Recognition: unknown
DORA: A Scalable Asynchronous Reinforcement Learning System for Language Model Training
Pith reviewed 2026-05-07 13:43 UTC · model grok-4.3
The pith
Multi-version streaming rollout enables full asynchronous overlap in LLM reinforcement learning while preserving policy consistency and convergence.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
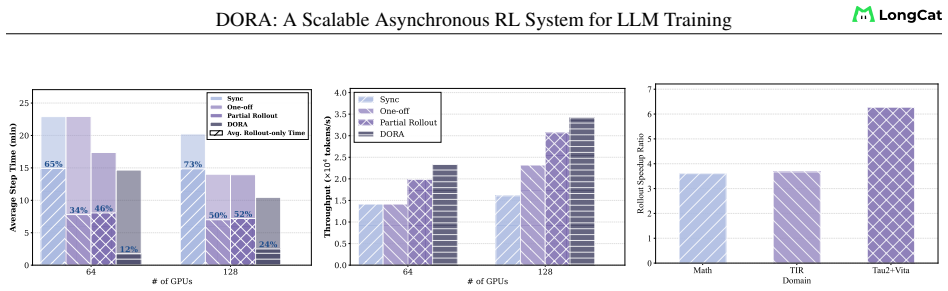
DORA introduces multi-version streaming rollout, a novel asynchronous paradigm that maintains multiple policy versions concurrently. This simultaneously achieves full bubble elimination in the rollout phase without compromising intra-trajectory policy consistency, data integrity, or bounded staleness, and without deviating from the standard RL training formulation or the long-tailed trajectory distribution present in MoE models. The resulting system delivers up to 2-3 times higher throughput than state-of-the-art systems on open-source benchmarks and 2-4 times acceleration compared to synchronous training in large-scale industrial deployments with tens of thousands of accelerators, while the
What carries the argument
multi-version streaming rollout, which maintains multiple policy versions concurrently to enable complete overlap of generation and training while satisfying the three algorithmic constraints
If this is right
- Throughput rises 2-3 times on open-source benchmarks while convergence behavior remains unchanged.
- Large-scale runs with tens of thousands of accelerators finish 2-4 times faster than synchronous equivalents.
- The resulting models, such as LongCat-Flash-Thinking, reach competitive scores on complex reasoning tasks.
- Long-tailed trajectories and MoE imbalance no longer force pipeline stalls or force deviation from standard RL updates.
Where Pith is reading between the lines
- The same concurrency pattern could shorten iteration cycles for repeated RL fine-tuning loops on large models.
- Production environments might adopt similar streaming designs to support more frequent policy updates from live data.
- The co-design approach may transfer to other distributed training stages that suffer from data skew or generation imbalance.
- Further scaling could expose new limits on version count or staleness bounds that require additional coordination mechanisms.
Load-bearing premise
That a multi-version streaming rollout can simultaneously satisfy intra-trajectory policy consistency, data integrity, and bounded staleness while staying inside the standard RL formulation and the long-tailed trajectory distribution of MoE models.
What would settle it
A controlled experiment in which models trained with DORA show measurably lower final performance on complex reasoning benchmarks than identically configured synchronous baselines, or in which the claimed throughput gains disappear once the three constraints are strictly enforced.
Figures






read the original abstract
Reinforcement learning (RL) has become a critical paradigm for LLM post-training, yet the rollout phase -- accounting for 50--80% of total step time -- is bottlenecked by skewed generation: long-tailed trajectories indispensable for model performance block the entire training pipeline. Asynchronous training offers a natural remedy by overlapping generation with training, but introduces a fundamental tension between efficiency and algorithmic correctness. We identify three constraints in asynchronous training to preserve convergence: intra-trajectory policy consistency, data integrity, and bounded staleness. Existing approaches fail to intrinsically address the long-tailed trajectory problem, which is further exacerbated by the imbalance characteristic of Mix-of-Experts models, or deviate from the standard RL training formulation, thereby hindering model convergence. Therefore, we propose DORA (Dynamic ORchestration for Asynchronous Rollout), which addresses this challenge through algorithm-system co-design. DORA introduces multi-version streaming rollout, a novel asynchronous paradigm that maintains multiple policy versions concurrently -- simultaneously achieving full bubble elimination without compromising algorithmic constraints. Experimental results demonstrate that our DORA system achieves substantial improvements in throughput -- up to 2--3 times higher than state-of-the-art systems on open-source benchmarks -- without compromising convergence. Furthermore, in large-scale industrial applications with tens of thousands of accelerators, DORA accelerates RL training by 2--4 times compared to synchronous training across various scenarios. The resultant open-source models, LongCat-Flash-Thinking, exhibit competitive performance on complex reasoning benchmarks, matching the capability of most advanced LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces DORA, a system for asynchronous RL post-training of LLMs that uses multi-version streaming rollout to overlap generation and training. It identifies three constraints (intra-trajectory policy consistency, data integrity, bounded staleness) needed to preserve convergence and claims that the new paradigm eliminates rollout bubbles (the 50-80% bottleneck, worsened by long-tailed MoE trajectories) while satisfying those constraints. Reported results include 2-3x throughput gains versus SOTA on open-source benchmarks, 2-4x acceleration versus synchronous training at industrial scale (tens of thousands of accelerators), and competitive performance of the resulting LongCat-Flash-Thinking models on reasoning benchmarks.
Significance. If the consistency and convergence claims hold, DORA would represent a meaningful advance in scalable RL for LLMs by solving the long-tail rollout bottleneck through algorithm-system co-design. The open-sourcing of the resulting models is a concrete strength that enables reproducibility and further use.
major comments (2)
- [Abstract] Abstract: the central claim that multi-version streaming rollout simultaneously achieves full bubble elimination while preserving intra-trajectory policy consistency (and the other two constraints) for long-tailed MoE trajectories is not supported by any description, pseudocode, or equation showing how a trajectory is pinned to a single policy version from token 1 to termination. Without this, it is unclear whether the generated data remains valid for standard RL (on-policy or clipped importance sampling) or whether bubbles are truly eliminated without extra staleness.
- [Experimental section] Experimental results (as referenced in the abstract and reader's assessment): no quantitative evidence, error bars, ablations on the three constraints, or handling details for long-tailed trajectories are supplied. This is load-bearing because the throughput gains (2-3x, 2-4x) and “without compromising convergence” assertion cannot be evaluated without them.
minor comments (2)
- [Abstract] Abstract: the specific open-source benchmarks and MoE models used for the 2-3x claim are not named.
- [Throughout] Notation: terms such as “multi-version streaming rollout,” “bounded staleness,” and “data integrity” would benefit from explicit definitions or equations early in the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, drawing on the full manuscript where relevant and committing to revisions that strengthen clarity and evidence without altering the core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that multi-version streaming rollout simultaneously achieves full bubble elimination while preserving intra-trajectory policy consistency (and the other two constraints) for long-tailed MoE trajectories is not supported by any description, pseudocode, or equation showing how a trajectory is pinned to a single policy version from token 1 to termination. Without this, it is unclear whether the generated data remains valid for standard RL (on-policy or clipped importance sampling) or whether bubbles are truly eliminated without extra staleness.
Authors: We agree the abstract is too concise to include pseudocode or equations. The full manuscript (Section 3.2 and Algorithm 1) specifies that each trajectory is pinned at initiation to the policy version active when rollout begins; all subsequent tokens are generated under that fixed version via the streaming orchestration, which maintains concurrent versions only for new trajectories. This satisfies intra-trajectory consistency, keeps data valid for standard on-policy RL (no cross-version mixing within a trajectory), and bounds staleness by the maximum number of active versions. Long-tailed MoE trajectories are handled by allowing shorter ones to advance with newer versions while long ones complete under their pinned version, removing bubbles. We will revise the abstract to add one sentence summarizing the pinning mechanism and directing readers to Section 3. revision: yes
-
Referee: [Experimental section] Experimental results (as referenced in the abstract and reader's assessment): no quantitative evidence, error bars, ablations on the three constraints, or handling details for long-tailed trajectories are supplied. This is load-bearing because the throughput gains (2-3x, 2-4x) and “without compromising convergence” assertion cannot be evaluated without them.
Authors: The manuscript reports the 2-3x and 2-4x throughput numbers with direct comparisons to prior systems and synchronous baselines. However, we acknowledge the referee's point that additional quantitative support is needed for full evaluation. In the revision we will add: (i) error bars from repeated runs on the open-source benchmarks, (ii) ablations isolating the contribution of each constraint (policy consistency, data integrity, bounded staleness), and (iii) explicit handling details and timing breakdowns for long-tailed MoE trajectories. These additions will be placed in Section 4 and will not change the reported gains but will make the convergence and efficiency claims directly verifiable. revision: yes
Circularity Check
No circularity; empirical systems claims with no derivation chain
full rationale
The provided abstract and text describe a systems paper proposing multi-version streaming rollout to address rollout bottlenecks in RL for LLMs. No equations, fitted parameters, or mathematical derivations are present. Throughput claims (2-3x over SOTA, 2-4x vs synchronous) rest on experimental measurements across benchmarks and industrial deployments rather than any first-principles result that reduces to its own inputs by construction. The three constraints (intra-trajectory policy consistency, data integrity, bounded staleness) are stated as requirements to preserve convergence, but the paper does not derive them from self-referential definitions or self-citations; they function as design goals. No self-citation load-bearing steps, ansatz smuggling, or renaming of known results appear. This is a standard empirical co-design paper whose central claims are falsifiable via runtime measurements and do not contain tautological reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard RL training formulation remains valid when generation and training are overlapped under bounded staleness
invented entities (1)
-
multi-version streaming rollout
no independent evidence
Reference graph
Works this paper leans on
-
[1]
$\tau^2$-Bench: Evaluating Conversational Agents in a Dual-Control Environment
URLhttps://www.anthropic.com/news/claude-opus-4-5. Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ2-bench: Evaluating conversational agents in a dual-control environment.CoRR, abs/2506.07982,
work page internal anchor Pith review arXiv
-
[2]
Dong Du, Shulin Liu, Tao Yang, Shaohua Chen, and Yang Li. Ulorl: An ultra-long output reinforcement learning approach for advancing large language models’ reasoning abilities.arXiv preprint arXiv:2507.19766,
-
[3]
Wei Fu, Jiaxuan Gao, Xujie Shen, Chen Zhu, Zhiyu Mei, Chuyi He, Shusheng Xu, Guo Wei, Jun Mei, Jiashu Wang, et al. Areal: A large-scale asynchronous reinforcement learning system for language reasoning.arXiv preprint arXiv:2505.24298,
-
[4]
Wei Gao, Yuheng Zhao, Dakai An, Tianyuan Wu, Lunxi Cao, Shaopan Xiong, Ju Huang, Weixun Wang, Siran Yang, Wenbo Su, et al. Rollpacker: Mitigating long-tail rollouts for fast, synchronous rl post-training.arXiv preprint arXiv:2509.21009,
-
[5]
Zhenyu Han, Ansheng You, Haibo Wang, Kui Luo, Guang Yang, Wenqi Shi, Menglong Chen, Sicheng Zhang, Zeshun Lan, Chunshi Deng, et al. Asyncflow: An asynchronous streaming rl framework for efficient llm post-training.arXiv preprint arXiv:2507.01663,
-
[6]
Jingkai He, Tianjian Li, Erhu Feng, Dong Du, Qian Liu, Tao Liu, Yubin Xia, and Haibo Chen. History rhymes: Accelerating llm reinforcement learning with rhymerl.arXiv preprint arXiv:2508.18588, 2025a. Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, Man Gao, Xi Su, Xiaodong Cai, Xunlia...
-
[7]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088,
work page internal anchor Pith review arXiv
-
[8]
arXiv preprint arXiv:2410.18252 , year=
Michael Noukhovitch, Shengyi Huang, Sophie Xhonneux, Arian Hosseini, Rishabh Agarwal, and Aaron Courville. Asynchronous rlhf: Faster and more efficient off-policy rl for language models.arXiv preprint arXiv:2410.18252,
-
[9]
URLhttps://arxiv.org/abs/2412.15115. Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE,
work page internal anchor Pith review arXiv
-
[10]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
- [11]
-
[12]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
14 DORA: A Scalable Asynchronous RL System for LLM Training Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
- [13]
-
[14]
arXiv preprint arXiv:2510.12633 , year=
Guangming Sheng, Yuxuan Tong, Borui Wan, Wang Zhang, Chaobo Jia, Xibin Wu, Yuqi Wu, Xiang Li, Chi Zhang, Yanghua Peng, et al. Laminar: A scalable asynchronous rl post-training framework.arXiv preprint arXiv:2510.12633, 2025a. Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A fl...
-
[15]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute optimally can be more effective than scaling model parameters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review arXiv
-
[16]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025a. Meituan LongCat Team, Anchun Gui, Bei Li, Bingyang Tao, Bole Zhou, Borun Chen, Chao Zhang, Chengcheng Han, Chenhui Yang, Chi Zhang...
work page internal anchor Pith review arXiv
-
[17]
Jinghui Wang, Shaojie Wang, Yinghan Cui, Xuxing Chen, Chao Wang, Xiaojiang Zhang, Minglei Zhang, Jiarong Zhang, Wenhao Zhuang, Yuchen Cao, et al. Seamlessflow: A trainer agent isolation rl framework achieving bubble-free pipelines via tag scheduling.arXiv preprint arXiv:2508.11553,
-
[18]
Bo Wu, Sid Wang, Yunhao Tang, Jia Ding, Eryk Helenowski, Liang Tan, Tengyu Xu, Tushar Gowda, Zhengxing Chen, Chen Zhu, et al. Llamarl: A distributed asynchronous reinforcement learning framework for efficient large-scale llm training.arXiv preprint arXiv:2505.24034,
-
[19]
Youshao Xiao, Zhenglei Zhou, Fagui Mao, Weichang Wu, Shangchun Zhao, Lin Ju, Lei Liang, Xiaolu Zhang, and Jun Zhou. An adaptive placement and parallelism framework for accelerating rlhf training.arXiv preprint arXiv:2312.11819,
-
[20]
Deepspeed-chat: Easy, fast and affordable rlhf training of chatgpt-like models at all scales
Zhewei Yao, Reza Yazdani Aminabadi, Olatunji Ruwase, Samyam Rajbhandari, Xiaoxia Wu, Ammar Ahmad Awan, Jeff Rasley, Minjia Zhang, Conglong Li, Connor Holmes, et al. Deepspeed-chat: Easy, fast and affordable rlhf training of chatgpt-like models at all scales.arXiv preprint arXiv:2308.01320,
-
[21]
Chao Yu, Yuanqing Wang, Zhen Guo, Hao Lin, Si Xu, Hongzhi Zang, Quanlu Zhang, Yongji Wu, Chunyang Zhu, Junhao Hu, et al. Rlinf: Flexible and efficient large-scale reinforcement learning via macro-to-micro flow transformation.arXiv preprint arXiv:2509.15965, 2025a. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian ...
-
[22]
URL https://www.vldb.org/ pvldb/vol16/p3848-huang.pdf
doi:10.14778/3611540.3611569. URL https://www.vldb.org/ pvldb/vol16/p3848-huang.pdf. Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Livia Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems...
-
[23]
Yinmin Zhong, Zili Zhang, Xiaoniu Song, Hanpeng Hu, Chao Jin, Bingyang Wu, Nuo Chen, Yukun Chen, Yu Zhou, Changyi Wan, et al. Streamrl: Scalable, heterogeneous, and elastic rl for llms with disaggregated stream generation.arXiv preprint arXiv:2504.15930,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.