Recognition: unknown
FlowS: One-Step Motion Prediction via Local Transport Conditioning
Pith reviewed 2026-05-07 15:24 UTC · model grok-4.3
The pith
By anchoring the base distribution near plausible futures, single-step flow matching delivers accurate multimodal motion prediction at real-time speeds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
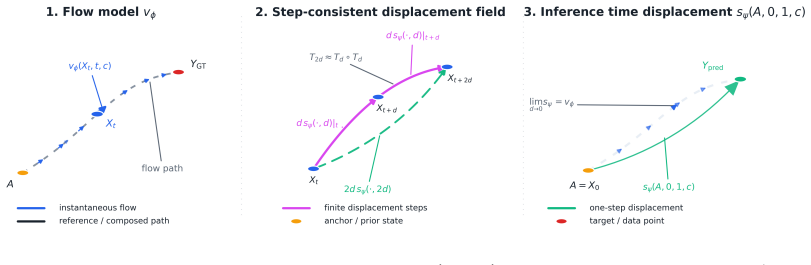
The paper claims that single-step integration is accurate when the underlying transport problem is local. An online scene-conditioned prior first emits K calibrated anchor trajectories per agent already near plausible futures, converting mode discovery into local correction. A step-consistent displacement field, anchored at these priors along straight-line paths, then enforces semigroup self-consistency so that one step inherits the accuracy of multiple steps without suffering high-variance bootstrap signals.
What carries the argument
Local transport conditioning: the mechanism that places the base distribution near plausible futures via learned anchor trajectories, reducing global transport to short-range refinement amenable to single Euler-step integration.
If this is right
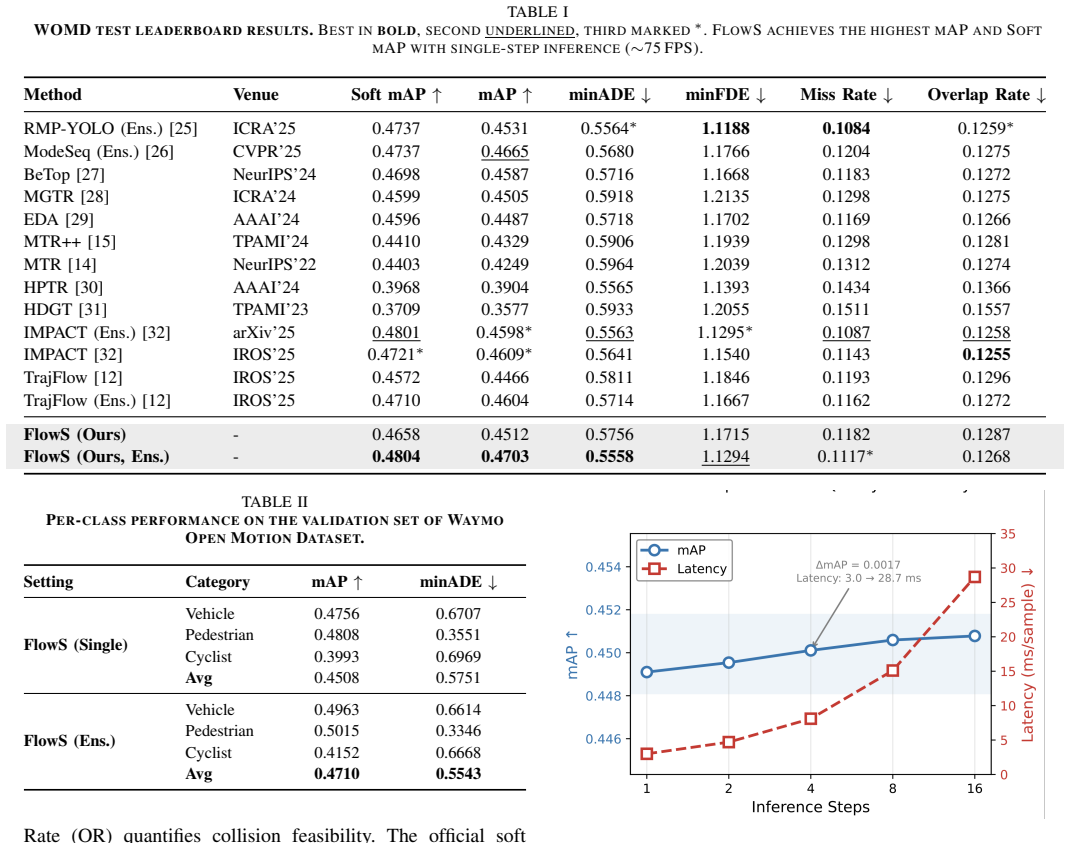
- Single-step inference reaches Soft mAP of 0.4804 and mAP of 0.4703 on the Waymo Open Motion Dataset.
- The model runs at 75 FPS while preserving multimodal diversity required for safety-critical planning.
- Anchoring the displacement field at learned priors along straight paths yields stable low-variance training targets.
- The semigroup self-consistency property guarantees that one-step outputs match the accuracy of multi-step integration.
Where Pith is reading between the lines
- The same local-conditioning principle could be tested on other generative tasks such as trajectory forecasting in robotics or short-horizon video prediction where full diffusion remains too slow.
- Performance would likely degrade if the prior anchors are poorly calibrated, indicating that joint training of the prior and the flow field is essential.
- Adaptive choice of the number of anchors per agent could further improve coverage of rare but safety-critical modes without increasing inference cost.
Load-bearing premise
An online scene-conditioned learned prior must reliably emit calibrated anchor trajectories already close to actual plausible futures for each agent.
What would settle it
Training and evaluating the identical single-step model without the anchor prior on the Waymo Open Motion Dataset and checking whether its Soft mAP falls to the level of ordinary unconditioned one-step baselines.
Figures




read the original abstract
Generative motion prediction must satisfy three simultaneous requirements for real-world autonomy: high accuracy, diverse multimodal futures, and strictly bounded latency. Diffusion models meet the first two but violate the third, requiring tens to hundreds of denoising steps. We identify a conditioning strategy that resolves this tension: \textit{single-step integration is accurate when the underlying transport problem is local}. A model that must both discover the correct behavioral mode and traverse a long displacement in one step accumulates large discretization errors; conditioning the base distribution to lie near plausible futures reduces the problem to short-range refinement, the regime where a single Euler step suffices. We instantiate this \emph{local transport conditioning} in FlowS, a conditional flow matching framework with two mechanisms. First, an online, scene-conditioned learned prior emits $K$ calibrated anchor trajectories per agent, each already near a plausible future, converting mode discovery into local correction. Second, a step-consistent displacement field enforces semigroup self-consistency, guaranteeing that a single step inherits multi-step accuracy. Crucially, anchoring this field at learned priors along straight-line paths yields a {stable, low-variance} training target, unlike prior self-consistency methods that suffer from {high-variance bootstrap} signals on curved diffusion paths. On the Waymo Open Motion Dataset, FlowS achieves state-of-the-art Soft mAP {(0.4804) and mAP (0.4703) with ensemble at 75\,FPS} with single-step inference, demonstrating that local transport conditioning makes one-step generative motion prediction practical for safety-critical autonomy. Code and pretrained models will be released upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes FlowS, a conditional flow matching model for one-step generative motion prediction. It uses local transport conditioning via an online scene-conditioned learned prior that emits K calibrated anchor trajectories per agent, combined with a step-consistent displacement field trained on straight-line paths from these priors. This reduces mode discovery and long-range transport to short-range refinement, enabling accurate single Euler-step inference while achieving SOTA Soft mAP (0.4804) and mAP (0.4703) on the Waymo Open Motion Dataset at 75 FPS.
Significance. If the central claims hold, the work would be significant for safety-critical autonomy by delivering multimodal predictions with bounded latency, addressing a key limitation of diffusion-based methods. The emphasis on stable training targets via straight-line anchoring and the commitment to release code and models are positive contributions to reproducibility.
major comments (2)
- [Abstract] Abstract and method description: The claim that single-step integration suffices because 'the underlying transport problem is local' depends on the step-consistent displacement field (trained under straight-line interpolation between learned priors) remaining accurate when actual trajectories are curved. No theoretical bound or ablation isolating curvature-induced error is provided, which is load-bearing for the locality guarantee and the assertion that this avoids high-variance bootstrap signals.
- [Method] The self-consistency mechanism: It is unclear from the high-level description whether the semigroup property is enforced via an explicit loss on the vector field or emerges implicitly from the straight-line targets; without equations detailing the training objective or how the field is conditioned on the anchors, it is difficult to verify that the single step inherits multi-step accuracy rather than simply fitting the prior.
minor comments (2)
- The abstract reports ensemble results at 75 FPS but does not specify whether the primary metrics are from the single model or the ensemble, nor the value of K used in the reported experiments.
- Notation for the learned prior, anchor calibration, and the exact form of the displacement field could be introduced with consistent symbols earlier in the text to improve readability.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's potential significance for safety-critical autonomy and for the constructive feedback. We address each major comment below with clarifications and commitments to revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and method description: The claim that single-step integration suffices because 'the underlying transport problem is local' depends on the step-consistent displacement field (trained under straight-line interpolation between learned priors) remaining accurate when actual trajectories are curved. No theoretical bound or ablation isolating curvature-induced error is provided, which is load-bearing for the locality guarantee and the assertion that this avoids high-variance bootstrap signals.
Authors: We agree that a theoretical bound on curvature-induced discretization error would strengthen the locality argument. The current manuscript supports the claim empirically via SOTA results on the Waymo Open Motion Dataset, which contains diverse curved trajectories, and by design: the learned anchors place the base distribution near plausible futures, converting long-range transport into local refinement. Straight-line interpolation between anchors and ground truth further yields low-variance targets by construction. To isolate curvature effects as requested, we will add an ablation in the revised manuscript that bins test trajectories by average curvature and reports Soft mAP and mAP per bin. This will provide direct empirical evidence on whether single-step accuracy holds across curvature levels. revision: partial
-
Referee: [Method] The self-consistency mechanism: It is unclear from the high-level description whether the semigroup property is enforced via an explicit loss on the vector field or emerges implicitly from the straight-line targets; without equations detailing the training objective or how the field is conditioned on the anchors, it is difficult to verify that the single step inherits multi-step accuracy rather than simply fitting the prior.
Authors: We apologize for the insufficient detail in the high-level description. The semigroup property is enforced implicitly: the conditional flow matching objective trains the displacement field exclusively on straight-line paths from the scene-conditioned anchor priors to ground-truth trajectories. Because the learned vector field is consistent along these paths, a single Euler step approximates the full integration. The field is conditioned on both scene context and the K anchor trajectories. We will revise the method section to include the full training objective equations, the precise conditioning formulation, and an illustrative figure of the anchored straight-line transport. This will demonstrate that single-step inference inherits multi-step accuracy from the path-consistent training rather than merely regressing to the prior. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper's core derivation rests on the locality principle for transport problems: conditioning the base distribution near plausible futures (via learned priors) reduces the task to short-range refinement where one Euler step is accurate. The step-consistent displacement field is trained against a stable target constructed from straight-line interpolations of those priors; this is an explicit training objective, not a redefinition of the output as the input. No equation or claim reduces the single-step prediction to a fitted quantity by construction, nor does any load-bearing premise collapse to a self-citation chain or ansatz smuggled from prior author work. The semigroup self-consistency is enforced as an auxiliary loss rather than assumed, and the final claims are validated on held-out Waymo data rather than derived tautologically from the training targets.
Axiom & Free-Parameter Ledger
free parameters (1)
- K
axioms (1)
- domain assumption Single Euler step suffices for short-range refinement when the base distribution is conditioned near plausible futures
invented entities (2)
-
local transport conditioning
no independent evidence
-
step-consistent displacement field
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840– 6851, 2020
2020
-
[2]
Denoising diffusion bridge models.arXiv preprint arXiv:2309.16948, 2023
L. Zhou, A. Lou, S. Khanna, and S. Ermon, “Denoising diffusion bridge models,”arXiv preprint arXiv:2309.16948, 2023
-
[3]
Flow Matching for Generative Modeling
Y . Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le, “Flow matching for generative modeling,”arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review arXiv 2022
-
[4]
Motiondiffuser: Controllable multi-agent motion prediction using diffusion,
C. Jiang, A. Cornman, C. Park, B. Sapp, Y . Zhou, D. Anguelov et al., “Motiondiffuser: Controllable multi-agent motion prediction using diffusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 9644–9653
2023
-
[5]
Scenario dreamer: Vectorized latent diffusion for generating driving simulation environments,
L. Rowe, R. Girgis, A. Gosselin, L. Paull, C. Pal, and F. Heide, “Scenario dreamer: Vectorized latent diffusion for generating driving simulation environments,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 17 207–17 218
2025
-
[6]
Leapfrog diffu- sion model for stochastic trajectory prediction,
W. Mao, C. Xu, Q. Zhu, S. Chen, and Y . Wang, “Leapfrog diffu- sion model for stochastic trajectory prediction,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 5517–5526
2023
-
[7]
Stochastic trajectory prediction via motion indeterminacy diffusion,
T. Gu, G. Chen, J. Li, C. Lin, Y . Rao, J. Zhou, and J. Lu, “Stochastic trajectory prediction via motion indeterminacy diffusion,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 17 113–17 122
2022
-
[8]
Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,
B. Liao, S. Chen, H. Yin, B. Jiang, C. Wang, S. Yan, X. Zhang, X. Li, Y . Zhang, Q. Zhanget al., “Diffusiondrive: Truncated diffusion model for end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 12 037–12 047
2025
-
[9]
Bridgedrive: Diffusion bridge policy for closed-loop trajectory planning in autonomous driving,
S. Liu, W. Chen, W. Li, Z. Wang, L. Yang, J. Huang, Y . Zhang, Z. Huang, Z. Cheng, and H. Yang, “Bridgedrive: Diffusion bridge policy for closed-loop trajectory planning in autonomous driving,”arXiv preprint arXiv:2509.23589, 2025
-
[10]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
X. Liu, C. Gong, and Q. Liu, “Flow straight and fast: Learning to generate and transfer data with rectified flow,”arXiv preprint arXiv:2209.03003, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
Improving and generalizing flow-based generative models with minibatch optimal transport
A. Tong, N. Malkin, G. Huguet, Y . Zhang, J. Rector-Brooks, K. Fatras, G. Wolf, and Y . Bengio, “Conditional flow matching: Simulation-free dynamic optimal transport,”arXiv preprint arXiv:2302.00482, vol. 2, no. 3, 2023
work page internal anchor Pith review arXiv 2023
-
[12]
Trajflow: Multi-modal motion prediction via flow matching,
Q. Yan, B. Zhang, Y . Zhang, D. Yang, J. White, D. Chen, J. Liu, L. Liu, B. Zhuang, S. Shiet al., “Trajflow: Multi-modal motion prediction via flow matching,”arXiv preprint arXiv:2506.08541, 2025
-
[13]
Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,
Z. Xing, X. Zhang, Y . Hu, B. Jiang, T. He, Q. Zhang, X. Long, and W. Yin, “Goalflow: Goal-driven flow matching for multimodal trajec- tories generation in end-to-end autonomous driving,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1602–1611
2025
-
[14]
Motion transformer with global intention localization and local movement refinement,
S. Shi, L. Jiang, D. Dai, and B. Schiele, “Motion transformer with global intention localization and local movement refinement,”Advances in Neural Information Processing Systems, vol. 35, pp. 6531–6543, 2022
2022
-
[15]
Mtr++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying,
——, “Mtr++: Multi-agent motion prediction with symmetric scene modeling and guided intention querying,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 3955–3971, 2024
2024
-
[16]
N. Nayakanti, R. Al-Rfou, A. Zhou, K. Goel, K. S. Refaat, and B. Sapp, “Wayformer: Motion forecasting via simple & efficient attention net- works,”arXiv preprint arXiv:2207.05844, 2022
-
[17]
Query-centric trajectory prediction,
Z. Zhou, J. Wang, Y .-H. Li, and Y .-K. Huang, “Query-centric trajectory prediction,” inCVPR, 2023, pp. 17 863–17 873
2023
-
[18]
Motionlm: Multi-agent motion forecasting as language modeling,
A. Seff, B. Cera, D. Chen, M. Ng, A. Zhou, N. Nayakanti, K. S. Refaat, R. Al-Rfou, and B. Sapp, “Motionlm: Multi-agent motion forecasting as language modeling,” inProceedings of the IEEE/CVF ICCV, 2023, pp. 8579–8590
2023
-
[19]
Smart: Scalable multi-agent real- time motion generation via next-token prediction,
W. Wu, X. Feng, Z. Gao, and Y . Kan, “Smart: Scalable multi-agent real- time motion generation via next-token prediction,”Advances in Neural Information Processing Systems, vol. 37, pp. 114 048–114 071, 2024
2024
-
[20]
Flowdrive: moderated flow matching with data balancing for trajectory planning,
L. Wang, ¨O. S ¸. Tas ¸, M. Steiner, and C. Stiller, “Flowdrive: moderated flow matching with data balancing for trajectory planning,”arXiv preprint arXiv:2509.21961, 2025
-
[21]
One step diffusion via shortcut models.arXiv preprint arXiv:2410.12557, 2024
K. Frans, D. Hafner, S. Levine, and P. Abbeel, “One step diffusion via shortcut models,”arXiv preprint arXiv:2410.12557, 2024
-
[22]
Flowdrive: Energy flow field for end-to-end autonomous driving,
H. Jiang, Z. Zhang, Y . Gao, Z. Sun, Y . Wang, Y . Heng, S. Wang, J. Chai, Z. Chen, H. Zhaoet al., “Flowdrive: Energy flow field for end-to-end autonomous driving,”arXiv preprint arXiv:2509.14303, 2025
-
[23]
Film: Visual reasoning with a general conditioning layer,
E. Perez, F. Strub, H. De Vries, V . Dumoulin, and A. Courville, “Film: Visual reasoning with a general conditioning layer,” inAAAI, vol. 32, no. 1, 2018
2018
-
[24]
arXiv preprint arXiv:2407.02398 , year=
L. Yang, Z. Zhang, Z. Zhang, X. Liu, M. Xu, W. Zhang, C. Meng, S. Er- mon, and B. Cui, “Consistency flow matching: Defining straight flows with velocity consistency,”arXiv preprint arXiv:2407.02398, 2024
-
[25]
Rmp-yolo: A robust motion predictor for partially observable scenarios even if you only look once,
J. Sun, J. Li, T. Liu, C. Yuan, S. Sun, Z. Huang, A. Wong, K. P. Tee, and M. H. Ang, “Rmp-yolo: A robust motion predictor for partially observable scenarios even if you only look once,” in2025 IEEE ICRA. IEEE, 2025, pp. 1024–1031
2025
-
[26]
Modeseq: Taming sparse multimodal motion prediction with sequential mode modeling,
Z. Zhou, H. Zhou, H. Hu, Z. Wen, J. Wang, Y .-H. Li, and Y .-K. Huang, “Modeseq: Taming sparse multimodal motion prediction with sequential mode modeling,” inProceedings of the Computer Vision and Pattern Recognition Conference, 2025, pp. 1612–1621
2025
-
[27]
Reasoning multi-agent behavioral topology for interactive autonomous driving,
H. Liu, L. Chen, Y . Qiao, C. Lv, and H. Li, “Reasoning multi-agent behavioral topology for interactive autonomous driving,”Advances in Neural Information Processing Systems, vol. 37, pp. 92 605–92 637, 2024
2024
-
[28]
Multi-granular transformer for motion prediction with lidar,
Y . Gan, H. Xiao, Y . Zhao, E. Zhang, Z. Huang, X. Ye, and L. Ge, “Multi-granular transformer for motion prediction with lidar,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 15 092–15 098
2024
-
[29]
Eda: Evolving and distinct anchors for multimodal motion prediction,
L. Lin, X. Lin, T. Lin, L. Huang, R. Xiong, and Y . Wang, “Eda: Evolving and distinct anchors for multimodal motion prediction,” inProceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 4, 2024, pp. 3432–3440
2024
-
[30]
Real-time motion prediction via heterogeneous polyline transformer with relative pose encoding,
Z. Zhang, A. Liniger, C. Sakaridis, F. Yu, and L. V . Gool, “Real-time motion prediction via heterogeneous polyline transformer with relative pose encoding,”Advances in Neural Information Processing Systems, vol. 36, pp. 57 481–57 499, 2023
2023
-
[31]
Hdgt: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding,
X. Jia, P. Wu, L. Chen, Y . Liu, H. Li, and J. Yan, “Hdgt: Heterogeneous driving graph transformer for multi-agent trajectory prediction via scene encoding,”IEEE transactions on pattern analysis and machine intelli- gence, vol. 45, no. 11, pp. 13 860–13 875, 2023
2023
-
[32]
Impact: Behavioral intention-aware multimodal trajectory prediction with adaptive context trimming,
J. Sun, X. Yue, J. Li, T. Shen, C. Yuan, S. Sun, S. Guo, Q. Zhou, and M. H. Ang Jr, “Impact: Behavioral intention-aware multimodal trajectory prediction with adaptive context trimming,”arXiv preprint arXiv:2504.09103, 2025
-
[33]
Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,
S. Ettinger, S. Cheng, B. Caine, C. Liu, H. Zhao, S. Pradhan, Y . Chai, B. Sapp, C. R. Qi, Y . Zhouet al., “Large scale interactive motion forecasting for autonomous driving: The waymo open motion dataset,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 9710–9719
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.