Recognition: unknown
SIEVES: Selective Prediction Generalizes through Visual Evidence Scoring
Pith reviewed 2026-05-07 16:42 UTC · model grok-4.3
The pith
SIEVES triples coverage in selective prediction for out-of-distribution visual question answering by scoring localized visual evidence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
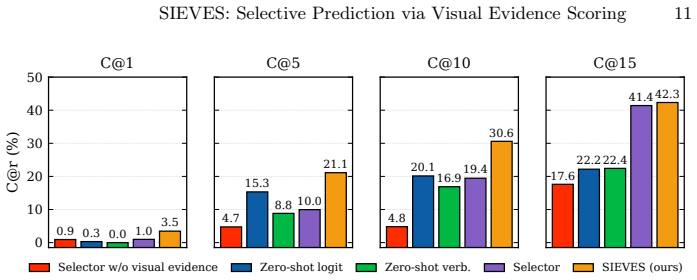
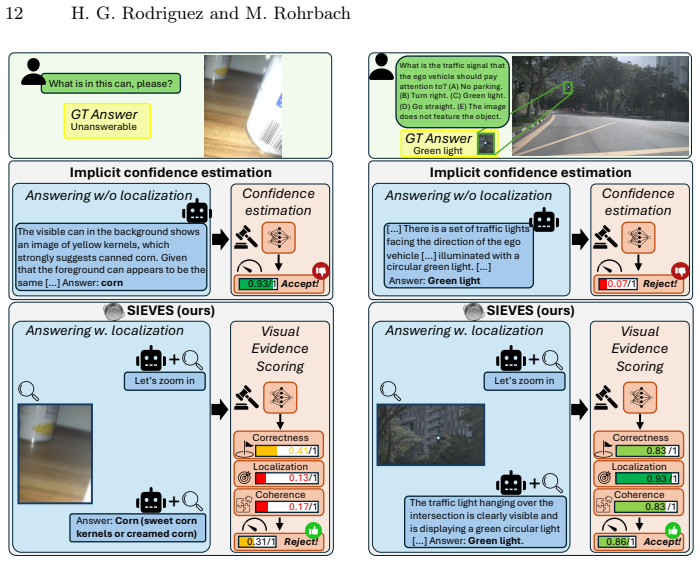
SIEVES requires the reasoner to output localized visual evidence alongside each answer and trains a selector to estimate the quality of that localization as a proxy for answer correctness. On five challenging out-of-distribution benchmarks the selector raises coverage up to three times higher than non-grounding baselines at controlled risk levels. The same selector generalizes across Pixel-Reasoner, o3, and Gemini-3-Pro without benchmark-specific or model-specific training or adaptation, including cases where only the final outputs of proprietary models are available.
What carries the argument
The SIEVES selector, which learns to score the quality of localized visual evidence produced by the reasoner to decide whether to answer or abstain.
If this is right
- Up to threefold higher coverage on OOD benchmarks at fixed risk levels compared with non-grounding baselines
- Transferable gains on proprietary models such as o3 and Gemini-3-Pro without weights or logits
- Consistent performance across five OOD datasets and three different reasoner architectures without retraining
- Selective prediction that outperforms methods relying solely on the reasoner's internal signals
Where Pith is reading between the lines
- Localization quality appears to be a more distribution-robust signal for abstention decisions than model-specific probabilities.
- The method supports selective prediction in API-only settings where internal model details are inaccessible.
- Evidence-scoring selectors could be tested on other multimodal tasks that require deciding when to answer.
Load-bearing premise
That the quality of a reasoner's localized visual evidence reliably indicates whether the accompanying answer is correct, even under distribution shift.
What would settle it
A new out-of-distribution visual question answering dataset where the SIEVES selector produces no coverage gain over a baseline that uses only the reasoner's native answer confidence at the same risk level.
Figures








read the original abstract
Multimodal large language models (MLLMs) achieve ever-stronger performance on visual-language tasks. Even as traditional visual question answering benchmarks approach saturation, reliable deployment requires satisfying low error tolerances in real-world out-of-distribution (OOD) scenarios. Precisely, selective prediction aims to improve coverage, i.e. the share of inputs the system answers, while adhering to a user-defined risk level. This is typically achieved by assigning a confidence score to each answer and abstaining on those that fall below a certain threshold. To enable reliable generalization, we require reasoner models to produce localized visual evidence while answering, and design a selector that explicitly learns to estimate the quality of the localization provided by the reasoner. We show that SIEVES (Selective Prediction through Visual Evidence Scoring) improves coverage by up to three times on challenging OOD benchmarks (V* Bench, HR-Bench-8k, MME-RealWorld-Lite, VizWiz, and AdVQA), compared to non-grounding baselines. Beyond better generalization to OOD tasks, the design of the SIEVES selector enables transfer to proprietary reasoners without access to their weights or logits, such as o3 and Gemini-3-Pro, providing coverage boosts beyond those attributable to accuracy alone. We highlight that SIEVES generalizes across all five tested OOD datasets and reasoner models (Pixel-Reasoner, o3, and Gemini-3-Pro), without benchmark- or reasoner-specific training or adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SIEVES, a selective prediction approach for multimodal LLMs in which the reasoner is prompted to output localized visual evidence (e.g., bounding boxes or regions) alongside its answer. A separate selector is trained to estimate the quality of this localization as a proxy for answer correctness, enabling abstention decisions that aim to maximize coverage while respecting a user-specified risk level. The authors report up to 3x coverage gains on five OOD benchmarks (V* Bench, HR-Bench-8k, MME-RealWorld-Lite, VizWiz, AdVQA) relative to non-grounding baselines, and claim that the same selector transfers without retraining or access to weights/logits to proprietary models including o3 and Gemini-3-Pro.
Significance. If the empirical claims hold, the work would offer a practical route to reliable selective prediction for vision-language systems that does not require white-box access or model-specific retraining. The emphasis on visual-evidence scoring as a transferable signal for risk calibration could influence deployment practices in safety-critical OOD settings.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experiments): the central generalization claim—that a selector trained solely on Pixel-Reasoner localization quality transfers to o3 and Gemini-3-Pro without adaptation—rests on the untested assumption that prompted visual evidence from the proprietary models lies in a distribution where the learned quality estimator remains well-calibrated. No quantitative comparison of evidence granularity, format, or error modes across models is supplied, leaving open the possibility that reported coverage gains at fixed risk are artifacts of miscalibration rather than genuine risk control.
- [§4.2 and Table 2] §4.2 and Table 2: the reported coverage improvements (up to 3x) are presented without accompanying risk-coverage curves, error bars, or statistical tests at the operating points used for comparison. It is therefore impossible to determine whether the gains are robust across risk levels or driven by a small number of easy examples.
- [§3.2] §3.2 (Selector training): the selector is described as learning an independent estimate of localization quality, yet no ablation is shown that isolates the contribution of the visual-evidence signal from simple answer-confidence baselines. Without this control, it remains unclear whether the reported OOD gains exceed what could be obtained by training a selector directly on answer correctness labels.
minor comments (2)
- [§2] Notation for the risk level and coverage metric is introduced inconsistently between the abstract and §2; a single, explicit definition (e.g., “coverage at 5 % error rate”) should be used throughout.
- [Figure 3] Figure 3 caption does not state the exact risk threshold or the number of runs used to generate the plotted curves.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address each of the major comments below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central generalization claim—that a selector trained solely on Pixel-Reasoner localization quality transfers to o3 and Gemini-3-Pro without adaptation—rests on the untested assumption that prompted visual evidence from the proprietary models lies in a distribution where the learned quality estimator remains well-calibrated. No quantitative comparison of evidence granularity, format, or error modes across models is supplied, leaving open the possibility that reported coverage gains at fixed risk are artifacts of miscalibration rather than genuine risk control.
Authors: We agree that the transfer to proprietary models relies on the assumption that the visual evidence quality is similarly distributed. Due to the black-box nature of o3 and Gemini-3-Pro, we cannot access their internal states to perform a full quantitative comparison of distributions. However, our results show consistent coverage improvements across these models, which would be unlikely if the selector were severely miscalibrated. To strengthen the manuscript, we will include a qualitative comparison of sample visual evidence outputs from Pixel-Reasoner, o3, and Gemini-3-Pro, highlighting similarities in format and granularity where possible. We will also discuss the limitations imposed by proprietary access in the revised version. revision: partial
-
Referee: [§4.2 and Table 2] §4.2 and Table 2: the reported coverage improvements (up to 3x) are presented without accompanying risk-coverage curves, error bars, or statistical tests at the operating points used for comparison. It is therefore impossible to determine whether the gains are robust across risk levels or driven by a small number of easy examples.
Authors: We acknowledge this limitation in the current presentation. In the revised manuscript, we will include risk-coverage curves for all evaluated methods and datasets to demonstrate performance across the full range of risk levels. Additionally, we will report error bars based on multiple experimental runs and include statistical significance tests (e.g., paired t-tests) for the coverage improvements at the reported operating points. This will provide a more complete picture of the robustness of the gains. revision: yes
-
Referee: [§3.2] §3.2 (Selector training): the selector is described as learning an independent estimate of localization quality, yet no ablation is shown that isolates the contribution of the visual-evidence signal from simple answer-confidence baselines. Without this control, it remains unclear whether the reported OOD gains exceed what could be obtained by training a selector directly on answer correctness labels.
Authors: We will add an ablation study in the revised §3.2 and §4 to isolate the contribution of the visual-evidence scoring. Specifically, we will compare SIEVES against a baseline selector trained solely on answer correctness labels (using the same architecture but without localization quality features). This will quantify whether the visual evidence provides benefits beyond what answer confidence alone can achieve. We expect the results to show that the localization signal contributes to better OOD generalization, but the ablation will make this explicit. revision: yes
Circularity Check
No circularity: selector training and selective prediction remain independent
full rationale
The paper trains a selector to estimate localization quality of visual evidence produced by a reasoner, then uses those scores for abstention in selective prediction. This is a standard supervised setup with no equations or claims showing that the coverage gains, OOD generalization, or transfer results reduce by construction to the training inputs or to a self-referential quantity. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps in the abstract or described method. The claimed improvements are presented as empirical outcomes on external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Anthropic: System card: Claude opus 4 & claude sonnet 4.https://www- cdn.anthropic.com/6d8a8055020700718b0c49369f60816ba2a7c285.pdf (2025)
2025
-
[2]
Lawrence Zitnick, and Devi Parikh
Antol, S., Agrawal, A., Lu, J., Mitchell, M., Batra, D., Zitnick, C.L., Parikh, D.: Vqa: Visual question answering. In: ICCV (2015),https://doi.org/ 10.1109/ICCV.2015.279
-
[3]
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., et al.: Qwen2. 5-vl technical report. arXiv preprint arXiv:2502.13923 (2025)
work page internal anchor Pith review arXiv 2025
-
[4]
In: NeurIPS (2024), https://doi.org/10.52202/079017-3970, URLhttps://doi.org/10
Belinkov, Y., Gurnee, W., Nanda, N., Sachan, M., Song, X., Stolfo, A., Wu, B.: Confidence regulation neurons in language models. In: NeurIPS (2024), https://doi.org/10.52202/079017-3970, URLhttps://doi.org/10. 52202/079017-3970
-
[5]
In: NeurIPS (2024),https://doi
Bhatt, U., Collins, K., Dooley, S., Goldblum, M., Gruver, N., Kapoor, S., Pal, A., Roberts, M., Weller, A., Wilson, A.: Large language models must be taught to know what they don’t know. In: NeurIPS (2024),https://doi. org/10.52202/079017-2729, URLhttps://doi.org/10.52202/079017- 2729
-
[6]
In: Bouamor, H., Pino, J., Bali, K
Chen, J., Yoon, J., Ebrahimi, S., Arik, S., Pfister, T., Jha, S.: Adaptation with self-evaluation to improve selective prediction in LLMs. In: Bouamor, H., Pino, J., Bali, K. (eds.) Findings of the Association for Computa- tional Linguistics: EMNLP 2023, pp. 5190–5213, Association for Compu- tational Linguistics, Singapore (Dec 2023),https://doi.org/10.18...
2023
-
[7]
Training Deep Nets with Sublinear Memory Cost
Chen, T., Xu, B., Zhang, C., Guestrin, C.: Training deep nets with sub- linear memory cost. arXiv preprint arXiv:1604.06174 (2016), URLhttps: //arxiv.org/abs/1604.06174
work page internal anchor Pith review arXiv 2016
-
[8]
Chow, C.K.: On optimum recognition error and reject tradeoff. IEEE Trans. Inf. Theory16(1), 41–46 (1970),https://doi.org/10.1109/TIT.1970. 1054406
-
[9]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plap- pert, M., Tworek, J., Hilton, J., Nakano, R., et al.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021)
work page internal anchor Pith review arXiv 2021
-
[10]
In: NeurIPS (2016), URLhttps://proceedings.neurips.cc/paper_files/paper/ 2016/file/7634ea65a4e6d9041cfd3f7de18e334a-Paper.pdf
Cortes, C., DeSalvo, G., Mohri, M.: Boosting with abstention. In: NeurIPS (2016), URLhttps://proceedings.neurips.cc/paper_files/paper/ 2016/file/7634ea65a4e6d9041cfd3f7de18e334a-Paper.pdf
2016
-
[11]
Dancette, C., Whitehead, S., Maheshwary, R., Vedantam, R., Scherer, S., Chen, X., Cord, M., Rohrbach, M.: Improving selective visual question answering by learning from your peers. arXiv preprint arXiv:2306.08751 (2023), URLhttps://arxiv.org/abs/2306.08751 SIEVES: Selective Prediction via Visual Evidence Scoring 17
-
[12]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Dao, T.: Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691 (2023), URLhttps: //arxiv.org/abs/2307.08691
work page internal anchor Pith review arXiv 2023
-
[13]
Eyes, B.M.: Be my ai.https://www.bemyeyes.com/be-my-ai(2026), ac- cessed on 03/05/2026
2026
-
[14]
Fu, X., Hu, Y., Krishna, R., Ostendorf, M., Roth, D., Shi, W., Smith, N., Zettlemoyer, L.: Visual sketchpad: Sketching as a visual chain of thought for multimodal language models. In: NeurIPS (2024),https://doi.org/ 10.52202/079017-4423, URLhttps://doi.org/10.52202/079017-4423, neurIPS 2024
-
[15]
In: NeurIPS (2017)
Geifman, Y., El-Yaniv, R.: Selective classification for deep neural networks. In: NeurIPS (2017)
2017
-
[16]
In: Chaudhuri, K., Salakhutdinov, R
Geifman, Y., El-Yaniv, R.: Selectivenet: A deep neural network with an in- tegrated reject option. In: Chaudhuri, K., Salakhutdinov, R. (eds.) Proceed- ings of the 36th International Conference on Machine Learning, Proceedings of Machine Learning Research, vol. 97, pp. 2151–2159, PMLR (09–15 Jun 2019), URLhttps://proceedings.mlr.press/v97/geifman19a.html
2019
- [17]
-
[18]
URL https://openaccess.thecvf.com/ content_cvpr_2017/html/Goyal_Making_the_v_CVPR_2017_paper.html
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the v in vqa matter: Elevating the role of image understanding in visual question answering. In: CVPR (2017),https://doi.org/10.1109/CVPR.2017.670
- [19]
-
[20]
2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) pp
Gu, S., Lugmayr, A., Danelljan, M., Fritsche, M., Lamour, J., Timofte, R.: Div8k: Diverse 8k resolution image dataset. 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW) pp. 3512–3516 (2019)
2019
-
[21]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025)
work page internal anchor Pith review arXiv 2025
-
[22]
Gurari, D., et al.: Vizwiz grand challenge: Answering visual questions from blind people. In: CVPR (2018),https://doi.org/10.1109/CVPR.2018. 00380
-
[23]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.0968510(2021)
work page internal anchor Pith review arXiv 2021
-
[24]
In: ICML 2025 Workshop on Reliable and Responsible Foundation Models (2025), URLhttps://openreview.net/forum?id=Ub3eXwQ0uA
Jang, C., Choi, M., Kim, Y., Lee, H., Lee, J.: Verbalized confidence triggers self-verification : Emergent behavior without explicit reasoning supervision. In: ICML 2025 Workshop on Reliable and Responsible Foundation Models (2025), URLhttps://openreview.net/forum?id=Ub3eXwQ0uA
2025
-
[25]
Why Language Models Hallucinate
Kalai, A.T., Nachum, O., Vempala, S.S., Zhang, E.: Why language models hallucinate. arXiv preprint arXiv:2509.04664 (2025)
work page internal anchor Pith review arXiv 2025
-
[26]
T-VSL: text-guided visual sound source localization in mixtures
Khan, Z., Fu, Y.: Consistency and uncertainty: Identifying unreliable re- sponses from black-box vision-language models for selective visual ques- tion answering. In: CVPR, pp. 10854–10863 (2024),https://doi.org/10. 1109/CVPR52733.2024.01032 18 H. G. Rodriguez and M. Rohrbach
-
[27]
In: Proceedings of the IEEE/CVF international conference on computer vision, pp
Kirillov, A., Mintun, E., Ravi, N., Mao, H., Rolland, C., Gustafson, L., Xiao, T., Whitehead, S., Berg, A.C., Lo, W.Y., et al.: Segment anything. In: Proceedings of the IEEE/CVF international conference on computer vision, pp. 4015–4026 (2023)
2023
-
[28]
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike,J.,Schulman,J.,Sutskever,I.,Cobbe,K.:Let’sverifystepbystep.In: The Twelfth International Conference on Learning Representations (2024)
2024
-
[29]
Lucarini, D., Pelz-Sharpe, A.: Intelligent document processing market analysis 2025-2028: Idp at the crossroads. Tech. rep., Deep Analysis (2025), URLhttps://www.deep-analysis.net/intelligent-document- processing-market-analysis-2025-2028/
2025
-
[30]
In: Finlayson, G.D., Triantaphillidou, S
Müller, P., Brummel, M., Braun, A.: Spatial recall index for machine learning algorithms. In: Finlayson, G.D., Triantaphillidou, S. (eds.) Lon- don Imaging Meeting 2021: Imaging for Deep Learning, LIM 2021, online, September 20-22, 2021, pp. 58–62, Society for Imaging Science and Technol- ogy (2021),https://doi.org/10.2352/ISSN.2694-118X.2021.LIM-58, URLh...
-
[31]
Mushtaq, E., Fabian, Z., Bakman, Y.F., Ramakrishna, A., Soltanolkotabi, M., Avestimehr, S.: Harmony: Hidden activation representations and model output-aware uncertainty estimation for vision-language models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW) (2025), URLhttps:// openaccess.thecvf.com/co...
2025
-
[32]
OpenAI: Gpt-5 system card.https://cdn.openai.com/gpt-5-system- card.pdf(2025)
2025
-
[33]
com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini- system-card.pdf(2025)
OpenAI: Openai o3 and o4-mini system card.https://cdn.openai. com/pdf/2221c875-02dc-4789-800b-e7758f3722c1/o3-and-o4-mini- system-card.pdf(2025)
2025
-
[34]
OpenAI: Thinking with images.https://openai.com/index/thinking- with-images/(2025)
2025
- [35]
-
[36]
org/roe.html(2021)
Shrivastava, A., Goyal, Y., Batra, D., Parikh, D., Agrawal, A.: Real open- ended track leaderboard results, vqa challenge 2021.https://visualqa. org/roe.html(2021)
2021
- [37]
-
[38]
selective prediction
Srinivasan, T., Hessel, J., Gupta, T., Lin, B.Y., Choi, Y., Thomason, J., Chandu, K.: Selective “selective prediction”: Reducing unnecessary ab- stention in vision-language reasoning. In: Findings of the Association for Computational Linguistics: ACL 2024, pp. 12935–12948 (2024),https: SIEVES: Selective Prediction via Visual Evidence Scoring 19 / / doi . ...
2024
-
[39]
Su, A., Wang, H., Ren, W., Lin, F., Chen, W.: Pixel Reasoner: Incentivizing Pixel-Space Reasoning with Curiosity-Driven Reinforcement Learning (May 2025)
2025
-
[40]
Team, G., Kamath, A., Ferret, J., Pathak, S., Vieillard, N., Merhej, R., Perrin, S., Matejovicova, T., Ramé, A., Rivière, M., Rouillard, L., Mes- nard, T., Cideron, G., Grill, J.b., Ramos, S., Yvinec, E., Casbon, M., Pot, E., Penchev, I., Liu, G., Visin, F., Kenealy, K., Beyer, L., Zhai, X., Tsit- sulin, A., Busa-Fekete, R., Feng, A., Sachdeva, N., Colema...
work page internal anchor Pith review arXiv 2025
-
[41]
Varshney,N.,Baral,C.:Post-abstention:Towardsreliablyre-attemptingthe abstained instances in QA. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 967–982, Association for Computational Linguistics, Toronto, Canada (Jul 2023),https://doi.org/10.18653/v1/2023.acl-long.55, URLhttps: //acl...
-
[42]
pdfreaderpro.com/blog/document-processing-statistics(2025)
Venter, M.: 40 intelligent document processing statistics.https://www. pdfreaderpro.com/blog/document-processing-statistics(2025)
2025
- [43]
-
[44]
Know your limits: A survey of abstention in large language models
Wen, B., Yao, J., Feng, S., Xu, C., Tsvetkov, Y., Howe, B., Wang, L.L.: Know your limits: A survey of abstention in large language models. Transac- tions of the Association for Computational Linguistics13, 529–556 (2025), https://doi.org/10.1162/tacl_a_00754, URLhttps://direct.mit. edu/tacl/article/doi/10.1162/tacl_a_00754
-
[45]
Rethinking data augmentation for robust LiDAR semantic segmentation in adverse weather,
Whitehead, S., Petryk, S., Shakib, V., Gonzalez, J., Darrell, T., Rohrbach, A., Rohrbach, M.: Reliable visual question answering: Abstain rather than answer incorrectly. In: Computer Vision – ECCV 2022 Workshops, pp. 148–166, Springer, Cham (2022),https://doi.org/10.1007/978-3-031- 20059-5_9
-
[46]
In: CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
Wu, P., Xie, S.: V*: Guided visual search as a core mechanism in multimodal llms. In: CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2024)
2024
-
[47]
Xin, J., Tang, R., Yu, Y., Lin, J.: The art of abstention: Selective prediction and error regularization for natural language processing. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL) (2021),https://doi.org/10.18653/v1/2021.acl-long.84, URL https://aclanthology.org/2021.acl-long.84 20 H. G. Rodriguez and...
-
[48]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al.: Qwen3 technical report. arXiv preprint arXiv:2505.09388 (2025)
work page internal anchor Pith review arXiv 2025
-
[49]
In: ICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI (2025), URL https://openreview.net/forum?id=CVRdNQvFPE
Yang, D., Tsai, Y.H.H., Yamada, M.: On verbalized confidence scores for LLMs. In: ICLR Workshop: Quantify Uncertainty and Hallucination in Foundation Models: The Next Frontier in Reliable AI (2025), URL https://openreview.net/forum?id=CVRdNQvFPE
2025
-
[50]
URL https://aclantholo gy.org/2023.acl-long.557/
Yoshikawa, H., Okazaki, N.: Selective-LAMA: Selective prediction for confidence-aware evaluation of language models. In: Vlachos, A., Augen- stein, I. (eds.) Findings of the Association for Computational Linguistics: EACL 2023, pp. 2017–2028, Association for Computational Linguistics, Dubrovnik, Croatia (May 2023),https://doi.org/10.18653/v1/2023. finding...
-
[51]
Zhang, Y.F., Lu, X., Yin, S., Fu, C., Chen, W., Hu, X., Wen, B., Jiang, K., Liu, C., Zhang, T., Fan, H., Chen, K., Chen, J., Ding, H., Tang, K., Zhang, Z., Wang, L., Yang, F., Gao, T., Zhou, G.: Thyme: Think beyond images (2025), URLhttps://arxiv.org/abs/2508.11630
work page internal anchor Pith review arXiv 2025
-
[52]
Zhang, Y.F., Zhang, H., Tian, H., Fu, C., Zhang, S., Wu, J., Li, F., Wang, K., Wen, Q., Zhang, Z., Wang, L., Jin, R., Tan, T.: Mme-realworld: Could your multimodal llm challenge high-resolution real-world scenarios that are difficult for humans? (2024), URLhttps://arxiv.org/abs/2408.13257
-
[53]
Zheng, Y., Zhang, R., Zhang, J., Ye, Y., Luo, Z., Feng, Z., Ma, Y.: Lla- mafactory: Unified efficient fine-tuning of 100+ language models. In: Pro- ceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), Association for Compu- tational Linguistics, Bangkok, Thailand (2024), URLhttp://arxiv.or...
work page internal anchor Pith review arXiv 2024
-
[54]
Thinking with Images
Zheng, Z., Yang, M., Hong, J., Zhao, C., Xu, G., Yang, L., Shen, C., Yu, X.: DeepEyes: Incentivizing "Thinking with Images" via Reinforcement Learn- ing (May 2025)
2025
-
[55]
Zhu, F., Lei, W., Feng, F., Wang, C., Zhang, H., Chua, T.S.: Towards com- plex document understanding by discrete reasoning. In: ACMMM (2022), https://doi.org/10.1145/3503161.3548422, URLhttps://doi.org/ 10.1145/3503161.3548422 SIEVES: Selective Prediction via Visual Evidence Scoring A1 Supplementary Material We briefly describe how the appendix is organi...
-
[56]
What is the material of the glove?
The exact prompt templates used for distractor options generation, answering with localization, correctness judging, coherence labeling, and localization anno- tation are shown in Sec. F. C Ablating threshold for binarizing localization Here,wealsoablatethemIoGTthresholdusedtobinarizethelocalizationtarget, which then propagates to the coherence target: gl...
-
[57]
Note you are not provided this final image, and only the crop, which the model should only use to give the final answer
**Crop Sufficiency**: Is the provided image crop sufficient to support the model’s response? Does it contain all the necessary visual information referenced in the response? If the model explicitly states they use the global view to answer this question, you should consider this as not grounded in the prompt. Note you are not provided this final image, an...
-
[58]
red car" -> \boxed{Yes} - If the crop shows a partial view that doesn’t contain enough information to answer -> \boxed{No} - If the crop shows a dog but the model answers
**Answer Coherence**: Is the model’s response coherent with what is actually visible in the image? Or is the model hallucinating information or obtaining it from elsewhere (not from the image)? Think step by step about both aspects, then provide your final assessment. Output your final decision as \boxed{Yes} if the answer is well-grounded in the image cr...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.