Recognition: unknown
ImproBR: Bug Report Improver Using LLMs
Pith reviewed 2026-05-07 15:40 UTC · model grok-4.3
The pith
An LLM pipeline can automatically complete missing steps and behaviors in bug reports, raising structural completeness from 7.9 percent to 96.4 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
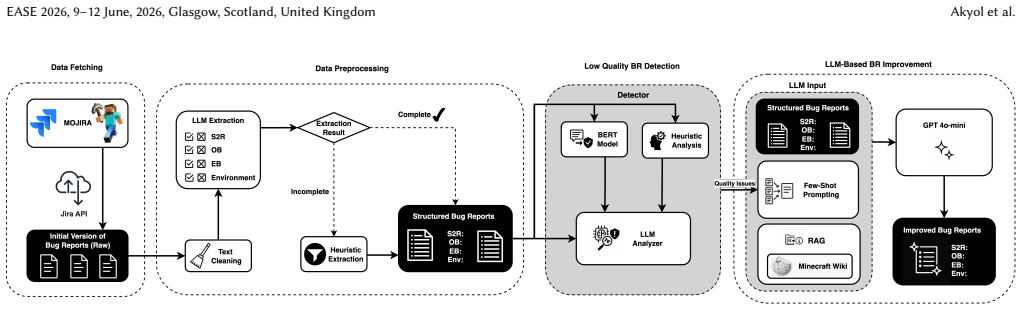
ImproBR is an LLM-based pipeline that combines a fine-tuned DistilBERT detector, heuristic checks, and GPT-4o mini guided by section-specific few-shot prompts plus retrieval-augmented generation from Minecraft wiki knowledge. The pipeline identifies and repairs missing, incomplete, or ambiguous S2R, OB, and EB sections. On 139 challenging real-world Mojira reports, it raised structural completeness from 7.9 percent to 96.4 percent, more than doubled the share of executable steps to reproduce from 28.8 percent to 67.6 percent, and increased the count of fully reproducible reports from 1 to 13.
What carries the argument
The hybrid detector plus section-specific LLM completion pipeline with RAG, which locates deficient S2R, OB, and EB sections and generates targeted improvements.
If this is right
- Bug reports reach over 96 percent structural completeness after processing.
- The proportion of executable steps to reproduce more than doubles.
- The number of fully reproducible reports rises substantially in a fixed sample of real issues.
- A hybrid mix of fine-tuned models, heuristics, and prompted LLMs can locate and repair the main deficiencies in bug reports.
Where Pith is reading between the lines
- Bug tracking systems could run the improver at submission time so low-quality reports never reach developers.
- The same pattern could apply to other domains if each project supplies its own domain knowledge base for the retrieval step.
- Teams would still need a review step to catch any cases where the model altered the reporter's meaning.
Load-bearing premise
The LLM-generated text accurately reflects the original reporter's intent without introducing errors or hallucinations.
What would settle it
A blinded study in which independent developers attempt to reproduce the reported bugs using the original reports versus the improved reports and record their actual success rates.
Figures

read the original abstract
Bug tracking systems play a crucial role in software maintenance, yet developers frequently struggle with low-quality user-submitted reports that omit essential details such as Steps to Reproduce (S2R), Observed Behavior (OB), and Expected Behavior (EB). We propose ImproBR, an LLM-based pipeline that automatically detects and improves bug reports by addressing missing, incomplete, and ambiguous S2R, OB, and EB sections. ImproBR employs a hybrid detector combining fine-tuned DistilBERT, heuristic analysis, and an LLM analyzer, guided by GPT-4o mini with section-specific few-shot prompts and a Retrieval-Augmented Generation (RAG) pipeline grounded in Minecraft Wiki domain knowledge. Evaluated on Mojira, ImproBR improved structural completeness from 7.9% to 96.4%, more than doubled the proportion of executable S2R from 28.8% to 67.6%, and raised fully reproducible bug reports from 1 to 13 across 139 challenging real-world reports.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents ImproBR, an LLM-based pipeline (centered on GPT-4o mini with few-shot prompts and RAG over Minecraft Wiki) that first detects missing/incomplete/ambiguous S2R, OB, and EB sections via a hybrid classifier (fine-tuned DistilBERT + heuristics + LLM analyzer) and then completes them. On a set of 139 challenging real-world Mojira reports, the system is reported to raise structural completeness from 7.9% to 96.4%, executable S2R from 28.8% to 67.6%, and fully reproducible reports from 1 to 13.
Significance. If the reported gains in executability and reproducibility are shown to preserve original reporter intent without introducing hallucinations, the work would offer a practical, domain-grounded approach to a persistent software-engineering pain point. The hybrid detection stage and RAG grounding are concrete strengths that distinguish it from pure LLM prompting.
major comments (3)
- [Evaluation] Evaluation section (and associated tables/figures): the metrics for 'executable S2R' and 'fully reproducible' reports are load-bearing for the central claim, yet the manuscript provides no description of the judgment protocol (human vs. LLM evaluators, blinding to original vs. improved versions, inter-rater reliability, or how intent fidelity was verified against the reporter's original meaning). Without these details the large reported deltas (28.8% -> 67.6% executable; 1 -> 13 reproducible) cannot be confidently attributed to faithful completion rather than plausible fabrication.
- [Section 3] Section 3 (RAG and prompt design): the RAG corpus is limited to Minecraft Wiki; the paper does not discuss how this grounding interacts with bug-specific context that may lie outside the wiki (e.g., version-specific behavior or user-environment details), raising the risk that completions are wiki-plausible but not faithful to the original report.
- [Evaluation] Abstract and Evaluation: the hybrid detector is presented as a key innovation, but no ablation is reported that isolates its contribution from the subsequent LLM completion stage; thus it is unclear whether the detection accuracy is actually necessary for the observed end-to-end gains.
minor comments (2)
- [Appendix] The manuscript should include the exact prompt templates and the DistilBERT fine-tuning hyperparameters in an appendix or replication package to support reproducibility.
- [Results] Figure captions and axis labels in the results section would benefit from explicit definitions of 'structural completeness' and 'executable S2R' to avoid reader ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the recognition of the hybrid detector and RAG grounding as distinguishing strengths. We address each major comment below, indicating where revisions will be made to the manuscript.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and associated tables/figures): the metrics for 'executable S2R' and 'fully reproducible' reports are load-bearing for the central claim, yet the manuscript provides no description of the judgment protocol (human vs. LLM evaluators, blinding to original vs. improved versions, inter-rater reliability, or how intent fidelity was verified against the reporter's original meaning). Without these details the large reported deltas (28.8% -> 67.6% executable; 1 -> 13 reproducible) cannot be confidently attributed to faithful completion rather than plausible fabrication.
Authors: We agree that the evaluation protocol requires explicit documentation to support the reported gains. The original manuscript did not provide a dedicated description of how executability and reproducibility were judged. In the revised manuscript we will add a new subsection in the Evaluation section that details the protocol: assessments were performed by two human evaluators experienced in software engineering and bug reporting; evaluators were blinded to whether each report was original or improved; inter-rater reliability was measured via Cohen's kappa; and intent fidelity was enforced by requiring evaluators to cross-reference every added detail against the original report text, marking any ungrounded addition as invalid. We will report the resulting kappa value and disagreement-resolution procedure. These additions will allow readers to assess whether the observed improvements reflect faithful completion. revision: yes
-
Referee: [Section 3] Section 3 (RAG and prompt design): the RAG corpus is limited to Minecraft Wiki; the paper does not discuss how this grounding interacts with bug-specific context that may lie outside the wiki (e.g., version-specific behavior or user-environment details), raising the risk that completions are wiki-plausible but not faithful to the original report.
Authors: We acknowledge the limitation of grounding RAG exclusively in the Minecraft Wiki. The system prompts always prepend the full original report text, so version and environment details supplied by the reporter remain available to the LLM. In the revision we will expand Section 3 to explicitly describe this interaction, noting that RAG supplies general domain knowledge while the original report supplies instance-specific constraints. We will also add a limitations paragraph acknowledging the risk of wiki-plausible yet report-inconsistent completions and state that the LLM is instructed to prioritize information present in the original report when conflicts arise. revision: yes
-
Referee: [Evaluation] Abstract and Evaluation: the hybrid detector is presented as a key innovation, but no ablation is reported that isolates its contribution from the subsequent LLM completion stage; thus it is unclear whether the detection accuracy is actually necessary for the observed end-to-end gains.
Authors: We agree that an ablation isolating the hybrid detector would strengthen the claim of its necessity. The current manuscript reports only end-to-end results. In the revised Evaluation section we will add an ablation study that compares the full ImproBR pipeline against a variant that bypasses the hybrid detector and applies the LLM completion stage directly to every input report. We will present the resulting metrics for structural completeness, executable S2R, and fully reproducible reports, thereby quantifying the detector's contribution to the observed gains. revision: yes
Circularity Check
No circularity: empirical evaluation on external reports with independent metrics
full rationale
The paper proposes an LLM pipeline (hybrid detector + GPT-4o mini + RAG on Minecraft Wiki) and evaluates it on 139 real-world Mojira bug reports using explicitly defined metrics for structural completeness, executable S2R proportion, and full reproducibility. No equations, derivations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the abstract or described content. Results are measured outcomes on held-out external data rather than reductions to inputs by construction, making the evaluation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs guided by few-shot prompts and domain RAG can produce accurate and useful completions for bug report sections.
Reference graph
Works this paper leans on
- [1]
-
[2]
Andrea Arcuri and Lionel C. Briand. 2011. A Practical Guide for Using Statistical Tests to Assess Randomized Algorithms in Software Engineering. InProceedings of the 33rd International Conference on Software Engineering (ICSE 2011). ACM, New York, NY, USA, 1–10. doi:10.1145/1985793.1985795
-
[3]
Atlassian. 2024. Jira Software. https://www.atlassian.com/software/jira. Accessed: 2025-05-14
2024
-
[4]
Nicolas Bettenburg, Sascha Just, Adrian Schröter, Cathrin Weiss, Rahul Premraj, and Thomas Zimmermann. 2008. What makes a good bug report?. InProceedings of the 16th ACM SIGSOFT International Symposium on Foundations of Software Engineering(Atlanta, Georgia)(SIGSOFT ’08/FSE-16). Association for Computing Machinery, New York, NY, USA, 308–318. doi:10.1145/...
-
[5]
Lili Bo, Wangjie Ji, Xiaobing Sun, Ting Zhang, Xiaoxue Wu, and Ying Wei. 2024. ChatBR: Automated assessment and improvement of bug report quality using ChatGPT. InProceedings of the 39th IEEE/ACM International Conference on Auto- mated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New York, NY, USA, 1472–1483. do...
-
[6]
Oscar Chaparro, Carlos Bernal-Cárdenas, Jing Lu, Kevin Moran, Andrian Marcus, Massimiliano Di Penta, Denys Poshyvanyk, and Vincent Ng. 2019. Assessing the quality of the steps to reproduce in bug reports. InProceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering(Ta...
-
[7]
Oscar Chaparro, Jing Lu, Fiorella Zampetti, Laura Moreno, Massimiliano Di Penta, Andrian Marcus, Gabriele Bavota, and Vincent Ng. 2017. Detecting missing information in bug descriptions. InProceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering(Paderborn, Germany)(ESEC/FSE 2017). Association for Computing Machinery, New York, NY,...
-
[8]
Harrison Chase. 2023. LangChain: Building applications with LLMs through composability. https://github.com/hwchase17/langchain
2023
-
[9]
Chroma. 2023. Chroma: the open-source embedding database. https://github. com/chroma-core/chroma
2023
-
[10]
Explosion. 2020. English spaCy Models - en_core_web_sm. https://spacy.io/ models/en
2020
-
[11]
2023.DistilBERT
Hugging Face. 2023.DistilBERT. https://huggingface.co/docs/transformers/ model_doc/distilbert
2023
- [12]
-
[13]
GitHub, Inc. 2024. GitHub: Where the world builds software. https://github.com. Accessed: 2025-05-14
2024
-
[14]
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, and Adriane Boyd. 2020. spaCy: Industrial-strength Natural Language Processing in Python. doi:10.5281/ zenodo.1212303
2020
-
[15]
J. Richard Landis and Gary G. Koch. 1977. The Measurement of Observer Agreement for Categorical Data.Biometrics33, 1 (1977), 159–174. http: //www.jstor.org/stable/2529310
-
[16]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks.Advances in Neural Information Processing Systems33 (2020), 9459–9474
2020
-
[17]
Junayed Mahmud, Antu Saha, Oscar Chaparro, Kevin Moran, and Andrian Marcus
-
[18]
arXiv:2502.04251 [cs.SE] https://arxiv.org/abs/2502
Combining Language and App UI Analysis for the Automated Assessment of Bug Reproduction Steps. arXiv:2502.04251 [cs.SE] https://arxiv.org/abs/2502. 04251
-
[19]
Microsoft Azure. 2023. Azure OpenAI Service Documentation. https://learn. microsoft.com/en-us/azure/cognitive-services/openai/ (Accessed: 2025-05-15)
2023
-
[20]
Tomás Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. 2013. Efficient Estimation of Word Representations in Vector Space. InWorkshop Track Proceed- ings of the 1st International Conference on Learning Representations (ICLR 2013). arXiv:arXiv:1301.3781 http://arxiv.org/abs/1301.3781 Poster
work page internal anchor Pith review arXiv 2013
-
[21]
Mojang Studios. 2025. Mojira – The Official Mojang Bug Tracker. https://bugs. mojang.com/ Accessed: March 21, 2025
2025
-
[22]
Kevin Moran, Mario Linares-Vásquez, Carlos Bernal-Cárdenas, and Denys Poshy- vanyk. 2015. Auto-completing bug reports for Android applications. InPro- ceedings of the 2015 10th Joint Meeting on Foundations of Software Engineering (Bergamo, Italy)(ESEC/FSE 2015). Association for Computing Machinery, New York, NY, USA, 673–686. doi:10.1145/2786805.2786857
-
[23]
Arvind Neelakantan, Tao Xu, Raul Puri, Alec Radford, Jesse Michael Han, Jerry Tworek, Qiming Yuan, Nikolas Tezak, Jong Wook Kim, Chris Hallacy, Johannes Heidecke, Pranav Shyam, Boris Power, Tyna Eloundou Nekoul, Girish Sastry, Gretchen Krueger, David Schnurr, Felipe Petroski Such, Kenny Hsu, Madeleine Thompson, Tabarak Khan, Toki Sherbakov, Joanne Jang, P...
-
[24]
OpenAI. 2023. GPT-4o Fine-Tuning. https://openai.com/index/gpt-4o-fine- tuning/ Accessed: March 21, 2025
2023
-
[25]
Khushbakht Ali Qamar, Emre Sülün, and Eray Tüzün. 2021. Towards a Taxonomy of Bug Tracking Process Smells: A Quantitative Analysis. In2021 47th Euromicro Conference on Software Engineering and Advanced Applications (SEAA). 138–147. doi:10.1109/SEAA53835.2021.00026
-
[26]
Khushbakht Ali Qamar, Emre Sülün, and Eray Tüzün. 2022. Taxonomy of Bug Tracking Process Smells: Perceptions of Practitioners and an Empirical Analysis. Information and Software Technology150 (2022), 106972. doi:10.1016/j.infsof.2022. 106972
-
[27]
Kromrey, Jesse Coraggio, and Jeff Skowronek
Jeanine Romano, Jeffrey D. Kromrey, Jesse Coraggio, and Jeff Skowronek. 2006. Appropriate Statistics for Ordinal Level Data: Should We Really Be Using t-test and Cohen’s d for Evaluating Group Differences on the NSSE and Other Surveys?. InAnnual Meeting of the Florida Association of Institutional Research. 1–3
2006
-
[28]
G Salton, A Wong, and C S Yang. 1975. A vector space model for automatic indexing.Commun. ACM18, 11 (Nov. 1975), 613–620
1975
-
[29]
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. 2019. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter. arXiv:1910.01108 [cs.CL] https://arxiv.org/abs/1910.01108
work page internal anchor Pith review arXiv 2019
-
[30]
Kurt Shuster, Spencer Poff, Moya Chen, Douwe Kiela, and Jason Weston. 2021. Retrieval Augmentation Reduces Hallucination in Conversation. InFindings of the Association for Computational Linguistics: EMNLP 2021. 3784–3798
2021
-
[31]
Mozhan Soltani, Felienne Hermans, and Thomas Bäck. 2020. The significance of bug report elements.Empirical Software Engineering25, 6 (Nov. 2020), 5255–5294. doi:10.1007/s10664-020-09882-z
-
[32]
Yang Song and Oscar Chaparro. 2020. BEE: a tool for structuring and analyzing bug reports. InProceedings of the 28th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering (Virtual Event, USA)(ESEC/FSE 2020). Association for Computing Machinery, New York, NY, USA, 1551–1555. doi:10.1145/33680...
-
[33]
Yang Song, Junayed Mahmud, Nadeeshan De Silva, Ying Zhou, Oscar Chaparro, Kevin Moran, Andrian Marcus, and Denys Poshyvanyk. 2023. Burt: A Chatbot for Interactive Bug Reporting. InProceedings of the 45th International Conference on Software Engineering: Companion Proceedings(Melbourne, Victoria, Australia) (ICSE ’23). IEEE Press, 170–174. doi:10.1109/ICSE...
-
[34]
Erdem Tuna, Vladimir Kovalenko, and Eray Tüzün. 2022. Bug tracking process smells in practice. InProceedings of the 44th International Conference on Software Engineering: Software Engineering in Practice(Pittsburgh, Pennsylvania)(ICSE- SEIP ’22). Association for Computing Machinery, New York, NY, USA, 77–86. doi:10.1145/3510457.3513080
-
[35]
Bureau of Labor Statistics
U.S. Bureau of Labor Statistics. 2025. Employer Costs for Employee Compensation – March 2025. News Release USDL-25-0958. https://www.bls.gov/news.release/ ecec.htm
2025
-
[36]
Dingbang Wang, Yu Zhao, Sidong Feng, Zhaoxu Zhang, William G. J. Halfond, Chunyang Chen, Xiaoxia Sun, Jiangfan Shi, and Tingting Yu. 2024. Feedback- Driven Automated Whole Bug Report Reproduction for Android Apps. InProceed- ings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis(Vienna, Austria)(ISSTA 2024). Association for ...
-
[37]
Wenhui Wang, Furu Wei, Li Dong, Hangbo Bao, Nan Yang, and Ming Zhou
- [38]
-
[39]
Eray Yapağcı, Yavuz Öztürk, and Eray Tüzün. 2025. Agents in the Sandbox: End- to-End Crash Bug Reproduction for Minecraft. InProceedings of ASE. 3095–3107. doi:10.1109/ASE63991.2025.00254
-
[40]
Tao Zhang, Jiachi Chen, He Jiang, Xiapu Luo, and Xin Xia. 2017. Bug Report Enrichment with Application of Automated Fixer Recommendation. In2017 IEEE/ACM 25th International Conference on Program Comprehension (ICPC). 230–
2017
-
[41]
doi:10.1109/ICPC.2017.28
-
[42]
Zhaoxu Zhang, Robert Winn, Yu Zhao, Tingting Yu, and William G.J. Halfond
-
[43]
Automatically Reproducing Android Bug Reports using Natural Language Processing and Reinforcement Learning. InProceedings of the 32nd ACM SIGSOFT International Symposium on Software Testing and Analysis(Seattle, WA, USA) EASE 2026, 9–12 June, 2026, Glasgow, Scotland, United Kingdom Akyol et al. (ISSTA 2023). Association for Computing Machinery, New York, ...
-
[44]
Thomas Zimmermann, Rahul Premraj, Nicolas Bettenburg, Sascha Just, Adrian Schroter, and Cathrin Weiss. 2010. What Makes a Good Bug Report?IEEE Trans. Softw. Eng.36, 5 (Sept. 2010), 618–643. doi:10.1109/TSE.2010.63
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.