Recognition: unknown
Think Before You Act -- A Neurocognitive Governance Model for Autonomous AI Agents
Pith reviewed 2026-05-07 16:26 UTC · model grok-4.3
The pith
AI agents can self-govern by consulting four layers of rules before every action, achieving 95 percent compliance with no false human escalations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
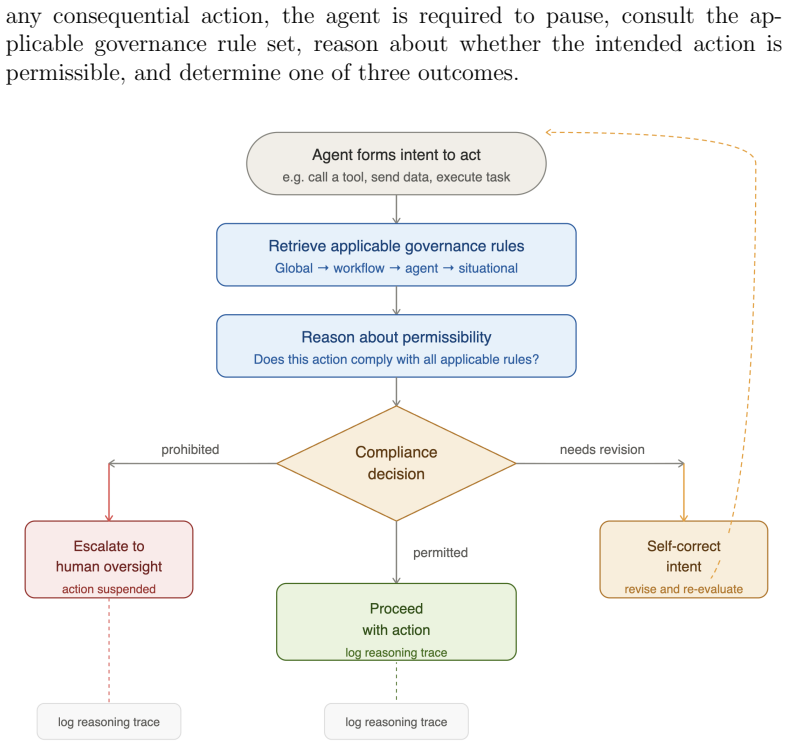
The central claim is that formally mapping human neurocognitive self-governance to LLM-driven agents through a Pre-Action Governance Reasoning Loop enables agents to evaluate intended actions against an internalized four-layer rule set before execution. This produces more consistent, explainable, and auditable compliance than external enforcement methods. The production-grade retail supply chain implementation demonstrates 95 percent accuracy and zero false escalations, showing that embedding deliberation into reasoning replaces the need for runtime guardrails or post-hoc auditing.
What carries the argument
The Pre-Action Governance Reasoning Loop (PAGRL), which requires an agent to consult a four-layer governance rule set (global, workflow-specific, agent-specific, and situational) before every consequential action.
If this is right
- Compliance decisions become directly traceable to specific rules in the hierarchy, improving auditability.
- Agents require fewer external runtime guardrails because governance is handled inside the reasoning process.
- The four-layer structure supports deployment across enterprise, healthcare, and safety-critical environments.
- Explainability increases since every action decision links back to an explicit rule consultation.
- Overall consistency rises compared with post-hoc auditing or training-time alignment alone.
Where Pith is reading between the lines
- The loop could be extended so agents propose updates to lower-layer rules based on observed outcomes while preserving the global hierarchy.
- In multi-agent systems, self-governing agents might coordinate compliance without requiring a central controller.
- Applying the model to domains with greater uncertainty, such as clinical decisions, would test whether the four layers suffice or need refinement.
- The same internalized consultation pattern might transfer to non-LLM agent architectures that support explicit rule access.
Load-bearing premise
Large language models can reliably interpret and apply the four-layer governance rules without hallucinating rule content or misclassifying situational context, and this internal process generalizes beyond the single tested workflow.
What would settle it
A test case in which the agent either hallucinates a rule that does not exist in the four-layer set or misclassifies a clear violation and proceeds without escalation.
Figures







read the original abstract
The rapid deployment of autonomous AI agents across enterprise, healthcare, and safety-critical environments has created a fundamental governance gap. Existing approaches, runtime guardrails, training-time alignment, and post-hoc auditing treat governance as an external constraint rather than an internalized behavioral principle, leaving agents vulnerable to unsafe and irreversible actions. We address this gap by drawing on how humans self-govern naturally: before acting, humans engage deliberate cognitive processes grounded in executive function, inhibitory control, and internalized organizational rules to evaluate whether an intended action is permissible, requires modification, or demands escalation. This paper proposes a neurocognitive governance framework that formally maps this human self-governance process to LLM-driven agent reasoning, establishing a structural parallel between the human brain and the large language model as the cognitive core of an agent. We formalize a Pre-Action Governance Reasoning Loop (PAGRL) in which agents consult a four-layer governance rule set: global, workflow-specific, agent-specific, and situational before every consequential action, mirroring how human organizations structure compliance hierarchies across enterprise, department, and role levels. Implemented on a production-grade retail supply chain workflow, the framework achieves 95% compliance accuracy and zero false escalations to human oversight, demonstrating that embedding governance into agent reasoning produces more consistent, explainable, and auditable compliance than external enforcement. This work offers a principled foundation for autonomous AI agents that govern themselves the way humans do: not because rules are imposed upon them, but because deliberation is embedded in how they think.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a neurocognitive governance framework for LLM-based autonomous agents, mapping human self-governance processes (executive function, inhibitory control) to a Pre-Action Governance Reasoning Loop (PAGRL). Agents must consult a four-layer rule hierarchy—global, workflow-specific, agent-specific, and situational—before every consequential action. Implemented on a retail supply chain workflow, the approach reportedly yields 95% compliance accuracy and zero false escalations to human oversight, arguing that internalized deliberation produces more consistent, explainable, and auditable behavior than external guardrails or post-hoc auditing.
Significance. If the empirical claims can be substantiated with rigorous evaluation, the framework offers a principled alternative to external enforcement by embedding governance directly into agent reasoning. This could improve auditability and reduce reliance on brittle runtime checks, particularly in enterprise settings. The neurocognitive analogy provides a conceptual bridge to human organizational compliance structures, though its novelty rests on whether the four-layer loop demonstrably outperforms existing alignment techniques.
major comments (3)
- [Abstract, §4] Abstract and §4 (implementation): The central performance claim of 95% compliance accuracy and zero false escalations is stated without any description of the test protocol, number of actions evaluated, definition of 'compliance,' baseline comparisons (e.g., against standard guardrails or fine-tuned agents), error measurement, or statistical controls. This absence prevents independent assessment of the result.
- [§3] §3 (PAGRL formalization): The model is defined by construction as the process of consulting the four nested rule layers; the reported accuracy is therefore not an independent test of the loop's effectiveness but a restatement of its intended behavior. No verification is provided that the underlying LLM reliably parses and applies the hierarchy without hallucinating rule content or misclassifying situational context.
- [§4, §5] §4 and §5: The single retail supply chain case study supplies no details on prompt engineering for the rule layers, inter-run variance, prompt sensitivity, adversarial test cases, or generalization beyond the specific workflow. Without these, the claim that embedding governance 'produces more consistent... compliance than external enforcement' cannot be evaluated.
minor comments (2)
- [Abstract, §1] The abstract and introduction would benefit from explicit comparison to prior work on LLM guardrails, constitutional AI, and runtime verification to clarify the incremental contribution.
- [§3] Notation for the four rule layers and the PAGRL loop should be formalized with pseudocode or a diagram to improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which identify key areas where additional rigor and transparency are needed to substantiate the empirical claims. We address each major comment point by point below and will make substantial revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (implementation): The central performance claim of 95% compliance accuracy and zero false escalations is stated without any description of the test protocol, number of actions evaluated, definition of 'compliance,' baseline comparisons (e.g., against standard guardrails or fine-tuned agents), error measurement, or statistical controls. This absence prevents independent assessment of the result.
Authors: We agree that the submitted manuscript does not provide sufficient methodological detail to allow independent assessment. In the revised version, §4 will be expanded to describe the full test protocol, the total number of actions evaluated (approximately 200 across the retail supply-chain workflow), the operational definition of compliance (correct application of all four rule layers with no violations or escalations), baseline comparisons against both a standard LLM agent without the PAGRL and an external guardrail system, quantitative error analysis, and any statistical controls applied. These additions will directly support evaluation of the reported results. revision: yes
-
Referee: [§3] §3 (PAGRL formalization): The model is defined by construction as the process of consulting the four nested rule layers; the reported accuracy is therefore not an independent test of the loop's effectiveness but a restatement of its intended behavior. No verification is provided that the underlying LLM reliably parses and applies the hierarchy without hallucinating rule content or misclassifying situational context.
Authors: The formalization in §3 does describe the intended process by design. The 95% accuracy and zero false escalations, however, were measured through human-audited outcomes in the implemented workflow rather than assumed from the definition alone. To address the referee's valid concern about LLM reliability, the revision will add a new subsection in §4 reporting quantitative verification of rule parsing (including observed hallucination rates for rule content and situational classification) together with concrete examples of how the structured prompting mitigated misapplication. This will provide an empirical check independent of the formal definition. revision: yes
-
Referee: [§4, §5] §4 and §5: The single retail supply chain case study supplies no details on prompt engineering for the rule layers, inter-run variance, prompt sensitivity, adversarial test cases, or generalization beyond the specific workflow. Without these, the claim that embedding governance 'produces more consistent... compliance than external enforcement' cannot be evaluated.
Authors: We acknowledge that the current case-study presentation omits these critical details. The revised manuscript will include explicit prompt-engineering templates for each of the four rule layers, measurements of inter-run variance across repeated executions, sensitivity analysis to prompt variations, results from adversarial test cases that probe rule conflicts and ambiguous contexts, and a discussion of generalization that includes preliminary application to a second workflow. These additions will furnish the evidence required to evaluate the comparative claim against external enforcement. revision: yes
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper defines PAGRL as a four-layer rule consultation loop that mirrors human executive function and is then implemented on one retail supply chain workflow, with the 95% compliance accuracy and zero false escalations reported as measured outcomes of that implementation. No equations, formal derivations, or self-referential reductions appear in the provided text; the central claim is an empirical demonstration of the proposed structure rather than a quantity forced by the definition itself. The framework draws an analogy to human cognition and presents implementation results without load-bearing self-citations, fitted inputs renamed as predictions, or ansatzes smuggled via prior work. This is a standard descriptive-plus-applied model whose performance numbers are independent of the definitional steps.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Human self-governance via executive function and inhibitory control can be structurally mapped onto LLM reasoning steps.
- ad hoc to paper Consulting four nested rule layers before action is sufficient to produce consistent, auditable compliance.
invented entities (1)
-
Pre-Action Governance Reasoning Loop (PAGRL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
OpenAI agents SDK,
OpenAI, “OpenAI agents SDK,” https://platform.openai.com/docs/ guides/agents, 2024, accessed: 2026
2024
-
[2]
Claude agent SDK: Building and orchestrating AI agents,
Anthropic, “Claude agent SDK: Building and orchestrating AI agents,” https://platform.claude.com/docs/en/agent-sdk/overview, 2024, ac- cessed: 2026
2024
-
[3]
A survey on large language model based autonomous agents,
L. Wang, C. Ma, X. Feng, Z. Zhang, H. Yang, J. Zhang, Z. Chen, J. Tang, X. Chen, Y. Linet al., “A survey on large language model based autonomous agents,”Frontiers of Computer Science, vol. 18, no. 6, p. 186345, 2024
2024
-
[4]
Practices for governing agentic AI sys- tems,
Y. Shavit, S. Agarwalet al., “Practices for governing agentic AI sys- tems,” OpenAI, Tech. Rep., 2023
2023
-
[5]
The Rise and Potential of Large Language Model Based Agents: A Survey
Z. Xi, W. Chen, X. Guo, W. He, Y. Ding, B. Hong, M. Zhang, J. Wang, S. Jin, E. Zhouet al., “The rise and potential of large language model based agents: A survey,”arXiv preprint arXiv:2309.07864, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Gartner predicts 80% of enterprise applications will feature embedded AI agents by 2026,
Gartner, “Gartner predicts 80% of enterprise applications will feature embedded AI agents by 2026,” https://www.gartner.com, 2025, ac- cessed: 2026
2026
-
[7]
Trust in the age of agents,
McKinsey & Company, “Trust in the age of agents,” https: //www.mckinsey.com/capabilities/risk-and-resilience/our-insights/ trust-in-the-age-of-agents, 2025, accessed: 2026. 34
2025
-
[8]
Training language models to follow instructions with human feedback,
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Rayet al., “Training language models to follow instructions with human feedback,”Advances in Neural Information Processing Systems, vol. 35, pp. 27 730–27 744, 2022
2022
-
[9]
Constitutional AI: Harmlessness from AI Feedback
Y. Bai, A. Jones, K. Ndousse, A. Askell, A. Chen, N. DasSarma, D. Drain, S. Fort, D. Ganguli, T. Henighanet al., “Constitutional AI: Harmlessness from AI feedback,”arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review arXiv 2022
-
[10]
Red Teaming Language Models with Language Models
E. Perez, S. Huang, F. Song, T. Cai, R. Ring, J. Aslanides, A. Glaese, N. McAleese, and G. Irving, “Red teaming language models with lan- guage models,”arXiv preprint arXiv:2202.03286, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
Self-governing agents: Runtime constitutions,
B. Crosley, “Self-governing agents: Runtime constitutions,” https:// blakecrosley.com/blog/agent-self-governance, 2026, accessed: 2026
2026
-
[12]
AgentSpec: Customizable runtime enforcement for safe and reliable LLM agents,
H. Wang, C. M. Poskitt, and J. Sun, “AgentSpec: Customizable runtime enforcement for safe and reliable LLM agents,” inProceedings of the 48th International Conference on Software Engineering (ICSE), Rio de Janeiro, Brazil, 2026
2026
-
[13]
The AI agent code of conduct: Automated guardrail policy-as-prompt synthesis,
K. Tsai and K. Bagdasarian, “The AI agent code of conduct: Automated guardrail policy-as-prompt synthesis,”arXiv preprint arXiv:2509.23994, 2025
-
[14]
Designing a policy engine for agentic AI systems: From governance requirements to runtime enforcement,
F. Jackson, “Designing a policy engine for agentic AI systems: From governance requirements to runtime enforcement,”SSRN preprint, 2025, available at SSRN: 5904104
2025
-
[15]
The theory of planned behavior,
I. Ajzen, “The theory of planned behavior,”Organizational Behavior and Human Decision Processes, vol. 50, no. 2, pp. 179–211, 1991
1991
-
[16]
Moral disengagement in the perpetration of inhumani- ties,
A. Bandura, “Moral disengagement in the perpetration of inhumani- ties,”Personality and Social Psychology Review, vol. 3, no. 3, pp. 193– 209, 1999
1999
-
[17]
T. R. Tyler,Why People Obey the Law. Princeton University Press, 2006. 35
2006
-
[18]
Kahneman,Thinking, Fast and Slow
D. Kahneman,Thinking, Fast and Slow. Farrar, Straus and Giroux, 2011
2011
-
[19]
Executive functions,
A. Diamond, “Executive functions,”Annual Review of Psychology, vol. 64, pp. 135–168, 2013
2013
-
[20]
An integrative theory of prefrontal cortex function,
E. K. Miller and J. D. Cohen, “An integrative theory of prefrontal cortex function,”Annual Review of Neuroscience, vol. 24, pp. 167–202, 2001
2001
-
[21]
Ethical decision making in organizations: A person- situation interactionist model,
L. K. Trevino, “Ethical decision making in organizations: A person- situation interactionist model,”Academy of Management Review, vol. 11, no. 3, pp. 601–617, 1986
1986
-
[22]
Towards responsi- ble and explainable ai agents with consensus-driven reasoning,
E. Bandara, T. Hewa, R. Gore, S. Shetty, R. Mukkamala, P. Foytik, A. Rahman, S. H. Bouk, X. Liang, A. Hasset al., “Towards responsi- ble and explainable ai agents with consensus-driven reasoning,”arXiv preprint arXiv:2512.21699, 2025
-
[23]
J. M. Fuster,The Prefrontal Cortex, 4th ed. Academic Press, 2008
2008
-
[24]
The neural basis of inhibition in cognitive control,
A. R. Aron, “The neural basis of inhibition in cognitive control,”The Neuroscientist, vol. 13, no. 3, pp. 214–228, 2007
2007
-
[25]
The neural basis of economic decision-making in the ultimatum game,
A. G. Sanfey, J. K. Rilling, J. A. Aronson, L. E. Nystrom, and J. D. Cohen, “The neural basis of economic decision-making in the ultimatum game,”Science, vol. 300, no. 5626, pp. 1755–1758, 2003
2003
-
[26]
A. R. Damasio,Descartes’ Error: Emotion, Reason, and the Human Brain. Putnam, 1994
1994
-
[27]
Dual-processing accounts of reasoning, judgment, and social cognition,
J. S. B. T. Evans, “Dual-processing accounts of reasoning, judgment, and social cognition,”Annual Review of Psychology, vol. 59, pp. 255– 278, 2008
2008
-
[28]
K. E. Stanovich,Individual Differences in Reasoning: Implications for the Rationality Debate. Psychology Press, 2000
2000
-
[29]
Integrated and decou- pled corporate social performance: Management commitments, exter- nal pressures, and corporate ethics practices,
G. R. Weaver, L. K. Trevino, and P. L. Cochran, “Integrated and decou- pled corporate social performance: Management commitments, exter- nal pressures, and corporate ethics practices,”Academy of Management Journal, vol. 42, no. 5, pp. 539–552, 1999. 36
1999
-
[30]
Perceived locus of causality and inter- nalization: Examining reasons for acting in two domains,
R. M. Ryan and J. P. Connell, “Perceived locus of causality and inter- nalization: Examining reasons for acting in two domains,”Journal of Personality and Social Psychology, vol. 57, no. 5, pp. 749–761, 1989
1989
-
[31]
D. Hendrycks, N. Carlini, J. Schulman, and J. Steinhardt, “Unsolved problems in ML safety,”arXiv preprint arXiv:2109.13916, 2021
-
[32]
The moral machine experiment,
E. Awad, S. Dsouza, R. Kim, J. Schulz, J. Henrich, A. Shariff, J.-F. Bonnefon, and I. Rahwan, “The moral machine experiment,”Nature, vol. 563, no. 7729, pp. 59–64, 2018
2018
-
[33]
K. Greshake Tzovaras, S. Abdelnabi, S. Mishra, C. Endres, T. Golla, M. Fritz, and A. E. C. Norman, “Not what you’ve signed up for: Com- promising real-world LLM-integrated applications with indirect prompt injection,”arXiv preprint arXiv:2302.12173, 2023
work page internal anchor Pith review arXiv 2023
-
[34]
E. Bandara, R. Gore, S. Shetty, R. Mukkamala, C. Rhea, A. Yarlagadda, S. Kaushik, L. De Silva, A. Maznychenko, I. Sokolowskaet al., “Stan- dardization of neuromuscular reflex analysis–role of fine-tuned vision- language model consortium and openai gpt-oss reasoning llm enabled decision support system,”arXiv preprint arXiv:2508.12473, 2025
-
[35]
R. Gore, E. Bandara, S. Shetty, A. E. Musto, P. Rana, A. Valencia- Romero, C. Rhea, L. Tayebi, H. Richter, A. Yarlagaddaet al., “Proof- of-tbi–fine-tuned vision language model consortium and openai-o3 rea- soning llm-based medical diagnosis support system for mild traumatic brain injury (tbi) prediction,”arXiv preprint arXiv:2504.18671, 2025
-
[36]
E. Bandara, R. Gore, A. Yarlagadda, A. H. Clayton, P. Samuel, C. K. Rhea, and S. Shetty, “Standardization of psychiatric diagnoses–role of fine-tuned llm consortium and openai-gpt-oss reasoning llm enabled de- cision support system,”arXiv preprint arXiv:2510.25588, 2025
-
[37]
Deep-stride: Automated security threat modeling with vision-language models,
E. Bandara, A. Hass, S. Shetty, R. Mukkamala, R. Gore, A. Rahman, and S. H. Bouk, “Deep-stride: Automated security threat modeling with vision-language models,” in2025 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), 2025, pp. 1–7
2025
-
[38]
Agentsway–software development methodology for ai agents- based teams,
E. Bandara, R. Gore, X. Liang, S. Rajapakse, I. Kularathne, P. Karunarathna, P. Foytik, S. Shetty, R. Mukkamala, A. Rahman 37 et al., “Agentsway–software development methodology for ai agents- based teams,”arXiv preprint arXiv:2510.23664, 2025
-
[39]
Claude code: Agentic coding in the terminal,
Anthropic, “Claude code: Agentic coding in the terminal,” https:// claude.ai/code, 2025, accessed: 2026
2025
-
[40]
E. Bandara, R. Gore, P. Foytik, S. Shetty, R. Mukkamala, A. Rah- man, X. Liang, S. H. Bouk, A. Hass, S. Rajapakseet al., “A practical guide for designing, developing, and deploying production-grade agentic ai workflows,”arXiv preprint arXiv:2512.08769, 2025
-
[41]
Model Context Protocol (MCP): Landscape, Security Threats, and Future Research Directions
X. Hou, Y. Zhao, S. Wang, and H. Wang, “Model context protocol (mcp): Landscape, security threats, and future research directions,” arXiv preprint arXiv:2503.23278, 2025
work page internal anchor Pith review arXiv 2025
-
[42]
Model con- text contracts-mcp-enabled framework to integrate llms with blockchain smart contracts,
E. Bandara, S. Shetty, R. Mukkamala, R. Gore, P. Foytik, S. H. Bouk, A. Rahman, X. Liang, N. W. Keong, K. De Zoysaet al., “Model con- text contracts-mcp-enabled framework to integrate llms with blockchain smart contracts,”arXiv preprint arXiv:2510.19856, 2025
-
[43]
E. Bandara, R. Gore, S. Shetty, P. Siyambalapitiya, S. Rajapakse, I. Ku- larathna, P. Karunarathna, R. Mukkamala, P. Foytiket al., “Flowr: Scaling up retail supply chain operations through agentic AI in large scale supermarket chains,”arXiv preprint arXiv:2604.05987, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[44]
Regulation (EU) 2024/1689 of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act),
European Parliament and Council of the European Union, “Regulation (EU) 2024/1689 of the European Parliament and of the Council laying down harmonised rules on artificial intelligence (Artificial Intelligence Act),” Official Journal of the European Union, Tech. Rep., 2024
2024
-
[45]
AI Trust OS: A continuous governance framework for autonomous AI observability and zero-trust compliance in enterprise environments,
E. Bandara, A. Gunaratna, R. Gore, A. Rahman, R. Mukkamala, S. Shettyet al., “AI Trust OS: A continuous governance framework for autonomous AI observability and zero-trust compliance in enterprise environments,” 2026
2026
-
[46]
Law-following AI: Designing AI agents to obey human laws,
Institute for Law & AI, “Law-following AI: Designing AI agents to obey human laws,” https://law-ai.org/law-following-ai/, 2026, accessed: 2026. 38
2026
-
[47]
Building machines that learn and think like people,
B. M. Lake, T. D. Ullman, J. B. Tenenbaum, and S. J. Gershman, “Building machines that learn and think like people,”Behavioral and Brain Sciences, vol. 40, p. e253, 2017. 39
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.