Recognition: unknown
KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Pith reviewed 2026-05-07 15:36 UTC · model grok-4.3
The pith
KinDER introduces a benchmark of 25 environments that isolate physical reasoning challenges for robots and shows existing methods fail on many of them.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
KinDER supplies a collection of procedurally generated simulation environments together with a Gymnasium-compatible interface and evaluation protocol; when thirteen representative methods from task-and-motion planning, imitation learning, reinforcement learning, and foundation-model pipelines are run on the suite, they fail to solve many of the environments, demonstrating clear limitations in current physical-reasoning capabilities.
What carries the argument
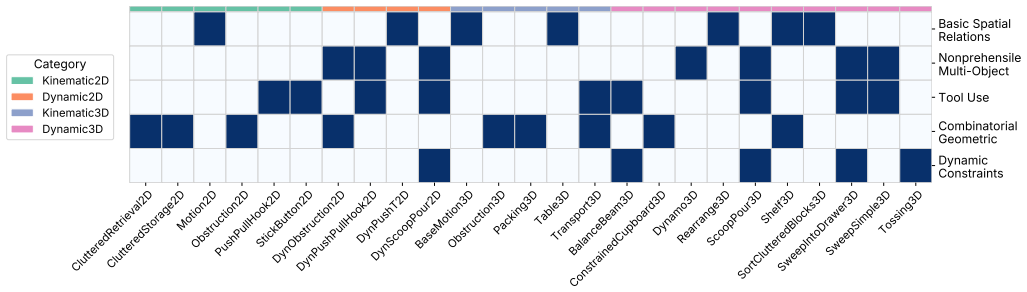
The KinDER benchmark itself, whose 25 environments and standardized evaluation suite are constructed to isolate five specific physical-reasoning challenges while providing parameterized skills and real-to-sim-to-real transfer experiments.
If this is right
- Robot planning and learning algorithms must incorporate explicit handling of nonprehensile contacts, tool affordances, and time-varying forces to reach high success rates on the suite.
- Standardized, open benchmarks make it possible to measure progress across planning, learning, and large-model approaches on the same physical-reasoning problems.
- Real-to-sim-to-real transfer experiments become a required check for any new physical-reasoning technique developed in simulation.
- Procedural generation of environments allows controlled variation of geometric and dynamic parameters to diagnose which constraints remain hardest.
Where Pith is reading between the lines
- The same environments could serve as unit tests for new hybrid planners that combine learned priors with explicit constraint solvers.
- Extending the benchmark to include partial observability or natural-language instructions would test whether the current disentanglement holds when perception and language are reintroduced.
- Success on KinDER could become a prerequisite filter before deploying learned controllers on physical mobile manipulators.
Load-bearing premise
The chosen environments and task definitions actually separate the targeted physical constraints from perception, language, and domain-specific details.
What would settle it
A single method, without task-specific engineering, that solves every environment in the benchmark at the reported success threshold would contradict the claim that substantial gaps remain.
Figures








read the original abstract
Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 13 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics. Website and code: https://prpl-group.com/kinder-site/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces KinDER, a benchmark for kinematic and dynamic embodied reasoning consisting of 25 procedurally generated environments, a Gymnasium-compatible library with parameterized skills and demonstrations, and a standardized evaluation suite. It evaluates 13 baselines spanning task-and-motion planning, imitation learning, reinforcement learning, and foundation-model approaches, reports that existing methods struggle on many environments, and includes real-to-sim-to-real experiments on a mobile manipulator to validate physical interaction correspondence. The environments are claimed to isolate five core challenges (spatial relations, nonprehensile manipulation, tool use, combinatorial geometric constraints, dynamic constraints) from perception, language, and application-specific factors.
Significance. If the isolation of the five physical-reasoning challenges holds and the baseline failures are not attributable to unaccounted perceptual or skill-prior confounders, KinDER would provide a valuable, open-source, standardized testbed for systematic comparison across paradigms in robot learning and planning, highlighting concrete gaps that could guide future work on embodied physical reasoning.
major comments (2)
- [§4 and §5] §4 (Environment Design) and §5 (Baseline Evaluation): The central claim that poor baseline performance reveals gaps in physical reasoning depends on successful isolation of the five challenges. The manuscript describes state-based skills and procedural generation but provides no quantitative validation (e.g., oracle-perception ablations, geometry-perturbation tests, or skill-prior removal experiments) that the environments are free of implicit perceptual demands or task-specific priors; without such evidence the interpretation of the reported success rates remains ambiguous.
- [§6 and Table 2] §6 (Experiments) and Table 2: The aggregate success rates across the 25 environments are presented as evidence of substantial gaps, yet the paper does not report per-challenge breakdowns with statistical significance tests or confidence intervals; this weakens the ability to attribute failures specifically to combinatorial vs. dynamic constraints rather than implementation details of the 13 baselines.
minor comments (3)
- [§3] The abstract and §3 refer to 'parameterized skills' without an explicit enumeration or pseudocode listing of the skill parameter spaces; adding this would improve reproducibility.
- [Figure 3] Figure 3 (environment visualizations) would benefit from clearer labeling of the five challenge categories per row to aid quick cross-reference with the textual descriptions.
- [Real-to-Sim-to-Real Experiments] The real-to-sim-to-real section mentions correspondence but does not report quantitative metrics (e.g., trajectory error or success-rate delta) between sim and real; including these numbers would strengthen the validation claim.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential value of KinDER as a standardized testbed. We address each major comment point by point below, agreeing where additional evidence or analysis would strengthen the claims, and indicating the revisions we will incorporate.
read point-by-point responses
-
Referee: [§4 and §5] §4 (Environment Design) and §5 (Baseline Evaluation): The central claim that poor baseline performance reveals gaps in physical reasoning depends on successful isolation of the five challenges. The manuscript describes state-based skills and procedural generation but provides no quantitative validation (e.g., oracle-perception ablations, geometry-perturbation tests, or skill-prior removal experiments) that the environments are free of implicit perceptual demands or task-specific priors; without such evidence the interpretation of the reported success rates remains ambiguous.
Authors: We agree that explicit quantitative validation would strengthen the interpretation that baseline failures stem from physical reasoning gaps rather than unaccounted confounders. The environments are constructed with fully observable state inputs, parameterized skills, and procedural generation specifically to isolate the five challenges from perception and language, as detailed in §4 and the abstract. However, we acknowledge that the current manuscript does not include the suggested ablations or perturbation tests. In the revised version we will add oracle-perception baselines, skill-prior removal experiments, and geometry-perturbation results to §5 to provide this quantitative support. revision: yes
-
Referee: [§6 and Table 2] §6 (Experiments) and Table 2: The aggregate success rates across the 25 environments are presented as evidence of substantial gaps, yet the paper does not report per-challenge breakdowns with statistical significance tests or confidence intervals; this weakens the ability to attribute failures specifically to combinatorial vs. dynamic constraints rather than implementation details of the 13 baselines.
Authors: We appreciate the suggestion to improve granularity. While §6 and Table 2 report aggregate success rates to demonstrate overall limitations of existing methods, we agree that per-challenge breakdowns with statistical analysis would allow clearer attribution to specific constraint types. In the revised manuscript we will add a per-challenge success breakdown (by the five core challenges) to §6, including confidence intervals and appropriate significance tests, either as an expanded Table 2 or a new supplementary table. revision: yes
Circularity Check
No circularity: benchmark creation with direct empirical evaluation
full rationale
This is a benchmark paper that defines 25 procedurally generated environments, provides a Gymnasium library with skills and demonstrations, and reports empirical results from 13 baselines across TAMP, IL, RL, and foundation models. No derivation chain, equations, fitted parameters, or predictions exist that could reduce to inputs by construction. The central claim (existing methods struggle, revealing gaps) rests on direct evaluation rather than self-definition, self-citation load-bearing, or renaming. Environment isolation is asserted via design description without circular reduction to prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Physical reasoning,
E. Davis, “Physical reasoning,”Foundations of Artificial Intelligence, vol. 3, pp. 597–620, 2008
2008
-
[2]
Describing physics for physical reasoning: Force-based sequential manipulation planning,
M. Toussaint, J.-S. Ha, and D. Driess, “Describing physics for physical reasoning: Force-based sequential manipulation planning,”IEEE Robotics and Automation Letters, vol. 5, no. 4, pp. 6209–6216, 2020
2020
-
[3]
Integrated task and motion planning,
C. R. Garrett, R. Chitnis, R. Holladay, B. Kim, T. Sil- ver, L. P. Kaelbling, and T. Lozano-P ´erez, “Integrated task and motion planning,”Annual review of control, robotics, and autonomous systems, vol. 4, no. 1, pp. 265–293, 2021
2021
-
[4]
Newton: Are large language models capable of physical reason- ing?
Y . Wang, J. Duan, D. Fox, and S. Srinivasa, “Newton: Are large language models capable of physical reason- ing?” inFindings of the association for computational linguistics: EMNLP 2023, 2023, pp. 9743–9758
2023
-
[5]
A. Cherian, R. Corcodel, S. Jain, and D. Romeres, “Llmphy: Complex physical reasoning using large language models and world models,”arXiv preprint arXiv:2411.08027, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Physically grounded vision-language models for robotic manipulation,
J. Gao, B. Sarkar, F. Xia, T. Xiao, J. Wu, B. Ichter, A. Majumdar, and D. Sadigh, “Physically grounded vision-language models for robotic manipulation,” in 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 12 462–12 469
2024
-
[7]
Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,
Q. Zhao, Y . Lu, M. J. Kim, Z. Fu, Z. Zhang, Y . Wu, Z. Li, Q. Ma, S. Han, C. Finnet al., “Cot-vla: Visual chain-of-thought reasoning for vision-language-action models,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1702–1713
2025
-
[8]
Vla-r1: Enhancing reasoning in vision-language-action models.arXiv preprint arXiv:2510.01623, 2025
A. Ye, Z. Zhang, B. Wang, X. Wang, D. Zhang, and Z. Zhu, “Vla-r1: Enhancing reasoning in vision-language-action models,”arXiv preprint arXiv:2510.01623, 2025
-
[9]
Rapid trial-and-error learning with simulation supports flexible tool use and physical reasoning,
K. R. Allen, K. A. Smith, and J. B. Tenenbaum, “Rapid trial-and-error learning with simulation supports flexible tool use and physical reasoning,”Proceedings of the National Academy of Sciences, vol. 117, no. 47, pp. 29 302–29 310, 2020
2020
-
[10]
A survey of optimization-based task and motion planning: From classical to learning ap- proaches,
Z. Zhao, S. Cheng, Y . Ding, Z. Zhou, S. Zhang, D. Xu, and Y . Zhao, “A survey of optimization-based task and motion planning: From classical to learning ap- proaches,”IEEE/ASME Transactions on Mechatronics, 2024
2024
-
[11]
Doing more with less: meta-reasoning and meta-learning in humans and machines,
T. L. Griffiths, F. Callaway, M. B. Chang, E. Grant, P. M. Krueger, and F. Lieder, “Doing more with less: meta-reasoning and meta-learning in humans and machines,”Current Opinion in Behavioral Sciences, vol. 29, pp. 24–30, 2019
2019
-
[12]
Learn- ing when to quit: meta-reasoning for motion planning,
Y . Sung, L. P. Kaelbling, and T. Lozano-P ´erez, “Learn- ing when to quit: meta-reasoning for motion planning,” in2021 IEEE/RSJ International Conference on Intel- ligent Robots and Systems (IROS). IEEE, 2021, pp. 4692–4699
2021
-
[13]
Efficient re- covery learning using model predictive meta-reasoning,
S. Vats, M. Likhachev, and O. Kroemer, “Efficient re- covery learning using model predictive meta-reasoning,” arXiv preprint arXiv:2209.13605, 2022
-
[14]
Procthor: Large-scale embodied ai using procedural generation,
M. Deitke, E. VanderBilt, A. Herrasti, L. Weihs, K. Ehsani, J. Salvador, W. Han, E. Kolve, A. Kembhavi, and R. Mottaghi, “Procthor: Large-scale embodied ai using procedural generation,”Advances in Neural In- formation Processing Systems, vol. 35, pp. 5982–5994, 2022
2022
-
[15]
Gensim: Generating robotic simulation tasks via large language models,
L. Wang, Y . Ling, Z. Yuan, M. Shridhar, C. Bao, Y . Qin, B. Wang, H. Xu, and X. Wang, “Gensim: Generating robotic simulation tasks via large language models,” arXiv preprint arXiv:2310.01361, 2023
-
[16]
scene synthesizer: A python library for procedural scene generation in robot manipulation,
C. Eppner, A. Murali, C. Garrett, R. O’Flaherty, T. Hermans, W. Yang, and D. Fox, “scene synthesizer: A python library for procedural scene generation in robot manipulation,”Journal of Open Source Software, vol. 10, no. 105, p. 7561, 2025
2025
-
[17]
C. Li, R. Zhang, J. Wong, C. Gokmen, S. Srivas- tava, R. Mart ´ın-Mart´ın, C. Wang, G. Levine, W. Ai, B. J. Martinez, H. Yin, M. Lingelbach, M. Hwang, A. Hiranaka, S. Garlanka, A. Aydin, S. Lee, J. Sun, M. Anvari, M. Sharma, D. Bansal, S. Hunter, K.-Y . Kim, A. Lou, C. R. Matthews, I. Villa-Renteria, J. H. Tang, C. Tang, F. Xia, Y . Li, S. Savarese, H. Gw...
-
[18]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard, “Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks,” arXiv preprint arXiv:2112.03227, 2021
-
[19]
Dittogym: Learning to control soft robots with differentiable simulation,
Y . Li, Y . Zeng, Z. Huang, R. Luo, X. He, C. K. Liu, and Y . Zhu, “Dittogym: Learning to control soft robots with differentiable simulation,”arXiv preprint arXiv:2406.12452, 2024
-
[20]
Y . Tassa, Y . Doron, A. Muldal, T. Erez, Y . Li, D. de Las Casas, D. Budden, A. Abdolmaleki, J. Merel, A. Lefrancq, T. Lillicrap, and M. Riedmiller, “Deep- mind control suite,”arXiv preprint arXiv:1801.00690, 2018
work page internal anchor Pith review arXiv 2018
-
[21]
Embod- ied agent interface: Benchmarking llms for embodied decision making,
M. Li, S. Zhao, Q. Wang, K. Wang, Y . Zhou, S. Srivas- tava, C. Gokmen, T. Lee, L. E. Li, R. Zhang, W. Liu, P. Liang, L. Fei-Fei, J. Mao, and J. Wu, “Embod- ied agent interface: Benchmarking llms for embodied decision making,” inAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[22]
Embodied- bench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents,
R. Yang, H. Chen, J. Zhang, M. Zhao, C. Qian, K. Wang, Q. Wang, T. V . Koripella, M. Movahedi, M. Li, H. Ji, H. Zhang, and T. Zhang, “Embodied- bench: Comprehensive benchmarking multi-modal large language models for vision-driven embodied agents,” in Proceedings of the 42nd International Conference on Machine Learning (ICML), 2025
2025
-
[23]
Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,
M. Heo, Y . Lee, D. Lee, and J. J. Lim, “Furniturebench: Reproducible real-world benchmark for long-horizon complex manipulation,” inRobotics: Science and Sys- tems (RSS), 2023
2023
-
[24]
I-phyre: Inter- active physical reasoning,
S. Li, K. Wu, C. Zhang, and Y . Zhu, “I-phyre: Inter- active physical reasoning,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[25]
Kinetix: Investigating the training of general agents through open-ended physics-based control tasks,
M. Matthews, M. Beukman, C. Lu, and J. Foerster, “Kinetix: Investigating the training of general agents through open-ended physics-based control tasks,” in OpenReview, 2024
2024
-
[26]
Platform-independent benchmarks for task and motion planning,
F. Lagriffoul, N. T. Dantam, C. Garrett, A. Akbari, S. Srivastava, and L. E. Kavraki, “Platform-independent benchmarks for task and motion planning,”IEEE Robotics and Automation Letters, vol. 3, no. 4, pp. 3765–3772, 2018
2018
-
[27]
Libero: Benchmarking knowledge transfer for lifelong robot learning,
X. Li, W. Zhang, X. Xu, Y . Li, and Y . Zhu, “Libero: Benchmarking knowledge transfer for lifelong robot learning,” inProceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS), 2023
2023
-
[28]
Maniskill-hab: A bench- mark for low-level manipulation in home rearrangement tasks,
A. Shukla, S. Tao, and H. Su, “Maniskill-hab: A bench- mark for low-level manipulation in home rearrangement tasks,” inInternational Conference on Learning Repre- sentations (ICLR), 2025
2025
-
[29]
Og- bench: Benchmarking offline goal-conditioned rl,
S. Park, K. Frans, B. Eysenbach, and S. Levine, “Og- bench: Benchmarking offline goal-conditioned rl,” in International Conference on Learning Representations (ICLR), 2025
2025
-
[30]
Robocasa: Large-scale simulation of household tasks for generalist robots,
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y . Zhu, “Robocasa: Large-scale simulation of household tasks for generalist robots,” inProceedings of Robotics: Science and Sys- tems (RSS), 2024
2024
-
[31]
Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks,
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, and X. Qiu, “Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks,” inProceedings of the IEEE/CVF Inter- national Conference on Computer Vision (ICCV), 2025
2025
-
[32]
Vlmgineer: Vision language models as robotic toolsmiths,
G. J. Gao, T. Li, J. Shi, Y . Li, Z. Zhang, N. Figueroa, and D. Jayaraman, “Vlmgineer: Vision language models as robotic toolsmiths,” 2025
2025
-
[33]
Integrated task and motion planning in belief space,
L. P. Kaelbling and T. Lozano-P ´erez, “Integrated task and motion planning in belief space,”The International Journal of Robotics Research, vol. 32, no. 9-10, pp. 1194–1227, 2013
2013
-
[34]
Combined task and motion plan- ning through an extensible planner-independent inter- face layer,
S. Srivastava, E. Fang, L. Riano, R. Chitnis, S. Rus- sell, and P. Abbeel, “Combined task and motion plan- ning through an extensible planner-independent inter- face layer,” in2014 IEEE international conference on robotics and automation (ICRA). IEEE, 2014, pp. 639– 646
2014
-
[35]
Pddlstream: Integrating symbolic planners and black- box samplers via optimistic adaptive planning,
C. R. Garrett, T. Lozano-P ´erez, and L. P. Kaelbling, “Pddlstream: Integrating symbolic planners and black- box samplers via optimistic adaptive planning,” inPro- ceedings of the international conference on automated planning and scheduling, vol. 30, 2020, pp. 440–448
2020
-
[36]
Proximal Policy Optimization Algorithms
J. Schulman, F. Wolski, P. Dhariwal, A. Radford, and O. Klimov, “Proximal policy optimization algorithms,” arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[37]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Kumar, H. Zhu, A. Gupta, P. Abbeelet al., “Soft actor-critic algorithms and applications,”arXiv preprint arXiv:1812.05905, 2018
work page internal anchor Pith review arXiv 2018
-
[38]
Physically embedded planning prob- lems: New challenges for reinforcement learning,
M. Mirza, A. Jaegle, J. J. Hunt, A. Guez, S. Tunyasuvu- nakool, A. Muldal, T. Weber, P. Karkus, S. Racaniere, L. Buesinget al., “Physically embedded planning prob- lems: New challenges for reinforcement learning,”arXiv preprint arXiv:2009.05524, 2020
-
[39]
An algorithmic perspective on imitation learning,
T. Osa, J. Pajarinen, G. Neumann, J. A. Bagnell, P. Abbeel, and J. Peters, “An algorithmic perspective on imitation learning,”Foundations and Trends® in Robotics, vol. 7, no. 1-2, pp. 1–179, 2018
2018
-
[40]
Bc-z: Zero-shot task generalization with robotic imitation learning,
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn, “Bc-z: Zero-shot task generalization with robotic imitation learning,” in Conference on Robot Learning. PMLR, 2022
2022
-
[41]
Diffusion policy: Vi- suomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burch- fiel, R. Tedrake, and S. Song, “Diffusion policy: Vi- suomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[42]
Llmˆ 3: Large language model- based task and motion planning with motion failure reasoning,
S. Wang, M. Han, Z. Jiao, Z. Zhang, Y . N. Wu, S.- C. Zhu, and H. Liu, “Llmˆ 3: Large language model- based task and motion planning with motion failure reasoning,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 12 086–12 092
2024
-
[43]
Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning,
Y . Hu, F. Lin, T. Zhang, L. Yi, and Y . Gao, “Look before you leap: Unveiling the power of gpt-4v in robotic vision-language planning,”arXiv preprint arXiv:2311.17842, 2023
-
[44]
PaLM-E: An Embodied Multimodal Language Model
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdh- ery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yu et al., “Palm-e: An embodied multimodal language model,”arXiv preprint arXiv:2303.03378, 2023
work page internal anchor Pith review arXiv 2023
-
[45]
arXiv preprint arXiv:2510.03342 (2025)
G. R. Team, A. Abdolmaleki, S. Abeyruwan, J. Ainslie, J.-B. Alayrac, M. G. Arenas, A. Balakrishna, N. Batche- lor, A. Bewley, J. Binghamet al., “Gemini robotics 1.5: Pushing the frontier of generalist robots with advanced embodied reasoning, thinking, and motion transfer,” arXiv preprint arXiv:2510.03342, 2025
-
[46]
Energy-based models are zero-shot planners for compositional scene rearrange- ment,
N. Gkanatsios, A. Jain, Z. Xian, Y . Zhang, C. G. Atkeson, and K. Fragkiadaki, “Energy-based models are zero-shot planners for compositional scene rearrange- ment,” inProceedings of Robotics: Science and Systems (RSS), 2023
2023
-
[47]
Transformers are adaptable task planners,
V . Jain, Y . Lin, E. Undersander, Y . Bisk, and A. Rai, “Transformers are adaptable task planners,” inConfer- ence on Robot Learning. PMLR, 2023, pp. 1011–1037
2023
-
[48]
A semantic analysis of english locative prepositions,
G. S. Cooper, “A semantic analysis of english locative prepositions,” Bolt Beranek and Newman, Cambridge, MA, Tech. Rep. 1587, 1968
1968
-
[49]
Force distribution in multiple whole-limb manipulation,
A. Bicchi, “Force distribution in multiple whole-limb manipulation,” in[1993] Proceedings IEEE Interna- tional Conference on Robotics and Automation. IEEE, 1993, pp. 196–201
1993
-
[50]
Robopanoptes: The all- seeing robot with whole-body dexterity,
X. Xu, D. Bauer, and S. Song, “Robopanoptes: The all- seeing robot with whole-body dexterity,”arXiv preprint arXiv:2501.05420, 2025
-
[51]
Slap: Shortcut learning for abstract planning,
Y . I. Liu, B. Li, B. Eysenbach, and T. Silver, “Slap: Shortcut learning for abstract planning,”arXiv preprint arXiv:2511.01107, 2025
-
[52]
Prioritouch: Adapting to user contact preferences for whole-arm physical human-robot interaction,
R. Madan, J. Lin, M. Goel, A. Li, A. Xie, X. Liang, M. Lee, J. Guo, P. N. Thakkar, R. Banerjee, J. Barreiros, K. Tsui, T. Silver, and T. Bhattacharjee, “Prioritouch: Adapting to user contact preferences for whole-arm physical human-robot interaction,” inProceedings of the 9th Conference on Robot Learning (CoRL), 2025
2025
-
[53]
Jacta: A versatile planner for learn- ing dexterous and whole-body manipulation,
J. Br ¨udigam, A. A. Abbas, M. Sorokin, K. Fang, B. Hung, M. Guru, S. Sosnowski, J. Wang, S. Hirche, and S. Le Cleac’h, “Jacta: A versatile planner for learn- ing dexterous and whole-body manipulation,”arXiv preprint arXiv:2408.01258, 2024
-
[54]
Learning to break rocks with deep reinforcement learning,
P. Samtani, F. Leiva, and J. Ruiz-del Solar, “Learning to break rocks with deep reinforcement learning,”IEEE Robotics and Automation Letters, vol. 8, no. 2, pp. 1077–1084, 2023
2023
-
[55]
Force-and-motion constrained planning for tool use,
R. Holladay, T. Lozano-P ´erez, and A. Rodriguez, “Force-and-motion constrained planning for tool use,” in2019 IEEE/RSJ international conference on intelli- gent robots and systems (IROS). IEEE, 2019
2019
-
[56]
Differentiable physics and stable modes for tool-use and manipulation planning,
M. A. Toussaint, K. R. Allen, K. A. Smith, and J. B. Tenenbaum, “Differentiable physics and stable modes for tool-use and manipulation planning,” 2018
2018
-
[57]
Learning neuro-symbolic skills for bilevel planning,
T. Silver, A. Athalye, J. B. Tenenbaum, T. Lozano- P´erez, and L. P. Kaelbling, “Learning neuro-symbolic skills for bilevel planning,” inProceedings of The 6th Conference on Robot Learning, ser. Proceedings of Machine Learning Research, J. Tan, M. Toussaint, and K. Darvish, Eds., vol. 205. PMLR, 2023, pp. 701–714
2023
-
[58]
Discovering state and action abstractions for generalized task and motion planning,
A. Curtis, T. Silver, J. B. Tenenbaum, T. Lozano- P´erez, and L. Kaelbling, “Discovering state and action abstractions for generalized task and motion planning,” inProceedings of the AAAI conference on artificial intelligence, vol. 36, no. 5, 2022, pp. 5377–5384
2022
-
[59]
Stable bin packing of non- convex 3d objects with a robot manipulator,
F. Wang and K. Hauser, “Stable bin packing of non- convex 3d objects with a robot manipulator,” in2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 8698–8704
2019
-
[60]
Practice makes perfect: Planning to learn skill parameter poli- cies,
N. Kumar, T. Silver, W. McClinton, L. Zhao, S. Proulx, T. Lozano-P´erez, L. P. Kaelbling, and J. Barry, “Practice makes perfect: Planning to learn skill parameter poli- cies,” inRobotics: Science and Systems (RSS), 2024
2024
-
[61]
Tool macgyver- ing: Tool construction using geometric reasoning,
L. Nair, J. Balloch, and S. Chernova, “Tool macgyver- ing: Tool construction using geometric reasoning,” in 2019 international conference on robotics and automa- tion (ICRA). IEEE, 2019, pp. 5837–5843
2019
-
[62]
Multi- heuristic robotic bin packing of regular and irregular objects,
T. Nickel, R. Bormann, and K. O. Arras, “Multi- heuristic robotic bin packing of regular and irregular objects,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 10 730–10 736
2025
-
[63]
Fast and resilient manipulation planning for object retrieval in cluttered and confined environments,
C. Nam, S. H. Cheong, J. Lee, D. H. Kim, and C. Kim, “Fast and resilient manipulation planning for object retrieval in cluttered and confined environments,”IEEE Transactions on Robotics, vol. 37, no. 5, pp. 1539–1552, 2021
2021
-
[64]
Navigation among mov- able obstacles: Real-time reasoning in complex environ- ments,
M. Stilman and J. J. Kuffner, “Navigation among mov- able obstacles: Real-time reasoning in complex environ- ments,”International Journal of Humanoid Robotics, vol. 2, no. 04, pp. 479–503, 2005
2005
-
[65]
Gomp-fit: Grasp-optimized motion planning for fast inertial transport,
J. Ichnowski, Y . Avigal, Y . Liu, and K. Goldberg, “Gomp-fit: Grasp-optimized motion planning for fast inertial transport,” in2022 international conference on robotics and automation (ICRA). IEEE, 2022, pp. 5255–5261
2022
-
[66]
Grounding language plans in demonstrations through counterfactual perturbations,
Y . Wang, T.-H. Wang, J. Mao, M. Hagenow, and J. Shah, “Grounding language plans in demonstrations through counterfactual perturbations,”arXiv preprint arXiv:2403.17124, 2024
-
[67]
Learning basketball dribbling skills using trajectory optimization and deep reinforce- ment learning,
L. Liu and J. Hodgins, “Learning basketball dribbling skills using trajectory optimization and deep reinforce- ment learning,”Acm transactions on graphics (tog), vol. 37, no. 4, pp. 1–14, 2018
2018
-
[68]
Progress in spatial robot juggling
A. A. Rizzi and D. E. Koditschek, “Progress in spatial robot juggling.” in1992 IEEE International Conference on Robotics and Automation (ICRA), 1992, pp. 775– 780
1992
-
[69]
What matters in learning from large-scale datasets for robot manipulation,
V . Saxena, M. Bronars, N. R. Arachchige, K. Wang, W. C. Shin, S. Nasiriany, A. Mandlekar, and D. Xu, “What matters in learning from large-scale datasets for robot manipulation,” inThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[70]
BiGym: A demo- driven mobile bi-manual manipulation benchmark
N. Chernyadev, N. Backshall, X. Ma, Y . Lu, Y . Seo, and S. James, “Bigym: A demo-driven mobile bi-manual manipulation benchmark,”arXiv preprint arXiv:2407.07788, 2024
-
[71]
Benchmark- ing motion planning algorithms: An extensible infras- tructure for analysis and visualization,
M. Moll, I. A. Sucan, and L. E. Kavraki, “Benchmark- ing motion planning algorithms: An extensible infras- tructure for analysis and visualization,”IEEE Robotics & Automation Magazine, vol. 22, no. 3, pp. 96–102, 2015
2015
-
[72]
Bench-mr: A motion plan- ning benchmark for wheeled mobile robots,
E. Heiden, L. Palmieri, L. Bruns, K. O. Arras, G. S. Sukhatme, and S. Koenig, “Bench-mr: A motion plan- ning benchmark for wheeled mobile robots,”IEEE Robotics and Automation Letters, vol. 6, no. 3, pp. 4536–4543, 2021
2021
-
[73]
Motionbenchmaker: A tool to generate and benchmark motion planning datasets,
C. Chamzas, C. Quintero-Pena, Z. Kingston, A. Orthey, D. Rakita, M. Gleicher, M. Toussaint, and L. E. Kavraki, “Motionbenchmaker: A tool to generate and benchmark motion planning datasets,”IEEE Robotics and Automa- tion Letters, vol. 7, no. 2, pp. 882–889, 2021
2021
-
[74]
The 3rd international planning competition: Results and analysis,
D. Long and M. Fox, “The 3rd international planning competition: Results and analysis,”Journal of Artificial Intelligence Research, vol. 20, pp. 1–59, 2003
2003
-
[75]
The 2014 international planning competition: Progress and trends,
M. Vallati, L. Chrpa, M. Grze ´s, T. L. McCluskey, M. Roberts, S. Sanneret al., “The 2014 international planning competition: Progress and trends,”Ai Maga- zine, vol. 36, no. 3, pp. 90–98, 2015
2014
-
[76]
The 2023 international planning competition,
A. Taitler, R. Alford, J. Espasa, G. Behnke, D. Fi ˇser, M. Gimelfarb, F. Pommerening, S. Sanner, E. Scala, D. Schreiberet al., “The 2023 international planning competition,” 2024
2023
-
[77]
Alfred: A benchmark for interpreting grounded instructions for everyday tasks,
M. Shridhar, J. Thomason, D. Gordon, Y . Bisk, W. Han, R. Mottaghi, L. Zettlemoyer, and D. Fox, “Alfred: A benchmark for interpreting grounded instructions for everyday tasks,” inProceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition (CVPR), 2020
2020
-
[78]
AI2-THOR: An Interactive 3D Environment for Visual AI
E. Kolve, R. Mottaghi, D. Gordon, Y . Zhu, A. Gupta, A. Farhadi, and L. Fei-Fei, “Ai2-thor: An interac- tive 3d environment for visual AI,”arXiv preprint arXiv:1712.05474, 2017
work page internal anchor Pith review arXiv 2017
-
[79]
Manipulathor: A framework for visual object manipulation,
J. Li, E. Kolve, D. Ramanan, A. Gupta, A. Farhadi, and R. Mottaghi, “Manipulathor: A framework for visual object manipulation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion (CVPR), 2022
2022
-
[80]
Habitat 2.0: Training home assistants to rearrange their habitat,
A. Szot, A. Clegg, E. Undersander, E. Wijmans, Y . Zhao, J. Turner, N. Maestre, M. Mukadam, D. S. Chaplot, O. Maksymetset al., “Habitat 2.0: Training home assistants to rearrange their habitat,”Advances in neural information processing systems, vol. 34, pp. 251–266, 2021
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.