Recognition: unknown
Similarity Choice and Negative Scaling in Supervised Contrastive Learning for Deepfake Audio Detection
Pith reviewed 2026-05-07 13:44 UTC · model grok-4.3
The pith
Cosine similarity with a delayed negative queue in supervised contrastive learning yields the lowest equal error rates for deepfake audio detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After stage-one fine-tuning of the encoder and projection head with the supervised contrastive objective on ASVspoof 2019 LA, followed by stage-two training of a linear classifier with binary cross-entropy, cosine similarity combined with a delayed queue produces superior equal error rates on ASVspoof 2019 evaluation, ASVspoof 2021 DF and LA, and in-the-wild test sets compared with angular similarity or absence of the queue.
What carries the argument
The supervised contrastive loss computed with either cosine or hyperspherical angular similarity, augmented by a warm-started global cross-batch queue that supplies and scales negative samples.
If this is right
- Cosine SupCon with a delayed queue reduces dependence on very large negative sets while still improving detection.
- Angular similarity supports strong performance even when queued negatives are unavailable.
- The two-stage separation of contrastive representation learning from linear classification remains effective across the tested similarity variants.
- Gains appear consistently on both ASVspoof 2021 and in-the-wild evaluations.
Where Pith is reading between the lines
- The same similarity and queue ablations could be tested on other audio classification tasks that use contrastive pre-training.
- Lower reliance on negative-sample volume may reduce training memory and compute costs in larger-scale audio models.
- Parallel controlled studies on similarity choice might reveal similar patterns in contrastive learning for image or video deepfake detection.
Load-bearing premise
Observed EER differences arise chiefly from the similarity function and negative-scaling choices rather than from interactions with other training details or dataset specifics.
What would settle it
Re-training the identical pipeline while changing only the similarity function and queue delay, then checking whether the reported EER gaps disappear.
Figures

read the original abstract
Supervised contrastive learning (SupCon) is widely used to shape representations, but has seen limited targeted study for audio deepfake detection. Existing work typically combines contrastive terms with broader pipelines; however, the focus on SupCon itself is missing. In this work, we run a controlled study on wav2vec2 XLS-R (300M) that varies (i) similarity in SupCon (cosine vs angular similarity derived from the hyperspherical angle) and (ii) negative scaling using a warm-started global cross-batch queue. Stage 1 fine-tunes the encoder and projection head with SupCon; Stage 2 freezes them and trains a linear classifier with BCE. Trained on ASVspoof 2019 LA and evaluated on ASV19 eval plus ITW and ASVspoof 2021 DF/LA, Cosine SupCon with a delayed queue achieves the best ITW EER (8.29%) and pooled EER (4.44), while angular similarity performs strongly without queued negatives (ITW 8.70), indicating reduced reliance on large negative sets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled study on supervised contrastive learning (SupCon) for deepfake audio detection with wav2vec2 XLS-R (300M). It varies similarity (cosine vs. angular, derived from hyperspherical angle) and negative scaling (delayed global cross-batch queue vs. none) during Stage-1 SupCon fine-tuning of the encoder and projection head; Stage 2 freezes the model and trains a linear head with BCE. Trained on ASVspoof 2019 LA and evaluated on ASVspoof 2019 eval, ITW, and ASVspoof 2021 DF/LA, the results indicate that cosine SupCon with the delayed queue yields the lowest ITW EER (8.29%) and pooled EER (4.44), while angular similarity performs competitively without queued negatives (ITW EER 8.70%), suggesting reduced reliance on large negative sets.
Significance. If the attribution to similarity choice and queue-based scaling holds after proper controls, the work supplies targeted, practical guidance on SupCon design for audio deepfake detection. The concrete EER numbers and the efficiency observation for angular similarity could inform representation-learning pipelines that must operate with limited negative samples or compute, especially when building on large pre-trained models such as XLS-R.
major comments (2)
- [Abstract / §4 (Experiments)] Abstract and experimental description: the reported EER ranking (cosine+queue at 8.29% ITW vs. angular+no-queue at 8.70%) is presented as evidence that the two varied axes drive performance, yet the manuscript provides no explicit statement or ablation confirming that temperature, projection-head dimension, learning-rate schedule, augmentations, and queue hyperparameters were held fixed across runs. Without such isolation the performance gap cannot be confidently assigned to similarity and negative scaling rather than unablated interactions.
- [Abstract / Results tables] Results presentation: the abstract and any accompanying tables report point EER values (e.g., 8.29%, 4.44, 8.70) with no error bars, standard deviations across random seeds, or statistical significance tests. This omission weakens the claim that one configuration is reliably superior and makes it impossible to judge whether observed differences exceed typical training variance.
minor comments (2)
- [Abstract] The abstract would be clearer if it explicitly named the training set (ASVspoof 2019 LA) and all evaluation sets in a single sentence.
- [Results] A consolidated table listing EER for every similarity/queue combination on every test set would improve readability and allow direct comparison.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each of the major comments below.
read point-by-point responses
-
Referee: [Abstract / §4 (Experiments)] Abstract and experimental description: the reported EER ranking (cosine+queue at 8.29% ITW vs. angular+no-queue at 8.70%) is presented as evidence that the two varied axes drive performance, yet the manuscript provides no explicit statement or ablation confirming that temperature, projection-head dimension, learning-rate schedule, augmentations, and queue hyperparameters were held fixed across runs. Without such isolation the performance gap cannot be confidently assigned to similarity and negative scaling rather than unablated interactions.
Authors: We agree that making the controlled nature of the study more explicit would strengthen the paper. Although the manuscript describes the work as a 'controlled study' varying only the two specified factors, we will add a clear statement in the revised Section 4 confirming that temperature, projection-head dimension, learning-rate schedule, augmentations, and queue hyperparameters were held fixed across all runs. This will better isolate the effects of similarity choice and negative scaling. revision: yes
-
Referee: [Abstract / Results tables] Results presentation: the abstract and any accompanying tables report point EER values (e.g., 8.29%, 4.44, 8.70) with no error bars, standard deviations across random seeds, or statistical significance tests. This omission weakens the claim that one configuration is reliably superior and makes it impossible to judge whether observed differences exceed typical training variance.
Authors: We recognize that including measures of variability would enhance confidence in the results. Due to the high computational cost associated with fine-tuning the large XLS-R model, each configuration was evaluated with a single training run. The performance gaps (e.g., 0.41% EER difference on ITW) are substantial relative to expected variance in such tasks, but we will include a note in the revised manuscript acknowledging the single-run limitation and the absence of statistical significance testing. revision: partial
Circularity Check
No circularity; empirical comparisons rest on direct experiments
full rationale
The paper reports results from a controlled experimental study on wav2vec2 XLS-R using SupCon in stage 1 followed by BCE in stage 2. It varies only similarity function (cosine vs. angular) and negative scaling (delayed queue vs. none), then measures EER on ASVspoof 2019 LA training with evaluation on ASV19, ITW, and ASVspoof 2021. All reported numbers (e.g., 8.29% ITW EER for cosine+queue) are obtained by training and testing; no equations, predictions, or first-principles derivations are presented that could reduce to the inputs by construction. No self-citations appear in the provided text, and no fitted parameters are relabeled as predictions. The work is self-contained against external benchmarks via explicit dataset splits and metrics.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Introduction Recent advances in neural text-to-speech (TTS) and voice con- version (VC) systems have drastically improved the realism of synthetic speech. These modern generative systems are capa- ble of synthesizing speech that is perceptually indistinguish- able from genuine recordings. While these technologies enable beneficial applications including p...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[2]
Related Work Recent work has used supervised contrastive learning (Sup- Con) to improve robustness, but typically byengineering hard negativesandstructuring mini-batches. Trident of Poseidon introduces a triad training strategy that combines supervised contrastive learning with hard negative mining through audio re-synthesis and proactive batch sampling t...
-
[3]
The encoder architecture, projection dimension, pooling strategy, Stage 2 classifier, optimizer, and augmentation policy are fixed across all experiments
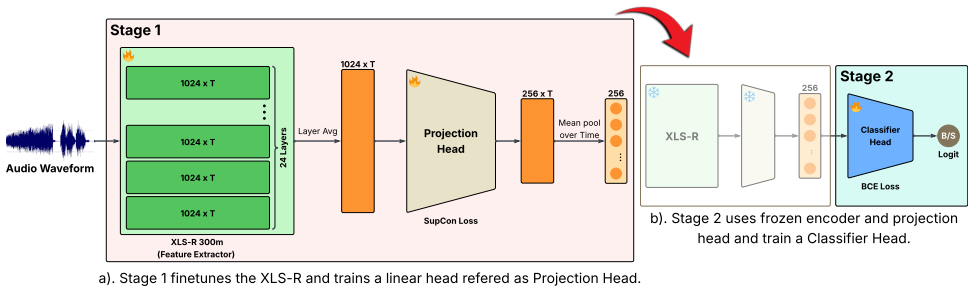
Method We study supervised contrastive learning for deepfake speech detection in a controlled two-stage XLS-R pipeline. The encoder architecture, projection dimension, pooling strategy, Stage 2 classifier, optimizer, and augmentation policy are fixed across all experiments. We vary only two factors in Stage 1: the similarity function used inside SupCon (S...
-
[4]
Datasets and evaluation protocol We train all models on the ASVspoof 2019 Logical Access (LA)trainsplit and select checkpoints using the officialdev split [3]
Experimental Setup 4.1. Datasets and evaluation protocol We train all models on the ASVspoof 2019 Logical Access (LA)trainsplit and select checkpoints using the officialdev split [3]. No target-domain data from ASVspoof 2021 or ITW is used during training or model selection. In-domain per- formance is reported on ASVspoof 2019 LAeval. To assess cross-data...
2019
-
[5]
Relative to the BCE base- line (pooled EER7.27), SupCon improves cross-dataset per- formance whenτis tuned, but the optimalτdiffers by sim- ilarity
Results To isolate the effect of the similarity geometry and the temper- atureτ, we first perform a temperature sweep for cosine- and geodesic-based SupCon (Table 1). Relative to the BCE base- line (pooled EER7.27), SupCon improves cross-dataset per- formance whenτis tuned, but the optimalτdiffers by sim- ilarity. For cosine,τ= 0.30yields the best pooled ...
2048
-
[6]
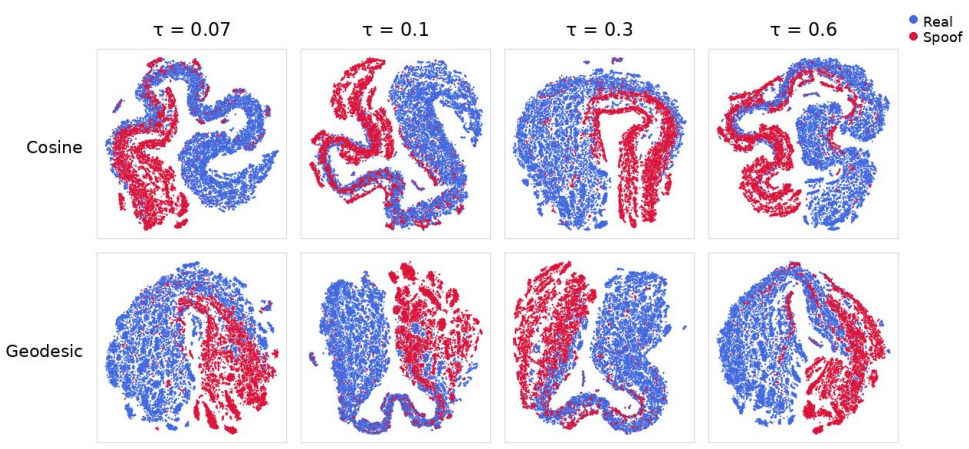
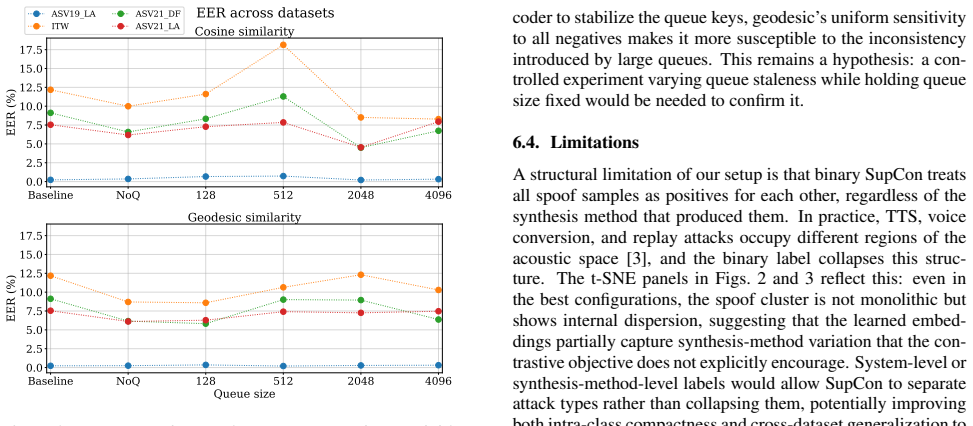
Discussion 6.1. Effect of temperature and similarity choice Table 1 shows that the optimal temperature differs substantially between the two similarity functions: cosine peaks atτ=0.30 while geodesic peaks atτ=0.07, a fourfold difference. This is consistent with the gradient dynamics argument in Section 3.3: geodesic’s linear dependence onθ ij makes the l...
2048
-
[7]
Conclusion and Future Work We presented a controlled study of two SupCon design choices similarity function and negative scaling for cross-dataset deep- fake audio detection with XLS-R. Our results show that sim- ilarity choice and temperature are coupled: geodesic similar- ity achieves strong OOD performance at a much lower tem- perature than cosine, con...
2048
-
[8]
Add 2022: the first audio deep synthesis detection challenge,
J. Yi, R. Fu, J. Tao, S. Nie, H. Ma, C. Wang, T. Wang, Z. Tian, X. Zhang, Y . Bai, C. Fan, S. Liang, S. Wang, S. Zhang, X. Yan, L. Xu, Z. Wen, H. Li, Z. Lian, and B. Liu, “Add 2022: the first audio deep synthesis detection challenge,” 2024. [Online]. Available: https://arxiv.org/abs/2202.08433
-
[9]
H. Tak, M. Todisco, X. Wang, J. weon Jung, J. Yamagishi, and N. Evans, “Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation,” 2022. [Online]. Available: https://arxiv.org/abs/2202.12233
-
[10]
Asvspoof 2019: Future horizons in spoofed and fake audio detection,
M. e. a. Todisco, “Asvspoof 2019: Future horizons in spoofed and fake audio detection,” inInterspeech, 2019
2019
-
[11]
Asvspoof 2021: accelerating progress in spoofed and deep- fake speech detection,
J. Yamagishi, X. Wang, M. Todisco, M. Sahidullah, J. Patino, A. Nautsch, X. Liu, K. A. Lee, T. Kinnunen, N. Evanset al., “Asvspoof 2021: accelerating progress in spoofed and deep- fake speech detection,” inASVspoof 2021 Workshop-Automatic Speaker Verification and Spoofing Coutermeasures Challenge, 2021
2021
-
[12]
Is audio spoof detection robust to laundering attacks?
H. Ali, S. Subramani, S. Sudhir, R. Varahamurthy, and H. Malik, “Is audio spoof detection robust to laundering attacks?” inPro- ceedings of the 2024 ACM Workshop on Information Hiding and Multimedia Security, 2024, pp. 283–288
2024
-
[13]
A SUPERB-Style Benchmark of Self-Supervised Speech Models for Audio Deepfake Detection
H. Ali, N. S. Adupa, S. Subramani, and H. Malik, “A superb-style benchmark of self-supervised speech models for audio deepfake detection,” 2026. [Online]. Available: https: //arxiv.org/abs/2603.01482
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Spoofed speech detection with a focus on speaker embedding
H. M. Tran, D. Guennec, P. Martin, A. Sini, D. Lolive, A. Del- hay, and P.-F. Marteau, “Spoofed speech detection with a focus on speaker embedding.” inInterspeech, 2024
2024
-
[15]
Trident of poseidon: A generalized approach for detecting deepfake voices,
T.-P. Doan, H. Dinh-Xuan, T. Ryu, I. Kim, W. Lee, K. Hong, and S. Jung, “Trident of poseidon: A generalized approach for detecting deepfake voices,” inProceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security, ser. CCS ’24. New York, NY , USA: Association for Computing Machinery, 2024, p. 2222–2235. [Online]. Available: http...
-
[16]
Balance, multi- ple augmentation, and re-synthesis: A triad training strategy for enhanced audio deepfake detection,
P. Doan, L. Nguyen Vu, K. Hong, and S. Jung, “Balance, multi- ple augmentation, and re-synthesis: A triad training strategy for enhanced audio deepfake detection,” 09 2024, pp. 2105–2109
2024
-
[17]
Clad: Robust audio deepfake detection against manipulation attacks with contrastive learning,
H. Wu, J. Chen, R. Du, C. Wu, K. He, X. Shang, H. Ren, and G. Xu, “Clad: Robust audio deepfake detection against manipulation attacks with contrastive learning,” 2024. [Online]. Available: https://arxiv.org/abs/2404.15854
-
[18]
Supervised contrastive learning,
P. Khosla, P. Teterwak, C. Wang, A. Sarna, Y . Tian, P. Isola, A. Maschinot, C. Liu, and D. Krishnan, “Supervised contrastive learning,” 2021. [Online]. Available: https://arxiv.org/abs/2004. 11362
2021
-
[19]
A simple framework for contrastive learning of visual representations,
T. Chen, S. Kornblith, M. Norouzi, and G. Hinton, “A simple framework for contrastive learning of visual representations,”
-
[20]
A Simple Framework for Contrastive Learning of Visual Representations
[Online]. Available: https://arxiv.org/abs/2002.05709
work page internal anchor Pith review arXiv 2002
-
[21]
Momentum contrast for unsupervised visual representation learning
K. He, H. Fan, Y . Wu, S. Xie, and R. Girshick, “Momentum contrast for unsupervised visual representation learning,” 2020. [Online]. Available: https://arxiv.org/abs/1911.05722
-
[22]
Representation Learning with Contrastive Predictive Coding
A. van den Oord, Y . Li, and O. Vinyals, “Representation learning with contrastive predictive coding,” 2019. [Online]. Available: https://arxiv.org/abs/1807.03748
work page internal anchor Pith review arXiv 2019
-
[23]
Contrastive learning with hard negative samples,
J. Robinson, C.-Y . Chuang, S. Sra, and S. Jegelka, “Contrastive learning with hard negative samples,” 2021. [Online]. Available: https://arxiv.org/abs/2010.04592
-
[24]
Cross-batch memory for embedding learning,
X. Wang, H. Zhang, W. Huang, and M. R. Scott, “Cross-batch memory for embedding learning,” 2020. [Online]. Available: https://arxiv.org/abs/1912.06798
-
[25]
Does Audio Deepfake Detection Generalize?
N. M. M ¨uller, P. Czempin, F. Dieckmann, A. Froghyar, and K. B ¨ottinger, “Does Audio Deepfake Detection Generalize?” Apr. 2022, arXiv:2203.16263 [cs, eess]. [Online]. Available: http://arxiv.org/abs/2203.16263
-
[26]
A gradient accumulation method for dense retriever under memory constraint,
J. Kim, Y . Lee, and P. Kang, “A gradient accumulation method for dense retriever under memory constraint,” 2024. [Online]. Available: https://arxiv.org/abs/2406.12356
-
[27]
Raw- boost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,
H. Tak, M. Kamble, J. Patino, M. Todisco, and N. Evans, “Raw- boost: A raw data boosting and augmentation method applied to automatic speaker verification anti-spoofing,” inICASSP 2022- 2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2022, pp. 6382–6386
2022
-
[28]
Xls-r: Self-supervised cross- lingual speech representation learning at scale,
A. Babu, C. Wang, A. Tjandra, K. Lakhotia, Q. Xu, N. Goyal, K. Singh, P. von Platen, Y . Saraf, J. Pino, A. Baevski, A. Conneau, and M. Auli, “Xls-r: Self-supervised cross- lingual speech representation learning at scale,” 2021. [Online]. Available: https://arxiv.org/abs/2111.09296
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.