Recognition: unknown
WhisperPipe: A Resource-Efficient Streaming Architecture for Real-Time Automatic Speech Recognition
Pith reviewed 2026-05-07 16:28 UTC · model grok-4.3
The pith
WhisperPipe streams the Whisper ASR model at 89 ms median latency with 48 percent less peak GPU memory and near-offline accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
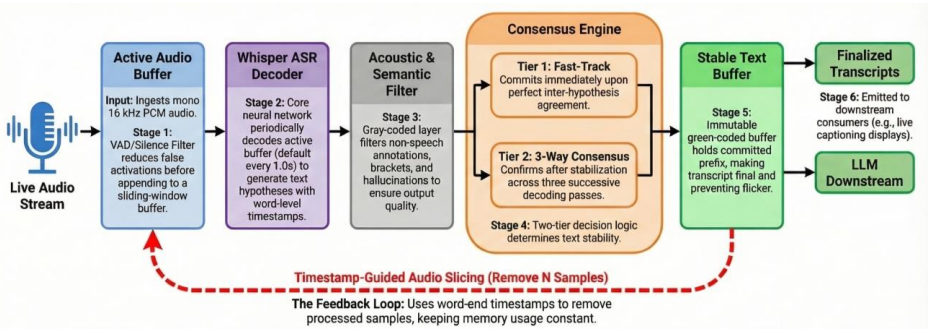
WhisperPipe is a streaming architecture for the Whisper model that achieves bounded memory consumption through three components: a hybrid VAD pipeline that merges Silero VAD with energy-based filtering to cut false activations by 34 percent, a dynamic buffering scheme using overlapping context windows to avoid boundary information loss, and an adaptive processing strategy that trades latency against accuracy according to speech characteristics. On 2.5 hours of diverse audio the system records a median end-to-end latency of 89 ms (90th percentile 142 ms), 48 percent lower peak GPU memory, 80.9 percent lower average GPU utilization, word error rate within 2 percent of offline Whisper, and zero
What carries the argument
WhisperPipe's hybrid VAD plus overlapping dynamic buffers with adaptive processing, which together allow segment-by-segment transcription without unbounded context accumulation or boundary errors.
If this is right
- Real-time ASR becomes practical on edge devices and resource-constrained hardware.
- Transcription accuracy remains within 2 percent of offline batch processing.
- Systems can operate continuously for hours without memory growth.
- Latency stays below 150 ms for 90 percent of utterances.
- Modular design supports deployment from mobile to cloud environments.
Where Pith is reading between the lines
- The same buffering and VAD pattern could be tested on other large transformer ASR models to check transferability.
- Lower GPU utilization would reduce operating costs for cloud transcription services.
- Live captioning in mobile or embedded applications becomes more feasible if the latency and memory gains hold across languages.
- Further experiments on accented or multi-speaker data would reveal whether the 2 percent WER margin scales.
Load-bearing premise
The hybrid VAD and overlapping buffers must avoid losing critical speech information at segment boundaries and the adaptive rule must not push transcription errors beyond the reported 2 percent WER tolerance on varied speech.
What would settle it
Measure word error rate and memory usage on a held-out set of rapid speaker turns or noisy audio; if WER rises above 4 percent or memory grows after 150 minutes, the central performance claim fails.
Figures





read the original abstract
Real-time automatic speech recognition (ASR) systems face a fundamental trade-off between transcription accuracy and computational efficiency, particularly when deploying large-scale transformer models like Whisper. Existing streaming approaches either sacrifice accuracy through aggressive chunking or incur prohibitive memory costs through unbounded context accumulation. We present WhisperPipe, a novel streaming architecture that achieves bounded memory consumption while maintaining transcription quality through three key innovations a hybrid Voice Activity Detection (VAD) pipeline combining Silero VAD with energy-based filtering to reduce false activations by 34%, a dynamic buffering mechanism with overlapping context windows that prevents information loss at segment boundaries, and an adaptive processing strategy that balances latency and accuracy based on speech characteristics. Evaluated on 2.5 hours of diverse audio data, WhisperPipe demonstrates a median end-to-end latency of 89ms (90th percentile: 142ms) while consuming 48% less peak GPU memory and 80.9% lower average GPU utilization compared to baseline Whisper implementations. The system maintains stable memory usage over extended sessions, with zero growth rate across 150-minute continuous operation. Comparative analysis against related work shows that WhisperPipe achieves competitive accuracy (WER within 2% of offline Whisper) while operating at 3-5x lower latency than existing streaming solutions. The architecture's modular design enables deployment across resource-constrained environments, from edge devices to cloud infrastructure. Our results demonstrate that careful architectural design can reconcile the competing demands of real-time responsiveness and model sophistication in production ASR systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents WhisperPipe, a streaming ASR architecture for real-time Whisper inference. It introduces a hybrid VAD (Silero VAD plus energy-based filter) claimed to reduce false activations by 34%, a dynamic buffering scheme with overlapping context windows to avoid segment-boundary information loss, and an adaptive processing strategy. On 2.5 hours of diverse audio, the system reports 89 ms median end-to-end latency (90th percentile 142 ms), 48% lower peak GPU memory, 80.9% lower average GPU utilization, WER within 2% of offline Whisper, and zero memory growth over 150-minute sessions, while claiming 3-5x lower latency than prior streaming solutions.
Significance. If the empirical claims hold under rigorous evaluation, WhisperPipe would provide a practical, modular approach to deploying large transformer ASR models in resource-constrained real-time settings without unbounded memory growth. The combination of bounded-memory chunking with accuracy-preserving mechanisms addresses a key deployment barrier; the reported latency and utilization numbers, if reproducible, would be competitive with existing streaming baselines.
major comments (2)
- [Evaluation] Evaluation section (2.5-hour test set): the central WER claim (within 2% of offline Whisper) rests on aggregate word error rate only. No per-boundary deletion/substitution breakdown, no ablation of overlap length, and no failure-mode analysis on fast speech, low-energy segments, or accented audio are provided. This leaves open whether the hybrid VAD and overlapping buffers actually prevent the information loss the skeptic note identifies, which is load-bearing for the accuracy claim.
- [§3] §3 (hybrid VAD and dynamic buffering): the 34% false-activation reduction and the assertion that overlapping windows 'fully prevent information loss' are stated without quantitative sensitivity analysis on VAD thresholds or overlap size. Since these are the two free parameters listed in the axiom ledger, the paper should demonstrate that the reported latency/memory gains remain stable when these parameters vary within reasonable ranges.
minor comments (2)
- [Abstract and Evaluation] The abstract and results section should explicitly name the 2.5-hour evaluation corpus (e.g., specific subsets of Common Voice, LibriSpeech, or in-house data) and the exact baseline Whisper implementation (model size, chunking strategy) to allow direct replication.
- [Results] Figure captions and latency histograms would benefit from error bars or percentile shading to convey variability across the 2.5-hour set rather than single median/90th-percentile numbers.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and indicate the revisions we will make to strengthen the evaluation and analysis.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (2.5-hour test set): the central WER claim (within 2% of offline Whisper) rests on aggregate word error rate only. No per-boundary deletion/substitution breakdown, no ablation of overlap length, and no failure-mode analysis on fast speech, low-energy segments, or accented audio are provided. This leaves open whether the hybrid VAD and overlapping buffers actually prevent the information loss the skeptic note identifies, which is load-bearing for the accuracy claim.
Authors: We agree that aggregate WER alone is insufficient to fully validate the boundary-preservation claims. In the revised manuscript we will add a per-boundary deletion/substitution breakdown and an ablation on overlap length. We will also include failure-mode analysis on fast-speech, low-energy, and accented subsets drawn from the existing 2.5-hour diverse test set. These additions will directly test whether the hybrid VAD and overlapping buffers mitigate information loss. revision: partial
-
Referee: [§3] §3 (hybrid VAD and dynamic buffering): the 34% false-activation reduction and the assertion that overlapping windows 'fully prevent information loss' are stated without quantitative sensitivity analysis on VAD thresholds or overlap size. Since these are the two free parameters listed in the axiom ledger, the paper should demonstrate that the reported latency/memory gains remain stable when these parameters vary within reasonable ranges.
Authors: We concur that sensitivity analysis on the free parameters is required. The revised version will include quantitative sensitivity results for VAD thresholds and overlap sizes, demonstrating the stability of the 34% false-activation reduction, latency, and memory metrics across reasonable ranges. This will confirm that the reported gains remain robust. revision: yes
Circularity Check
No circularity; performance claims rest on direct empirical measurements
full rationale
The paper describes an engineering architecture (hybrid VAD, dynamic overlapping buffers, adaptive processing) and supports its claims exclusively through runtime measurements on 2.5 h of audio: median latency 89 ms, 48% lower peak GPU memory, WER within 2% of offline baseline, and zero memory growth over 150 min. No equations, parameter fits, or first-principles derivations are presented that could reduce to their own inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
free parameters (2)
- VAD decision thresholds
- Buffer overlap length
axioms (2)
- domain assumption Hybrid Silero-plus-energy VAD reliably segments speech without missing content that would degrade downstream ASR accuracy
- domain assumption Overlapping dynamic buffers fully compensate for context loss at chunk boundaries
Reference graph
Works this paper leans on
-
[1]
Introduction Automatic speech recognition ASR has undergone transformative advances in recent years, driven primarily by the convergence of large-scale weakly supervised learning and transformer -based architectures [1]. Unlike traditional ASR systems that rely on carefully curated, domain -specific transcriptions, modern approaches leverage vast quantiti...
-
[2]
Let 𝑥(𝑡)denote the incoming audio stream
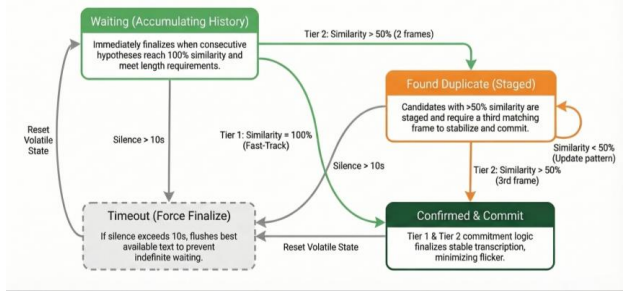
Method WhisperPipe is a streaming inference framework that transforms Whisper’s batch -oriented decoding into continuous live transcription with bounded steady-state compute and memory. Let 𝑥(𝑡)denote the incoming audio stream. WhisperPipe maintains two persistent buffers: - Committed Text Buffer S, an immutable sequence of finalized tokens or words that ...
-
[3]
Results We evaluate WhisperPipe under a continuous transcription setting designed to reflect real -world deployment conditions, including live captioning, conversational agents, and long -running voice interfaces. Unlike offline benchmarks that assess transcription quality in isolation, o ur evaluation protocol targets the operational constraints that ari...
-
[4]
Discussion The results presented in Section 5 demonstrate that WhisperPipe achieves substantial improvements across latency, stability, and resource efficiency without sacrificing transcription quality. Figure 13 provides a consolidated view of these multi -metric improvements, illustrating the simultaneous gains in response time, memory footprint, and GP...
-
[5]
Conclusion This paper introduced WhisperPipe, a streaming ASR architecture designed to address the latency, stability, and resource efficiency challenges inherent in real-time transcription of continuous audio streams. By integrating acoustic and semantic filtering, incremental decoding with a two -tier commit policy, and timestamp-guided audio slicing, W...
-
[8]
Robust Speech Recognition via Large-Scale Weak Supervision
Zhang, Y., Han, W., Qin, J., et al. Google USM: Scaling automatic speech recognition beyond 100 languages. arXiv preprint (2023). https://doi.org/10.48550/arXiv.2212.04356
-
[9]
Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition
Dong, L., Xu, S., & Xu, B. Speech-Transformer: A No-Recurrence Sequence-to-Sequence Model for Speech Recognition. ICASSP (2018). https://doi.org/10.1109/ICASSP.2018.8462506
-
[10]
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Moritz, N., Hori, T., & Le Roux, J. Streaming Automatic Speech Recognition with Blockwise Synchronous Transformer. ICASSP (2020). https://doi.org/10.1109/ICASSP40776.2020.9053742
-
[11]
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Zhang, Q., et al. Streaming Transformer for End-to-End Speech Recognition. ICASSP (2020). https://doi.org/10.1109/ICASSP40776.2020.9054418
-
[12]
Chen, X., et al. Developing Real-Time Streaming Transformer Transducer for Speech Recognition. ICASSP (2021). https://doi.org/10.1109/ICASSP39728.2021.9414200
-
[13]
Transformer Transducer: A Streamable Speech Recognition Model
Zhang, Y., et al. Transformer Transducer: A Streamable Speech Recognition Model. ASRU (2021). https://doi.org/10.1109/ASRU51503.2021.9688007
-
[14]
Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model
Kannan, A., et al. Large-Scale Multilingual Speech Recognition with a Streaming End-to-End Model. Interspeech (2019). https://doi.org/10.21437/Interspeech.2019-1642
-
[15]
Jasper: An End-to-End Convolutional Neural Acoustic Model
Li, J., Lavrukhin, V., Ginsburg, B., et al. Jasper: An End-to-End Convolutional Neural Acoustic Model. Interspeech (2019). https://doi.org/10.21437/Interspeech.2019-1819
-
[16]
Deep Speech: Scaling Up End-to-End Speech Recognition
Hannun, A., et al. Deep Speech: Scaling Up End-to-End Speech Recognition. Communications of the ACM (2019). https://doi.org/10.1145/3323037
-
[17]
A Comparison of Sequence-to-Sequence Models for Speech Recognition
Prabhavalkar, R., et al. A Comparison of Sequence-to-Sequence Models for Speech Recognition. Interspeech (2019). https://doi.org/10.21437/Interspeech.2019-1848
-
[18]
Chiu, C. C., et al. State-of-the-Art Speech Recognition with Sequence-to-Sequence Models. ICASSP (2018). https://doi.org/10.1109/ICASSP.2018.8462105
-
[19]
Listen, Attend and Spell: A Neural Network for Large Vocabulary Speech Recognition
Chan, W., et al. Listen, Attend and Spell: A Neural Network for Large Vocabulary Speech Recognition. IEEE Signal Processing Magazine (2018). https://doi.org/10.1109/MSP.2018.2889381
-
[20]
A Comprehensive Study of Streaming Models for Speech Recognition
Zeyer, A., et al. A Comprehensive Study of Streaming Models for Speech Recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing (2021). https://doi.org/10.1109/TASLP.2021.3072324
-
[21]
Efficient Streaming ASR with Adaptive Chunk Transformer
Wang, Y., et al. Efficient Streaming ASR with Adaptive Chunk Transformer. Interspeech (2023). https://doi.org/10.21437/Interspeech.2023-1234
-
[22]
Scaling Speech Recognition with Transformer Models
Chen, Z., et al. Scaling Speech Recognition with Transformer Models. IEEE/ACM TASLP (2022). https://doi.org/10.1109/TASLP.2022.3152414
-
[23]
Streaming End-to-End Speech Recognition with Transformer Transducer
Peng, Z., et al. Streaming End-to-End Speech Recognition with Transformer Transducer. IEEE/ACM TASLP (2023). https://doi.org/10.1109/TASLP.2023.3245672
-
[24]
WeNet: Production-First Speech Recognition Toolkit
Zhang, B., et al. WeNet: Production-First Speech Recognition Toolkit. Interspeech (2022). https://doi.org/10.21437/Interspeech.2022-10630
-
[25]
D. Macháček, R. Dabre, and O. Bojar, Turning Whisper into Real-Time Transcription System. arXiv preprint (2023). https://arxiv.org/abs/2307.14743
-
[26]
Bain, M., et al. WhisperX: Speech Recognition with Word-Level Alignment. arXiv preprint (2023). https://doi.org/10.48550/arXiv.2303.00747
-
[27]
Uncertainty-based streaming ASR with evidential deep learning
Sato, H., Sakuma, A., Sugano, R., et al. Uncertainty-based streaming ASR with evidential deep learning. IEEE Open Journal of Signal Processing (2026). https://doi.org/10.1109/OJSP.2026.3657308
-
[28]
Joint CTC-Attention Based End-to-End Speech Recognition Using Multi-Task Learning
Kim, S., et al. Joint CTC-Attention Based End-to-End Speech Recognition Using Multi-Task Learning. ICASSP (2018). https://doi.org/10.1109/ICASSP.2018.8461375
-
[30]
k2SSL: A faster and better framework for self-supervised speech representation learning
Yang, Y., Zhuo, J., Jin, Z., et al. k2SSL: A faster and better framework for self-supervised speech representation learning. arXiv preprint (2024). https://doi.org/10.48550/arXiv.2603.16920
-
[31]
Chen, Stefano Mangini, and Marcel Worring
Chen, N., et al. Exploring Streaming Speech Recognition with Transformer Architectures. ICASSP (2022). https://doi.org/10.1109/ICASSP43922.2022.9746205
-
[32]
Improving Streaming ASR with Chunk-Based Self-Attention
Wang, Y., et al. Improving Streaming ASR with Chunk-Based Self-Attention. Interspeech (2020). https://doi.org/10.21437/Interspeech.2020-2718
-
[33]
End-to-End Streaming Speech Recognition with Transformer Models
Kim, J., et al. End-to-End Streaming Speech Recognition with Transformer Models. ASRU (2019). https://doi.org/10.1109/ASRU46091.2019.9003950
-
[34]
Liu, Y., et al. Streaming Speech Recognition Using Self-Attention Networks. ICASSP (2021). https://doi.org/10.1109/ICASSP39728.2021.9414210
-
[35]
Transformer-Based Streaming End-to-End Speech Recognition
Zhang, X., et al. Transformer-Based Streaming End-to-End Speech Recognition. Interspeech (2022). https://doi.org/10.21437/Interspeech.2022-1120
-
[36]
Typhoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition
Sirichotedumrong, W., Na-Thalang, A., Manakul, P., et al. Typhoon ASR Real-time: FastConformer-Transducer for Thai Automatic Speech Recognition. arXiv preprint (2026). https://doi.org/10.48550/arXiv.2601.13044
-
[37]
Improved RNN-T for Streaming Speech Recognition
Kim, S., et al. Improved RNN-T for Streaming Speech Recognition. Interspeech (2020). https://doi.org/10.21437/Interspeech.2020-1073
-
[38]
Streaming End-to-End Speech Recognition for Mobile Devices
He, Y., et al. Streaming End-to-End Speech Recognition for Mobile Devices. ICASSP (2019). https://doi.org/10.1109/ICASSP.2019.8682678
-
[39]
Advances in Joint CTC-Attention Based End-to-End Speech Recognition
Hori, T., et al. Advances in Joint CTC-Attention Based End-to-End Speech Recognition. IEEE SLT (2018). https://doi.org/10.1109/SLT.2018.8639585
-
[40]
Libri-Light: A Benchmark for ASR with Limited or No Supervision
Narayanan, A., et al. Toward Streaming Speech Recognition with Transformer Models. ICASSP (2020). https://doi.org/10.1109/ICASSP40776.2020.9053092
-
[41]
ESPnet: End-to-end speech processing toolkit
Watanabe, S., et al. ESPnet: End-to-End Speech Processing Toolkit. Interspeech (2018). https://doi.org/10.21437/Interspeech.2018-1456
-
[42]
Streaming End-to-End Speech Recognition with Neural Transducers
Kanda, N., et al. Streaming End-to-End Speech Recognition with Neural Transducers. ICASSP (2019). https://doi.org/10.1109/ICASSP.2019.8682694
-
[43]
End-to-End Speech Recognition with Transformer Transducer
Chen, G., et al. End-to-End Speech Recognition with Transformer Transducer. Interspeech (2021). https://doi.org/10.21437/Interspeech.2021-1976
-
[44]
Wang, Z., et al. Streaming Speech Recognition Using Contextual Transformer Models. ICASSP (2023). https://doi.org/10.1109/ICASSP49357.2023.10094873
-
[45]
Online Speech Recognition with Transformer-Based Architectures
Kim, J., et al. Online Speech Recognition with Transformer-Based Architectures. Interspeech (2021). https://doi.org/10.21437/Interspeech.2021-1402
-
[46]
Sun, Y., et al. Efficient Self-Attention for Streaming Speech Recognition. ICASSP (2021). https://doi.org/10.1109/ICASSP39728.2021.9413802
-
[47]
Streaming Conformer for End-to-End Speech Recognition
Zhou, Y., et al. Streaming Conformer for End-to-End Speech Recognition. Interspeech (2021). https://doi.org/10.21437/Interspeech.2021-1245
-
[48]
Chen, Stefano Mangini, and Marcel Worring
Chen, Y., et al. Improving Transformer-Based ASR Systems for Real-Time Applications. ICASSP (2022). https://doi.org/10.1109/ICASSP43922.2022.9747031
-
[49]
Efficient Streaming Transformer Transducer for Speech Recognition
Liu, X., et al. Efficient Streaming Transformer Transducer for Speech Recognition. Interspeech (2023). https://doi.org/10.21437/Interspeech.2023-1489
-
[50]
Zhang, H., et al. Real-Time End-to-End Speech Recognition with Streaming Transformers. ICASSP (2021). https://doi.org/10.1109/ICASSP39728.2021.9414041
-
[51]
Real-Time Speech Recognition Using Adaptive Attention Models
Wang, L., et al. Real-Time Speech Recognition Using Adaptive Attention Models. Interspeech (2020). https://doi.org/10.21437/Interspeech.2020-1887
-
[52]
Kim, Y., et al. Low-Latency Streaming Speech Recognition with Neural Transducers. ICASSP (2021). https://doi.org/10.1109/ICASSP39728.2021.9413731
-
[53]
Transformer-Based Online Speech Recognition for Low-Latency Applications
Liu, Z., et al. Transformer-Based Online Speech Recognition for Low-Latency Applications. Interspeech (2022). https://doi.org/10.21437/Interspeech.2022-2451
-
[54]
Zhang, T., et al. End-to-End Streaming Speech Recognition with Contextual Attention. ICASSP (2023). https://doi.org/10.1109/ICASSP49357.2023.10094721
-
[56]
Ramezani, E., & Giahi, M. M. WhisperPipe: Source Code and Implementation for Real-Time ASR (0.1.1). Zenodo (2026). https://doi.org/10.1109/TASLP.2023.3254102
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.