Recognition: unknown
Topology-Aware Representation Alignment for Semi-Supervised Vision-Language Learning
Pith reviewed 2026-05-07 13:57 UTC · model grok-4.3
The pith
Aligning persistent homology edges across modalities improves semi-supervised vision-language learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ToMA identifies topologically salient edges and cycles via persistent homology on each modality independently and aligns them across modalities by using the cross-modal pairing information, capturing both connectivity from H0 features and cycle structure from lightweight H1 features without needing higher-dimensional simplices.
What carries the argument
Persistent homology-based identification and cross-modal alignment of H0-death edges and H1-birth edges.
If this is right
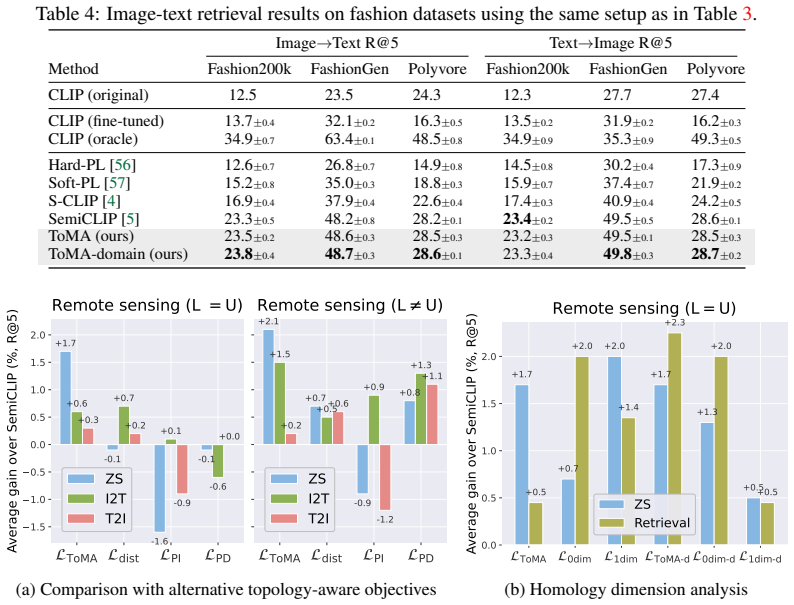
- ToMA yields stable performance gains on remote sensing tasks.
- It provides modest but consistent benefits on fashion retrieval.
- The approach is more stable than alternative topology-based objectives.
- Lightweight H1-birth edges supply useful higher-order structural signals.
Where Pith is reading between the lines
- The same principle of matching manifold structures could apply to other multimodal semi-supervised settings where global geometry matters.
- Testing the method on additional specialized domains would clarify when topological alignment provides the largest benefit.
- The lightweight use of H1 features suggests a path to incorporating higher-order information without the computational cost of full simplicial complexes.
Load-bearing premise
The topologically salient edges and cycles found separately in each modality correspond to meaningful cross-modal correspondences that enhance alignment when few paired examples are available.
What would settle it
If applying the topology alignment shows no improvement or reduced stability over standard pairwise methods on a held-out semi-supervised vision-language dataset, the central claim would be falsified.
Figures









read the original abstract
Vision-language models have shown strong performance, but they often generalize poorly to specialized domains. While semi-supervised vision-language learning mitigates this limitation by leveraging a small set of labeled image-text pairs together with abundant unlabeled images, existing methods remain fundamentally pairwise and fail to model the global structure of multimodal representation manifolds. Existing topology-based alignment methods rely on persistence diagram matching, which neither guarantees geometric alignment nor utilizes the image-text pairing information central to vision-language learning. We propose Topology-Aware Multimodal Representation Alignment (ToMA), a framework that uses persistent homology to identify topologically salient edges and aligns them across modalities through available cross-modal correspondences. ToMA leverages both H_0-death edges and lightweight H_1-birth edges, allowing it to capture both connectivity and cycle structure without constructing 2-simplices. Experiments show that ToMA yields stable gains, with clear improvements on remote sensing and modest but consistent benefits on fashion retrieval. Additional analysis shows that ToMA is more stable than alternative topology-based objectives and that lightweight H_1-birth edges provide useful higher-order structural signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Topology-Aware Multimodal Representation Alignment (ToMA) for semi-supervised vision-language learning in specialized domains. It computes persistent homology separately on image and text representation manifolds to extract salient H0-death edges (connectivity) and lightweight H1-birth edges (cycles), then aligns these intra-modal topological features across modalities using the available labeled image-text pairs. The central claim is that this captures global manifold structure better than pairwise contrastive methods or existing persistence-diagram matching approaches, yielding stable gains on remote sensing and modest consistent benefits on fashion retrieval while being more stable than alternative topology-based objectives.
Significance. If the intra-modal topological features reliably encode cross-modal semantic correspondences, ToMA would offer a practical way to incorporate higher-order structure into semi-supervised V-L alignment without full simplicial complexes or expensive diagram matching. The lightweight H1 component and reported stability advantages are potentially useful contributions for label-scarce domains. However, the significance is limited by the absence of quantitative results, ablations, or direct tests of the cross-modal correspondence assumption in the provided abstract.
major comments (2)
- [Abstract] Abstract: The claim that aligning intra-modal H0-death and H1-birth edges 'through available cross-modal correspondences' improves downstream alignment rests on the unverified assumption that these topological features encode semantically corresponding structures across modalities. No mechanism is described to verify that matched edges reflect true cross-modal semantics rather than incidental connections among the limited labeled pairs, which is load-bearing for the central claim that ToMA outperforms pairwise methods.
- [Abstract] Abstract (method description): The paper states that ToMA 'leverages both H0-death edges and lightweight H1-birth edges... without constructing 2-simplices,' but provides no details on the filtration, distance metric, or exact procedure for extracting and aligning these edges on the representation manifolds. This omission makes it impossible to assess whether the alignment step actually enforces geometric consistency or merely matches edges that happen to connect paired points.
minor comments (1)
- [Abstract] Abstract: The phrases 'stable gains' and 'clear improvements' are used without accompanying quantitative values, baseline comparisons, or statistical tests, reducing clarity on the magnitude of the reported benefits.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing clarifications based on the full paper while revising the abstract to improve clarity and address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that aligning intra-modal H0-death and H1-birth edges 'through available cross-modal correspondences' improves downstream alignment rests on the unverified assumption that these topological features encode semantically corresponding structures across modalities. No mechanism is described to verify that matched edges reflect true cross-modal semantics rather than incidental connections among the limited labeled pairs, which is load-bearing for the central claim that ToMA outperforms pairwise methods.
Authors: We acknowledge that the abstract does not explicitly describe an independent verification mechanism (such as a dedicated semantic correspondence test) beyond the alignment procedure itself. The full manuscript supports the claim through quantitative experiments demonstrating stable gains on remote sensing datasets and consistent benefits on fashion retrieval, together with stability comparisons showing advantages over alternative topology-based objectives. These results indicate that alignment via labeled pairs captures more than incidental connections. To address the concern directly, we will revise the abstract to reference this empirical validation and clarify that the cross-modal correspondences serve as anchors for matching topologically salient edges. revision: yes
-
Referee: [Abstract] Abstract (method description): The paper states that ToMA 'leverages both H0-death edges and lightweight H1-birth edges... without constructing 2-simplices,' but provides no details on the filtration, distance metric, or exact procedure for extracting and aligning these edges on the representation manifolds. This omission makes it impossible to assess whether the alignment step actually enforces geometric consistency or merely matches edges that happen to connect paired points.
Authors: The abstract is intentionally high-level, but the full Methods section details the Vietoris-Rips filtration on the representation manifolds using Euclidean distance, the extraction of H0-death edges from the persistence diagram (corresponding to connectivity), and the computation of lightweight H1-birth edges via a simplified cycle-detection procedure that avoids explicit 2-simplex construction. Alignment then matches these intra-modal edges across modalities by leveraging the labeled image-text pairs as correspondence anchors. We will revise the abstract to concisely include these procedural elements so that readers can immediately assess the geometric intent of the alignment. revision: yes
Circularity Check
No circularity: method and claims are empirically grounded without self-referential reductions
full rationale
The paper proposes ToMA as a new objective that extracts H0-death and lightweight H1-birth edges via persistent homology on each modality separately, then aligns them using the available (limited) image-text pairs. No equations, derivations, or parameter-fitting steps are shown that reduce the claimed alignment gains or stability improvements to quantities defined in terms of themselves or to a fitted input renamed as a prediction. The central claims rest on external experimental validation across remote-sensing and fashion-retrieval benchmarks rather than on any self-citation chain, uniqueness theorem imported from the authors' prior work, or ansatz smuggled via citation. The derivation chain is therefore self-contained and independent of the target results.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agar- wal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PmLR, 2021
2021
-
[2]
Fine tuning clip with remote sensing (satellite) images and captions
Artashes Arutiunian, Dev Vidhani, Goutham V enkatesh, Mayank Bhaskar, Ritobrata Ghosh, and Sujit Pal. Fine tuning clip with remote sensing (satellite) images and captions. Hugging- Face Blog, 2021
2021
-
[3]
Bias-to-text: Debiasing unknown visual biases through language interpretation
Y ounghyun Kim, Sangwoo Mo, Minkyu Kim, Kyungmin Lee, Jaeho Lee, and Jinwoo Shin. Bias-to-text: Debiasing unknown visual biases through language interpretation. arXiv preprint arXiv:2301.11104, 2:1, 2023
-
[4]
S-clip: Semi-supervised vision- language learning using few specialist captions
Sangwoo Mo, Minkyu Kim, Kyungmin Lee, and Jinwoo Shin. S-clip: Semi-supervised vision- language learning using few specialist captions. Advances in Neural Information Processing Systems, 36:61187–61212, 2023
2023
-
[5]
Semi-supervised clip adaptation by enforcing semantic and trapezoidal consistency
Kai Gan, Bo Y e, Min-Ling Zhang, and Tong Wei. Semi-supervised clip adaptation by enforcing semantic and trapezoidal consistency. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[6]
Deep manifold learning com- bined with convolutional neural networks for action recognition
Xin Chen, Jian Weng, Wei Lu, Jiaming Xu, and Jiasi Weng. Deep manifold learning com- bined with convolutional neural networks for action recognition. IEEE transactions on neural networks and learning systems , 29(9):3938–3952, 2017
2017
-
[7]
Separability and geometry of object manifolds in deep neural networks
Uri Cohen, SueY eon Chung, Daniel D Lee, and Haim Sompolinsky. Separability and geometry of object manifolds in deep neural networks. Nature communications, 11(1):746, 2020
2020
-
[8]
Geometric deep learning: going beyond euclidean data
Michael M Bronstein, Joan Bruna, Y ann LeCun, Arthur Szlam, and Pierre V andergheynst. Geometric deep learning: going beyond euclidean data. IEEE Signal Processing Magazine, 34 (4):18–42, 2017
2017
-
[9]
Topological autoencoders,
Michael Moor, Max Horn, Bastian Rieck, and Karsten Borgwardt. Topological autoencoders,
-
[10]
URL https://openreview.net/forum?id=HkgtJRVFPS
-
[11]
Do topologi- cal characteristics help in knowledge distillation? In F orty-first International Conference on Machine Learning, 2024
Jungeun Kim, Junwon Y ou, Dongjin Lee, Ha Y oung Kim, and Jae-Hun Jung. Do topologi- cal characteristics help in knowledge distillation? In F orty-first International Conference on Machine Learning, 2024
2024
-
[12]
Persistence homology distillation for semi-supervised continual learning
Y an Fan, Y u Wang, Pengfei Zhu, Dongyue Chen, and Qinghua Hu. Persistence homology distillation for semi-supervised continual learning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems , 2024. URL https://openreview.net/forum? id=qInb7EUmxz
2024
-
[13]
Homology consistency constrained efficient tuning for vision-language models
Huatian Zhang, Lei Zhang, Y ongdong Zhang, and Zhendong Mao. Homology consistency constrained efficient tuning for vision-language models. Advances in Neural Information Pro- cessing Systems, 37:93011–93032, 2024
2024
-
[14]
Topological alignment of shared vision-language embedding space
Junwon Y ou, Kang Dasol, and Jae-Hun Jung. Topological alignment of shared vision-language embedding space. In The 29th International Conference on Artificial Intelligence and Statistics,
-
[15]
URL https://openreview.net/forum?id=ecd8cgWZr6
-
[16]
Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning
Victor Weixin Liang, Y uhui Zhang, Y ongchan Kwon, Serena Y eung, and James Y Zou. Mind the gap: Understanding the modality gap in multi-modal contrastive representation learning. Advances in Neural Information Processing Systems , 35:17612–17625, 2022
2022
-
[17]
Y onatan Gideoni, Y oav Gelberg, Tim G. J. Rudner, and Y arin Gal. Misalignment between vision-language representations in vision-language models. In UniReps: 3rd Edition of the Workshop on Unifying Representations in Neural Models, 2025. URL https://openreview. net/forum?id=jo2zpLRKMk. 10
2025
-
[18]
Position: The platonic representation hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. Position: The platonic representation hypothesis. In F orty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=BH8TYy0r6u
2024
-
[19]
Do vision and language encoders represent the world similarly? In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14334–14343, 2024
Mayug Maniparambil, Raiymbek Akshulakov, Y asser Abdelaziz Dahou Djilali, Mohamed El Amine Seddik, Sanath Narayan, Karttikeya Mangalam, and Noel E O’Connor. Do vision and language encoders represent the world similarly? In Proceedings of the IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, pages 14334–14343, 2024
2024
-
[20]
With limited data for multimodal alignment, let the STRUCTURE guide you
Fabian Gröger, Shuo Wen, Huyen Le, and Maria Brbic. With limited data for multimodal alignment, let the STRUCTURE guide you. In The Thirty-ninth Annual Conference on Neu- ral Information Processing Systems , 2025. URL https://openreview.net/forum?id= IkvQqD7hk3
2025
-
[21]
Sotal- ign: Semi-supervised alignment of unimodal vision and language models via optimal transport
Simon Roschmann, Paul Krzakala, Sonia Mazelet, Quentin Bouniot, and Zeynep Akata. Sotal- ign: Semi-supervised alignment of unimodal vision and language models via optimal transport. arXiv preprint arXiv:2602.23353, 2026
-
[22]
Topology and data
Gunnar Carlsson. Topology and data. Bulletin of the American Mathematical Society , 46(2): 255–308, 2009
2009
-
[23]
Exploring models and data for remote sensing image caption generation
Xiaoqiang Lu, Binqiang Wang, Xiangtao Zheng, and Xuelong Li. Exploring models and data for remote sensing image caption generation. IEEE Transactions on Geoscience and Remote Sensing, 56(4):2183–2195, 2017
2017
-
[24]
Bag-of-visual-words and spatial extensions for land-use clas- sification
Yi Y ang and Shawn Newsam. Bag-of-visual-words and spatial extensions for land-use clas- sification. In Proceedings of the 18th SIGSPATIAL international conference on advances in geographic information systems, pages 270–279, 2010
2010
-
[25]
Saliency-guided unsupervised feature learning for scene classification
Fan Zhang, Bo Du, and Liangpei Zhang. Saliency-guided unsupervised feature learning for scene classification. IEEE transactions on Geoscience and Remote Sensing , 53(4):2175–2184, 2014
2014
-
[26]
Automatic spatially-aware fashion concept discovery
Xintong Han, Zuxuan Wu, Phoenix X Huang, Xiao Zhang, Menglong Zhu, Y uan Li, Y ang Zhao, and Larry S Davis. Automatic spatially-aware fashion concept discovery. In Proceedings of the IEEE international conference on computer vision , pages 1463–1471, 2017
2017
-
[27]
Fashion-gen: The generative fashion dataset and challenge
Negar Rostamzadeh, Seyedarian Hosseini, Thomas Boquet, Wojciech Stokowiec, Ying Zhang, Christian Jauvin, and Chris Pal. Fashion-gen: The generative fashion dataset and challenge. arXiv preprint arXiv:1806.08317, 2018
-
[28]
Learning type-aware embeddings for fashion compatibility
Mariya I V asileva, Bryan A Plummer, Krishna Dusad, Shreya Rajpal, Ranjitha Kumar, and David Forsyth. Learning type-aware embeddings for fashion compatibility. In Proceedings of the European conference on computer vision (ECCV) , pages 390–405, 2018
2018
-
[29]
Scaling up visual and vision-language representation learning with noisy text supervision
Chao Jia, Yinfei Y ang, Y e Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Y un- Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning , pages 4904–4916. PMLR, 2021
2021
-
[30]
Combined scaling for zero-shot transfer learning
Hieu Pham, Zihang Dai, Golnaz Ghiasi, Kenji Kawaguchi, Hanxiao Liu, Adams Wei Y u, Jiahui Y u, Yi-Ting Chen, Minh-Thang Luong, Y onghui Wu, et al. Combined scaling for zero-shot transfer learning. Neurocomputing, 555:126658, 2023
2023
-
[31]
Nlip: Noise-robust language-image pre-training
Runhui Huang, Y anxin Long, Jianhua Han, Hang Xu, Xiwen Liang, Chunjing Xu, and Xi- aodan Liang. Nlip: Noise-robust language-image pre-training. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 37, pages 926–934, 2023
2023
-
[32]
Visualbert: A simple and perfor- 13 mant baseline for vision and language
Liunian Harold Li, Mark Y atskar, Da Yin, Cho-Jui Hsieh, and Kai-Wei Chang. Visualbert: A simple and performant baseline for vision and language. arXiv preprint arXiv:1908.03557 , 2019. 11
-
[33]
Uniter: Universal image-text representation learning
Y en-Chun Chen, Linjie Li, Licheng Y u, Ahmed El Kholy, Faisal Ahmed, Zhe Gan, Y u Cheng, and Jingjing Liu. Uniter: Universal image-text representation learning. In European confer- ence on computer vision , pages 104–120. Springer, 2020
2020
-
[34]
Vilt: Vision-and-language transformer without convolution or region supervision
Wonjae Kim, Bokyung Son, and Ildoo Kim. Vilt: Vision-and-language transformer without convolution or region supervision. In International conference on machine learning , pages 5583–5594. PMLR, 2021
2021
-
[35]
SimVLM: Simple visual language model pretraining with weak supervision
Zirui Wang, Jiahui Y u, Adams Wei Y u, Zihang Dai, Y ulia Tsvetkov, and Y uan Cao. SimVLM: Simple visual language model pretraining with weak supervision. In International Con- ference on Learning Representations , 2022. URL https://openreview.net/forum?id= GUrhfTuf_3
2022
-
[36]
Image as a foreign lan- guage: Beit pretraining for vision and vision-language tasks
Wenhui Wang, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggar- wal, Owais Khan Mohammed, Saksham Singhal, Subhojit Som, et al. Image as a foreign lan- guage: Beit pretraining for vision and vision-language tasks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19175–19186, 2023
2023
-
[37]
Lit: Zero-shot transfer with locked-image text tuning
Xiaohua Zhai, Xiao Wang, Basil Mustafa, Andreas Steiner, Daniel Keysers, Alexander Kolesnikov, and Lucas Beyer. Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 18123–18133, 2022
2022
-
[38]
Scaling language-image pre-training via masking
Y anghao Li, Haoqi Fan, Ronghang Hu, Christoph Feichtenhofer, and Kaiming He. Scaling language-image pre-training via masking. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 23390–23400, 2023
2023
-
[39]
Rs-clip: Zero shot remote sensing scene classification via contrastive vision-language supervision
Xiang Li, Congcong Wen, Y uan Hu, and Nan Zhou. Rs-clip: Zero shot remote sensing scene classification via contrastive vision-language supervision. International Journal of Applied Earth Observation and Geoinformation , 124:103497, 2023
2023
-
[40]
Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning
Huaishao Luo, Lei Ji, Ming Zhong, Y ang Chen, Wen Lei, Nan Duan, and Tianrui Li. Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning. Neurocomputing, 508:293–304, 2022
2022
-
[41]
Open-vocabulary object detection via vision and language knowledge distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, and Yin Cui. Open-vocabulary object detection via vision and language knowledge distillation. In International Conference on Learning Repre- sentations, 2022. URL https://openreview.net/forum?id=lL3lnMbR4WU
2022
-
[42]
A simple baseline for open-vocabulary semantic segmentation with pre-trained vision-language model
Mengde Xu, Zheng Zhang, Fangyun Wei, Y utong Lin, Y ue Cao, Han Hu, and Xiang Bai. A simple baseline for open-vocabulary semantic segmentation with pre-trained vision-language model. In European conference on computer vision , pages 736–753. Springer, 2022
2022
-
[43]
Few-shot parameter-efficient fine-tuning is better and cheaper than in- context learning
Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in- context learning. Advances in Neural Information Processing Systems , 35:1950–1965, 2022
1950
-
[44]
Medclip: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. Medclip: Contrastive learning from unpaired medical images and text. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , pages 3876–3887, 2022
2022
-
[45]
Learning by hallucinating: Vision-language pre-training with weak supervision
Tzu-Jui Julius Wang, Jorma Laaksonen, Tomas Langer, Heikki Arponen, and Tom E Bishop. Learning by hallucinating: Vision-language pre-training with weak supervision. In Proceed- ings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages 1073– 1083, 2023
2023
-
[46]
Toposrl: topology preserving self-supervised simplicial representation learning
Hiren Madhu and Sundeep Prabhakar Chepuri. Toposrl: topology preserving self-supervised simplicial representation learning. Advances in Neural Information Processing Systems , 36: 64306–64317, 2023
2023
-
[47]
Topogcl: Topological graph contrastive learning
Y uzhou Chen, Jose Frias, and Y ulia R Gel. Topogcl: Topological graph contrastive learning. In Proceedings of the AAAI conference on artificial intelligence , volume 38, pages 11453–11461, 2024. 12
2024
-
[48]
Principle component trees and their persistent ho- mology
Ben Kizaric and Daniel Pimentel-Alarcón. Principle component trees and their persistent ho- mology. In Proceedings of the AAAI Conference on Artificial Intelligence , volume 38, pages 13220–13229, 2024
2024
-
[49]
Deep regression representation learning with topology
Shihao Zhang, Kenji Kawaguchi, and Angela Y ao. Deep regression representation learning with topology. In F orty-first International Conference on Machine Learning , 2024. URL https://openreview.net/forum?id=HbdeEGVfEN
2024
-
[50]
Position: Topological deep learning is the new frontier for relational learning
Theodore Papamarkou, Tolga Birdal, Michael Bronstein, Gunnar Carlsson, Justin Curry, Y ue Gao, Mustafa Hajij, Roland Kwitt, Pietro Lio, Paolo Di Lorenzo, et al. Position: Topological deep learning is the new frontier for relational learning. Proceedings of machine learning research, 235:39529, 2024
2024
-
[51]
Bronstein, and Hag- gai Maron
Y am Eitan, Y oav Gelberg, Guy Bar-Shalom, Fabrizio Frasca, Michael M. Bronstein, and Hag- gai Maron. Topological blindspots: Understanding and extending topological deep learning through the lens of expressivity. In The Thirteenth International Conference on Learning Rep- resentations, 2025. URL https://openreview.net/forum?id=EzjsoomYEb
2025
-
[52]
Towards scalable topological regularizers
Wong Hiu Tung, Darrick Lee, and Hong Y an. Towards scalable topological regularizers. In The Thirteenth International Conference on Learning Representations , 2025. URL https: //openreview.net/forum?id=FjZcwQJX8D
2025
-
[53]
Phlp: Sole persistent homology for link predic- tion - interpretable feature extraction
Junwon Y ou, Eunwoo Heo, and Jae-Hun Jung. Phlp: Sole persistent homology for link predic- tion - interpretable feature extraction. Neurocomputing, 665:132147, 2026. ISSN 0925-2312. doi: https://doi.org/10.1016/j.neucom.2025.132147. URL https://www.sciencedirect. com/science/article/pii/S092523122502819X
-
[54]
Persistence-based topo- logical optimization: a survey
Mathieu Carriere, Y uichi Ike, Théo Lacombe, and Naoki Nishikawa. Persistence-based topo- logical optimization: a survey. arXiv preprint arXiv:2603.24613, 2026
-
[55]
Learning topology-preserving data representations
Ilya Trofimov, Daniil Cherniavskii, Eduard Tulchinskii, Nikita Balabin, Evgeny Burnaev, and Serguei Barannikov. Learning topology-preserving data representations. In The Eleventh Inter- national Conference on Learning Representations , 2023. URL https://openreview.net/ forum?id=lIu-ixf-Tzf
2023
-
[56]
Representation topol- ogy divergence: A method for comparing neural network representations
Serguei Barannikov, Ilya Trofimov, Nikita Balabin, and Evgeny Burnaev. Representation topol- ogy divergence: A method for comparing neural network representations. arXiv preprint arXiv:2201.00058, 2021
-
[57]
Computational topology for data analysis
Tamal Krishna Dey and Y usu Wang. Computational topology for data analysis . Cambridge University Press, 2022
2022
-
[58]
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks
Dong-Hyun Lee et al. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Workshop on challenges in representation learning, ICML , vol- ume 3, page 896. Atlanta, 2013
2013
-
[59]
Semi-supervised learning of visual features by non-parametrically predicting view assignments with support samples
Mahmoud Assran, Mathilde Caron, Ishan Misra, Piotr Bojanowski, Armand Joulin, Nicolas Ballas, and Michael Rabbat. Semi-supervised learning of visual features by non-parametrically predicting view assignments with support samples. In Proceedings of the IEEE/CVF interna- tional conference on computer vision , pages 8443–8452, 2021
2021
-
[60]
Remote sensing image scene classification: Benchmark and state of the art
Gong Cheng, Junwei Han, and Xiaoqiang Lu. Remote sensing image scene classification: Benchmark and state of the art. Proceedings of the IEEE , 105(10):1865–1883, 2017
2017
-
[61]
Struc- tural high-resolution satellite image indexing
Gui-Song Xia, Wen Y ang, Julie Delon, Y ann Gousseau, Hong Sun, and Henri Maître. Struc- tural high-resolution satellite image indexing. In ISPRS TC VII Symposium-100 Years ISPRS , volume 38, pages 298–303, 2010
2010
-
[62]
Deep learning based feature selection for remote sensing scene classification
Qin Zou, Lihao Ni, Tong Zhang, and Qian Wang. Deep learning based feature selection for remote sensing scene classification. IEEE Geoscience and remote sensing letters, 12(11):2321– 2325, 2015. 13
2015
-
[63]
Aid: A benchmark data set for performance evaluation of aerial scene classification
Gui-Song Xia, Jingwen Hu, Fan Hu, Baoguang Shi, Xiang Bai, Y anfei Zhong, Liangpei Zhang, and Xiaoqiang Lu. Aid: A benchmark data set for performance evaluation of aerial scene classification. IEEE Transactions on Geoscience and Remote Sensing, 55(7):3965–3981, 2017
2017
-
[64]
Fixmatch: Simplifying semi- supervised learning with consistency and confidence
Kihyuk Sohn, David Berthelot, Nicholas Carlini, Zizhao Zhang, Han Zhang, Colin A Raf- fel, Ekin Dogus Cubuk, Alexey Kurakin, and Chun-Liang Li. Fixmatch: Simplifying semi- supervised learning with consistency and confidence. Advances in neural information process- ing systems, 33:596–608, 2020
2020
-
[65]
Scicap: Generating captions for scientific figures
Ting-Y ao Hsu, C Lee Giles, and Ting-Hao Huang. Scicap: Generating captions for scientific figures. In Findings of the Association for Computational Linguistics: EMNLP 2021 , pages 3258–3264, 2021
2021
-
[66]
Simpsons blip captions
Doron Adler. Simpsons blip captions. https://huggingface.co/datasets/Norod78/ simpsons-blip-captions , 2023. 14 Appendix A Qualitative Analysis 16 A.1 Illustrative Example of ToMA with the Embeddings in Figure 2b . . . . . . . . . 16 A.2 Additional Examples of 0 and 1-Dimensional Edges . . . . . . . . . . . . . . . . . 17 B Limitations and Broader Impacts...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.