Recognition: unknown
SAFEdit: Does Multi-Agent Decomposition Resolve the Reliability Challenges of Instructed Code Editing?
Pith reviewed 2026-05-07 15:59 UTC · model grok-4.3
The pith
Multi-agent decomposition with a failure abstraction layer raises instructed code editing success to 68.6 percent on EditBench.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
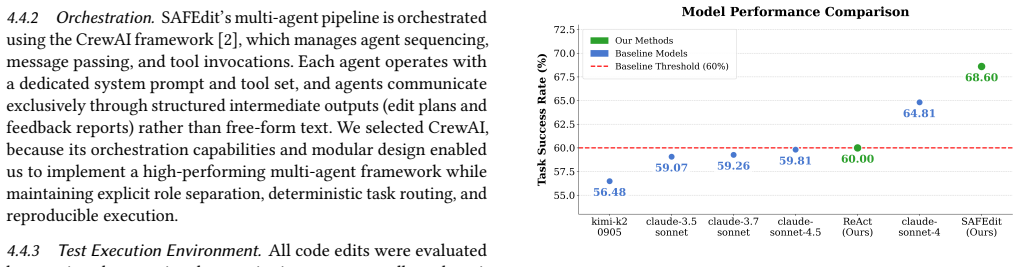
SAFEdit decomposes the editing process into a Planner Agent that produces explicit, visibility-aware edit plans, an Editor Agent that performs minimal literal modifications, and a Verifier Agent that executes tests; when tests fail, a Failure Abstraction Layer transforms raw logs into structured feedback that drives further editing rounds. On the EditBench benchmark this yields 68.6 percent task success rate, 3.8 points above the single-model baseline and 8.6 points above the ReAct single-agent baseline, with the iterative loop contributing 17.4 points to overall success and automated error analysis showing reduced instruction hallucinations.
What carries the argument
The three-agent pipeline (Planner, Editor, Verifier) plus the Failure Abstraction Layer that converts test logs into structured diagnostic feedback for iterative refinement.
If this is right
- Multi-agent role specialization produces higher task success than single-agent prompting on instruction-driven code edits that must pass tests.
- The iterative refinement loop driven by abstracted failure signals adds more than 17 percentage points to final success rate.
- Structured diagnostic feedback reduces instruction-level hallucinations compared with direct single-agent editing.
- The framework maintains its advantage across English, Polish, Spanish, Chinese, and Russian instructions and different spatial context sizes.
Where Pith is reading between the lines
- The same decomposition pattern could be tested on other precision-sensitive LLM tasks such as data transformation or configuration editing where test oracles exist.
- Direct head-to-head token-budget comparisons would clarify whether the reliability gains justify the extra agent calls.
- The Failure Abstraction Layer might be reusable as a plug-in component for other multi-step LLM workflows that produce executable artifacts.
Load-bearing premise
The measured gains arise from the multi-agent role split and the failure abstraction layer rather than from differences in prompting detail, total compute, or implementation choices relative to the ReAct baseline.
What would settle it
Re-running the ReAct single-agent baseline and the prior single-model approaches on the identical 445 EditBench instances while matching total prompt tokens and inference budget to see whether the 3.8-point and 8.6-point gaps remain.
Figures


read the original abstract
Instructed code editing is a significant challenge for large language models (LLMs). On the EditBench benchmark, 39 of 40 evaluated models obtain a task success rate (TSR) below 60 percent, highlighting a gap between general code generation and the ability to perform instruction-driven editing under executable test constraints. To address this, we propose SAFEdit, a multi-agent framework for instructed code editing that decomposes the editing process into specialized roles to improve reliability and reduce unintended code changes. A Planner Agent produces an explicit, visibility-aware edit plan, an Editor Agent applies minimal, literal code modifications, and a Verifier Agent executes real test runs. When tests fail, SAFEdit uses a Failure Abstraction Layer (FAL) to transform raw test logs into structured diagnostic feedback, which is fed back to the Editor to support iterative refinement. We compare SAFEdit against both prior single-model results reported for EditBench and an implemented ReAct single-agent baseline under the same evaluation conditions. We used EditBench to evaluate SAFEdit on 445 code editing instances in five languages (English, Polish, Spanish, Chinese, and Russian) under varying spatial context variants. SAFEdit achieved 68.6 percent TSR, outperforming the single-model baseline by 3.8 percentage points and the ReAct single-agent baseline by 8.6 percentage points. The iterative refinement loop was found to contribute 17.4 percentage points to SAFEdit's overall success rate. SAFEdit's automated error analysis further indicates a reduction in instruction-level hallucinations compared to single-agent approaches, providing an additional framework component for interpreting failures beyond pass or fail outcomes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SAFEdit, a multi-agent framework for instructed code editing that decomposes the task into Planner, Editor, and Verifier agents augmented by a Failure Abstraction Layer (FAL) for structured feedback during iterative refinement. Evaluated on 445 instances from the EditBench benchmark across five languages, SAFEdit achieves a 68.6% task success rate (TSR), surpassing prior single-model results by 3.8 percentage points and an implemented ReAct baseline by 8.6 percentage points. The iterative refinement loop is reported to contribute 17.4 percentage points to the overall success rate, with additional analysis suggesting reduced instruction-level hallucinations.
Significance. If the reported gains prove robustly attributable to the multi-agent decomposition and FAL rather than differences in prompting effort or iteration budgets, this could provide a practical and interpretable approach to improving LLM reliability on instructed code editing, addressing the benchmark gap where 39 of 40 models fall below 60% TSR. The automated error analysis component adds value for failure diagnosis beyond binary pass/fail outcomes.
major comments (2)
- [Experimental Setup and Results] Experimental Setup and Results sections: The 8.6pp TSR improvement over the implemented ReAct baseline (68.6% vs. ~59.9%) is presented as evidence for the multi-agent decomposition, yet the manuscript does not provide explicit details on the ReAct baseline's total LLM call budget, maximum refinement iterations, or prompt engineering parity. Without these, the performance delta cannot be isolated from potential confounds in compute or prompting effort, undermining the central attribution claim.
- [Results] Results section (iterative refinement analysis): The 17.4pp contribution of the iterative loop is measured exclusively within SAFEdit. An equivalent ablation or iteration-budget-matched run of the ReAct baseline would be required to demonstrate that the multi-agent structure (Planner-Editor-Verifier + FAL) is the load-bearing factor rather than the presence of any iterative refinement mechanism.
minor comments (2)
- [Results] The reported margins (3.8pp and 8.6pp) are given without error bars, confidence intervals, or statistical significance tests, which is needed to assess whether the differences are robust across the 445 instances.
- [Experimental Setup] Clarify how the 'prior single-model results' on EditBench were reproduced or matched in terms of exact model versions, context lengths, and spatial context variants used in the SAFEdit evaluation.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of experimental rigor in attributing performance gains to our proposed framework. We address each major comment in detail below, with plans for revisions to enhance clarity and robustness of our claims.
read point-by-point responses
-
Referee: [Experimental Setup and Results] Experimental Setup and Results sections: The 8.6pp TSR improvement over the implemented ReAct baseline (68.6% vs. ~59.9%) is presented as evidence for the multi-agent decomposition, yet the manuscript does not provide explicit details on the ReAct baseline's total LLM call budget, maximum refinement iterations, or prompt engineering parity. Without these, the performance delta cannot be isolated from potential confounds in compute or prompting effort, undermining the central attribution claim.
Authors: We agree that providing these details is essential for readers to evaluate the fairness of the comparison. Although the manuscript states that the ReAct baseline was implemented under the same evaluation conditions, we did not include the granular specifications in the original submission. In the revised manuscript, we will expand the Experimental Setup section to explicitly report: (1) the average and maximum number of LLM calls per instance for both SAFEdit and ReAct (which were matched by design), (2) the maximum refinement iterations set to 5 for both, and (3) the prompt templates used, noting that while the base model and core instructions were identical, the multi-agent prompts incorporate role-specific guidance and the FAL. This revision will strengthen the isolation of the multi-agent decomposition's contribution. revision: yes
-
Referee: [Results] Results section (iterative refinement analysis): The 17.4pp contribution of the iterative loop is measured exclusively within SAFEdit. An equivalent ablation or iteration-budget-matched run of the ReAct baseline would be required to demonstrate that the multi-agent structure (Planner-Editor-Verifier + FAL) is the load-bearing factor rather than the presence of any iterative refinement mechanism.
Authors: This is a valid point regarding the interpretation of the iterative refinement's impact. The 17.4pp figure reflects the difference between SAFEdit with and without the iterative loop (using the FAL for feedback). To address whether iteration alone suffices, we will add to the Results section a comparison of the ReAct baseline run with an equivalent iteration budget (up to 5 iterations). We will report the TSR for this matched ReAct configuration and discuss how the multi-agent structure with FAL provides additional gains beyond what iteration achieves in the single-agent setting. This will be included as an additional analysis in the revised paper. revision: yes
Circularity Check
No circularity: empirical benchmark comparisons are self-contained measurements
full rationale
The paper's central claims consist of direct experimental measurements of task success rate (TSR) on the public EditBench benchmark for 445 instances, including comparisons to an implemented ReAct baseline run under the same evaluation conditions and to previously reported single-model numbers. The reported 17.4 percentage point contribution of the iterative refinement loop is an internal ablation within SAFEdit, not a fitted parameter or self-referential definition. No equations, first-principles derivations, or load-bearing self-citations appear in the provided text; the results do not reduce to quantities defined by the inputs or by prior author work. This is a standard empirical evaluation paper whose validity rests on experimental controls rather than tautological construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Current LLMs can be reliably prompted to perform distinct specialized roles (planner, editor, verifier) without excessive role confusion.
invented entities (4)
-
Planner Agent
no independent evidence
-
Editor Agent
no independent evidence
-
Verifier Agent
no independent evidence
-
Failure Abstraction Layer (FAL)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. Program Synthesis with Large Language Models. arXiv:2108.07732 [cs.PL] https://arxiv.org/abs/2108.07732
work page internal anchor Pith review arXiv 2021
-
[2]
Rafael Barbarroxa, Luis Gomes, and Zita Vale. 2024. Benchmarking large language models for multi-agent systems: A comparative analysis of AutoGen, CrewAI, and TaskWeaver. InInternational Conference on Practical Applications of Agents and Multi-Agent Systems. Springer, 39–48. https://doi.org/10.1007/978-3-031- 70415-4_4
-
[3]
Federico Cassano, Luisa Li, Akul Sethi, Noah Shinn, Abby Brennan-Jones, Jacob Ginesin, Edward Berman, George Chakhnashvili, Anton Lozhkov, Carolyn Jane Anderson, and Arjun Guha. 2024. Can It Edit? Evaluating the Ability of Large Language Models to Follow Code Editing Instructions. arXiv:2312.12450 [cs.SE] https://arxiv.org/abs/2312.12450
-
[4]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review arXiv 2021
- [5]
-
[6]
Wayne Chi, Valerie Chen, Ryan Shar, Aditya Mittal, Jenny Liang, Wei-Lin Chiang, Anastasios Nikolas Angelopoulos, Ion Stoica, Graham Neubig, Ameet Talwalkar, and Chris Donahue. 2026. EditBench: Evaluating LLM Abilities to Perform Real-World Instructed Code Edits. InThe Fourteenth International Conference on Learning Representations. https://openreview.net/...
2026
-
[7]
Sijia Gu, Noor Nashid, and Ali Mesbah. 2025. LLM Test Generation via Iterative Hybrid Program Analysis. arXiv:2503.13580 [cs.SE] doi:10.1145/3744916.3764553
- [8]
-
[9]
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Jie M. Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, and Heming Cui. 2024. AgentCoder: Multi-Agent-based Code Generation with Iterative Test- ing and Optimisation. arXiv:2312.13010 [cs.CL] https://arxiv.org/abs/2312.13010
work page internal anchor Pith review arXiv 2024
- [10]
-
[11]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real- World GitHub Issues? arXiv:2310.06770 [cs.CL] https://arxiv.org/abs/2310.06770
work page internal anchor Pith review arXiv 2024
- [12]
-
[13]
2024.pytest Traceback Styles
pytest development team. 2024.pytest Traceback Styles. pytest. Avail- able at: https://docs.pytest.org/en/stable/how-to/output.html#modifying-python- traceback-printing
2024
- [14]
-
[15]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Language Models. InThe Eleventh International Conference on Learning Representations (ICLR). https://arxiv.org/abs/2210.03629
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.