Recognition: unknown
The Difference Between "Replicable" and "Not replicable" is not Itself Scientifically Replicable
Pith reviewed 2026-05-07 12:49 UTC · model grok-4.3
The pith
Standard replication data with binary verdicts cannot reliably separate replicable from non-replicable scientific results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that the usual data structure of replication studies—single binary verdicts per experiment—cannot support reliable demarcation between replicable and not replicable results. Under a shared latent rate model, variability in rates creates an irreducible variance floor on estimates. Under a conditionally independent rates model, the heterogeneity is not identifiable at all from the data. Thus, high- and low-replicability sequences cannot be distinguished in principle, and aggregating rates across studies lacks stable interpretation. Replicability rate is not a reliable criterion for demarcation.
What carries the argument
Two formal statistical models of non-exact replication sequences: the shared latent rate (benchmark) model, where experiments share a common random replicability rate, and the conditionally independent rates (operational) model, where each experiment has its own rate drawn from a population distribution; these models reveal that binary verdict data provides insufficient information to measure or account for between-experiment differences.
Load-bearing premise
The two statistical models of non-exactness and heterogeneity fully capture the relevant variability in actual replication studies.
What would settle it
A controlled replication dataset that collects richer continuous outcome measures per experiment and shows the estimated mean replicability rate converging without an irreducible variance floor as the number of studies grows would falsify the central claim.
Figures
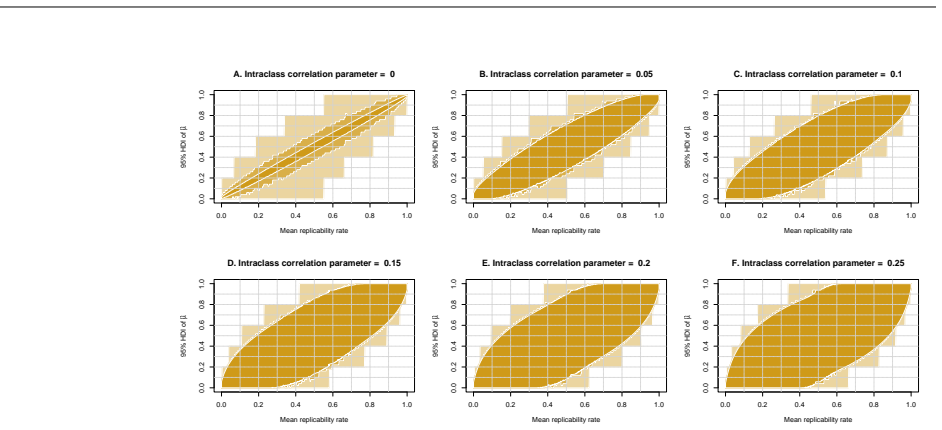
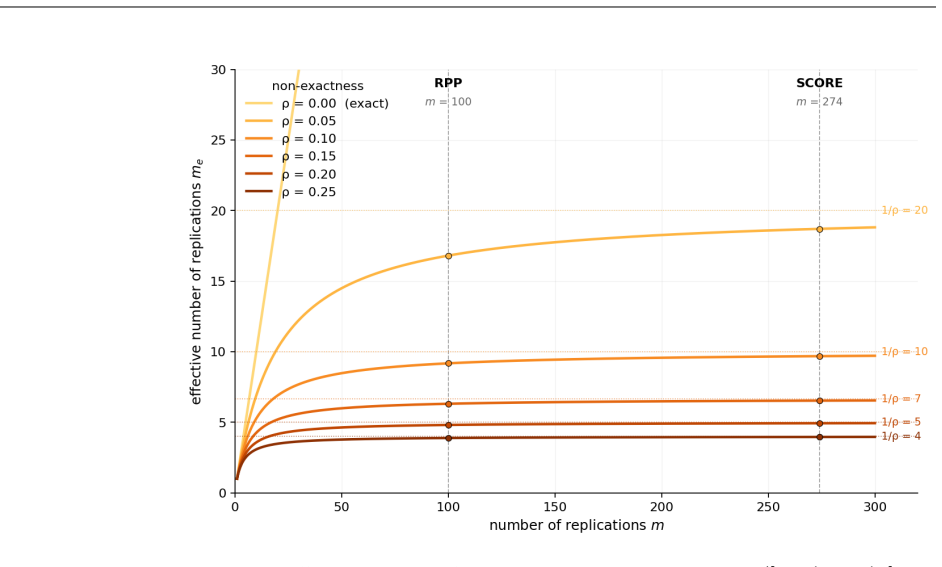

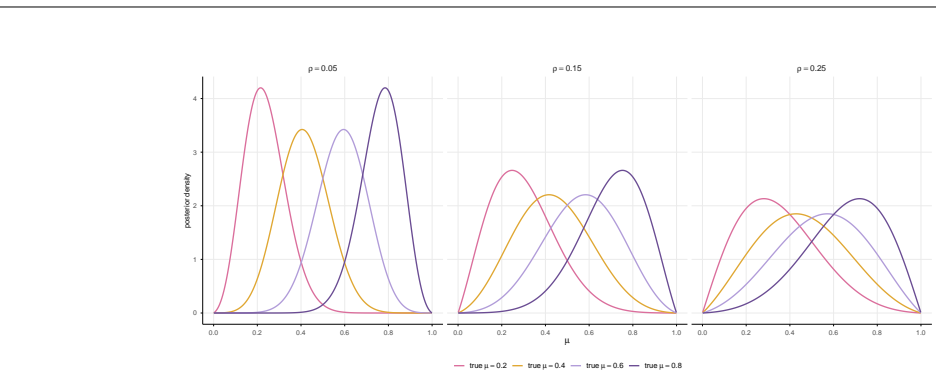

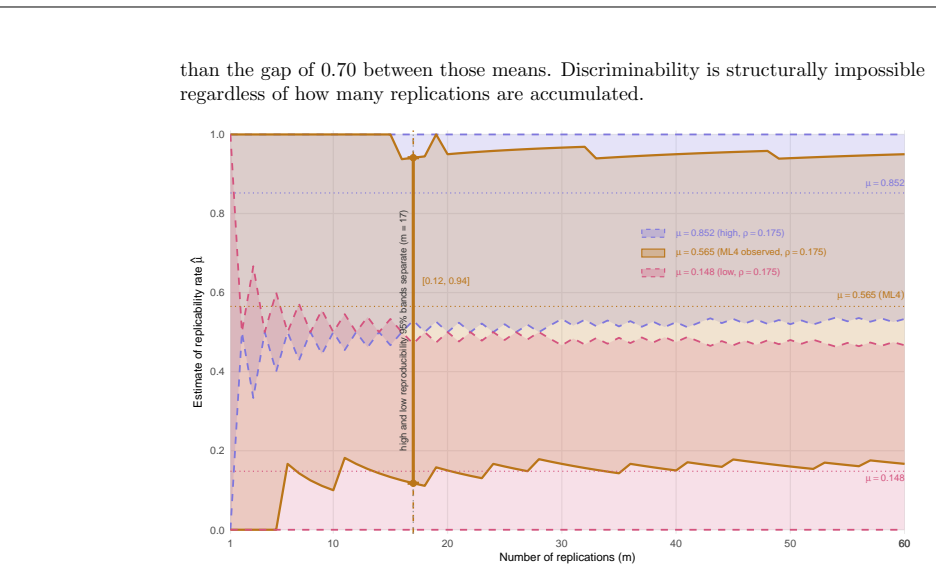
read the original abstract
Replication studies estimate the replicability rate of scientific results by aggregating binary verdicts of experiments. Exact replications are rarely attainable, so most replication sequences are non-exact. Experiments differ in ways that matter and do not share a single data-generating process. We formalize two statistical interpretations of non-exactness. In a shared latent rate (benchmark) model, experiments are exchangeable and depend on a common random replicability rate. In a conditionally independent rates (operational) model, each experiment has its own replicability rate drawn from a population distribution. Under the benchmark model, even small variability among replicability rates induces an irreducible variance floor on the estimated mean replicability rate that no amount of replication can eliminate. Under the operational model, the degree of non-exactness is not identifiable from standard replication data, because one binary verdict per experiment carries no information about between-experiment heterogeneity. Researchers cannot tell which precision regime they are in or whether high- and low-replicability sequences can be distinguished in principle. The usual data structure cannot support reliable demarcation between "replicable" and "not replicable" results and systematically understates uncertainty, making high- and low-replicability sequences appear discriminable when they are not. We show how common sources of heterogeneity amplify these problems and demonstrate practical consequences in a reanalysis of Many Labs 4. Aggregating replicability rates across heterogeneous literatures produces averages that conflate incommensurable regimes and lack a stable interpretation. Replicability rate is not a reliable demarcation criterion. The replication crisis, if there is one, cannot be established by the methods used to declare it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes two statistical models for non-exact replication sequences— a shared latent rate (benchmark) model in which experiments are exchangeable draws from a common random replicability rate, and a conditionally independent rates (operational) model in which each experiment has its own rate drawn from a population distribution. It shows that the benchmark model induces an irreducible variance floor on the estimated mean replicability rate equal to Var(Θ), while the operational model renders the degree of heterogeneity non-identifiable from binary verdicts alone. These properties imply that standard replication data cannot reliably demarcate 'replicable' from 'not replicable' results, systematically understate uncertainty, and produce misleading distinctions between high- and low-replicability sequences. The argument is illustrated with a reanalysis of Many Labs 4 and extended to the aggregation of replicability rates across heterogeneous literatures.
Significance. If the modeling distinctions hold, the work identifies a structural limitation in the data structures routinely used to quantify replicability, showing that binary verdicts alone cannot support stable inferences about heterogeneity or replicability rates. This has direct bearing on claims about the replication crisis and on the interpretation of large-scale replication projects. The explicit derivation of the variance floor and non-identifiability results, together with the reanalysis, supplies a concrete, falsifiable basis for questioning current demarcation practices.
major comments (2)
- [§3] §3 (benchmark model): the derivation that the marginal variance of the sample mean converges to Var(Θ) rather than zero is a direct consequence of the hierarchical structure; however, the manuscript should state the precise regularity conditions (e.g., finite second moments of Θ) under which the asymptotic floor is guaranteed, as these are load-bearing for the 'no amount of replication can eliminate' claim.
- [§4] §4 (operational model): the non-identifiability result follows immediately from the fact that each experiment contributes only a single Bernoulli observation; the paper should clarify whether this remains true under mild relaxations such as known bounds on the support of the heterogeneity distribution or the availability of continuous outcome measures in a subset of replications.
minor comments (3)
- [reanalysis section] The reanalysis of Many Labs 4 would benefit from an explicit table or figure showing the estimated variance floor under the benchmark model versus the observed between-experiment variability.
- [§2] Notation for the two models (e.g., Θ vs. θ_i) is introduced clearly but could be summarized in a single display equation for quick reference.
- [discussion] A brief discussion of how the conclusions change if some replications provide continuous rather than binary outcomes would strengthen the practical implications.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify points where additional technical precision and scope clarification will strengthen the manuscript. We address each major comment below and have incorporated revisions as indicated.
read point-by-point responses
-
Referee: [§3] §3 (benchmark model): the derivation that the marginal variance of the sample mean converges to Var(Θ) rather than zero is a direct consequence of the hierarchical structure; however, the manuscript should state the precise regularity conditions (e.g., finite second moments of Θ) under which the asymptotic floor is guaranteed, as these are load-bearing for the 'no amount of replication can eliminate' claim.
Authors: We agree that the regularity conditions merit explicit statement. The revised manuscript now includes the assumption that Θ possesses finite second moments (E[Θ²] < ∞), which is the standard condition ensuring that the variance of the sample mean converges to Var(Θ) rather than zero under exchangeability. This addition does not alter the main result or the claim that an irreducible floor persists; it simply makes the technical basis transparent. revision: yes
-
Referee: [§4] §4 (operational model): the non-identifiability result follows immediately from the fact that each experiment contributes only a single Bernoulli observation; the paper should clarify whether this remains true under mild relaxations such as known bounds on the support of the heterogeneity distribution or the availability of continuous outcome measures in a subset of replications.
Authors: The non-identifiability result is derived specifically for the standard case of one binary verdict per experiment. With a priori known bounds on the support of the heterogeneity distribution, partial identification of the variance of rates becomes feasible in principle, though such bounds are rarely available in replication studies. Continuous outcome measures would indeed supply additional information and could relax the non-identifiability, but they fall outside the binary-verdict data structure that defines current replication protocols. The revised §4 now briefly notes these scope limitations while emphasizing that our conclusions apply to the binary data routinely collected. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper defines two explicit hierarchical models (shared latent rate benchmark and conditionally independent rates operational) and derives their consequences for variance floors and non-identifiability directly from the model structures and standard probability results. The asymptotic variance floor equals Var(Θ) under exchangeability, and binary data yield no information on heterogeneity; both follow immediately from the stated assumptions without parameter fitting to the target replication verdicts or reduction to self-citations. No load-bearing step equates a prediction to its input by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Experiments in replication sequences are non-exact and differ in ways that matter for the data-generating process.
- domain assumption Binary verdicts (replicable/not) are the only data available per experiment in standard replication studies.
invented entities (2)
-
Shared latent rate (benchmark) model
no independent evidence
-
Conditionally independent rates (operational) model
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Raise standards for preclinical cancer research
C Glenn Begley and Lee M Ellis. Raise standards for preclinical cancer research. Nature, 483 0 (7391): 0 531--533, 2012
2012
-
[2]
Behavioural science is unlikely to change the world without a heterogeneity revolution
Christopher J Bryan, Elizabeth Tipton, and David S Yeager. Behavioural science is unlikely to change the world without a heterogeneity revolution. Nature human behaviour, 5 0 (8): 0 980--989, 2021
2021
-
[3]
Power failure: why small sample size undermines the reliability of neuroscience
Katherine S Button, John PA Ioannidis, Claire Mokrysz, Brian A Nosek, Jonathan Flint, Emma SJ Robinson, and Marcus R Munaf \`o . Power failure: why small sample size undermines the reliability of neuroscience. Nature reviews neuroscience, 14 0 (5): 0 365--376, 2013
2013
-
[4]
Buzbas, Berna Devezer, and Bert Baumgaertner
Erkan O. Buzbas, Berna Devezer, and Bert Baumgaertner. The logical structure of experiments lays the foundation for a theory of reproducibility. Royal Society Open Science, 10 0 (3): 0 221042, 2023
2023
-
[5]
Evaluating replicability of laboratory experiments in economics
Colin F Camerer, Anna Dreber, Eskil Forsell, Teck-Hua Ho, J \"u rgen Huber, Magnus Johannesson, Michael Kirchler, Johan Almenberg, Adam Altmejd, Taizan Chan, et al. Evaluating replicability of laboratory experiments in economics. Science, 351 0 (6280): 0 1433--1436, 2016
2016
-
[6]
Estimating the reproducibility of psychological science
Open Science Collaboration. Estimating the reproducibility of psychological science. Science, 349 0 (6251): 0 aac4716, 2015
2015
-
[7]
Minimum viable experiment to replicate, 2025
Berna Devezer and Erkan Buzbas. Minimum viable experiment to replicate, 2025. URL https://philsci-archive.pitt.edu/24738/
2025
-
[8]
Beyond power calculations: Assessing type s (sign) and type m (magnitude) errors
Andrew Gelman and John Carlin. Beyond power calculations: Assessing type s (sign) and type m (magnitude) errors. Perspectives on psychological science, 9 0 (6): 0 641--651, 2014
2014
-
[9]
significant
Andrew Gelman and Hal Stern. The difference between “significant” and “not significant” is not itself statistically significant. The American Statistician, 60 0 (4): 0 328--331, 2006
2006
-
[10]
Role of consciousness and accessibility of death-related thoughts in mortality salience effects
Jeff Greenberg, Tom Pyszczynski, Sheldon Solomon, Linda Simon, and Michael Breus. Role of consciousness and accessibility of death-related thoughts in mortality salience effects. Journal of personality and social psychology, 67 0 (4): 0 627, 1994
1994
-
[11]
Distribution theory for glass's estimator of effect size and related estimators
Larry V Hedges. Distribution theory for glass's estimator of effect size and related estimators. journal of Educational Statistics, 6 0 (2): 0 107--128, 1981
1981
-
[12]
Most people are not weird
Joseph Henrich, Steven J Heine, and Ara Norenzayan. Most people are not weird. Nature, 466 0 (7302): 0 29--29, 2010
2010
-
[13]
Many labs 4: Failure to replicate mortality salience effect with and without original author involvement
Richard A Klein, Corey L Cook, Charles R Ebersole, Christine Vitiello, Brian A Nosek, Joseph Hilgard, Paul Hangsan Ahn, Abbie J Brady, Christopher R Chartier, Cody D Christopherson, et al. Many labs 4: Failure to replicate mortality salience effect with and without original author involvement. Collabra: Psychology, 8 0 (1): 0 35271, 2022
2022
-
[14]
Reproducibility, replicability, and reliability
Xiao-Li Meng. Reproducibility, replicability, and reliability. Harvard Data Science Review, 2 0 (4): 0 10, 2020
2020
-
[15]
A multi-center study on the reproducibility of drug-response assays in mammalian cell lines
Mario Niepel, Marc Hafner, Caitlin E Mills, Kartik Subramanian, Elizabeth H Williams, Mirra Chung, Benjamin Gaudio, Anne Marie Barrette, Alan D Stern, Bin Hu, et al. A multi-center study on the reproducibility of drug-response assays in mammalian cell lines. Cell systems, 9 0 (1): 0 35--48, 2019
2019
-
[16]
Believe it or not: how much can we rely on published data on potential drug targets? Nature Reviews Drug Discovery, 10 0 (9): 0 712--712, 2011
Florian Prinz, Thomas Schlange, and Khusru Asadullah. Believe it or not: how much can we rely on published data on potential drug targets? Nature Reviews Drug Discovery, 10 0 (9): 0 712--712, 2011
2011
-
[17]
Investigating the replicability of the social and behavioural sciences
Andrew H Tyner, Anna Lou Abatayo, Mason Daley, Samuel Field, Nicholas Fox, Noah A Haber, Krystal M Hahn, Melissa Kline Struhl, Brinna Mawhinney, Olivia Miske, et al. Investigating the replicability of the social and behavioural sciences. Nature, 652 0 (8108): 0 143--150, 2026
2026
-
[18]
Achieving across-laboratory replicability in psychophysical scaling
Lawrence M Ward, Michael Baumann, Graeme Moffat, Larry E Roberts, Shuji Mori, Matthew Rutledge-Taylor, and Robert L West. Achieving across-laboratory replicability in psychophysical scaling. Frontiers in Psychology, 6: 0 903, 2015
2015
-
[19]
Development and validation of brief measures of positive and negative affect: the panas scales
David Watson, Lee Anna Clark, and Auke Tellegen. Development and validation of brief measures of positive and negative affect: the panas scales. Journal of personality and social psychology, 54 0 (6): 0 1063, 1988
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.