Recognition: unknown
Robust Deepfake Detection: Mitigating Spatial Attention Drift via Calibrated Complementary Ensembles
Pith reviewed 2026-05-07 16:31 UTC · model grok-4.3
The pith
A multi-stream ensemble trained on compound degradations suppresses spatial attention drift in deepfake detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that an extreme compound degradation engine combined with a three-stream architecture (Global Texture, Localized Facial, and Hybrid Semantic Fusion incorporating CLIP) extracts complementary invariant priors from a DINOv2-Giant backbone; when aggregated by calibrated discretized voting, the resulting ensemble suppresses background attention drift and functions as a robust geometric anchor for deepfake detection.
What carries the argument
Calibrated discretized voting over three complementary streams (Global Texture, Localized Facial, Hybrid Semantic Fusion with CLIP) that process invariant priors extracted by a DINOv2-Giant backbone trained on an extreme compound degradation pipeline.
If this is right
- The model maintains stable attention entropy on facial geometry under blurring and severe lossy compression.
- Quantitative Score-CAM and cosine-similarity analysis confirms the streams supply non-redundant representations.
- Zero-shot generalization remains high on degraded deepfake images without additional fine-tuning.
- The approach achieves fourth place in the NTIRE 2026 Robust Deepfake Detection Challenge.
Where Pith is reading between the lines
- The same degradation-plus-voting pattern could be transferred to other forensic vision tasks such as manipulation localization where background noise commonly misleads attention.
- Extending the streams with temporal consistency checks might allow the framework to handle video deepfakes without retraining the entire backbone.
- If the voting thresholds are learned rather than hand-calibrated, the method could adapt automatically to new degradation distributions encountered in deployment.
Load-bearing premise
The three streams extract non-redundant complementary features and the degradation engine sufficiently simulates real-world compound degradations to produce invariant priors.
What would settle it
If the ensemble exhibits the same degree of background attention drift as a single-stream baseline on a held-out test set containing blur-plus-compression combinations at severity levels absent from the training degradation engine, the robustness claim would be falsified.
Figures





read the original abstract
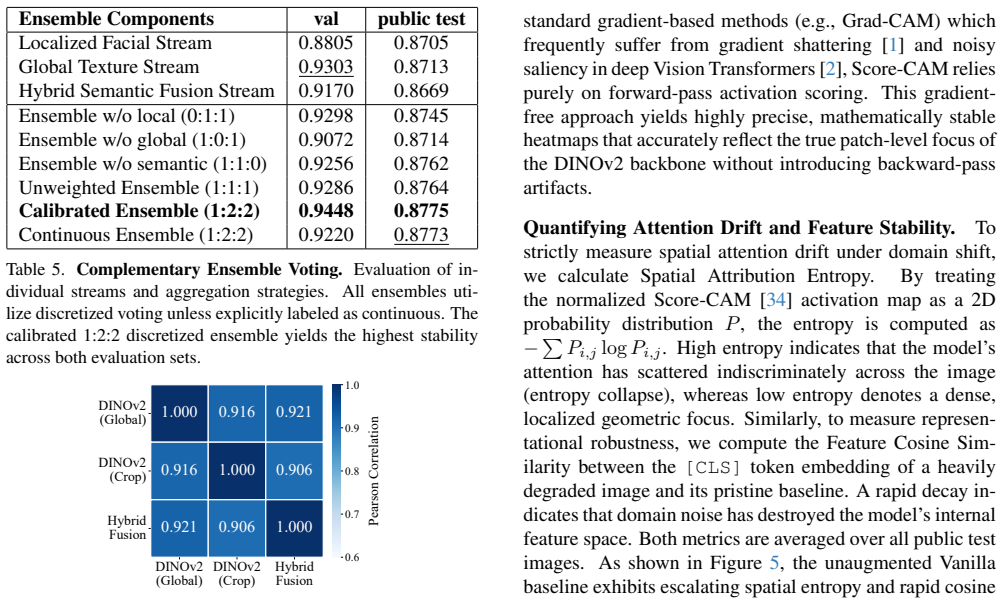
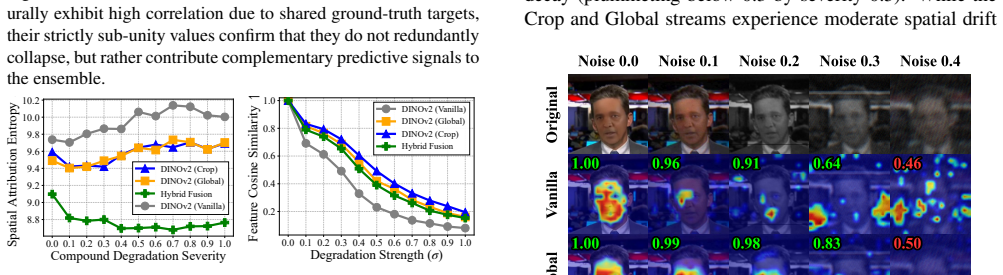
Current deepfake detection models achieve state-of-the-art performance on pristine academic datasets but suffer severe spatial attention drift under real-world compound degradations, such as blurring and severe lossy compression. To address this vulnerability, we propose a foundation-driven forensic framework that integrates an extreme compound degradation engine with a structurally constrained, multi-stream architecture. During training, our degradation pipeline systematically destroys high-frequency artifacts, optimizing the DINOv2-Giant backbone to extract invariant geometric and semantic priors. We then process images through three specialized pathways: a Global Texture stream, a Localized Facial stream, and a Hybrid Semantic Fusion stream incorporating CLIP. Through analyzing spatial attribution via Score-CAM and feature stability using Cosine Similarity, we quantitatively demonstrate that these streams extract non-redundant, complementary feature representations and stabilize attention entropy. By aggregating these predictions via a calibrated, discretized voting mechanism, our ensemble successfully suppresses background attention drift while acting as a robust geometric anchor. Our approach yields highly stable zero-shot generalization, achieving Fourth Place in the NTIRE 2026 Robust Deepfake Detection Challenge at CVPR. Code is available at https://github.com/khoalephanminh/ntire26-deepfake-challenge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a foundation-driven framework for robust deepfake detection that trains DINOv2-Giant on an extreme compound degradation engine to extract invariant geometric and semantic priors, then routes images through three complementary streams (Global Texture, Localized Facial, and Hybrid Semantic Fusion incorporating CLIP). Spatial attribution is analyzed via Score-CAM and feature stability via cosine similarity to demonstrate non-redundant representations and stabilized attention entropy; predictions are aggregated with a calibrated, discretized voting mechanism claimed to suppress background attention drift. The work reports fourth place in the NTIRE 2026 Robust Deepfake Detection Challenge at CVPR and releases code.
Significance. If the central claims hold, the manuscript offers a practical ensemble strategy that leverages foundation-model priors and explicit complementarity analysis to improve generalization under real-world degradations, with the challenge placement providing external validation. The quantitative use of Score-CAM and cosine similarity to link stream complementarity to attention stability is a methodological strength that could inform future forensic architectures.
major comments (2)
- [Abstract and §3] Abstract and §3 (Degradation Engine): The claim that the degradation pipeline produces priors invariant to real-world compound degradations is load-bearing for the zero-shot generalization and geometric-anchor assertions, yet the description is limited to blurring and lossy compression without specifying the full parameter ranges, combination distributions, or ablation studies against held-out real-world artifacts (e.g., sensor noise, variable lighting). If these simulations do not cover the target distribution, the extracted priors and subsequent voting stabilization may not transfer.
- [§4] §4 (Experimental Evaluation): The fourth-place NTIRE 2026 result is cited as evidence of stable generalization, but the manuscript provides no data splits, error bars, statistical tests, or full baseline comparisons. Without these, the quantitative support for suppressed attention drift and complementarity cannot be assessed, weakening the central empirical claim.
minor comments (2)
- [Abstract] The abstract states that streams 'extract non-redundant, complementary feature representations' via Score-CAM and cosine similarity, but does not report the specific similarity thresholds, entropy values, or statistical significance used to establish non-redundancy.
- [§3.3] Notation for the calibrated discretized voting mechanism is described only at a high level; adding explicit equations or pseudocode would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate the revisions we will incorporate to improve clarity and empirical support.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (Degradation Engine): The claim that the degradation pipeline produces priors invariant to real-world compound degradations is load-bearing for the zero-shot generalization and geometric-anchor assertions, yet the description is limited to blurring and lossy compression without specifying the full parameter ranges, combination distributions, or ablation studies against held-out real-world artifacts (e.g., sensor noise, variable lighting). If these simulations do not cover the target distribution, the extracted priors and subsequent voting stabilization may not transfer.
Authors: We agree that the current description of the degradation engine is concise and would benefit from greater detail to substantiate the invariance claims. In the revised manuscript we will expand §3 with the complete parameter ranges and sampling distributions for the compound degradations, along with an ablation that evaluates performance when additional real-world artifacts (sensor noise, lighting variation) drawn from the NTIRE 2026 data are introduced. The fourth-place challenge result already provides external evidence that the learned priors transfer under the target distribution, but the added ablations will directly address the concern. revision: yes
-
Referee: [§4] §4 (Experimental Evaluation): The fourth-place NTIRE 2026 result is cited as evidence of stable generalization, but the manuscript provides no data splits, error bars, statistical tests, or full baseline comparisons. Without these, the quantitative support for suppressed attention drift and complementarity cannot be assessed, weakening the central empirical claim.
Authors: The NTIRE 2026 placement constitutes official evaluation on a held-out test set, yet we acknowledge that internal statistical details are missing. We will revise §4 to report the training/validation splits, include error bars (standard deviation across multiple seeds) for the reported metrics, add statistical significance tests comparing the ensemble to its constituent streams, and expand the baseline table to encompass additional challenge entries and standard detectors. These changes will allow direct assessment of the complementarity and attention-stability claims. revision: yes
Circularity Check
No circularity; claims rest on independent architectural choices and empirical analysis
full rationale
The abstract and description present a degradation pipeline that destroys high-frequency artifacts to train invariant priors on DINOv2-Giant, followed by three distinct streams (Global Texture, Localized Facial, Hybrid Semantic Fusion with CLIP) whose complementarity is shown via Score-CAM and cosine similarity, then aggregated by a calibrated discretized voting mechanism. No equations appear, no parameters are fitted to a subset and then relabeled as predictions, and no self-citations or uniqueness theorems are invoked to justify core choices. The suppression of background attention drift and zero-shot generalization are reported as measured outcomes of these components rather than definitions or reductions to the inputs themselves. The chain is therefore self-contained against external benchmarks such as the NTIRE challenge results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The shattered gradients problem: If resnets are the answer, then what is the question? InInternational conference on machine learning, pages 342–350
David Balduzzi, Marcus Frean, Lennox Leary, JP Lewis, Kurt Wan-Duo Ma, and Brian McWilliams. The shattered gradients problem: If resnets are the answer, then what is the question? InInternational conference on machine learning, pages 342–350. PMLR, 2017. 7
2017
-
[2]
Transformer inter- pretability beyond attention visualization
Hila Chefer, Shir Gur, and Lior Wolf. Transformer inter- pretability beyond attention visualization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 782–791, 2021. 7
2021
-
[3]
Retinaface: Single-shot multi- level face localisation in the wild
Jiankang Deng, Jia Guo, Evangelos Ververas, Irene Kot- sia, and Stefanos Zafeiriou. Retinaface: Single-shot multi- level face localisation in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. 4
2020
-
[4]
Contributing data to deepfake detection
DFD. Contributing data to deepfake detection. Google AI Blog, 2020. Accessed: 2021-04-24. 4
2020
-
[5]
The deepfake detection challenge (DFDC) preview dataset,
Brian Dolhansky, Russ Howes, Ben Pflaum, Nicole Baram, and Cristian Canton Ferrer. The deepfake de- tection challenge (dfdc) preview dataset.arXiv preprint arXiv:1910.08854, 2019. 4
-
[6]
The DeepFake Detection Challenge (DFDC) Dataset
Brian Dolhansky, Joanna Bitton, Ben Pflaum, Jikuo Lu, Russ Howes, Menglin Wang, and Cristian Canton Ferrer. The deepfake detection challenge (dfdc) dataset.arXiv preprint arXiv:2006.07397, 2020. 4
work page internal anchor Pith review arXiv 2006
-
[7]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl- vain Gelly, et al. An image is worth 16x16 words: Trans- formers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020. 1, 4
work page internal anchor Pith review arXiv 2010
-
[8]
Leveraging fre- quency analysis for deep fake image recognition
Joel Frank, Thorsten Eisenhofer, Lea Sch ¨onherr, Asja Fis- cher, Dorothea Kolossa, and Thorsten Holz. Leveraging fre- quency analysis for deep fake image recognition. InInter- national conference on machine learning, pages 3247–3258. PMLR, 2020. 1
2020
-
[9]
Exploring unbiased deepfake detection via token- level shuffling and mixing
Xinhe Fu, Zhiyuan Yan, Taiping Yao, Shen Chen, and Xi Li. Exploring unbiased deepfake detection via token- level shuffling and mixing. InProceedings of the Thirty- Ninth AAAI Conference on Artificial Intelligence and Thirty- Seventh Conference on Innovative Applications of Artificial Intelligence and Fifteenth Symposium on Educational Ad- vances in Artifi...
2025
-
[10]
Shortcut learning in deep neural networks
Robert Geirhos, J ¨orn-Henrik Jacobsen, Claudio Michaelis, Richard Zemel, Wieland Brendel, Matthias Bethge, and Fe- lix A Wichmann. Shortcut learning in deep neural networks. Nature Machine Intelligence, 2(11):665–673, 2020. 1, 2, 3
2020
-
[11]
Rethinking vision-language model in face forensics: Multi-modal interpretable forged face detector
Xiao Guo, Xiufeng Song, Yue Zhang, Xiaohong Liu, and Xiaoming Liu. Rethinking vision-language model in face forensics: Multi-modal interpretable forged face detector. In Computer Vision and Pattern Recognition, 2025. 2
2025
-
[12]
Towards more general video-based deepfake detection through facial component guided adaptation for foundation model
Yue-Hua Han, Tai-Ming Huang, Kai-Lung Hua, and Jun- Cheng Chen. Towards more general video-based deepfake detection through facial component guided adaptation for foundation model. InProceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), 2025. 1, 2
2025
-
[13]
Towards more general video-based deepfake detection through facial component guided adaptation for foundation model
Yue-Hua Han, Tai-Ming Huang, Kai-Lung Hua, and Jun- Cheng Chen. Towards more general video-based deepfake detection through facial component guided adaptation for foundation model. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 22995–23005, 2025. 4
2025
-
[14]
E., Srivastava, N., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R
Geoffrey E Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, and Ruslan R Salakhutdinov. Improving neural networks by preventing co-adaptation of feature detectors. arXiv preprint arXiv:1207.0580, 2012. 4
-
[15]
Practical manipulation model for robust deepfake detection, 2025
Benedikt Hopf and Radu Timofte. Practical manipulation model for robust deepfake detection, 2025. 1, 2, 3
2025
-
[16]
Robust Deepfake De- tection, NTIRE 2026 Challenge: Report
Benedikt Hopf, Radu Timofte, et al. Robust Deepfake De- tection, NTIRE 2026 Challenge: Report . InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, 2026. 2, 5
2026
-
[17]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen- Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models, 2021. 1, 2, 3, 5
2021
-
[18]
Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection, 2020
Liming Jiang, Ren Li, Wayne Wu, Chen Qian, and Chen Change Loy. Deeperforensics-1.0: A large-scale dataset for real-world face forgery detection, 2020. 4
2020
-
[19]
Woo, and Jinyoung Han
Chaewon Kang, Seoyoon Jeong, Jonghyun Lee, Daejin Choi, Simon S. Woo, and Jinyoung Han. Hidf: A human- indistinguishable deepfake dataset. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, page 5527–5538, New York, NY , USA, 2025. Association for Computing Machinery. 4
2025
-
[20]
Ananya Kumar, Aditi Raghunathan, Robbie Jones, Tengyu Ma, and Percy Liang. Fine-tuning can distort pretrained fea- tures and underperform out-of-distribution.arXiv preprint arXiv:2202.10054, 2022. 5
-
[21]
Advancing high fidelity identity swapping for forgery detection
Lingzhi Li, Jianmin Bao, Hao Yang, Dong Chen, and Fang Wen. Advancing high fidelity identity swapping for forgery detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5074–5083,
-
[22]
In ictu oculi: Exposing ai created fake videos by detecting eye blinking
Yuezun Li, Ming-Ching Chang, and Siwei Lyu. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In 2018 IEEE International workshop on information forensics and security (WIFS), pages 1–7. Ieee, 2018. 4
2018
-
[23]
Celeb-df: A large-scale challenging dataset for deep- fake forensics, 2020
Yuezun Li, Xin Yang, Pu Sun, Honggang Qi, and Siwei Lyu. Celeb-df: A large-scale challenging dataset for deep- fake forensics, 2020. 4
2020
-
[24]
Celeb- df++: A large-scale challenging video deepfake benchmark for generalizable forensics, 2025
Yuezun Li, Delong Zhu, Xinjie Cui, and Siwei Lyu. Celeb- df++: A large-scale challenging video deepfake benchmark for generalizable forensics, 2025. 4
2025
-
[25]
Gener- alizing face forgery detection with high-frequency features
Yuchen Luo, Yong Zhang, Junchi Yan, and Wei Liu. Gener- alizing face forgery detection with high-frequency features. InProceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 16317–16326, 2021. 2
2021
-
[26]
Ddl: A large-scale datasets for deepfake detection and local- ization in diversified real-world scenarios, 2025
Changtao Miao, Yi Zhang, Weize Gao, Zhiya Tan, Weiwei Feng, Man Luo, Jianshu Li, Ajian Liu, Yunfeng Diao, Qi Chu, Tao Gong, Zhe Li, Weibin Yao, and Joey Tianyi Zhou. Ddl: A large-scale datasets for deepfake detection and local- ization in diversified real-world scenarios, 2025. 4
2025
-
[27]
Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake de- tection
Dat Nguyen, Nesryne Mejri, Inder Pal Singh, Polina Kuleshova, Marcella Astrid, Anis Kacem, Enjie Ghorbel, and Djamila Aouada. Laa-net: Localized artifact attention network for quality-agnostic and generalizable deepfake de- tection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17395–17405, 2024. 1, 2
2024
-
[28]
Towards uni- versal fake image detectors that generalize across genera- tive models
Utkarsh Ojha, Yuheng Li, and Yong Jae Lee. Towards uni- versal fake image detectors that generalize across genera- tive models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24480– 24489, 2023. 1, 4
2023
-
[29]
Dinov2: Learning robust visual features with- out supervision, 2024
Maxime Oquab, Timoth ´ee Darcet, Th ´eo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, Mah- moud Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herv ´e Je- gou, Julien Mairal, ...
2024
-
[30]
Learning transferable visual models from natural language supervision, 2021
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision, 2021. 1, 2, 3, 4
2021
-
[31]
Faceforen- sics: A large-scale video dataset for forgery detection in hu- man faces, 2018
Andreas R ¨ossler, Davide Cozzolino, Luisa Verdoliva, Chris- tian Riess, Justus Thies, and Matthias Nießner. Faceforen- sics: A large-scale video dataset for forgery detection in hu- man faces, 2018. 4
2018
-
[32]
Towards real-world deepfake de- tection: A diverse in-the-wild dataset of forgery faces, 2025
Junyu Shi, Minghui Li, Junguo Zuo, Zhifei Yu, Yipeng Lin, Shengshan Hu, Ziqi Zhou, Yechao Zhang, Wei Wan, Yinzhe Xu, and Leo Yu Zhang. Towards real-world deepfake de- tection: A diverse in-the-wild dataset of forgery faces, 2025. 4
2025
-
[33]
Detecting deep- fakes with self-blended images
Kaede Shiohara and Toshihiko Yamasaki. Detecting deep- fakes with self-blended images. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18720–18729, 2022. 1, 2
2022
-
[34]
Score-cam: Score-weighted visual explanations for convolutional neural networks
Haofan Wang, Zifan Wang, Mengnan Du, Fan Yang, Zijian Zhang, Sirui Ding, Piotr Mardziel, and Xia Hu. Score-cam: Score-weighted visual explanations for convolutional neural networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, pages 24–25, 2020. 2, 7
2020
-
[35]
What makes train- ing multi-modal classification networks hard? InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12695–12705, 2020
Weiyao Wang, Du Tran, and Matt Feiszli. What makes train- ing multi-modal classification networks hard? InProceed- ings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12695–12705, 2020. 4
2020
-
[36]
To- wards real-world blind face restoration with generative fa- cial prior
Xintao Wang, Yu Li, Honglun Zhang, and Ying Shan. To- wards real-world blind face restoration with generative fa- cial prior. InThe IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021. 4
2021
-
[37]
Zhiyuan Yan, Jiangming Wang, Zhendong Wang, Peng Jin, Ke-Yue Zhang, Shen Chen, Taiping Yao, Shouhong Ding, Baoyuan Wu, and Li Yuan. Effort: Efficient orthogonal mod- eling for generalizable ai-generated image detection.arXiv preprint arXiv:2411.15633, 2024. 1, 2
-
[38]
Df40: Toward next-generation deepfake detection, 2024
Zhiyuan Yan, Taiping Yao, Shen Chen, Yandan Zhao, Xinghe Fu, Junwei Zhu, Donghao Luo, Chengjie Wang, Shouhong Ding, Yunsheng Wu, and Li Yuan. Df40: Toward next-generation deepfake detection, 2024. 4
2024
-
[39]
Patch-discontinuity mining for general- ized deepfake detection, 2025
Huanhuan Yuan, Yang Ping, Zhengqin Xu, Junyi Cao, Shuai Jia, and Chao Ma. Patch-discontinuity mining for general- ized deepfake detection, 2025. 1, 2
2025
-
[40]
Multi-attentional deep- fake detection
Hanqing Zhao, Wenbo Zhou, Dongdong Chen, Tianyi Wei, Weiming Zhang, and Nenghai Yu. Multi-attentional deep- fake detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2185– 2194, 2021. 2
2021
-
[41]
Face forensics in the wild
Tianfei Zhou, Wenguan Wang, Zhiyuan Liang, and Jian- bing Shen. Face forensics in the wild. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5778–5788, 2021. 4
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.