Recognition: unknown
CORAL: Adaptive Retrieval Loop for Culturally-Aligned Multilingual RAG
Pith reviewed 2026-05-07 16:02 UTC · model grok-4.3
The pith
CORAL introduces an iterative agentic loop that refines retrieval corpora and queries based on evidence critique to better align multilingual RAG with cultural context.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
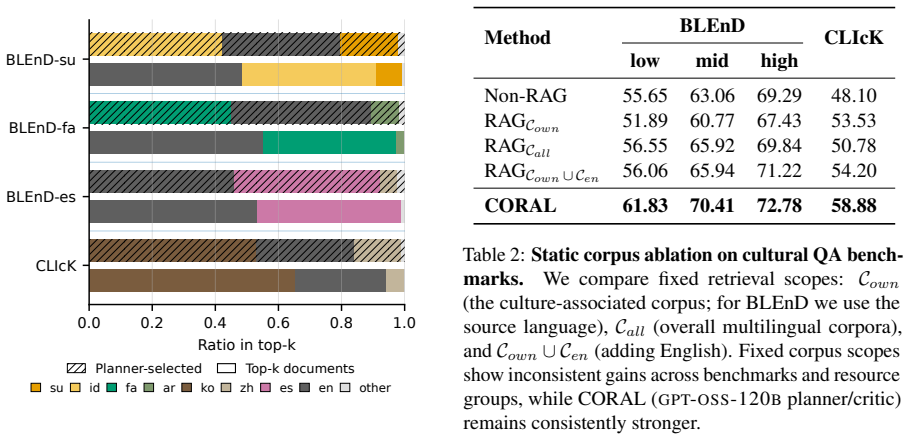
CORAL (COntext-aware Retrieval with Agentic Loop) is an adaptive methodology for multilingual retrieval-augmented generation that performs iterative refinement of both the retrieval space (corpora) and the retrieval probe (query) according to the quality of retrieved evidence. The loop consists of selecting corpora, retrieving documents, critiquing the evidence for relevance and cultural alignment, checking sufficiency for a correct answer, and, if insufficient, reselecting corpora and rewriting the query. On two cultural QA benchmarks this yields accuracy improvements of up to 3.58 percentage points on low-resource languages relative to the strongest fixed-retrieval baselines.
What carries the argument
The agentic retrieval loop that critiques evidence for cultural alignment and sufficiency then triggers corpus reselection and query rewriting when the current evidence is inadequate.
If this is right
- Multilingual RAG systems can handle culturally specific questions more reliably by dynamically adjusting the language and regional scope of retrieved documents.
- Low-resource languages benefit disproportionately because the loop compensates for sparse or misaligned initial retrieval results.
- Overall mRAG pipelines become more robust to retrieval-condition misalignment without requiring larger base models or bigger static corpora.
- The same iterative critique-and-rewrite pattern could reduce hallucination or cultural insensitivity in other retrieval-augmented tasks.
Where Pith is reading between the lines
- Similar adaptive loops might be applied to non-cultural domains where context alignment matters, such as technical or legal queries that require precise domain corpora.
- The method implies a trade-off between extra inference steps and final accuracy that could be measured as a cost-benefit curve for production systems.
- If the critique model itself carries cultural biases, the loop could amplify rather than correct them, suggesting the need for independent validation of the critic.
Load-bearing premise
The critique step can reliably detect cultural misalignment and evidence gaps without introducing its own errors or biases, and further iterations will improve rather than harm final answer quality.
What would settle it
Running the full CORAL pipeline on the same two cultural QA benchmarks and finding that final accuracy is equal to or lower than the strongest non-iterative baseline, or that additional iterations frequently degrade the answer.
Figures









read the original abstract
Multilingual retrieval-augmented generation (mRAG) is often implemented within a fixed retrieval space, typically via query or document translation or multilingual embedding vector representations. However, this approach may be inadequate for culturally grounded queries, in which retrieval-condition misalignment may occur. Even strong retrievers and generators may struggle to produce culturally relevant answers when sourcing evidence from inappropriate linguistic or regional contexts. To this end, we introduce CORAL (COntext-aware Retrieval with Agentic Loop, an adaptive retrieval methodology for mRAG that enables iterative refinement of both the retrieval space (corpora) and the retrieval probe (query) based on the quality of the evidence. The overall process includes: (1) selecting corpora, (2) retrieving documents, (3) critiquing evidence for relevance and cultural alignment, and (4) checking sufficiency. If the retrieved documents are insufficient to answer the query correctly, the system (5) reselects corpora and rewrites the query. Across two cultural QA benchmarks, CORAL achieves up to a 3.58%p accuracy improvement on low-resource languages relative to the strongest baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CORAL (COntext-aware Retrieval with Agentic Loop), an adaptive retrieval methodology for multilingual RAG. It iteratively refines the retrieval space (via corpus reselection) and retrieval probe (via query rewrite) through a loop of corpus selection, document retrieval, evidence critique for relevance/cultural alignment/sufficiency, and re-iteration if evidence is insufficient. The central empirical claim is an accuracy improvement of up to 3.58 percentage points on low-resource languages relative to the strongest baselines, evaluated on two cultural QA benchmarks.
Significance. If the reported gains are robust and the critique mechanism proves reliable, the work could meaningfully advance culturally-sensitive mRAG by moving beyond fixed retrieval spaces. The focus on low-resource languages and explicit handling of cultural misalignment addresses a practical gap in current multilingual systems.
major comments (2)
- [Abstract / §3 (Methodology)] Abstract and methodology description: The critique step (step 3) is presented as judging 'relevance and cultural alignment' without any implementation details, model choice, prompting strategy, or human validation of its judgments. This is load-bearing for the central claim, as systematic errors in the critic (e.g., English-centric bias) would cause incorrect corpus reselection or query rewrites, directly undermining or reversing the claimed 3.58%p gains on low-resource languages.
- [Experimental Results] Results section: No ablation studies, statistical significance tests, variance across runs, or isolation of the critique/iteration components are described. Without these, it is impossible to attribute the reported improvement specifically to the adaptive loop rather than other factors such as better base retrievers or prompt engineering.
minor comments (1)
- [Abstract] The acronym expansion 'COntext-aware' contains an inconsistent capitalization that should be standardized.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback, which highlights important areas for improving the clarity and rigor of our work on CORAL. We address each major comment below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / §3 (Methodology)] Abstract and methodology description: The critique step (step 3) is presented as judging 'relevance and cultural alignment' without any implementation details, model choice, prompting strategy, or human validation of its judgments. This is load-bearing for the central claim, as systematic errors in the critic (e.g., English-centric bias) would cause incorrect corpus reselection or query rewrites, directly undermining or reversing the claimed 3.58%p gains on low-resource languages.
Authors: We agree that the critique mechanism requires more explicit documentation to support the central claims. The full manuscript describes the critique at a high level as an LLM-based evaluation of relevance, cultural alignment, and sufficiency, but we acknowledge the absence of prompt templates, model specifications, and validation details in the provided sections. In the revision, we will expand §3 with the exact prompting strategy (including the full template and few-shot examples), the specific model used for critique (a multilingual LLM to mitigate English-centric bias), and any post-hoc checks performed. We will also add a brief discussion of potential biases and how the iterative loop design helps recover from individual critique errors. These changes will be incorporated directly into the methodology and referenced in the abstract. revision: yes
-
Referee: [Experimental Results] Results section: No ablation studies, statistical significance tests, variance across runs, or isolation of the critique/iteration components are described. Without these, it is impossible to attribute the reported improvement specifically to the adaptive loop rather than other factors such as better base retrievers or prompt engineering.
Authors: We concur that the current experimental presentation would be strengthened by additional analyses to isolate the contribution of the agentic loop. The reported gains are measured against strong baselines on two benchmarks, but we accept that without ablations it is difficult to rule out confounding factors. In the revised manuscript, we will add ablation experiments (e.g., variants without critique or without iteration), report statistical significance via appropriate tests (such as McNemar's test for paired accuracy differences), and include variance measures across multiple runs with different seeds. These results will be presented in an expanded results section with tables showing the isolated impact of each component. This will allow readers to attribute improvements more confidently to the adaptive retrieval loop. revision: yes
Circularity Check
No circularity: purely empirical methodology with benchmark-reported results
full rationale
The paper describes an iterative retrieval loop (corpus selection, document retrieval, evidence critique for relevance/cultural alignment/sufficiency, and conditional query rewrite or corpus reselection) and reports accuracy gains on two cultural QA benchmarks. No equations, parameters, or derivations are present. No self-citations are invoked to establish uniqueness, ansatzes, or load-bearing premises. The reported improvements are external benchmark outcomes rather than quantities that reduce to the method's own inputs by construction. Absence of implementation details for the critique module raises questions of reproducibility and assumption validity but does not constitute circularity in any derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Existing retrievers and generators can be improved by iterative refinement rather than single-pass retrieval.
invented entities (1)
-
CORAL adaptive retrieval loop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Mao-arag: Multi-agent orchestration for adaptive retrieval-augmented generation.Preprint, arXiv:2508.01005. Nadezhda Chirkova, David Rau, Hervé Déjean, Thibault Formal, Stéphane Clinchant, and Vassilina Nikoulina
-
[2]
InProceedings of the 1st Work- shop on Towards Knowledgeable Language Models (KnowLLM 2024), pages 177–188, Bangkok, Thai- land
Retrieval-augmented generation in multi- lingual settings. InProceedings of the 1st Work- shop on Towards Knowledgeable Language Models (KnowLLM 2024), pages 177–188, Bangkok, Thai- land. Association for Computational Linguistics. Youan Cong, Pritom Saha Akash, Cheng Wang, and Kevin Chen-Chuan Chang. 2025. Query optimiza- tion for parametric knowledge ref...
2024
-
[3]
The faiss library.Preprint, arXiv:2401.08281. Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al- Dahle, Aiesha Letman, Akhil Mathur, Alan Schel- ten, Alex Vaughan, Amy Yang, Angela Fan, Anirudh Goyal, Anthony Hartshorn, Aobo Yang, Archi Mi- tra, Archie Sravankumar, Artem Korenev, Arthur Hinsvark, and 542 others....
work page internal anchor Pith review arXiv 2024
-
[4]
Towards geo-culturally grounded LLM gen- erations. InProceedings of the 63rd Annual Meet- ing of the Association for Computational Linguistics (Volume 2: Short Papers), pages 313–330, Vienna, Austria. Association for Computational Linguistics. Will LeVine and Bijan Varjavand. 2025. Relevance isn’t all you need: Scaling RAG systems with inference- time com...
-
[5]
In Findings of the Association for Computational Lin- guistics: EACL 2026, pages 697–716, Rabat, Mo- rocco
Multilingual retrieval-augmented generation for knowledge-intensive question answering task. In Findings of the Association for Computational Lin- guistics: EACL 2026, pages 697–716, Rabat, Mo- rocco. Association for Computational Linguistics. Nandan Thakur, Suleman Kazi, Ge Luo, Jimmy Lin, and Amin Ahmad. 2025. MIRAGE-bench: Auto- matic multilingual benc...
2026
-
[6]
SeaKR: Self-aware knowledge retrieval for adaptive retrieval augmented generation. InProceed- ings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers), pages 27022–27043, Vienna, Austria. Associa- tion for Computational Linguistics. Ye Yuan, Chengwu Liu, Jingyang Yuan, Gongbo Sun, Siqi Li, and Ming Zhang. ...
-
[7]
Queries exceeding the model’s context length were excluded from evaluation
To comply with the model’s context length, the number of retrieved documents (top-k) was limited to 1.† indicates that the model was trained by the authors separately. Queries exceeding the model’s context length were excluded from evaluation. SYSTEM PROMPT: You are a helpful AI Assistant with expertise in cultural and linguistic content classification, a...
-
[8]
Always include the corpus whose language code matches the primary language of the query
-
[9]
If some corpora are **content-wise** relevant (country, region, culture, institution, person, etc.), you may additionally select them. - The query explicitly contains terms in another language or the user’s intent clearly bene- fits from cross-language retrieval (e.g., looking for translations, comparative cultural information). - Example: A topic about J...
-
[11]
just in case
**Never** add a corpus "just in case". Choose only a small, realistically useful set
-
[12]
id", "am
Use only language codes that appear in the following langauge pools. **Never invent new names**. Language Pools:["id", "am", "su", "ar", "ha", "en", "zh", "ko", "as", "el", "fa", "es", "az"] [Output format] Return **exactly** the following JSON object **as a single continuous line with no surrounding whitespace, line breaks, or markdown formatting**: {"la...
-
[13]
**Select language corpora** for the next retrieval round
-
[14]
You MUST NOT simply repeat the previous decision
**Rewrite the query** to improve retrieval quality, grounded in the system’s reasoning. You MUST NOT simply repeat the previous decision. At least one of the following must change: - the set of language codes (‘language_names‘), OR - the rewritten query (focus, structure, or keywords). [Corpus selection rules]
-
[15]
Always include the corpus whose language code matches the **primary language** of the original query, unless the system’s reasoning explicitly shows it is consistently low-relevance
-
[16]
- Example: a topic about Japan→include "ja"
If some corpora are **content-wise** relevant (country, region, culture, institution, person, event, etc.), you may additionally select them. - Example: a topic about Japan→include "ja"
-
[17]
If the system’s reasoning indicates that many documents from a language were off-topic, shallow, or irrelevant, you may lower its priority or remove it, and instead consider other content-relevant languages
-
[18]
Do not select corpora that are almost unrelated to the query
-
[19]
just in case
**Never** add corpora "just in case." Choose only a small, realistically useful set
-
[20]
id", "am
Use only language codes that appear in the following language pools. **Never invent new names.** Language Pools:["id", "am", "su", "ar", "ha", "en", "zh", "ko", "as", "el", "fa", "es", "az"] Figure 5:Planner Prompt Template w/ critique. [Query rewriting rules]
-
[21]
- Explicitly mention time, location, and named entities ONLY when given
**Preserve the original meaning and intent**, while making the query clearer and more retrieval-friendly: - Remove colloquial or filler phrases. - Explicitly mention time, location, and named entities ONLY when given. Do not add unnecessary details. - **Do not delete any complete sentences in the original query that convey substantive information** (given...
-
[22]
- If important aspects were missing→add them explicitly
Adjust the rewritten query using the system’s reasoning: - If results were too broad→make the query more specific. - If important aspects were missing→add them explicitly. - If results were off-topic→clarify the main topic and disambiguate the concepts. - If the structure was unclear→reorganize for better retrieval
-
[23]
language_names
The new rewritten query must **meaningfully differ** from the previous rewritten query (e.g., emphasize a different aspect, add missing constraints, reorganize structure, clarify ambiguous elements). [Output format] Return **exactly** the following JSON object **as a single continuous line with no surrounding whitespace, line breaks, or markdown formattin...
-
[24]
Coverage - Do the given documents collectively cover the main aspects and requirements of the query? - Are there important sub-questions or constraints in the query that are not addressed? - Are all information and details of the documents considered to solve the problem?
-
[25]
Depth & Specificity - Are the documents detailed and specific enough to support a precise and reliable answer? - If the query requires factual accuracy, step-by-step reasoning, or up-to-date information, be conservative: if you are not confident, prefer requesting more documents
-
[26]
enough_documents
Consistency - Do the documents agree on key facts? - If there are major contradictions that you cannot resolve with the current documents, you may need more documents. ## Output Format Respond in **valid JSON** with the following fields: - "enough_documents": boolean - true = the given documents are sufficient to answer the query reliably - false = you be...
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.