Recognition: unknown
CacheRAG: A Semantic Caching System for Retrieval-Augmented Generation in Knowledge Graph Question Answering
Pith reviewed 2026-05-07 13:44 UTC · model grok-4.3
The pith
CacheRAG adds semantic caching to turn stateless LLM planners for knowledge graph questions into continual learners.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CacheRAG is a cache-augmented architecture for LLM-based KGQA that converts stateless planners into continual learners through a schema-agnostic ISR interface for natural-language interaction, a two-layer hierarchical index paired with MMR for diverse cached example retrieval, and deterministic bounded subgraph operators for safe recall improvement, yielding measurable gains in accuracy and truthfulness over baselines on standard benchmarks.
What carries the argument
The three design principles of schema-agnostic ISR interface, MMR-based diversity retrieval on Domain-to-Aspect index, and bounded heuristic subgraph expansion.
If this is right
- Higher accuracy on knowledge graph question answering tasks.
- Greater truthfulness in answers produced by the language model.
- Fewer schema hallucinations during query planning.
- Broader retrieval coverage achieved within strict computational bounds.
- Safer translation of natural language questions into executable graph queries.
Where Pith is reading between the lines
- The same caching pattern could extend to other retrieval-augmented generation settings to accumulate experience across sessions.
- Diversity-focused retrieval may prove more useful than frequency-based methods when the goal is varied reasoning rather than simple repetition.
- Systems built this way could handle gradual schema evolution in knowledge graphs without requiring complete resets.
- Integration with existing database-style optimizers might further reduce the cost of initial plan generation.
Load-bearing premise
The three design principles can be put into practice without creating new failure modes or requiring extensive manual tuning of cache policies.
What would settle it
A benchmark run dominated by queries with low similarity to any cached examples, verifying whether accuracy and truthfulness fall back to non-cached baseline levels.
Figures





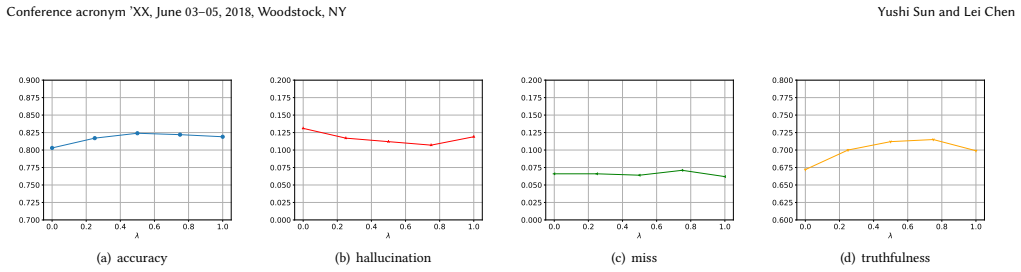

read the original abstract
The integration of Large Language Models (LLMs) with Retrieval-Augmented Generation (RAG) has significantly advanced Knowledge Graph Question Answering (KGQA). However, existing LLM-driven KGQA systems act as stateless planners, generating retrieval plans in isolation without exploiting historical query patterns: analogous to a database system that optimizes every query from scratch without a plan cache. This fundamental design flaw leads to schema hallucinations and limited retrieval coverage. We propose CacheRAG, a systematic cache-augmented architecture for LLM-based KGQA that transforms stateless planners into continual learners. Unlike traditional database plan caching (which optimizes for frequency), CacheRAG introduces three novel design principles tailored for LLM contexts: (1) Schema-agnostic user interface: A two-stage semantic parsing framework via Intermediate Semantic Representation (ISR) enables non-expert users to interact purely in natural language, while a Backend Adapter grounds the LLM with local schema context to compile executable physical queries safely. (2) Diversity-optimized cache retrieval: A two-layer hierarchical index (Domain $\rightarrow$ Aspect) coupled with Maximal Marginal Relevance (MMR) maximizes structural variety in cached examples, effectively mitigating reasoning homogeneity. (3) Bounded heuristic expansion: Deterministic depth and breadth subgraph operators with strict complexity guarantees significantly enhance retrieval recall without risking unbounded API execution. Extensive experiments on multiple benchmarks demonstrate that CacheRAG significantly outperforms state-of-the-art baselines (e.g., +13.2% accuracy and +17.5% truthfulness on the CRAG dataset).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CacheRAG, a semantic caching architecture for LLM-based Knowledge Graph Question Answering (KGQA) that converts stateless planners into continual learners. It introduces three design principles: (1) a schema-agnostic two-stage semantic parsing framework using an Intermediate Semantic Representation (ISR) with a Backend Adapter for safe query compilation, (2) a two-layer hierarchical index (Domain → Aspect) combined with Maximal Marginal Relevance (MMR) for diversity-optimized cache retrieval, and (3) bounded heuristic expansion using deterministic depth and breadth subgraph operators with complexity guarantees. The central claim is that this system significantly outperforms state-of-the-art baselines, with reported gains of +13.2% accuracy and +17.5% truthfulness on the CRAG dataset across multiple benchmarks.
Significance. If the performance claims are substantiated by rigorous experiments, CacheRAG could meaningfully advance KGQA systems by adapting database-style plan caching to LLM contexts, addressing schema hallucinations and limited coverage through reuse of historical patterns. The emphasis on schema-agnostic interfaces and bounded operations is a practical strength for deployment, and the work bridges database caching concepts with semantic retrieval in a novel way.
major comments (1)
- §5 (or equivalent Experiments section): The abstract reports specific quantitative gains (+13.2% accuracy, +17.5% truthfulness on CRAG) but provides no description of the experimental protocol, baseline implementations, statistical significance tests, error analysis, or ablation studies. This absence is load-bearing for the central outperformance claim, as the gains cannot be verified or reproduced from the given information.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive feedback on our manuscript. We address the major comment below and commit to a substantial revision of the experimental section to ensure full transparency, reproducibility, and substantiation of our claims.
read point-by-point responses
-
Referee: [—] §5 (or equivalent Experiments section): The abstract reports specific quantitative gains (+13.2% accuracy, +17.5% truthfulness on CRAG) but provides no description of the experimental protocol, baseline implementations, statistical significance tests, error analysis, or ablation studies. This absence is load-bearing for the central outperformance claim, as the gains cannot be verified or reproduced from the given information.
Authors: We agree that the current description of the experimental protocol is insufficient to support the central performance claims. In the revised manuscript, we will substantially expand Section 5 (Experiments) to include: (1) a complete experimental protocol detailing datasets, evaluation metrics, hardware, and LLM configurations; (2) explicit descriptions of baseline implementations, including any adaptations made to ensure fair comparison; (3) statistical significance testing (e.g., paired t-tests or bootstrap methods with reported p-values and confidence intervals); (4) a dedicated error analysis section breaking down failure cases; and (5) comprehensive ablation studies isolating the contribution of each CacheRAG component (ISR parsing, hierarchical caching with MMR, and bounded expansion). These additions will enable verification and reproduction of the reported +13.2% accuracy and +17.5% truthfulness gains on CRAG and other benchmarks. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper describes a system architecture for CacheRAG with three design principles (schema-agnostic ISR, MMR-based retrieval, bounded heuristic expansion) and reports empirical performance gains on benchmarks such as CRAG. No equations, first-principles derivations, fitted parameters presented as predictions, or self-citation chains appear in the provided text. All central claims reduce to experimental outcomes rather than any definitional or self-referential reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Historical query patterns in KGQA are sufficiently similar to new queries that cached plans improve accuracy without additional verification steps.
invented entities (1)
-
Intermediate Semantic Representation (ISR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Wikidata Query Blazegraph
2022. Wikidata Query Blazegraph. Retrieved Nov 18, 2025 from https://github. com/wikimedia/wikidata-query-blazegraph?tab=readme-ov-file
2022
-
[2]
Shubham Agarwal, Sai Sundaresan, Subrata Mitra, Debabrata Mahapatra, Archit Gupta, Rounak Sharma, Nirmal Joshua Kapu, Tong Yu, and Shiv Saini. 2025. Cache-craft: Managing chunk-caches for efficient retrieval-augmented genera- tion.Proceedings of the ACM on Management of Data3, 3 (2025), 1–28
2025
-
[3]
Manuel Borroto, Francesco Ricca, Bernardo Cuteri, and Vito Barbara. 2022. SPARQL-QA enters the QALD challenge. InProceedings of the 7th Natural Lan- guage Interfaces for the Web of Data (NLIWoD) co-located with the 19th European Semantic Web Conference, Hersonissos, Greece, Vol. 3196. 25–31. https://ceur- ws.org/Vol-3196/paper3.pdf
2022
-
[5]
Zi-Yuan Chen, Chih-Hung Chang, Yi-Pei Chen, Jijnasa Nayak, and Lun-Wei Ku. 2019. UHop: An Unrestricted-Hop Relation Extraction Framework for Knowledge-Based Question Answering. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguis- tics: Human Language Technologies, Volume 1 (Long and Short Papers)...
-
[6]
Rajarshi Das, Manzil Zaheer, Dung Thai, Ameya Godbole, Ethan Perez, Jay-Yoon Lee, Lizhen Tan, Lazaros Polymenakos, and Andrew Mccallum. 2021. Case-based Reasoning for Natural Language Queries over Knowledge Bases. InProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 9594–9611. doi:10.18653/v1/2021.emnlp-main.755
-
[7]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv preprint arXiv:2407.21783(2024). doi:10.48550/arXiv.2407.21783
work page internal anchor Pith review doi:10.48550/arxiv.2407.21783 2024
-
[8]
Wolfgang Fahl, Tim Holzheim, Andrea Westerinen, Christoph Lange, and Stefan Decker. 2022. Getting and hosting your own copy of Wikidata.. InWikidata@ ISWC
2022
-
[9]
Goetz Graefe and William J McKenna. 1993. The volcano optimizer generator: Ex- tensibility and efficient search. InProceedings of IEEE 9th international conference on data engineering. IEEE, 209–218
1993
-
[10]
Yu Gu, Xiang Deng, and Yu Su. 2023. Don’t Generate, Discriminate: A Proposal for Grounding Language Models to Real-World Environments. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 4928–4949. doi:10.18653/v1/2023.acl-long.270
-
[11]
Yu Gu and Yu Su. 2022. ArcaneQA: Dynamic Program Induction and Con- textualized Encoding for Knowledge Base Question Answering. InProceedings of the 29th International Conference on Computational Linguistics. 1718–1731. https://aclanthology.org/2022.coling-1.148/
2022
-
[12]
Xixin Hu, Xuan Wu, Yiheng Shu, and Yuzhong Qu. 2022. Logical form generation via multi-task learning for complex question answering over knowledge bases. InProceedings of the 29th International Conference on Computational Linguistics. 1687–1696. https://aclanthology.org/2022.coling-1.145/
2022
-
[13]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. 2024. Gpt-4o system card.arXiv preprint arXiv:2410.21276(2024). doi:10.48550/arXiv. 2410.21276
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[14]
Jinhao Jiang, Kun Zhou, Zican Dong, Keming Ye, Wayne Xin Zhao, and Ji-Rong Wen. 2023. StructGPT: A General Framework for Large Language Model to Reason over Structured Data. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 9237–9251. doi:10.18653/v1/2023.emnlp-main.574
-
[15]
Chao Jin, Zili Zhang, Xuanlin Jiang, Fangyue Liu, Shufan Liu, Xuanzhe Liu, and Xin Jin. 2025. Ragcache: Efficient knowledge caching for retrieval-augmented generation.ACM Transactions on Computer Systems44, 1 (2025), 1–27
2025
-
[17]
Yunshi Lan and Jing Jiang. 2020. Query Graph Generation for Answering Multi- hop Complex Questions from Knowledge Bases. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 969–974. doi:10.18653/ v1/2020.acl-main.91
2020
-
[18]
Yunshi Lan, Shuohang Wang, and Jing Jiang. 2019. Knowledge base question answering with topic units.(2019). InProceedings of the Twenty-Eighth Interna- tional Joint Conference on Artificial Intelligence. 5046–5052. https://www.ijcai. org/proceedings/2019/0701.pdf
2019
-
[19]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Cheng- gang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. 2024. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review arXiv 2024
-
[20]
Hanwen Liu, Qihan Zhang, Ryan Marcus, and Ibrahim Sabek. 2025. Serag: Self- evolving rag system for query optimization. (2025)
2025
-
[21]
Kangqi Luo, Fengli Lin, Xusheng Luo, and Kenny Zhu. 2018. Knowledge base question answering via encoding of complex query graphs. InProceedings of the 2018 conference on empirical methods in natural language processing. 2185–2194. doi:10.18653/v1/D18-1242
-
[22]
Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, Cehao Yang, Jiaxin Mao, and Jian Guo. 2025. Think-on-Graph 2.0: Deep and Faithful Large Language Model Reasoning with Knowledge-guided Retrieval Augmented Generation. InThe Thirteenth International Conference on Learning Representations. https: //openreview.net/forum?id=oFBu7qaZpS
2025
-
[23]
Barlas Oguz, Xilun Chen, Vladimir Karpukhin, Stan Peshterliev, Dmytro Okhonko, Michael Schlichtkrull, Sonal Gupta, Yashar Mehdad, and Scott Yih. 2022. UniK-QA: Unified Representations of Structured and Unstructured Knowledge for Open- Domain Question Answering. InFindings of the Association for Computational Linguistics: NAACL 2022. 1535–1546. doi:10.1865...
- [24]
-
[25]
Yiheng Shu, Zhiwei Yu, Yuhan Li, Börje Karlsson, Tingting Ma, Yuzhong Qu, and Chin-Yew Lin. 2022. TIARA: Multi-grained Retrieval for Robust Question Answering over Large Knowledge Base. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 8108–8121. doi:10.18653/v1/ 2022.emnlp-main.555
-
[26]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. InThe Twelfth International Conference on Learning Representations. https: //openreview.net/forum?id=nnVO1PvbTv
2024
-
[27]
Alon Talmor and Jonathan Berant. 2018. The Web as a Knowledge-Base for Answering Complex Questions. InProceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), Marilyn Walker, Heng Ji, and Amanda Stent (Eds.). Association for Computational Linguis...
-
[28]
Ricardo Usbeck, Xi Yan, Aleksandr Perevalov, Longquan Jiang, Julius Schulz, Angelie Kraft, Cedric Möller, Junbo Huang, Jan Reineke, Axel-Cyrille Ngonga Ngomo, Muhammad Saleem, and Andreas Both. 2023. QALD-10: The 10th chal- lenge on question answering over linked data.Semantic Web(2023). https: //api.semanticscholar.org/CorpusID:265577096
2023
- [29]
-
[30]
Tianbao Xie, Chen Henry Wu, Peng Shi, Ruiqi Zhong, Torsten Scholak, Michihiro Yasunaga, Chien-Sheng Wu, Ming Zhong, Pengcheng Yin, Sida I Wang, et al. 2022. UnifiedSKG: Unifying and Multi-Tasking Structured Knowledge Grounding with Text-to-Text Language Models. InProceedings of the 2022 Conference on Empirical Methods in Natural Language Processing. 602–6...
-
[31]
Silei Xu, Shicheng Liu, Theo Culhane, Elizaveta Pertseva, Meng-Hsi Wu, Sina Semnani, and Monica Lam. 2023. Fine-tuned LLMs Know More, Hallucinate Less with Few-Shot Sequence-to-Sequence Semantic Parsing over Wikidata. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. 5778–5791. doi:10.18653/v1/2023.emnlp-main.353
-
[32]
Ling Yang, Zhaochen Yu, Tianjun Zhang, Shiyi Cao, Minkai Xu, Wentao Zhang, Joseph E Gonzalez, and Bin Cui. 2024. Buffer of thoughts: Thought-augmented reasoning with large language models.Advances in Neural Information Processing Systems37 (2024), 113519–113544
2024
-
[33]
Xiao Yang, Kai Sun, Hao Xin, Yushi Sun, Nikita Bhalla, Xiangsen Chen, Sajal Choudhary, Rongze Daniel Gui, Ziran Will Jiang, Ziyu Jiang, Lingkun Kong, Brian Moran, Jiaqi Wang, Yifan Ethan Xu, An Yan, Chenyu Yang, Eting Yuan, Hanwen Zha, Nan Tang, Lei Chen, Nicolas Scheffer, Yue Liu, Nirav Shah, Rakesh Wanga, Conference acronym ’XX, June 03–05, 2018, Woodst...
-
[34]
Xi Ye, Semih Yavuz, Kazuma Hashimoto, Yingbo Zhou, and Caiming Xiong
-
[35]
RNG-KBQA: Generation Augmented Iterative Ranking for Knowledge Base Question Answering. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 6032–6043. doi:10.18653/v1/2022.acl-long.417
-
[36]
Scott Wen-tau Yih, Ming-Wei Chang, Xiaodong He, and Jianfeng Gao. 2015. Se- mantic parsing via staged query graph generation: Question answering with knowledge base. InProceedings of the Joint Conference of the 53rd Annual Meet- ing of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP. https://aclanthology.org/...
2015
-
[37]
Wen-tau Yih, Matthew Richardson, Christopher Meek, Ming-Wei Chang, and Jina Suh. 2016. The value of semantic parse labeling for knowledge base question an- swering. InProceedings of the 54th Annual Meeting of the Association for Computa- tional Linguistics (Volume 2: Short Papers). 201–206. https://aclanthology.org/P16- 2033.pdf
2016
-
[38]
Donghan Yu, Sheng Zhang, Patrick Ng, Henghui Zhu, Alexander Hanbo Li, Jun Wang, Yiqun Hu, William Yang Wang, Zhiguo Wang, and Bing Xiang. 2022. DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases. InThe Eleventh International Conference on Learning Representations. https://openreview.net/pdf?id=XHc5zRPxqV9
2022
-
[39]
Jiayi Zhang, Jinyu Xiang, Zhaoyang Yu, Fengwei Teng, Xiong-Hui Chen, Jiaqi Chen, Mingchen Zhuge, Xin Cheng, Sirui Hong, Jinlin Wang, et al. 2025. AFlow: Automating Agentic Workflow Generation. InThe Thirteenth International Con- ference on Learning Representations
2025
-
[40]
Lingxi Zhang, Jing Zhang, Yanling Wang, Shulin Cao, Xinmei Huang, Cuiping Li, Hong Chen, and Juanzi Li. 2023. FC-KBQA: A Fine-to-Coarse Composition Framework for Knowledge Base Question Answering. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 1002–1017. doi:10.18653/v1/2023.acl-long.57 C...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.