiaojun, H Ming, ZHANG Jie, L Yang, M Shiqing, and S Chao. 2026. JailGuard: A universal detection framework for prompt-based attacks on LLM systems.ACM Transactions on Software Engineering and Methodology35, 1 (2026), 1–40
2026
-
[51]
Kevin Xu, Yeganeh Kordi, Tanay Nayak, Adi Asija, Yizhong Wang, Kate Sanders, Adam Byerly, Jingyu Zhang, Benjamin Van Durme, and Daniel Khashabi. 2025. TurkingBench: A Challenge Benchmark for Web Agents. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies ...
2025
-
[52]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. InThe eleventh international conference on learning representations
2022
-
[53]
Yanzhe Zhang, Tao Yu, and Diyi Yang. 2025. Attacking vision-language computer agents via pop-ups. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 8387–8401
2025
-
[54]
Haoren Zhao, Tianyi Chen, and Zhen Wang. 2025. On the robustness of gui grounding models against image attacks. InProceedings of the Computer Vision and Pattern Recognition Conference. 1618–1623
2025
-
[55]
Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. 2024. GPT-4V(ision) is a Generalist Web Agent, if Grounded. InForty-first International Conference on Machine Learning. https://openreview.net/forum?id=piecKJ2DlB
2024
-
[56]
Boyuan Zheng, Boyu Gou, Scott Salisbury, Zheng Du, Huan Sun, and Yu Su
-
[57]
In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Delia Irazu Hernandez Farias, Tom Hope, and Manling Li (Eds.)
WebOlympus: An Open Platform for Web Agents on Live Websites. In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Delia Irazu Hernandez Farias, Tom Hope, and Manling Li (Eds.). Association for Computational Linguistics, Miami, Florida, USA, 187–197. https://aclanthology.org/2024.emnlp-demo.20
2024
- [58]
-
[59]
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. 2023. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854(2023)
work page internal anchor Pith review arXiv 2023
-
[60]
Wei Zou, Runpeng Geng, Binghui Wang, and Jinyuan Jia. 2025. {PoisonedRAG}: Knowledge corruption attacks to {Retrieval-Augmented} generation of large language models. In34th USENIX Security Symposium (USENIX Security 25). 3827–3844
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.