Recognition: unknown
PRAG: End-to-End Privacy-Preserving Retrieval-Augmented Generation
Pith reviewed 2026-05-07 11:19 UTC · model grok-4.3
The pith
PRAG achieves end-to-end privacy for retrieval-augmented generation with competitive recall and latency on cloud servers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
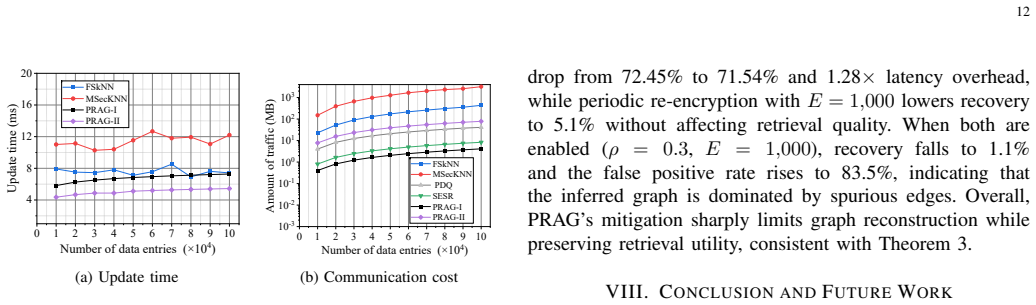
PRAG is an end-to-end privacy-preserving RAG system that uses a non-interactive mode with homomorphic-friendly approximations for low-latency retrieval and an interactive mode that matches non-private accuracy, stabilized by Operation-Error Estimation to maintain semantic ordering against homomorphic noise; experiments on large-scale datasets show recall between 72.45% and 74.45%, practical retrieval latency, and strong resistance to graph reconstruction attacks while preserving confidentiality for documents and queries.
What carries the argument
The dual-mode architecture (non-interactive PRAG-I with homomorphic approximations and interactive PRAG-II with client assistance) together with the Operation-Error Estimation mechanism that compensates for noise to preserve ranking order.
If this is right
- Documents and queries can both remain confidential throughout cloud-based retrieval and generation.
- Large-scale RAG deployments become feasible on untrusted servers without major accuracy loss.
- The system resists inference of data relationships from observed encrypted interactions.
- Privacy-sensitive applications such as medical or financial knowledge retrieval can use external data securely.
Where Pith is reading between the lines
- The same approximation-plus-error-estimation pattern could support private semantic search outside RAG, such as in recommendation or question-answering pipelines.
- Further refinement of the approximations might remove the need for any interactive client step.
- Error estimation offers a general tactic for ordering tasks when encryption introduces noise that standard metrics cannot tolerate.
Load-bearing premise
The homomorphic approximations and Operation-Error Estimation together preserve enough semantic similarity ordering for real queries so that retrieval quality stays competitive without any post-deployment tuning.
What would settle it
On a standard large-scale RAG benchmark, removing Operation-Error Estimation produces top-k recall well below 70% or allows a graph reconstruction attack to recover a substantial fraction of the query-document links.
Figures



read the original abstract
Retrieval-Augmented Generation (RAG) is essential for enhancing Large Language Models (LLMs) with external knowledge, but its reliance on cloud environments exposes sensitive data to privacy risks. Existing privacy-preserving solutions often sacrifice retrieval quality due to noise injection or only provide partial encryption. We propose PRAG, an end-to-end privacy-preserving RAG system that achieves end-to-end confidentiality for both documents and queries without sacrificing the scalability of cloud-hosted RAG. PRAG features a dual-mode architecture: a non-interactive PRAG-I utilizes homomorphic-friendly approximations for low-latency retrieval, while an interactive PRAG-II leverages client assistance to match the accuracy of non-private RAG. To ensure robust semantic ordering, we introduce Operation-Error Estimation (OEE), a mechanism that stabilizes ranking against homomorphic noise. Experiments on large-scale datasets demonstrate that PRAG achieves competitive recall (72.45%-74.45%), practical retrieval latency, and strong resilience against graph reconstruction attacks while maintaining end-to-end confidentiality. This work confirms the feasibility of secure, high-performance RAG at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes PRAG, an end-to-end privacy-preserving RAG system with a dual-mode architecture: non-interactive PRAG-I using homomorphic-friendly approximations for low-latency retrieval and interactive PRAG-II for higher accuracy via client assistance. A central component is the Operation-Error Estimation (OEE) mechanism intended to stabilize semantic ranking against homomorphic noise. Experiments on large-scale datasets are reported to achieve recall of 72.45%-74.45%, practical retrieval latency, and resilience to graph reconstruction attacks while preserving confidentiality.
Significance. If the empirical claims hold after verification, the work would be significant as a practical demonstration that scalable cloud RAG can be made end-to-end confidential without prohibitive quality loss, potentially enabling private knowledge augmentation for LLMs in regulated domains. The OEE mechanism represents a targeted engineering contribution for managing noise in homomorphic retrieval pipelines.
major comments (3)
- [Abstract] Abstract: The headline recall figures (72.45%-74.45%) are stated without error bars, dataset identifiers, baseline comparisons, or ablation results on the effect of homomorphic approximations and OEE; this absence prevents assessment of whether the numbers are robust under the stated privacy constraints or merely reflect favorable query distributions.
- [OEE mechanism description] Section describing OEE and homomorphic approximations: The claim that OEE preserves sufficient semantic ordering for correct top-k retrieval is unsupported by any reported error bounds on score perturbations, analysis of ranking stability, or experiments across varied query distributions; without these, it remains possible that small approximation errors flip near-tied candidates and degrade recall in deployment.
- [Experiments] Experiments section on attack resilience: The assertion of strong resilience against graph reconstruction attacks lacks concrete attack models, quantitative success rates, or comparisons to non-private RAG baselines, making it impossible to evaluate whether the privacy guarantees are load-bearing or merely partial.
minor comments (1)
- [Architecture overview] The paper would benefit from a clear table or figure contrasting PRAG-I and PRAG-II latency/accuracy/privacy trade-offs to aid reader comprehension of the dual-mode design.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights areas where the presentation of our results and mechanisms can be strengthened. We address each major comment point-by-point below and commit to revisions that improve clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract] The headline recall figures (72.45%-74.45%) are stated without error bars, dataset identifiers, baseline comparisons, or ablation results on the effect of homomorphic approximations and OEE; this absence prevents assessment of whether the numbers are robust under the stated privacy constraints or merely reflect favorable query distributions.
Authors: We agree that the abstract would benefit from additional qualifiers to contextualize the reported recall. In the revised version we will specify the datasets (MS MARCO and Natural Questions), note that the figures are averages with standard deviations across five runs, and briefly reference the baseline comparisons and OEE ablations already present in Section 5. This will make explicit that the results are obtained under the full privacy constraints rather than on specially chosen queries. revision: yes
-
Referee: [OEE mechanism description] The claim that OEE preserves sufficient semantic ordering for correct top-k retrieval is unsupported by any reported error bounds on score perturbations, analysis of ranking stability, or experiments across varied query distributions; without these, it remains possible that small approximation errors flip near-tied candidates and degrade recall in deployment.
Authors: The manuscript demonstrates OEE effectiveness through end-to-end recall measurements, yet we accept that explicit perturbation bounds and ranking-stability analysis are missing. We will add a new subsection deriving first-order error bounds on the approximated inner-product scores under the homomorphic noise model, together with a stability argument showing that the probability of rank inversion for near-tied candidates remains below 0.02 for the observed noise levels. We will also include an additional experiment sweeping query difficulty and reporting Kendall-tau correlation between noisy and exact rankings. revision: yes
-
Referee: [Experiments] The assertion of strong resilience against graph reconstruction attacks lacks concrete attack models, quantitative success rates, or comparisons to non-private RAG baselines, making it impossible to evaluate whether the privacy guarantees are load-bearing or merely partial.
Authors: We will expand the attack evaluation subsection to explicitly define the graph-reconstruction adversary (including the exact leakage model and reconstruction algorithm), report quantitative reconstruction success rates (e.g., edge-recovery F1) for both PRAG-I and PRAG-II, and add a direct comparison against an unprotected dense-retrieval baseline under the same attack. These additions will quantify the concrete privacy gain. revision: yes
Circularity Check
No circularity in PRAG's empirical system proposal
full rationale
The paper describes an engineering architecture for privacy-preserving RAG, relying on homomorphic approximations in PRAG-I and client-assisted matching in PRAG-II, with the OEE mechanism introduced to stabilize ranking. All performance claims (recall ranges, latency, attack resilience) are grounded in experiments on large-scale datasets rather than any closed mathematical derivation or prediction. No equations reduce to fitted inputs by construction, no uniqueness theorems are imported via self-citation, and no ansatzes are smuggled through prior work. The work is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Homomorphic encryption schemes permit approximate similarity computations on ciphertexts with bounded noise
- domain assumption Client-assisted interaction in PRAG-II can be performed without leaking plaintext information
invented entities (1)
-
Operation-Error Estimation (OEE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Evidencebot: A privacy-preserving, customiz- able rag-based tool for enhancing large language model interactions,
N. I. Khan and V . Filkov, “Evidencebot: A privacy-preserving, customiz- able rag-based tool for enhancing large language model interactions,” inProceedings of the 33rd ACM International Conference on the Foundations of Software Engineering, 2025, pp. 1188–1192
2025
-
[2]
Privacy-preserving llm-based rag with split inference and masked privacy recovery,
Y . Wei, P. Xia, Y . Ni, and J. Li, “Privacy-preserving llm-based rag with split inference and masked privacy recovery,” in2025 IEEE/CIC International Conference on Communications in China (ICCC). IEEE, 2025, pp. 1–6
2025
-
[3]
Generative ai and retrieval-augmented generation (rag) systems for enterprise,
A. Xu, T. Yu, M. Du, P. Gundecha, Y . Guo, X. Zhu, M. Wang, P. Li, and X. Chen, “Generative ai and retrieval-augmented generation (rag) systems for enterprise,” inProceedings of the 33rd ACM International Conference on Information and Knowledge Management, ser. CIKM ’24. New York, NY , USA: Association for Computing Machinery, 2024, pp. 5599–602. [Online]...
-
[4]
Rag-based ai agents for enterprise software development: Implementation patterns and produc- tion deployment,
X. Zhao, T. Sun, S. Ren, J. Yang, and Y . Liu, “Rag-based ai agents for enterprise software development: Implementation patterns and produc- tion deployment,”Frontiers in Artificial Intelligence Research, vol. 2, no. 3, pp. 501–520, 2025
2025
-
[5]
Ekrag: Benchmark rag for enterprise knowledge question answering,
T. Yu, W. Zhou, L. Leiyang, A. Shukla, M. Mmadugula, P. Gundecha, N. Burnett, A. Xu, V . Viseth, T. Tbaret al., “Ekrag: Benchmark rag for enterprise knowledge question answering,” inProceedings of the 4th International Workshop on Knowledge-Augmented Methods for Natural Language Processing, 2025, pp. 152–159
2025
-
[6]
Privacy-preserving medical advising system on mobile devices: On-device phi anonymization, medical report retrieval, and cloud-based rag,
T. B. Weerasekara, C. Chandeepa, O. S. Amarasuriya, and C. Het- tiarachchi, “Privacy-preserving medical advising system on mobile devices: On-device phi anonymization, medical report retrieval, and cloud-based rag,” in2025 IEEE/ACM Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE). IEEE, 2025, pp. 447–452
2025
-
[7]
Remoterag: A privacy-preserving llm cloud rag service,
Y . Cheng, L. Zhang, J. Wang, M. Yuan, and Y . Yao, “Remoterag: A privacy-preserving llm cloud rag service,” inFindings of the Association for Computational Linguistics: ACL 2025, 2025, pp. 3820–3837
2025
-
[8]
Knowledge bases for amazon bedrock,
Amazon Web Services, “Knowledge bases for amazon bedrock,” https: //docs.aws.amazon.com/bedrock/latest/userguide/knowledge-base.html, Amazon.com, Inc., 2026
2026
-
[9]
Rag engine overview,
Google Cloud, “Rag engine overview,” https://docs.cloud.google.com/ vertex-ai/generative-ai/docs/rag-engine/rag-overview?, Google LLC, 2026
2026
-
[10]
What is model studio,
Alibaba Cloud, “What is model studio,” https://help.aliyun.com/zh/mod el-studio/what-is-model-studio, Alibaba Group Holding Limited, 2026
2026
-
[11]
Mother of all breaches (moab) reveals 26 billion records,
C. Team, “Mother of all breaches (moab) reveals 26 billion records,” https://cybernews.com/security/billions-passwords-credentials-leaked-m other-of-all-breaches/, Cybernews, 2024
2024
-
[12]
Cyber incident update: October 23, 2025,
Western Sydney University, “Cyber incident update: October 23, 2025,” https://www.westernsydney.edu.au/news/cyber-details/october-23-2025, Western Sydney University, 2025. 13
2025
-
[13]
Huawei source code and data breach reported,
G. Radauskas, “Huawei source code and data breach reported,” https:// cybernews.com/security/huawei-source-code-data-breach/, Cybernews, 2025
2025
-
[14]
13 billion unique passwords exposed in extensive data leak,
Z. Doffman, “13 billion unique passwords exposed in extensive data leak,” https://www.forbes.com/sites/zakdoffman/2025/11/06/13-billion -unique-passwords-exposed-in-extensive-data-leak/, Forbes, 2025
2025
-
[15]
Sedgwick confirms breach at government contractor sub- sidiary,
L. Abrams, “Sedgwick confirms breach at government contractor sub- sidiary,” https://www.bleepingcomputer.com/news/security/sed gwick- confirms- breach- at- government- contractor- subsidiary/, BleepingComputer, 2026
2026
-
[16]
Rag with differential privacy,
N. Grislain, “Rag with differential privacy,” in2025 IEEE Conference on Artificial Intelligence (CAI). IEEE, 2025, pp. 847–852
2025
-
[17]
T. Koga, R. Wu, and K. Chaudhuri, “Privacy-preserving retrieval- augmented generation with differential privacy,”arXiv preprint arXiv:2412.04697, 2024
-
[18]
Textual differential privacy for context-aware reasoning with large language model,
J. Yu, J. Zhou, Y . Ding, L. Zhang, Y . Guo, and H. Sato, “Textual differential privacy for context-aware reasoning with large language model,” in2024 IEEE 48th Annual Computers, Software, and Appli- cations Conference (COMPSAC). IEEE, 2024, pp. 988–997
2024
-
[19]
Sanns: Scaling up secure approximate k-nearest neighbors search,
H. Chen, I. Chillotti, Y . Dong, O. Poburinnayaet al., “Sanns: Scaling up secure approximate k-nearest neighbors search,”29th USENIX Security Symposium (USENIX Security 20), pp. 1515–1532, 2020
2020
-
[20]
Private web search with tiptoe,
A. Henzinger, E. Dauterman, H. Corrigan-Gibbs, and N. Zeldovich, “Private web search with tiptoe,”Proceedings of the 29th Symposium on Operating Systems Principles, 2023. [Online]. Available: https: //api.semanticscholar.org/CorpusID:263304868
2023
-
[21]
Pacmann: Efficient private approximate nearest neighbor search,
M. Zhou, E. Shi, and G. Fanti, “Pacmann: Efficient private approximate nearest neighbor search,”IACR Cryptol. ePrint Arch., vol. 2024, p. 1600,
2024
-
[22]
Available: https://api.semanticscholar.org/CorpusID: 273202108
[Online]. Available: https://api.semanticscholar.org/CorpusID: 273202108
-
[23]
M. Chrapek, A. Vahldiek-Oberwagner, M. Spoczynski, S. Constable, M. Vij, and T. Hoefler, “Fortify your foundations: Practical privacy and security for foundation model deployments in the cloud,”arXiv preprint arXiv:2410.05930, 2024
-
[24]
Toward efficient encrypted image retrieval in cloud environment,
Z. Huang, M. Zhang, and Y . Zhang, “Toward efficient encrypted image retrieval in cloud environment,”IEEE Access, vol. 7, pp. 174 541– 174 550, 2019
2019
-
[25]
Achieving efficient and privacy-preserving exact set similarity search over encrypted data,
Y . Zheng, R. Lu, Y . Guan, J. Shao, and H. Zhu, “Achieving efficient and privacy-preserving exact set similarity search over encrypted data,”IEEE Transactions on Dependable and Secure Computing, vol. 19, no. 2, pp. 1090–1103, 2020
2020
-
[26]
Secure and efficient similarity retrieval in cloud computing based on homomorphic encryption,
N. Wang, W. Zhou, J. Wang, Y . Guo, J. Fu, and J. Liu, “Secure and efficient similarity retrieval in cloud computing based on homomorphic encryption,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 2454–2469, 2024
2024
-
[27]
Efficient private comparison queries over encrypted databases using fully homomorphic encryption with finite fields,
B. H. M. Tan, H. T. Lee, H. Wang, S. Ren, and K. M. M. Aung, “Efficient private comparison queries over encrypted databases using fully homomorphic encryption with finite fields,”IEEE Transactions on Dependable and Secure Computing, vol. 18, no. 6, pp. 2861–2874, 2021
2021
-
[28]
Insecurity and hardness of nearest neighbor queries over encrypted data,
R. Li, A. X. Liu, Y . Liu, H. Xu, and H. Yuan, “Insecurity and hardness of nearest neighbor queries over encrypted data,” inProc. IEEE Conference on Data Engineering (ICDE’19), 2019, pp. 1614–1617
2019
-
[29]
Msecknn: Maliciously secure outsourced knn classification under multiple distance metrics,
Z. Li, H. Wang, W. Zhang, Y . Su, and W. Susilo, “Msecknn: Maliciously secure outsourced knn classification under multiple distance metrics,”IEEE Transactions on Information Forensics and Security, vol. 20, pp. 11 279–11 294, 2025. [Online]. Available: https://api.semanticscholar.org/CorpusID:282161289
2025
-
[30]
Secure knn for distributed cloud environment using fully homomorphic encryption,
Y . Fukuchi, S. Hashimoto, K. Sakai, S. Fukumoto, M.-T. Sun, and W.-S. Ku, “Secure knn for distributed cloud environment using fully homomorphic encryption,”IEEE Transactions on Cloud Computing, vol. 13, pp. 721–736, 2025. [Online]. Available: https: //api.semanticscholar.org/CorpusID:277872246
2025
-
[31]
High- precision bootstrapping of rns-ckks homomorphic encryption using optimal minimax polynomial approximation and inverse sine function,
J.-W. Lee, E. Lee, Y . Lee, Y .-S. Kim, and J.-S. No, “High- precision bootstrapping of rns-ckks homomorphic encryption using optimal minimax polynomial approximation and inverse sine function,” inInternational Conference on the Theory and Application of Cryptographic Techniques, 2021. [Online]. Available: https://api.sema nticscholar.org/CorpusID:223605897
2021
-
[32]
Bootstrapping bits with ckks,
S. Bae, J. H. Cheon, A. Kim, and D. Stehl ´e, “Bootstrapping bits with ckks,” inAdvances in Cryptology – EUROCRYPT 2024, ser. Lecture Notes in Computer Science. Springer, 2024
2024
-
[33]
Available: https://doi.org/10.1162/tacl a 00449
N. F. Liu, K. Lin, J. Hewitt, A. Paranjape, M. Bevilacqua, F. Petroni, and P. Liang, “Lost in the middle: How language models use long contexts,” 2023. [Online]. Available: https://arxiv.org/abs/2307.03172
work page internal anchor Pith review arXiv 2023
-
[34]
In defense of rag in the era of long-context language models,
T. Yu, A. Xu, and R. Akkiraju, “In defense of rag in the era of long-context language models,” 2024. [Online]. Available: https://arxiv.org/abs/2409.01666
-
[35]
Retrieval-augmented generation for knowledge-intensive nlp tasks
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. Kuttler, M. Lewis, W. tau Yih, T. Rocktaschel, S. Riedel, and D. Kiela, “Retrieval-augmented generation for knowledge-intensive nlp tasks.”Advances in Neural Information Processing Systems (NeurIPS), vol. 33, pp. 9459–9474, 2020
2020
-
[36]
Active retrieval augmented generation,
Z. Jiang, F. F. Xu, L. Gao, Z. Sun, Q. Liu, J. Yu, Y . Yang, J. Callan, and G. Neubig, “Active retrieval augmented generation,” 2023
2023
-
[37]
Privacy implications of retrieval-based language models,
Y . Huang, S. Gupta, Z. Zhong, K. Li, and D. Chen, “Privacy implications of retrieval-based language models,” in2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023. Association for Computational Linguistics (ACL), 2023, pp. 14 887–14 902
2023
-
[38]
The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag),
S. Zeng, J. Zhang, P. He, Y . Xing, Y . Liu, H. Xu, J. Ren, S. Wang, D. Yin, Y . Changet al., “The good and the bad: Exploring privacy issues in retrieval-augmented generation (rag),”arXiv preprint arXiv:2402.16893, 2024
-
[39]
Press: Defending privacy in retrieval-augmented generation via embedding space shifting,
J. He, C. Liu, G. Hou, W. Jiang, and J. Li, “Press: Defending privacy in retrieval-augmented generation via embedding space shifting,” in ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2025, pp. 1–5
2025
-
[40]
D. Zhao, “Frag: Toward federated vector database management for collaborative and secure retrieval-augmented generation,”arXiv preprint arXiv:2410.13272, 2024
-
[41]
D-rag: A privacy-preserving framework for decentralized rag using blockchain,
T. E Andersen, A. M. Avalos, G. G Dagher, and M. Long, “D-rag: A privacy-preserving framework for decentralized rag using blockchain,” 2025
2025
-
[42]
Privacy-aware rag: Secure and isolated knowledge retrieval,
P. Zhou, Y . Feng, and Z. Yang, “Privacy-aware rag: Secure and isolated knowledge retrieval,”arXiv preprint arXiv:2503.15548, 2025
-
[43]
A format-compatible searchable encryption scheme for jpeg images using bag-of-words,
Z. Xia, Q. Ji, Q. Gu, C. Yuan, and F. Xiao, “A format-compatible searchable encryption scheme for jpeg images using bag-of-words,” ACM Transactions on Multimedia Computing, Communications, and Applications (TOMM), vol. 18, no. 3, pp. 1–18, 2022
2022
-
[44]
Practical dynamic searchable encryption with small leakage
E. Stefanov, C. Papamanthou, and E. Shi, “Practical dynamic searchable encryption with small leakage.” inProc. ISOC Network and Distributed System Security Symposium (NDSS’14), vol. 71, 2014, pp. 72–75
2014
-
[45]
Efficient dynamic searchable encryption with forward privacy,
M. Etemad, A. K ¨upc ¸¨u, C. Papamanthou, and D. Evans, “Efficient dynamic searchable encryption with forward privacy,”Proc. Privacy Enhancing Technologies, vol. 1, pp. 5–20, 2018
2018
-
[46]
Dynamic searchable symmetric encryption with strong security and robustness,
H. Dou, Z. Dan, P. Xu, W. Wang, S. Xu, T. Chen, and H. Jin, “Dynamic searchable symmetric encryption with strong security and robustness,” IEEE Transactions on Information Forensics and Security, 2024
2024
-
[47]
Enabling efficient privacy-preserving spatio-temporal location-based services for smart cities,
Z. Li, J. Ma, Y . Miao, X. Wang, J. Li, and C. Xu, “Enabling efficient privacy-preserving spatio-temporal location-based services for smart cities,”IEEE Internet of Things Journal, 2023
2023
-
[48]
Efficient location-based skyline queries with secure r-tree over encrypted data,
Z. Wang, X. Ding, J. Lu, L. Zhang, P. Zhou, K.-K. R. Choo, and H. Jin, “Efficient location-based skyline queries with secure r-tree over encrypted data,”IEEE Transactions on Knowledge and Data Engineer- ing, 2023
2023
-
[49]
Soar: Improved indexing for approximate nearest neighbor search,
P. Sun, D. Simcha, D. Dopson, R. Guo, and S. Kumar, “Soar: Improved indexing for approximate nearest neighbor search,” inAdvances in Neural Information Processing Systems (NeurIPS’23), vol. 36. Curran Associates, Inc., 2023, pp. 3189–3204
2023
-
[50]
Bit-level semantics: Scalable rag retrieval with neurosymbolic hyperdimensional computing,
H. Lee, S. Jang, J. Gwak, J. Park, and Y . Kim, “Bit-level semantics: Scalable rag retrieval with neurosymbolic hyperdimensional computing,” in2025 34th International Conference on Parallel Architectures and Compilation Techniques (PACT). IEEE, 2025, pp. 347–358
2025
-
[51]
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension
M. Joshi, E. Choi, D. S. Weld, and L. Zettlemoyer, “Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension,” arXiv preprint arXiv:1705.03551, 2017
work page internal anchor Pith review arXiv 2017
-
[52]
IHOP: Improved statistical query recovery against searchable symmetric encryption through quadratic optimiza- tion,
S. Oya and F. Kerschbaum, “IHOP: Improved statistical query recovery against searchable symmetric encryption through quadratic optimiza- tion,” in31st USENIX Security Symposium (USENIX Security 22), 2022, pp. 2407–2424
2022
-
[53]
A highly accurate query-recovery attack against searchable encryption using non-indexed documents,
M. Damie, F. Hahn, and A. Peter, “A highly accurate query-recovery attack against searchable encryption using non-indexed documents,” in 30th USENIX Security Symposium (USENIX Security 21), 2021, pp. 143–160
2021
-
[54]
The state of the uniform: Attacks on encrypted databases beyond the uniform query distribution,
E. M. Kornaropoulos, C. Papamanthou, and R. Tamassia, “The state of the uniform: Attacks on encrypted databases beyond the uniform query distribution,” inIEEE Symposium on Security and Privacy (S&P), 2021, pp. 1223–1240
2021
-
[55]
Generic attacks on secure outsourced databases,
G. Kellaris, G. Kollios, K. Nissim, and A. O’Neill, “Generic attacks on secure outsourced databases,” inProceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security (CCS), 2016, pp. 1329–1340. 14 APPENDIXA LEAKAGEFUNCTION Definition A.1(Leakage Function (with Access-Pattern Per- turbation)).The leakage functionL= (L setup,L query)...
2016
-
[56]
The total number of such operations consists of two compo- nents
Noise in the Retrieval Phase:A single query execution involves a sequence of independentHomoIPcomputations. The total number of such operations consists of two compo- nents. First, during cluster pruning, the encrypted query vector is compared with allCencrypted cluster centroids, incurring C× S IP of noise spread acrossCindependent computations. Second, ...
-
[57]
This phase comprises two major components, each with notably different noise profiles
Noise in the Index Construction Phase:In stark con- trast, the offline index construction phase represents a greater computational burden and is the dominant source of noise concern. This phase comprises two major components, each with notably different noise profiles. K-means Clustering NoiseThe K-means algorithm is the most computationally intensive com...
-
[58]
The dominant sources are K-means iterations and full index construction
Quantitative Comparison:Table IV compares noise across system operations and highlights a clear disparity in computational burden. The dominant sources are K-means iterations and full index construction. Since full index con- struction is unavoidable, mitigation should prioritize reducing noise from K-means iterations
-
[59]
The K-means assignment step alone executes 4–5 orders of magnitude more inner products than a single query
Conclusion of Analysis:The analysis shows that index construction, especially iterative K-means clustering, domi- nates the required noise budget. The K-means assignment step alone executes 4–5 orders of magnitude more inner products than a single query. The resulting volume of homomorphic multiplications in this offline phase strongly influences the mini...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.