Recognition: unknown
Deflation-Free Optimal Scoring
Pith reviewed 2026-05-07 14:25 UTC · model grok-4.3
The pith
A deflation-free approach estimates all sparse discriminant vectors simultaneously under a global orthogonality constraint.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proposes Deflation-Free Sparse Optimal Scoring (DFSOS) that estimates all discriminant vectors simultaneously under an explicit global orthogonality constraint by combining Bregman iteration with orthogonality-constrained optimization, decomposing the problem into tractable subproblems for scoring vectors, discriminant vectors, and orthogonality enforcement, establishing convergence to stationary points of the augmented Lagrangian under mild conditions, and showing through experiments that it achieves classification accuracy comparable to or better than existing deflation-based methods.
What carries the argument
The simultaneous estimation of all discriminant vectors under a global orthogonality constraint, decomposed via Bregman iteration into subproblems for scoring vectors, discriminant vectors, and orthogonality enforcement.
If this is right
- Eliminates error propagation that arises when discriminant vectors are computed one after another.
- Maintains or improves classification accuracy in settings where features outnumber observations.
- Provides convergence guarantees to stationary points under mild conditions on the augmented Lagrangian.
- Applies directly to high-dimensional classification tasks including time series data.
Where Pith is reading between the lines
- The same simultaneous-plus-global-constraint pattern could replace deflation in other sequential sparse optimization routines such as sparse PCA variants.
- In domains with very high feature-to-sample ratios, the absence of sequential error buildup may become more pronounced as dimension grows.
- The decomposition into independent subproblems suggests the method could be parallelized more readily than deflation sequences.
Load-bearing premise
Enforcing the global orthogonality constraint simultaneously does not introduce new instabilities or reduce the sparsity benefits compared to sequential deflation.
What would settle it
A high-dimensional dataset where DFSOS yields lower classification accuracy, less sparse solutions, or fails to converge while deflation-based methods succeed would show the simultaneous approach does not deliver the claimed benefits.
Figures




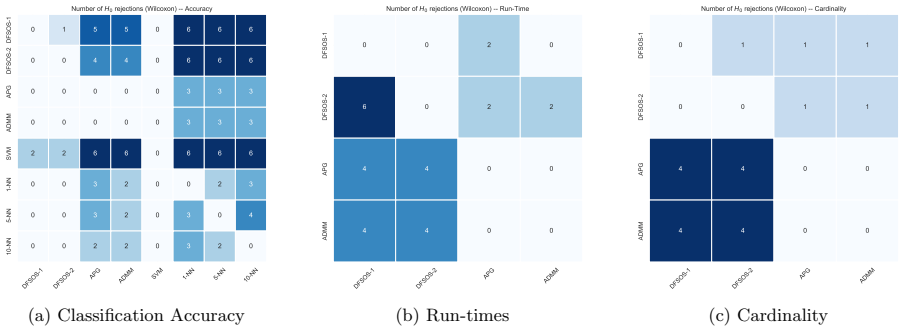
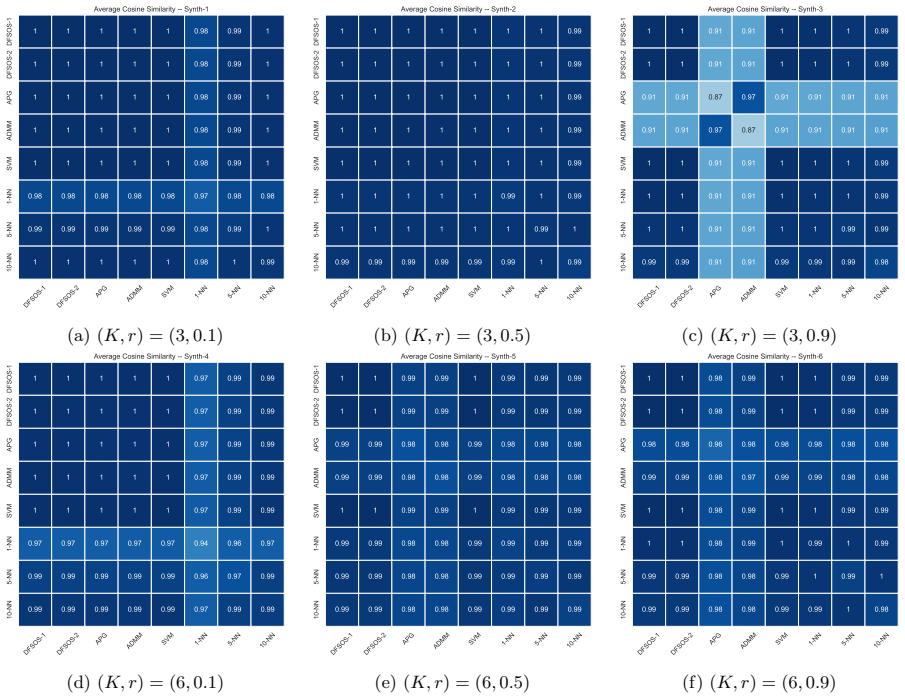


read the original abstract
Sparse Optimal Scoring (SOS) reformulates linear discriminant analysis to enable feature selection through elastic net regularization, making it well-suited for high-dimensional settings where the number of features exceeds observations. Most existing SOS methods use deflation-based strategies that compute discriminant vectors sequentially, which can propagate errors and produce suboptimal solutions. We propose a novel approach that estimates all discriminant vectors simultaneously under an explicit global orthogonality constraint, which we call Deflation-Free Sparse Optimal Scoring (DFSOS). DFSOS combines Bregman iteration with orthogonality-constrained optimization, decomposing the problem into tractable subproblems for scoring vectors, discriminant vectors, and orthogonality enforcement. We establish convergence to stationary points of the augmented Lagrangian under mild conditions. Extensive experiments using synthetic data and real-world time series data demonstrate that DFSOS achieves classification accuracy comparable to or better than existing deflation-based methods. These results indicate that deflation-free approaches offer a robust and effective framework for sparse discriminant analysis in high-dimensional problems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Deflation-Free Sparse Optimal Scoring (DFSOS) for high-dimensional sparse linear discriminant analysis. It reformulates the problem to estimate all discriminant vectors simultaneously under an explicit global orthogonality constraint by combining Bregman iteration with orthogonality-constrained optimization, decomposing the task into subproblems for scoring vectors, discriminant vectors, and orthogonality enforcement. The authors claim convergence to stationary points of the augmented Lagrangian under mild conditions and report that experiments on synthetic and real-world time-series data yield classification accuracy comparable to or better than deflation-based SOS methods.
Significance. If the convergence result and empirical claims hold, the work provides a technically interesting alternative to sequential deflation in sparse LDA, potentially mitigating error propagation while maintaining the feature-selection benefits of elastic-net regularization. The simultaneous global orthogonality enforcement via Bregman decomposition is a clear methodological contribution if it produces stationary points that are at least as good as deflation baselines in objective value and sparsity.
major comments (3)
- [Convergence Analysis] The convergence claim to stationary points under mild conditions (abstract and convergence section) does not verify that these conditions remain satisfied in the high-dimensional regimes (p ≫ n) used in the experiments; the augmented Lagrangian could become ill-conditioned when elastic-net regularization interacts with the orthogonality penalty, risking unstable or suboptimal stationary points.
- [Experimental Results] The central empirical claim that DFSOS achieves comparable or better accuracy relies on experiments (synthetic and time-series sections), but the manuscript provides no quantitative accuracy values, standard deviations, number of runs, or direct objective-value/sparsity comparisons to deflation baselines; without these, it is impossible to confirm that the simultaneous solutions avoid deflation's error propagation or preserve sparsity benefits.
- [Method and Experiments] The assertion that simultaneous estimation under global orthogonality yields superior or equivalent solutions to sequential deflation (introduction and method sections) is not supported by any demonstration that the obtained stationary points achieve lower or equal values of the original SOS objective or maintain comparable sparsity levels; this comparison is load-bearing for the claim of robustness.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments on our manuscript. We address each major comment below, providing honest responses and indicating the revisions we will make to strengthen the presentation and evidence.
read point-by-point responses
-
Referee: [Convergence Analysis] The convergence claim to stationary points under mild conditions (abstract and convergence section) does not verify that these conditions remain satisfied in the high-dimensional regimes (p ≫ n) used in the experiments; the augmented Lagrangian could become ill-conditioned when elastic-net regularization interacts with the orthogonality penalty, risking unstable or suboptimal stationary points.
Authors: We agree that the convergence theorem is presented under mild conditions without an explicit verification or discussion tailored to the high-dimensional p ≫ n regimes in the experiments. The conditions (bounded penalty parameters, Lipschitz continuity of the objective) are dimension-independent in the proof, but we did not address potential ill-conditioning from the interaction of elastic-net and orthogonality terms. In the revision, we will expand the convergence section with a remark on applicability to high dimensions and add numerical monitoring of convergence behavior and penalty parameters in the experimental results to confirm stability. revision: yes
-
Referee: [Experimental Results] The central empirical claim that DFSOS achieves comparable or better accuracy relies on experiments (synthetic and time-series sections), but the manuscript provides no quantitative accuracy values, standard deviations, number of runs, or direct objective-value/sparsity comparisons to deflation baselines; without these, it is impossible to confirm that the simultaneous solutions avoid deflation's error propagation or preserve sparsity benefits.
Authors: The referee is correct that the experimental sections report only qualitative statements on accuracy without providing mean values, standard deviations, the number of repetitions, or direct comparisons of the SOS objective and sparsity levels. This limits the ability to assess the claims quantitatively. We will revise the synthetic and time-series experiments to include tables with these statistics (e.g., averages and standard deviations over 20 runs) and add direct comparisons of objective values and selected feature counts against deflation baselines. revision: yes
-
Referee: [Method and Experiments] The assertion that simultaneous estimation under global orthogonality yields superior or equivalent solutions to sequential deflation (introduction and method sections) is not supported by any demonstration that the obtained stationary points achieve lower or equal values of the original SOS objective or maintain comparable sparsity levels; this comparison is load-bearing for the claim of robustness.
Authors: We acknowledge that while classification accuracy serves as an indirect indicator, the manuscript does not explicitly demonstrate that the stationary points of the augmented Lagrangian achieve objective values lower than or equal to deflation-based solutions or preserve comparable sparsity. To support the robustness claim, the revised manuscript will include additional analysis in the experimental section with side-by-side objective value and sparsity comparisons, showing that DFSOS solutions are at least as good as the baselines in these metrics. revision: yes
Circularity Check
No circularity: algorithmic reformulation with independent convergence analysis
full rationale
The paper's derivation chain consists of reformulating sparse optimal scoring as a joint optimization problem with explicit global orthogonality, then applying Bregman iteration to decompose into subproblems whose stationary points are shown to satisfy the augmented Lagrangian under stated mild conditions. No quoted step reduces a claimed result to a fitted parameter renamed as prediction, a self-referential definition, or a load-bearing self-citation whose content is unverified. The convergence claim is presented as a theorem derived from the algorithm's structure rather than presupposing the target performance metrics, and experiments are treated as external validation rather than inputs to the derivation. This is the normal case of a self-contained algorithmic contribution.
Axiom & Free-Parameter Ledger
free parameters (1)
- elastic net regularization parameters
axioms (1)
- domain assumption Bregman iteration converges to stationary points of the augmented Lagrangian under mild conditions
Reference graph
Works this paper leans on
-
[1]
Absil, R
P.-A. Absil, R. Mahony, and R. Sepulchre.Optimization algorithms on matrix manifolds. Princeton University Press, Princeton, NJ, 2008
2008
-
[2]
Atkins, G
S. Atkins, G. Einarsson, L. Clemmensen, and B. Ames. Proximal methods for sparse optimal scoring and discriminant analysis.Advances in Data Analysis and Classification, 17(4):983–1036, 2023
2023
-
[3]
Riemannian Adaptive Optimization Methods
G. B´ ecigneul and O.-E. Ganea. Riemannian adaptive optimization methods.arXiv preprint arXiv:1810.00760, 2018
work page Pith review arXiv 2018
-
[4]
Bonnabel
S. Bonnabel. Stochastic gradient descent on Riemannian manifolds.IEEE Transactions on Auto- matic Control, 58(9):2217–2229, 2013
2013
-
[5]
Boumal.An introduction to optimization on smooth manifolds
N. Boumal.An introduction to optimization on smooth manifolds. Cambridge University Press, Cambridge, 2023
2023
-
[6]
Burer and R
S. Burer and R. D. Monteiro. A nonlinear programming algorithm for solving semidefinite programs via low-rank factorization.Mathematical programming, 95(2):329–357, 2003
2003
-
[7]
Cai and W
T. Cai and W. Liu. A direct estimation approach to sparse linear discriminant analysis.Journal of the American statistical association, 106(496):1566–1577, 2011. 19
2011
-
[8]
S. Chen, S. Ma, A. Man-Cho So, and T. Zhang. Nonsmooth optimization over the Stiefel manifold and beyond: Proximal gradient method and recent variants.SIAM Review, 66(2):319–352, 2024
2024
-
[9]
Clemmensen, T
L. Clemmensen, T. Hastie, D. Witten, and B. Ersbøll. Sparse discriminant analysis.Technometrics, 53(4):406–413, 2011
2011
-
[10]
H. A. Dau, A. Bagnall, K. Kamgar, C.-C. M. Yeh, Y. Zhu, S. Gharghabi, C. A. Ratanamahatana, and E. Keogh. The UCR time series archive.IEEE/CAA Journal of Automatica Sinica, 6(6):1293– 1305, 2019
2019
-
[11]
Efron, T
B. Efron, T. Hastie, I. Johnstone, and R. Tibshirani. Least angle regression.Annals of Statistics, pages 407–451, 2004
2004
-
[12]
J. Fan, Y. Feng, and X. Tong. A road to classification in high dimensional space: the regularized optimal affine discriminant.Journal of the Royal Statistical Society Series B: Statistical Methodology, 74(4):745–771, 2012
2012
-
[13]
B. Gao, N. T. Son, P.-A. Absil, and T. Stykel. Riemannian optimization on the symplectic Stiefel manifold.SIAM Journal on Optimization, 31(2):1546–1575, 2021
2021
-
[14]
Y. Guo, T. Hastie, and R. Tibshirani. Regularized linear discriminant analysis and its application in microarrays.Biostatistics, 8(1):86–100, 2007
2007
-
[15]
Hastie, A
T. Hastie, A. Buja, and R. Tibshirani. Penalized discriminant analysis.The Annals of Statistics, 23(1):73–102, 1995
1995
-
[16]
Hastie, R
T. Hastie, R. Tibshirani, and A. Buja. Flexible discriminant analysis by optimal scoring.Journal of the American statistical association, 89(428):1255–1270, 1994
1994
-
[17]
Hastie, R
T. Hastie, R. Tibshirani, and J. H. Friedman.The elements of statistical learning: data mining, inference, and prediction, volume 2. Springer, 2009
2009
- [18]
-
[19]
Jiang, X
B. Jiang, X. Meng, Z. Wen, and X. Chen. An exact penalty approach for optimization with non- negative orthogonality constraints.Mathematical Programming, 198(1):855–897, 2023
2023
-
[20]
Lai and S
R. Lai and S. Osher. A splitting method for orthogonality constrained problems.Journal of Scientific Computing, 58:431–449, 2014
2014
- [21]
-
[22]
Lai, L.-H
Z. Lai, L.-H. Lim, and K. Ye. Grassmannian optimization is NP-hard.SIAM Journal on Optimiza- tion, 35(3):1939–1962, 2025
1939
-
[23]
X. Li, S. Chen, Z. Deng, Q. Qu, Z. Zhu, and A. Man-Cho So. Weakly convex optimization over Stiefel manifold using Riemannian subgradient-type methods.SIAM Journal on Optimization, 31(3):1605–1634, 2021
2021
-
[24]
Z. Lin, H. Li, and C. Fang.Alternating direction method of multipliers for machine learning. Springer, Singapore, 2022
2022
-
[25]
Liu and N
C. Liu and N. Boumal. Simple algorithms for optimization on Riemannian manifolds with con- straints.Applied Mathematics & Optimization, 82(3):949–981, 2020
2020
-
[26]
Mai and H
Q. Mai and H. Zou. A note on the connection and equivalence of three sparse linear discriminant analysis methods.Technometrics, 55(2):243–246, 2013
2013
-
[27]
Q. Mai, H. Zou, and M. Yuan. A direct approach to sparse discriminant analysis in ultra-high dimensions.Biometrika, 99(1):29–42, 2012
2012
-
[28]
Rosset and J
S. Rosset and J. Zhu. Piecewise linear regularized solution paths.The Annals of Statistics, pages 1012–1030, 2007. 20
2007
-
[29]
Sato.Riemannian optimization and its applications, volume 670
H. Sato.Riemannian optimization and its applications, volume 670. Springer, Berlin, 2021
2021
-
[30]
J. Shao, Y. Wang, X. Deng, and S. Wang. Sparse linear discriminant analysis by thresholding for high dimensional data.The Annals of Statistics, 39(2):1241–1265, 2011
2011
-
[31]
Statistics and Machine Learning Toolbox, 2022
The MathWorks Inc. Statistics and Machine Learning Toolbox, 2022
2022
-
[32]
MATLAB version: 9.14.0 (R2023a), 2023
The MathWorks Inc. MATLAB version: 9.14.0 (R2023a), 2023
2023
-
[33]
Statistics and Machine Learning Toolbox (R2023a), 2023
The MathWorks Inc. Statistics and Machine Learning Toolbox (R2023a), 2023
2023
-
[34]
Y. Wang, W. Yin, and J. Zeng. Global convergence of admm in nonconvex nonsmooth optimization. Journal of Scientific Computing, 78:29–63, 2019
2019
-
[35]
Wen and W
Z. Wen and W. Yin. A feasible method for optimization with orthogonality constraints.Mathematical Programming, 142(1):397–434, 2013
2013
-
[36]
D. M. Witten and R. Tibshirani. Penalized classification using Fisher’s linear discriminant.Journal of the Royal Statistical Society Series B: Statistical Methodology, 73(5):753–772, 2011
2011
-
[37]
Zhang and S
H. Zhang and S. Sra. First-order methods for geodesically convex optimization. InConference on learning theory, pages 1617–1638. PMLR, 2016
2016
-
[38]
Zou and T
H. Zou and T. Hastie. Regularization and variable selection via the elastic net.Journal of the Royal Statistical Society Series B: Statistical Methodology, 67(2):301–320, 2005. 21
2005
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.