Recognition: unknown
Beyond Fixed Formulas: Data-Driven Linear Predictor for Efficient Diffusion Models
Pith reviewed 2026-05-07 13:46 UTC · model grok-4.3
The pith
Learnable per-timestep weights let diffusion transformers skip more steps without losing image quality
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
L2P is a data-driven caching framework that substitutes fixed forecasting coefficients with learnable per-timestep weights; once trained, these weights reconstruct current features from a short history of cached past features and thereby permit substantially higher skipping rates during DiT inference without measurable quality loss.
What carries the argument
Learnable Linear Predictor (L2P): a per-timestep linear model whose weights are fitted on a small set of trajectories to map past features to the current feature vector.
If this is right
- 4.55 times reduction in FLOPs on FLUX.1-dev
- 4.15 times reduction in wall-clock latency on FLUX.1-dev
- Up to 7.18 times acceleration on Qwen-Image models while prior fixed-formula methods visibly degrade
- The same training procedure works across different DiT architectures without manual redesign of forecasting rules
Where Pith is reading between the lines
- Because the predictor is learned from data, it may automatically adapt to the distinct dynamics of different noise schedules or model scales.
- The short training time suggests the approach could be combined with lightweight online fine-tuning when the input distribution shifts.
- Similar learnable linear caches might apply to other iterative generative loops such as video or 3D diffusion.
Load-bearing premise
A linear combination of earlier features, using weights trained once per timestep, can stand in for the true next feature without introducing artifacts that affect final image quality.
What would settle it
Run the full sampling process and the L2P-accelerated process on the same prompt set at the reported skip rates and compare the resulting images using standard perceptual metrics or side-by-side human ratings.
Figures







read the original abstract
To address the high sampling cost of Diffusion Transformers (DiTs), feature caching offers a training-free acceleration method. However, existing methods rely on hand-crafted forecasting formulas that fail under aggressive skipping. We propose L2P (Learnable Linear Predictor), a simple data-driven caching framework that replaces fixed coefficients with learnable per-timestep weights. Rapidly trained in ~20 seconds on a single GPU, L2P accurately reconstructs current features from past trajectories. L2P significantly outperforms existing baselines: it achieves a 4.55x FLOPs reduction and 4.15x latency speedup on FLUX.1-dev, and maintains high visual fidelity under up to 7.18x acceleration on Qwen-Image models, where prior methods show noticeable quality degradation. Our results show learning linear predictors is highly effective for efficient DiT inference. Code is available at https://github.com/Aredstone/L2P-Cache.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces L2P (Learnable Linear Predictor), a data-driven feature caching method for Diffusion Transformers that replaces hand-crafted forecasting formulas with rapidly trained (~20s on one GPU) per-timestep linear weights to reconstruct current-step features from cached past trajectories. It reports 4.55× FLOPs reduction and 4.15× latency speedup on FLUX.1-dev, plus up to 7.18× acceleration on Qwen-Image models while preserving high visual fidelity, outperforming prior caching baselines that degrade under aggressive skipping.
Significance. If the speedups and fidelity claims hold under rigorous verification, the work offers a practical, low-overhead acceleration technique for large DiTs that could meaningfully reduce inference costs in production settings. The emphasis on a simple, data-driven linear fit trained in seconds, together with public code, strengthens reproducibility and lowers the barrier to adoption compared with more complex caching or distillation approaches.
major comments (2)
- [§4.2] §4.2 and Table 2: The headline claims of maintained high visual fidelity at 7.18× acceleration rest on final-image metrics (FID, CLIP score, user studies), but no per-timestep L2 or cosine-similarity error curves are reported between the linear predictor’s output and ground-truth features for the aggressive skip schedules. Without these diagnostics, it is impossible to confirm that reconstruction error does not accumulate in ways invisible to downstream image quality metrics.
- [§5.1] §5.1: The learned per-timestep weights are shown only on the calibration trajectories; no ablation or stability test is provided on whether the same coefficients generalize across different prompt distributions, random seeds, or model variants beyond the two evaluated (FLUX.1-dev and Qwen-Image). This is load-bearing for the claim that L2P is a robust, plug-and-play replacement for fixed formulas.
minor comments (2)
- [Abstract] The abstract states “training-free acceleration” yet the method requires a short calibration phase; a brief clarification in the introduction would avoid reader confusion.
- [§3.2] Figure 3 caption and §3.2: the notation for the linear predictor (W_t, b_t) is introduced without an explicit equation linking it to the feature reconstruction step; adding the equation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments, which help us improve the clarity and rigor of our work. We address each major point below and will incorporate the suggested analyses in the revised manuscript.
read point-by-point responses
-
Referee: [§4.2] §4.2 and Table 2: The headline claims of maintained high visual fidelity at 7.18× acceleration rest on final-image metrics (FID, CLIP score, user studies), but no per-timestep L2 or cosine-similarity error curves are reported between the linear predictor’s output and ground-truth features for the aggressive skip schedules. Without these diagnostics, it is impossible to confirm that reconstruction error does not accumulate in ways invisible to downstream image quality metrics.
Authors: We agree that per-timestep reconstruction diagnostics would provide stronger evidence against hidden error accumulation. In the revised version we will add L2-norm and cosine-similarity error curves (averaged over multiple trajectories) for the exact aggressive skip schedules used in Table 2 on both FLUX.1-dev and Qwen-Image. These plots will show that feature-level errors remain low and bounded across timesteps, thereby confirming that the reported final-image metrics are not masking progressive degradation. revision: yes
-
Referee: [§5.1] §5.1: The learned per-timestep weights are shown only on the calibration trajectories; no ablation or stability test is provided on whether the same coefficients generalize across different prompt distributions, random seeds, or model variants beyond the two evaluated (FLUX.1-dev and Qwen-Image). This is load-bearing for the claim that L2P is a robust, plug-and-play replacement for fixed formulas.
Authors: We acknowledge the value of explicit generalization tests. The manuscript already demonstrates that the same L2P procedure yields strong results on two architecturally distinct models (FLUX.1-dev and Qwen-Image) with their native prompt sets. Because training requires only ~20 seconds, the method is designed to be re-calibrated per model rather than assuming universal coefficients. To further address robustness, the revision will include (i) weight stability across multiple random seeds on the same calibration set and (ii) a cross-prompt evaluation where weights trained on one prompt distribution are applied to a held-out set of prompts, together with a short discussion clarifying the intended per-model calibration workflow. revision: yes
Circularity Check
No circularity: L2P is an explicitly data-driven fitted model trained separately from inference
full rationale
The manuscript introduces L2P as a rapidly trained (~20s) linear predictor with per-timestep learnable weights fitted to calibration trajectories, then deployed for feature reconstruction during accelerated DiT sampling. This is presented as an empirical replacement for hand-crafted formulas rather than a derivation from the denoising ODE or any first-principles equations. No load-bearing step reduces a claimed result to its inputs by construction, no self-citations are invoked for uniqueness or ansatz smuggling, and the performance claims (FLOPs/latency gains on FLUX.1-dev and Qwen-Image) rest on external experimental validation rather than tautological fitting. The approach is therefore self-contained against benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-timestep linear weights
Reference graph
Works this paper leans on
-
[1]
Stable video diffusion: Scaling latent video diffusion models to large datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets. 2023. 1
2023
-
[2]
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen.δ-dit: A training-free acceleration method tai- lored for diffusion transformers. 2024. 1
2024
-
[3]
Structural pruning for diffusion models, 2023
Gongfan Fang, Xinyin Ma, and Xinchao Wang. Structural pruning for diffusion models, 2023. 2
2023
-
[4]
Denoising Diffusion Probabilistic Models
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Dif- fusion Probabilistic Models, 2020. arXiv:2006.11239 [cs]. 1
work page internal anchor Pith review arXiv 2020
-
[5]
Accel- erating diffusion model training under minimal budgets: A condensation-based perspective, 2026
Rui Huang, Shitong Shao, Zikai Zhou, Pukun Zhao, Hangyu Guo, Tian Ye, Lichen Bai, Shuo Yang, and Zeke Xie. Accel- erating diffusion model training under minimal budgets: A condensation-based perspective, 2026. 2
2026
-
[6]
Har- monica: Harmonizing training and inference for better fea- ture caching in diffusion transformer acceleration, 2025
Yushi Huang, Zining Wang, Ruihao Gong, Jing Liu, Xinjie Zhang, Jinyang Guo, Xianglong Liu, and Jun Zhang. Har- monica: Harmonizing training and inference for better fea- ture caching in diffusion transformer acceleration, 2025. 2
2025
-
[7]
Ryoo, and Tian Xie
Kumara Kahatapitiya, Haozhe Liu, Sen He, Ding Liu, Menglin Jia, Chenyang Zhang, Michael S. Ryoo, and Tian Xie. Adaptive Caching for Faster Video Generation with Diffusion Transformers, 2024. 3
2024
-
[8]
Hunyuanvideo: A systematic framework for large video generative models, 2025
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
2025
-
[9]
Flux.https://github.com/ black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/ black-forest-labs/flux, 2024. 5, 1
2024
-
[10]
Senmao Li, Taihang Hu, Fahad Shahbaz Khan, Linxuan Li, Shiqi Yang, Yaxing Wang, Ming-Ming Cheng, and Jian Yang. Faster diffusion: Rethinking the role of unet encoder in diffusion models.arXiv preprint arXiv:2312.09608, 3,
-
[11]
Zhimin Li, Jianwei Zhang, Qin Lin, Jiangfeng Xiong, Yanxin Long, Xinchi Deng, Yingfang Zhang, Xingchao Liu, Minbin Huang, Zedong Xiao, et al. Hunyuan-dit: A powerful multi-resolution diffusion transformer with fine-grained chi- nese understanding.arXiv preprint arXiv:2405.08748, 2024. 2
-
[12]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. InProceedings of the IEEE/CVF Confer- ence on Computer Vision and Pattern Recognition (CVPR), pages 7353–7363, 2025. 3, 2
2025
-
[13]
Freqca: Accelerating diffusion models via frequency-aware caching, 2025
Jiacheng Liu, Peiliang Cai, Qinming Zhou, Yuqi Lin, Deyang Kong, Benhao Huang, Yupei Pan, Haowen Xu, Chang Zou, Junshu Tang, Shikang Zheng, and Lin- feng Zhang. Freqca: Accelerating diffusion models via frequency-aware caching, 2025. 3
2025
-
[14]
A survey on cache methods in diffusion models: Toward ef- ficient multi-modal generation, 2025
Jiacheng Liu, Xinyu Wang, Yuqi Lin, Zhikai Wang, Peiru Wang, Peiliang Cai, Qinming Zhou, Zhengan Yan, Zexuan Yan, Zhengyi Shi, Chang Zou, Yue Ma, and Linfeng Zhang. A survey on cache methods in diffusion models: Toward ef- ficient multi-modal generation, 2025. 1
2025
-
[15]
From reusing to forecasting: Accelerat- ing diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerat- ing diffusion models with taylorseers. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 15853–15863, 2025. 1, 3, 2
2025
-
[16]
Speca: Accelerating diffusion transformers with speculative feature caching
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Fei Ren, Shaobo Wang, Kaixin Li, and Linfeng Zhang. Speca: Accelerating diffusion transformers with speculative feature caching. In Proceedings of the 33rd ACM International Conference on Multimedia, page 10024–10033, New York, NY , USA, 2025. Association for Computing Machinery. 3
2025
-
[17]
Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022. 2
2022
-
[18]
Dpm-solver: A fast ode solver for dif- fusion probabilistic model sampling in around 10 steps
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan LI, and Jun Zhu. Dpm-solver: A fast ode solver for dif- fusion probabilistic model sampling in around 10 steps. In Advances in Neural Information Processing Systems, pages 5775–5787. Curran Associates, Inc., 2022. 2
2022
-
[19]
Dpm-solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Machine Intelligence Research, 22(4):730–751, 2025
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver++: Fast solver for guided sam- pling of diffusion probabilistic models.Machine Intelligence Research, 22(4):730–751, 2025. 2
2025
-
[20]
Learning-to-cache: Accelerating diffusion trans- former via layer caching, 2024
Xinyin Ma, Gongfan Fang, Michael Bi Mi, and Xinchao Wang. Learning-to-cache: Accelerating diffusion trans- former via layer caching, 2024. 2
2024
-
[21]
Deepcache: Accelerating diffusion models for free
Xinyin Ma, Gongfan Fang, and Xinchao Wang. Deepcache: Accelerating diffusion models for free. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15762–15772, 2024. 1, 2
2024
-
[22]
Scalable Diffusion Models with Transformers
William Peebles and Saining Xie. Scalable Diffusion Models with Transformers, 2023. arXiv:2212.09748 [cs]. 1, 2
work page internal anchor Pith review arXiv 2023
-
[23]
High-Resolution Image Synthesis with Latent Diffusion Models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models, 2022. arXiv:2112.10752 [cs]. 1
work page internal anchor Pith review arXiv 2022
-
[24]
U- net: Convolutional networks for biomedical image segmen- tation
Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U- net: Convolutional networks for biomedical image segmen- tation. InMedical Image Computing and Computer-Assisted Intervention – MICCAI 2015, pages 234–241, Cham, 2015. Springer International Publishing. 2
2015
-
[25]
Moghadam, and Ahmad Nickabadi
Omid Saghatchian, Atiyeh Gh. Moghadam, and Ahmad Nickabadi. Cached adaptive token merging: Dynamic token reduction and redundant computation elimination in diffu- sion model, 2025. 2
2025
-
[26]
Fora: Fast-forward caching in diffusion transformer acceleration, 2024
Pratheba Selvaraju, Tianyu Ding, Tianyi Chen, Ilya Zharkov, and Luming Liang. Fora: Fast-forward caching in diffusion transformer acceleration, 2024. 1, 2
2024
-
[27]
Denois- ing diffusion implicit models, 2022
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models, 2022. 2
2022
-
[28]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023. 2
2023
-
[29]
Wan: Open and advanced large-scale video generative models, 2025
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianx- iao Yang, Jianyuan Zeng, Jiayu Wang, Jingfeng Zhang, Jin- gren Zhou, Jinkai Wang, Jixuan Chen, Kai Zhu, Kang Zhao, Keyu Yan, Lianghua Huang, Mengyang Feng, Ningyi Zhang, Pandeng Li, Pingyu Wu, Ruihang Chu, Ruili Feng, Shiwei Zhang, Siyang Sun, Tao Fan...
2025
-
[30]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: From error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4): 600–612, 2004. 5, 1
2004
-
[31]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Shengming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Da-Wei Liu, De mei Li, Hang Zhang, Hao Meng, Hu Wei, Ji-Li Ni, Kai Chen, Kuang Cao, Liang Peng, Lin Qu, Min Wu, Peng Wang, Shuting Yu, Tingkun Wen, Wens...
work page internal anchor Pith review arXiv 2025
-
[32]
Perflow: Piecewise rectified flow as universal plug-and-play accelerator
Hanshu Yan, Xingchao Liu, Jiachun Pan, Jun Hao Liew, Qiang Liu, and Jiashi Feng. Perflow: Piecewise rectified flow as universal plug-and-play accelerator. InAdvances in Neural Information Processing Systems, pages 78630– 78652. Curran Associates, Inc., 2024. 2
2024
-
[33]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2
work page internal anchor Pith review arXiv 2024
-
[34]
Ditfastattn: Attention compression for diffusion transformer models
Zhihang Yuan, Hanling Zhang, Pu Lu, Xuefei Ning, Lin- feng Zhang, Tianchen Zhao, Shengen Yan, Guohao Dai, and Yu Wang. Ditfastattn: Attention compression for diffusion transformer models. InAdvances in Neural Information Pro- cessing Systems, pages 1196–1219. Curran Associates, Inc.,
-
[35]
Token pruning for caching better: 9 times acceleration on stable diffusion for free, 2024
Evelyn Zhang, Bang Xiao, Jiayi Tang, Qianli Ma, Chang Zou, Xuefei Ning, Xuming Hu, and Linfeng Zhang. Token pruning for caching better: 9 times acceleration on stable diffusion for free, 2024. 2
2024
-
[36]
The unreasonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shecht- man, and Oliver Wang. The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recogni- tion, pages 586–595, 2018. 5, 1
2018
-
[37]
Forecast then calibrate: Feature caching as ode for efficient diffusion transformers
Shikang Zheng, Liang Feng, Xinyu Wang, Qinming Zhou, Peiliang Cai, Chang Zou, Jiacheng Liu, Yuqi Lin, Junjie Chen, Yue Ma, and Linfeng Zhang. Forecast then calibrate: Feature caching as ode for efficient diffusion transformers. Proceedings of the AAAI Conference on Artificial Intelli- gence, 40(16):13449–13457, 2026. 3
2026
-
[38]
Dip-go: A diffusion pruner via few- step gradient optimization
Haowei Zhu, Dehua Tang, Ji Liu, Mingjie Lu, Jintu Zheng, Jinzhang Peng, Dong Li, Yu Wang, Fan Jiang, Lu Tian, Spandan Tiwari, Ashish Sirasao, Junhai Yong, Bin Wang, and Emad Barsoum. Dip-go: A diffusion pruner via few- step gradient optimization. InAdvances in Neural Informa- tion Processing Systems, pages 92581–92604. Curran Asso- ciates, Inc., 2024. 2
2024
-
[39]
Accelerating diffusion transformers with token- wise feature caching, 2025
Chang Zou, Xuyang Liu, Ting Liu, Siteng Huang, and Lin- feng Zhang. Accelerating diffusion transformers with token- wise feature caching, 2025. 1, 2
2025
-
[40]
Rethinking token- wise feature caching: Accelerating diffusion transformers with dual feature caching, 2025
Chang Zou, Evelyn Zhang, Runlin Guo, Haohang Xu, Con- ghui He, Xuming Hu, and Linfeng Zhang. Rethinking token- wise feature caching: Accelerating diffusion transformers with dual feature caching, 2025. 2 Beyond Fixed Formulas: Data-Driven Linear Predictor for Efficient Diffusion Models Supplementary Material
2025
-
[41]
The core learnable pre- dictor was trained for 200 epochs with a learning rate of 0.01, utilizing a dataset of 50 prompts generated by an LLM
Experiment Settings and Evaluation Implementation Details and Baselines.We evaluate our proposed method across three advanced diffusion transformer architectures: FLUX.1-dev [9] and Qwen Image [31] for text-to-image generation, and Hunyuan Video [8] for text-to-video tasks. The core learnable pre- dictor was trained for 200 epochs with a learning rate of ...
-
[42]
3.3.2, line 352,L 2Pperforms predic- tion usingonly thefinal-layerfeatures
Memory Overhead in Practice As described inSec. 3.3.2, line 352,L 2Pperforms predic- tion usingonly thefinal-layerfeatures. For HunyuanVideo at480×640resolution with 65 frames, the cached feature tensor is(1,20400,64), incurring at most∼0.49 GBcache memory for 50 steps, using∼38.6×less VRAM than the window-based baseline, first-order TaylorSeer. The resul...
-
[43]
Our method demonstrates a dom- inant advantage across both computational efficiency and generation fidelity
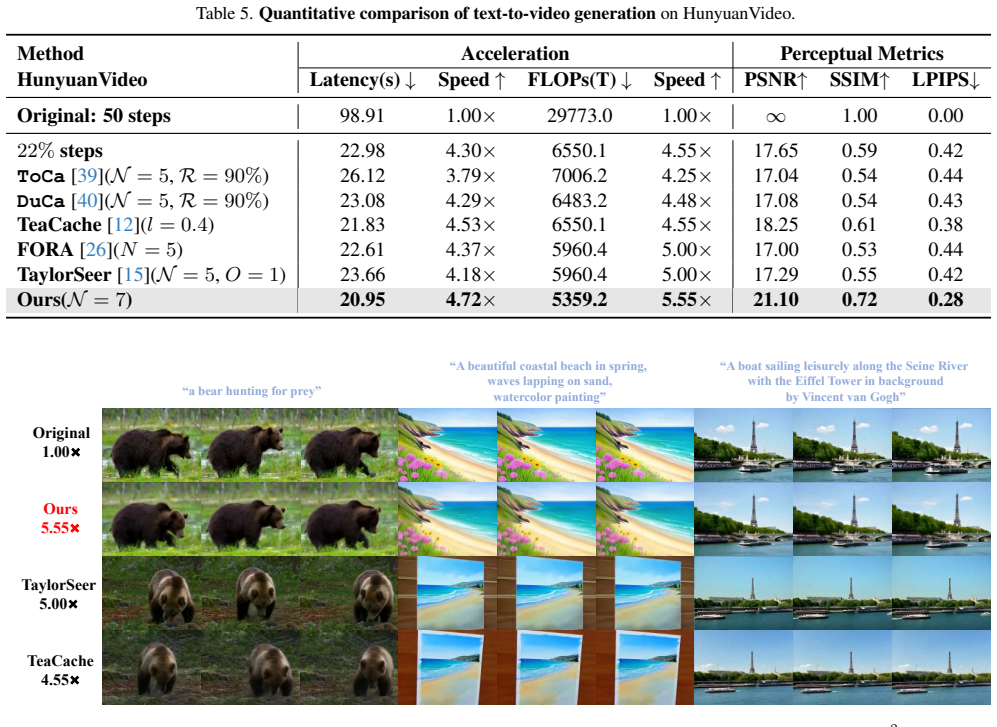
More Results on T2V Generation Table 5 reports the comprehensive performance on the Hun- yuanVideo benchmark. Our method demonstrates a dom- inant advantage across both computational efficiency and generation fidelity. In terms of efficiency, our method (withN= 7) achieves the lowest inference latency of 20.95s, correspond- ing to a 4.72×wall-clock speedu...
-
[44]
a bear hunting for prey
Justification for Linear Design A natural question arises:Why restrict the predictor to a linear combination? Can introducing non-linearity im- prove performance?We categorize potential non-linear en- hancements into two paradigms:(1) explicit a priori non- linear modeling, and(2) implicit data-driven non-linear learning. For the first paradigm, we conduc...
-
[45]
1 that existing difference-based prediction methods are equivalentd to linear combinations
Linear Combinations Seen Through High- Order Expansions We demonstrated in Obs. 1 that existing difference-based prediction methods are equivalentd to linear combinations. Conversely, it can be proven that any linear combination of historical features can be equivalently converted into a sum of high-order differences. Therefore, our explicitly learned pre...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.