Recognition: unknown
Magnification-Invariant Image Classification via Domain Generalization and Stable Sparse Embedding Signatures
Pith reviewed 2026-05-07 16:55 UTC · model grok-4.3
The pith
Domain generalization via gradient reversal produces magnification-invariant histopathology classifiers with compact and reproducible sparse embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
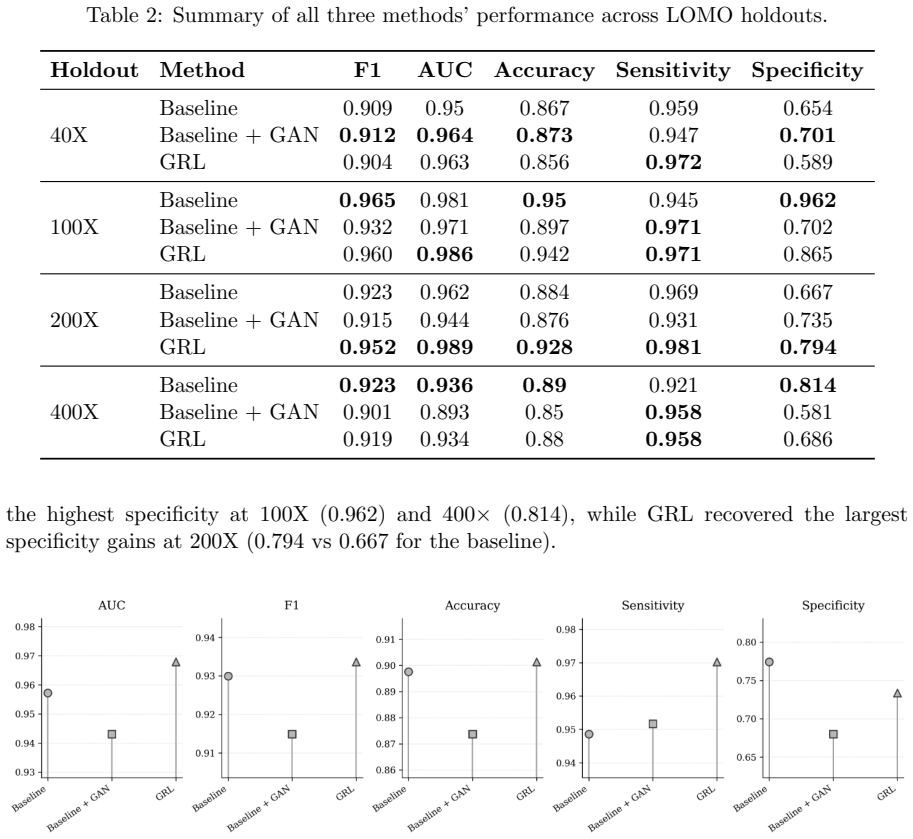
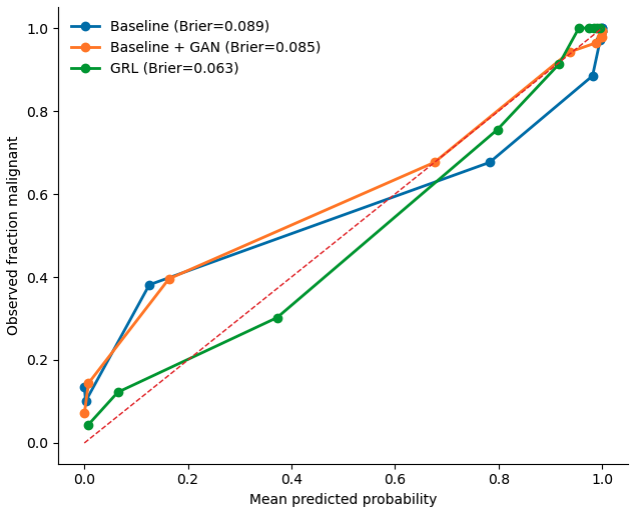
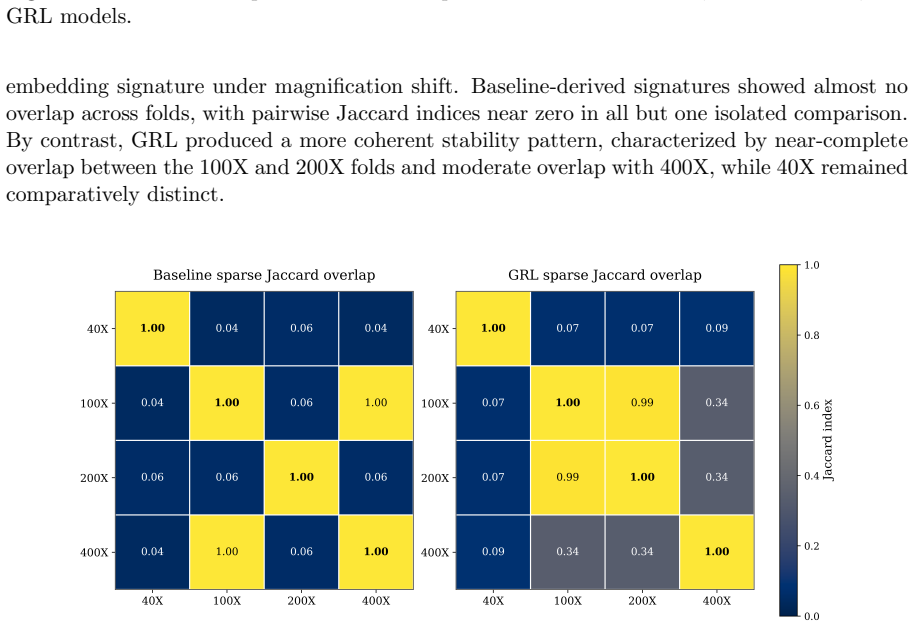
The central claim is that training with gradient reversal to suppress magnification-specific variation yields models that generalize better across magnifications than standard supervised learning or GAN augmentation. These models achieve lower Brier scores for calibration, maintain equivalent AUC and F1 scores, reduce the average dimension of sparse signatures by more than three times, and increase the Jaccard overlap of signatures between different magnification folds from near zero to 0.99.
What carries the argument
The gradient-reversal domain-general model that adversarially suppresses magnification-specific features in the embedding while retaining information for benign versus malignant classification.
Load-bearing premise
That gradient reversal successfully suppresses magnification-specific variation without removing information needed for accurate benign-versus-malignant discrimination, and that the patient-disjoint leave-one-magnification-out protocol fully isolates the magnification-shift effect from other sources of variation.
What would settle it
Replicating the leave-one-magnification-out experiment on BreaKHis and finding that the domain-general model's Brier score is not lower than the baseline value of 0.089, or that the average sparse signature size is not reduced by at least half while maintaining equivalent AUC and F1, would falsify the central claim.
Figures




read the original abstract
Magnification shift is a major obstacle to robust histopathology classification, because models trained on one imaging scale often generalize poorly to another. Here, we evaluated this problem on the BreaKHis dataset using a strict patient-disjoint leave-one-magnification-out protocol, comparing supervised baseline, baseline augmented with DCGAN-generated patches, and a gradient-reversal domain-general model designed to preserve discriminative information while suppressing magnification-specific variation. Across held-out magnifications, the domain-general model achieved the strongest overall discrimination and its clearest gain was observed when 200X was held out. By contrast, GAN augmentation produced inconsistent effects, improving some folds but degrading others, particularly at 400X. The domain-general model also yielded the lowest Brier score at 0.063 vs 0.089 at baseline. Sparse embedding analysis further revealed that domain-general training reduced average signature size more than three-fold (306 versus 1,074 dimensions) while preserving equivalent predictive performance (AUC: 0.967 vs 0.965; F1: 0.930 vs 0.931). It also increased cross-fold signature reproducibility from near-zero Jaccard overlap in the baseline to 0.99 between the 100X and 200X folds. These findings show that calibrated, compact, and transferable representations can be learned without added architectural complexity, with clear implications for the reliable deployment of computational pathology models across heterogeneous acquisition settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates magnification shift as a domain generalization problem in histopathology classification on the BreaKHis dataset. It compares a supervised baseline, a DCGAN-augmented baseline, and a gradient-reversal domain-generalization model under a strict patient-disjoint leave-one-magnification-out protocol. The domain-general model is reported to yield the best overall discrimination (particularly when 200X is held out), the lowest Brier score (0.063 vs. 0.089), more compact sparse embeddings (306 vs. 1,074 dimensions on average), and substantially higher cross-fold signature reproducibility (Jaccard 0.99 vs. near-zero).
Significance. If the reported invariance holds, the work shows that adversarial domain generalization can produce compact, well-calibrated, and reproducible embeddings for robust benign/malignant classification across magnification shifts without added architectural complexity. The inclusion of Brier scores and Jaccard-based signature stability analysis provides concrete, multi-faceted evidence beyond standard accuracy metrics, strengthening the case for practical deployment in heterogeneous clinical imaging settings.
major comments (2)
- [Results (leave-one-magnification-out experiments)] The central claim that gradient reversal produces magnification-invariant yet class-informative embeddings rests on downstream classification metrics and signature stability. No direct probe of invariance (e.g., magnification-prediction accuracy or mutual information between embeddings and magnification labels) is reported in the results; without it, the small AUC/F1 gains (0.967 vs. 0.965; 0.930 vs. 0.931) are consistent with either true invariance or a more robust but still magnification-sensitive representation.
- [Methods (evaluation protocol) and Results] The patient-disjoint protocol is correctly applied, yet images from the same patient at different magnifications share tissue morphology and staining. No analysis is provided to quantify residual patient-identity leakage in the final embeddings (e.g., patient-ID prediction accuracy), which could inflate apparent cross-magnification performance and undermine the isolation of the magnification-shift effect.
minor comments (2)
- [Results] The abstract and results mention specific numerical improvements but do not report run-to-run variance, statistical significance tests, or confidence intervals for the AUC, F1, and Brier differences; adding these would clarify whether the observed gains exceed experimental noise.
- [Results] The GAN-augmentation baseline shows inconsistent effects across folds; a brief discussion of why augmentation degraded performance at 400X would help readers interpret the comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The comments help clarify the strength of evidence for our invariance claims and the robustness of the evaluation protocol. We address each major comment below, agreeing where revisions are warranted and providing additional context from the patient-disjoint design where appropriate. All suggested analyses will be incorporated into the revised manuscript.
read point-by-point responses
-
Referee: [Results (leave-one-magnification-out experiments)] The central claim that gradient reversal produces magnification-invariant yet class-informative embeddings rests on downstream classification metrics and signature stability. No direct probe of invariance (e.g., magnification-prediction accuracy or mutual information between embeddings and magnification labels) is reported in the results; without it, the small AUC/F1 gains (0.967 vs. 0.965; 0.930 vs. 0.931) are consistent with either true invariance or a more robust but still magnification-sensitive representation.
Authors: We agree that a direct probe would provide stronger, more explicit support for the invariance claim. The reported gains in cross-magnification discrimination, Brier calibration (0.063 vs. 0.089), three-fold reduction in embedding dimensionality, and near-perfect signature reproducibility (Jaccard 0.99) are consistent with successful suppression of magnification-specific variation via gradient reversal. Nevertheless, these remain indirect. In the revision we will add an auxiliary experiment training a lightweight magnification classifier on the frozen embeddings from both the baseline and domain-general models, reporting prediction accuracy (and optionally mutual information) for each. We anticipate near-chance performance on the domain-general embeddings, directly quantifying the removal of magnification information while class discriminability is retained. revision: yes
-
Referee: [Methods (evaluation protocol) and Results] The patient-disjoint protocol is correctly applied, yet images from the same patient at different magnifications share tissue morphology and staining. No analysis is provided to quantify residual patient-identity leakage in the final embeddings (e.g., patient-ID prediction accuracy), which could inflate apparent cross-magnification performance and undermine the isolation of the magnification-shift effect.
Authors: We appreciate the referee raising this potential confounder. Because the protocol is strictly patient-disjoint, every test patient (and all of their images at the held-out magnification) is completely absent from the training set. Consequently, any patient-specific features encoded in the embeddings cannot contribute to classification performance on the held-out magnification, as the model has never observed those patients. This design already isolates the magnification-shift effect from patient identity. To further address the concern, we will add in the revision an analysis that trains a patient-ID predictor on the embeddings (using a separate held-out patient cohort) and reports its accuracy for both baseline and domain-general models, thereby quantifying any residual patient-specific information retained after training. revision: yes
Circularity Check
No circularity: all claims are direct empirical measurements on held-out data
full rationale
The manuscript presents an empirical study comparing supervised baselines, GAN-augmented training, and gradient-reversal domain generalization on the BreaKHis dataset under a patient-disjoint leave-one-magnification-out protocol. Reported quantities (AUC 0.967 vs 0.965, F1 0.930 vs 0.931, Brier score 0.063 vs 0.089, signature dimensionality 306 vs 1,074, Jaccard reproducibility 0.99) are computed directly from model outputs on held-out folds. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the domain-general objective is a standard adversarial training procedure whose success is assessed by external metrics rather than by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The BreaKHis dataset and patient-disjoint leave-one-magnification-out protocol adequately isolate magnification shift as the primary source of domain variation.
Reference graph
Works this paper leans on
-
[1]
& Zhao, Y
Qiao, Y., Zhao, L., Luo, C., Luo, Y., Wu, Y., Li, S., . . . & Zhao, Y. (2022). Multi-modality artificial intelligence in digital pathology.Briefings in Bioinformatics,23(6), bbac367
2022
-
[2]
C., Hao, J., Koh, H
Kosaraju, S. C., Hao, J., Koh, H. M., & Kang, M. (2020). Deep-Hipo: Multi-scale receptive field deep learning for histopathological image analysis.Methods,179, 3–13
2020
-
[3]
S., Huang, J
Rad, M. S., Huang, J. V., Hosseini, M. M., Choudhary, R., Siezen, H., Akabari, R., . . . & Rodd, B. (2025). Deep learning for digital pathology: A critical overview of methodological framework.Journal of Pathology Informatics, 100514
2025
- [4]
-
[5]
A., Oliveira, L
Spanhol, F. A., Oliveira, L. S., Petitjean, C., & Heutte, L. (2015). A dataset for breast can- cer histopathological image classification.IEEE Transactions on Biomedical Engineering, 63(7), 1455–1462. 11
2015
-
[6]
Zhou, K., Liu, Z., Qiao, Y., Xiang, T., & Loy, C. C. (2022). Domain generalization: A survey.IEEE Transactions on Pattern Analysis and Machine Intelligence,45(4), 4396– 4415
2022
-
[7]
Gupta, V., & Bhavsar, A. (2017). Breast cancer histopathological image classification: Is magnification important? InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops(pp. 17–24)
2017
-
[8]
Bayramoglu, N., Kannala, J., & Heikkil¨ a, J. (2016). Deep learning for magnification in- dependent breast cancer histopathology image classification. In2016 23rd International Conference on Pattern Recognition (ICPR)(pp. 2440–2445). IEEE
2016
-
[9]
Sikaroudi, M., Ghojogh, B., Karray, F., Crowley, M., & Tizhoosh, H. R. (2021). Magnifica- tion generalization for histopathology image embedding. In2021 IEEE 18th International Symposium on Biomedical Imaging (ISBI)(pp. 1864–1868). IEEE
2021
- [10]
-
[11]
E., Oostingh, G
Tschuchnig, M. E., Oostingh, G. J., & Gadermayr, M. (2020). Generative adversarial networks in digital pathology: A survey on trends and future potential.Patterns,1(6)
2020
-
[12]
C., & Brinker, T
Hetz, M., Bucher, T. C., & Brinker, T. (2023). Multi-domain stain normalization for digital pathology: A cycle-consistent adversarial network for whole slide images.arXiv preprint
2023
-
[13]
A., Khoury, Z
Alajaji, S. A., Khoury, Z. H., Elgharib, M., Saeed, M., Ahmed, A. R., Khan, M. B., . . . & Sultan, A. S. (2024). Generative adversarial networks in digital histopathology: Current applications, limitations, ethical considerations, and future directions.Modern Pathology, 37(1), 100369
2024
-
[14]
& Bengio, Y
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., . . . & Bengio, Y. (2020). Generative adversarial networks.Communications of the ACM,63(11), 139–144
2020
-
[15]
Attallah, O., & Pacal, I. (2026). Impact of magnification on deep learning approaches through comprehensive comparative study of histopathological breast cancer classification. Biomedical Signal Processing and Control,113, 108973
2026
-
[16]
N., Aurangzeb, K., Alhussein, M., Anwar, M
Iqbal, S., Qureshi, A. N., Aurangzeb, K., Alhussein, M., Anwar, M. S., Zhang, Y., & Syed, I. (2024). Adaptive magnification network for precise tumor analysis in histopathological images.Computers in Human Behavior,156, 108222. 12
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.