Recognition: unknown
SAND: Spatially Adaptive Network Depth for Fast Sampling of Neural Implicit Surfaces
Pith reviewed 2026-05-10 11:49 UTC · model grok-4.3
The pith
Neural implicit surfaces can use spatially varying network depths to accelerate queries by terminating early in low-complexity areas.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a volumetric network-depth map, which stores the depth needed for sufficient accuracy in each region, combined with a tailed multi-layer perceptron allows network evaluation to terminate adaptively at the prescribed depth, improving query speed for implicit functions such as signed distance functions while preserving representation quality.
What carries the argument
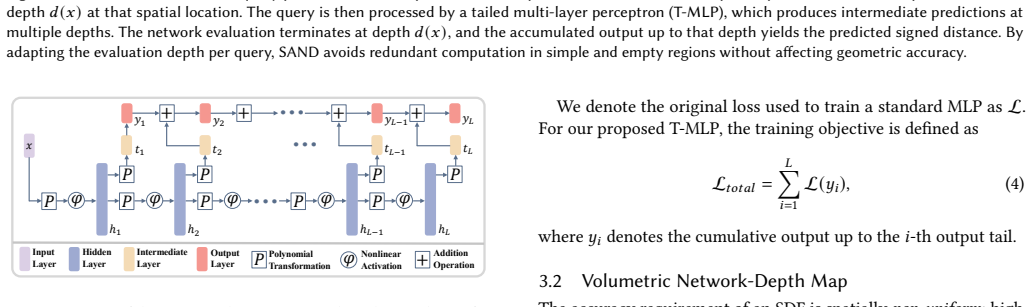
The volumetric network-depth map together with the tailed multi-layer perceptron (T-MLP), where an output branch is attached to each hidden layer so evaluation can stop without traversing the full network.
If this is right
- Query speeds for implicit neural representations increase substantially at inference time.
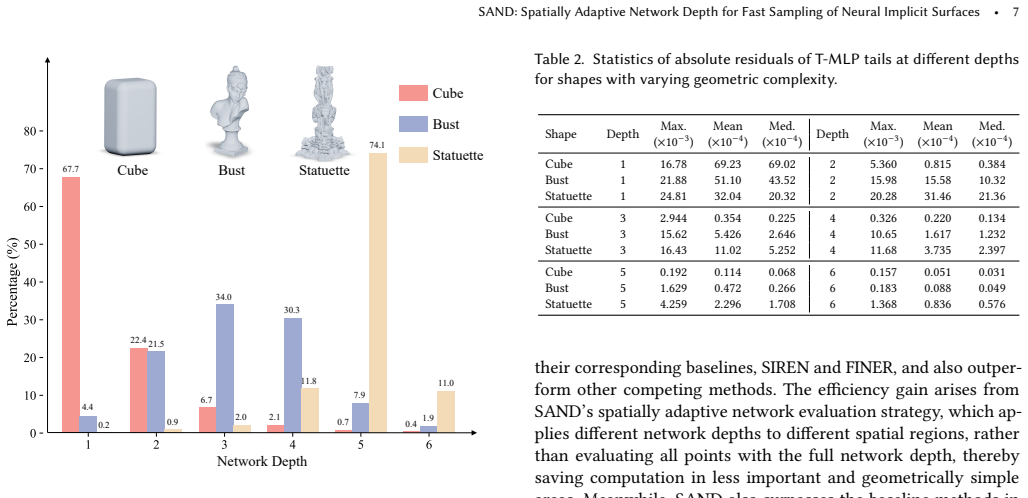
- Computational effort concentrates on geometrically complex regions near the surface.
- High-fidelity representations are maintained because termination occurs only after the map-specified accuracy is reached.
- The framework applies directly to signed distance functions and other common implicit representations.
Where Pith is reading between the lines
- The same depth-map idea could reduce query cost in related dense-sampling tasks such as neural radiance fields.
- Jointly optimizing the depth map during surface training would likely shrink any remaining overhead.
- For time-varying surfaces the depth map could be updated incrementally rather than recomputed from scratch.
Load-bearing premise
The volumetric depth map can be obtained or learned with negligible overhead and early termination at the prescribed depth preserves the required accuracy for the target application.
What would settle it
Compare signed distance values or extracted isosurfaces from full-depth evaluation versus SAND on the same dense query set around a surface with fine detail; visible deviation beyond a small tolerance would falsify the accuracy claim.
Figures





read the original abstract
Implicit neural representations are powerful for geometric modeling, but their practical use is often limited by the high computational cost of network evaluations. We observe that implicit representations require progressively lower accuracy as query points move farther from the target surface, and that even within the same iso-surface, representation difficulty varies spatially with local geometric complexity. However, conventional neural implicit models evaluate all query points with the same network depth and computational cost, ignoring this spatial variation and thereby incurring substantial computational waste. Motivated by this observation, we propose an efficient neural implicit geometry representation framework with spatially adaptive network depth (SAND). SAND leverages a volumetric network-depth map together with a tailed multi-layer perceptron (T-MLP) to model implicit representation. The volumetric depth map records, for each spatial region, the network depth required to achieve sufficient accuracy, while the T-MLP is a modified MLP designed to learn implicit functions such as signed distance functions, where an output branch, referred to as a tail, is attached to each hidden layer. This design allows network evaluation to terminate adaptively without traversing the full network and directs computational resources to geometrically important and complex regions, improving efficiency while preserving high-fidelity representations. Extensive experimental results demonstrate that our approach can significantly improve the inference-time query speed of implicit neural representations.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SAND, a framework for neural implicit surface representations that introduces a volumetric network-depth map to record spatially varying required network depths and a tailed MLP (T-MLP) with output branches attached to each hidden layer. This enables early termination of evaluations for query points far from or in low-complexity regions of the surface, directing computation to geometrically important areas while claiming to preserve high-fidelity signed distance functions. The central claim is that this adaptive mechanism yields significant inference-time speedups over standard uniform-depth MLPs, supported by extensive experiments.
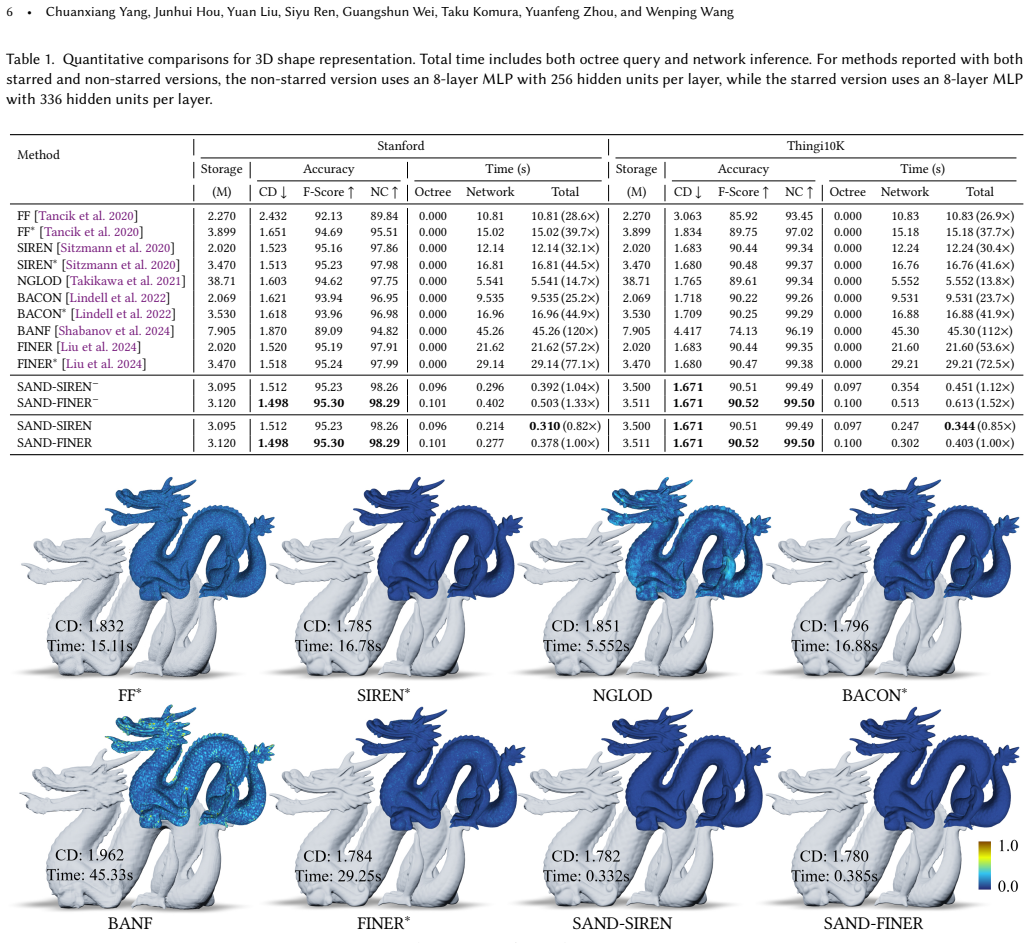
Significance. If the overhead of the depth map and accuracy of early tail outputs are validated, the approach could meaningfully advance practical deployment of neural implicits in graphics applications such as rendering and reconstruction by reducing computational waste without uniform full-network cost. The paper's strength lies in its explicit experimental validation across multiple datasets and baselines, demonstrating measurable query speed gains while maintaining representation quality.
major comments (3)
- [§3.2] §3.2 (T-MLP architecture): Early termination at prescribed depths assumes intermediate-layer outputs produce SDF values whose zero level set matches the full network to within application tolerances, but no error-bound analysis or per-region surface metric (e.g., local Hausdorff distance) is provided to confirm this; average pointwise error alone does not guarantee isosurface fidelity.
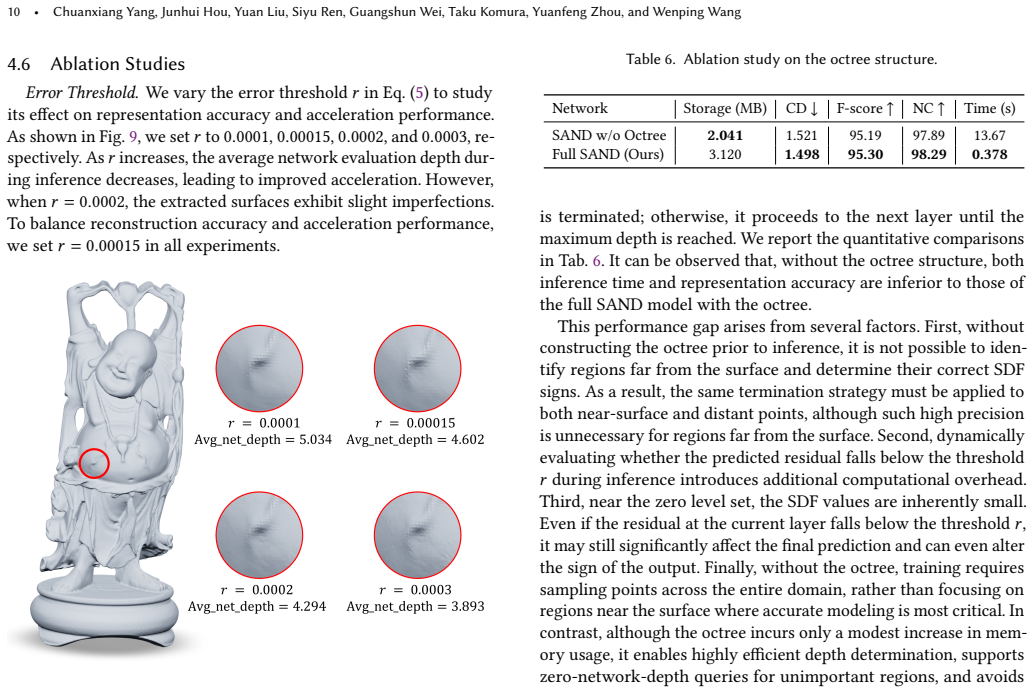
- [§4.1] §4.1 (volumetric depth map): The claim that the depth map adds negligible overhead is load-bearing for net speedup, yet the paper does not quantify storage, sampling, and interpolation costs relative to MLP savings (e.g., memory traffic for a 3D grid or pre-pass amortization); if the map is precomputed via dense full-network evaluations, this cost must be amortized and compared explicitly.
- [Table 3] Table 3 (speed/accuracy trade-off): Reported inference speedups are shown, but the table lacks a direct column comparing surface reconstruction error (Chamfer or IoU) between SAND and full-depth baselines specifically in early-termination voxels, undermining the claim that accuracy is preserved across all tested geometries.
minor comments (2)
- [§3.1] Notation for the depth map (e.g., D(x)) is introduced without an explicit equation defining its range or discretization; adding Eq. (X) would clarify how depths are quantized and stored.
- [Figure 4] Figure 4 caption does not specify the resolution of the volumetric depth map used in visualizations, making it difficult to assess memory scaling.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. We address each major comment point by point below, outlining the revisions we will make to strengthen the presentation and validation of SAND.
read point-by-point responses
-
Referee: [§3.2] Early termination at prescribed depths assumes intermediate-layer outputs produce SDF values whose zero level set matches the full network to within application tolerances, but no error-bound analysis or per-region surface metric (e.g., local Hausdorff distance) is provided to confirm this; average pointwise error alone does not guarantee isosurface fidelity.
Authors: We agree that average pointwise SDF error is insufficient to fully guarantee isosurface fidelity under early termination. While our current experiments include visual isosurface renderings and global metrics showing consistency, we will add a dedicated analysis in the revision: per-region surface metrics (local Hausdorff distance and normal consistency) computed specifically on points from early-termination voxels across multiple scenes. We will also include a brief discussion of the empirical approximation error of the tail outputs relative to the full network. This will provide direct evidence that the zero level sets remain aligned within practical tolerances. revision: yes
-
Referee: [§4.1] The claim that the depth map adds negligible overhead is load-bearing for net speedup, yet the paper does not quantify storage, sampling, and interpolation costs relative to MLP savings (e.g., memory traffic for a 3D grid or pre-pass amortization); if the map is precomputed via dense full-network evaluations, this cost must be amortized and compared explicitly.
Authors: We concur that explicit quantification of depth-map overhead is necessary to support the net speedup claims. In the revised version we will add a new subsection (or appendix) reporting: (1) storage cost as a function of grid resolution and bit depth, (2) per-query sampling and trilinear interpolation time, (3) precomputation cost (dense full-network evaluations) and its amortization over typical query counts (e.g., 10^5–10^6 points). We will also include a break-even analysis showing when the overhead is recovered. revision: yes
-
Referee: [Table 3] Reported inference speedups are shown, but the table lacks a direct column comparing surface reconstruction error (Chamfer or IoU) between SAND and full-depth baselines specifically in early-termination voxels, undermining the claim that accuracy is preserved across all tested geometries.
Authors: We acknowledge the gap in the current Table 3. We will augment the table (or introduce a companion table) with additional columns that report Chamfer distance and IoU computed exclusively on the subset of voxels where early termination occurs, for both SAND and the corresponding full-depth baseline. This will directly demonstrate that reconstruction accuracy is preserved in the early-termination regions across the evaluated geometries. revision: yes
Circularity Check
No circularity; auxiliary depth map and T-MLP are independently motivated structures with external experimental validation.
full rationale
The paper introduces SAND as a new architecture: a volumetric depth map that records per-region required depth plus a T-MLP with per-layer tails for early termination. Neither component is defined in terms of the final speedup result or isosurface accuracy; the depth map is described as learned or precomputed from accuracy requirements, and termination is a design choice whose fidelity is checked experimentally. No equation reduces a claimed prediction to a fitted input by construction, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled. The central claim rests on reported inference-time measurements rather than self-referential derivation, satisfying the self-contained criterion for score 0.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Volumetric network-depth map
no independent evidence
-
T-MLP (tailed MLP)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
ACM SIGGRAPH Computer Graphics21(4), 163–169 (1987)
FreSh: Frequency Shifting for Accelerated Neural Representation Learning. arXiv preprint arXiv:2410.05050(2024). Chiheon Kim, Doyup Lee, Saehoon Kim, Minsu Cho, and Wook-Shin Han. 2023. General- izable implicit neural representations via instance pattern composers. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11808–...
-
[2]
Convolutional occupancy networks. InComputer Vision–ECCV 2020: 16th Eu- ropean Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part III 16. Springer, 523–540. Haseena Rahmath P, Vishal Srivastava, Kuldeep Chaurasia, Roberto G Pacheco, and Rodrigo S Couto. 2024. Early-exit deep neural network-a comprehensive survey. Comput. Surveys57, 3 (2024), 1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.