Recognition: unknown
Sparse-on-Dense: Area and Energy-Efficient Computing of Sparse Neural Networks on Dense Matrix Multiplication Accelerators
Pith reviewed 2026-05-07 12:31 UTC · model grok-4.3
The pith
Allocating fixed chip area to more dense processing elements outperforms specialized sparse hardware for pruned neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Given a fixed area budget, deploying a larger number of dense processing elements on standard matrix-multiplication accelerators yields higher performance and lower energy consumption for sparse neural networks than an equivalent-area design using fewer sparse PEs whose index-matching circuits add substantial area and power overhead.
What carries the argument
Sparse-on-Dense, a software mapping technique that schedules sparse matrix multiplications onto dense PE arrays by managing zero elements at the software level rather than in hardware.
If this is right
- Hardware designers can achieve competitive or superior efficiency for sparse workloads by scaling the number of simple dense PEs rather than adding sparsity-specific logic.
- Software mapping and scheduling become the primary levers for extracting performance from pruned networks on dense accelerators.
- Energy efficiency improves because simpler PEs have lower power per unit area even at reduced utilization.
- The approach remains viable as pruning ratios increase, because the relative cost of index-matching hardware grows while dense-PE density stays constant.
Where Pith is reading between the lines
- Accelerator roadmaps may shift emphasis from custom sparse datapaths toward high-density dense arrays paired with compiler support for irregular data.
- Edge and mobile devices with tight area constraints could adopt this strategy to reduce both silicon cost and power without sacrificing pruned-network accuracy.
- Similar area-utilization trade-offs could be examined for other sparse linear-algebra workloads beyond neural networks, such as graph processing or scientific computing kernels.
Load-bearing premise
The area and power overhead of index-matching circuits in sparse PEs is large enough that it exceeds the performance penalty from lower utilization when the same area is instead used for more dense PEs.
What would settle it
A side-by-side measurement of area, power, throughput, and energy on the same process node for an equivalent-area Sparse-on-Dense dense-PE array versus a sparse-PE accelerator, both running identical pruned DNN models such as pruned ResNet or MobileNet.
Figures









read the original abstract
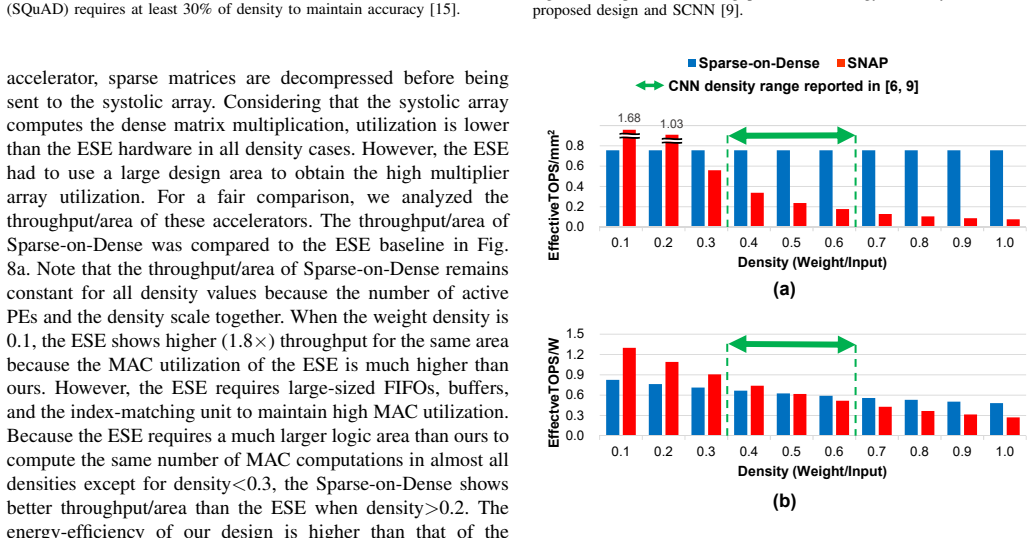
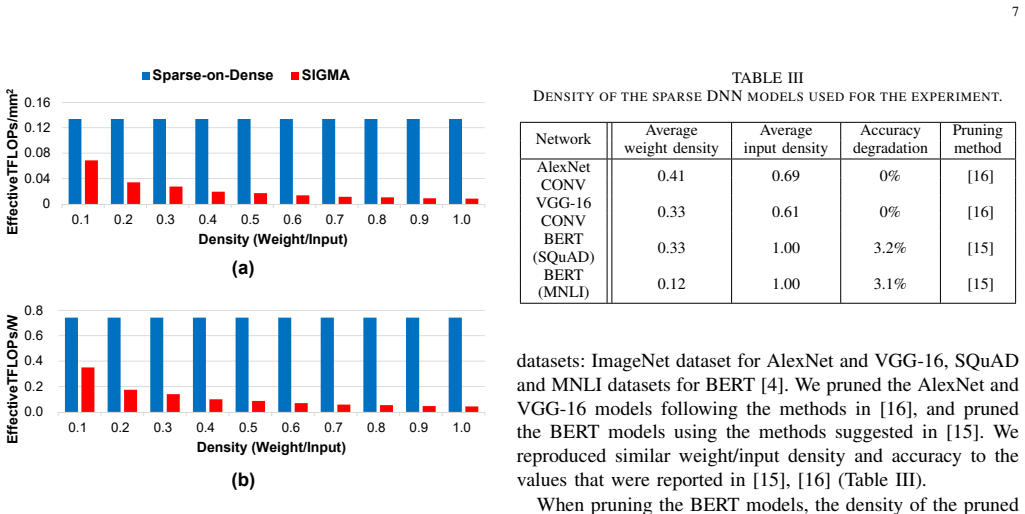
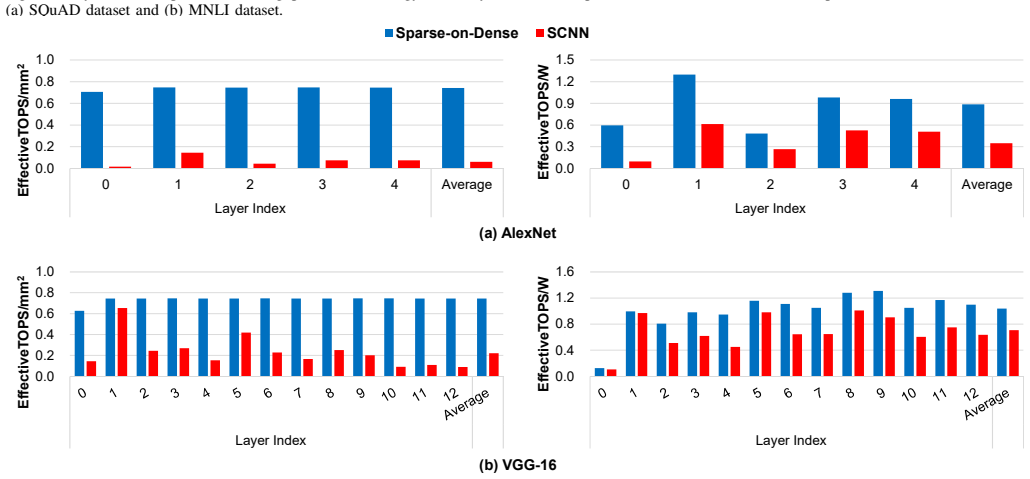
As the size of Deep Neural Networks (DNNs) increases dramatically to achieve high accuracy, the DNNs require a large amount of computations and memory footprint. Pruning, which produces a sparse neural network, is one of the solutions to reduce the computational complexity of neural network processing. To maximize the performance of the computations with such compressed data, dedicated sparse neural network accelerators have been introduced, but complex circuits for matching the indices of non-zero inputs/weights cause large overhead in area and power of processing elements (PEs). The sparse PE becomes significantly larger than the dense PE, which raises an interesting question for designers; "Given the area, isn't it better to use larger number of dense PEs despite the low utilization in sparse matrix computations?" In this paper, we show that the answer is "yes", and demonstrate an area and energy-efficient method for sparse neural network computing on dense-matrix multiplication hardware accelerators (Sparse-on-Dense).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the area and power overhead of index-matching logic in sparse PEs exceeds the utilization penalty of dense PEs for sparse neural network inference; therefore, given fixed silicon area, it is preferable to instantiate more dense PEs on a conventional dense matrix-multiplication accelerator and rely on software mapping to recover throughput. The authors present a method called Sparse-on-Dense that realizes this design choice and report it as both area- and energy-efficient.
Significance. If the quantitative trade-off is demonstrated, the result would challenge the prevailing direction of building specialized sparse accelerators and instead favor software-supported use of existing dense systolic or tensor-core hardware. Such a finding would be directly relevant to both academic and industrial accelerator design.
major comments (2)
- [Abstract and §1] Abstract and §1: The central design decision rests on the inequality that sparse-PE index-matching overhead > utilization loss of dense PEs. No area or power numbers, no synthesis results at a stated technology node, and no utilization figures after the proposed software mapping are supplied to substantiate this inequality.
- [Results section (presumed §4–5)] Results section (presumed §4–5): No direct comparison against published sparse accelerators (e.g., at the same node and with the same sparsity patterns) or against a pure dense baseline with the same total area is presented, leaving the claimed superiority of Sparse-on-Dense unsupported by the data required to evaluate the claim.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We agree that strengthening the quantitative support for our central claim will improve the paper. We address each major comment below and will incorporate revisions as indicated.
read point-by-point responses
-
Referee: [Abstract and §1] Abstract and §1: The central design decision rests on the inequality that sparse-PE index-matching overhead > utilization loss of dense PEs. No area or power numbers, no synthesis results at a stated technology node, and no utilization figures after the proposed software mapping are supplied to substantiate this inequality.
Authors: The manuscript provides an analytical argument and some utilization estimates derived from the software mapping strategy in Sections 3 and 4. However, we concur that explicit synthesis results at a specific technology node are necessary to fully substantiate the area and power overhead comparison. In the revision, we will add synthesis data using a 28nm CMOS library, reporting area and power for both sparse and dense PEs, along with post-mapping utilization figures for various sparsity ratios. revision: yes
-
Referee: [Results section (presumed §4–5)] Results section (presumed §4–5): No direct comparison against published sparse accelerators (e.g., at the same node and with the same sparsity patterns) or against a pure dense baseline with the same total area is presented, leaving the claimed superiority of Sparse-on-Dense unsupported by the data required to evaluate the claim.
Authors: Our evaluations compare Sparse-on-Dense against dense accelerators under fixed area budgets and demonstrate energy efficiency gains. To address this, we will expand the results to include normalized comparisons with representative published sparse accelerators (e.g., EIE, SCNN) at equivalent technology nodes and sparsity patterns from common benchmarks. Additionally, we will present a pure dense baseline with identical total silicon area to highlight the throughput recovery via software mapping. revision: yes
Circularity Check
No circularity: empirical hardware proposal without self-referential derivation
full rationale
The paper proposes Sparse-on-Dense as an area/energy-efficient method for sparse NN inference on dense matrix accelerators, motivated by the observation that sparse PEs incur large index-matching overhead. The central claim is demonstrated through architectural description and (presumably) synthesis/experimental results rather than any closed mathematical derivation. No equations, fitted parameters, ansatzes, or uniqueness theorems appear in the abstract or described content. The load-bearing step is an empirical inequality (area/power cost of sparse matching vs. utilization loss of dense PEs), which is external to the paper's own definitions and therefore not circular by construction. This is a standard empirical architecture paper whose validity rests on measured numbers, not on renaming or self-definition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Imagenet classification with deep convolutional neural networks,
A. Krizhevsky, I. Sutskever, and G. E. Hinton, “Imagenet classification with deep convolutional neural networks,”Advances in neural informa- tion processing systems, vol. 25, 2012
2012
-
[2]
Very Deep Convolutional Networks for Large-Scale Image Recognition
K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,”arXiv preprint arXiv:1409.1556, 2014
work page internal anchor Pith review arXiv 2014
-
[3]
Language Models are Few-Shot Learners
T. B. Brown, B. Mann, N. Ryder, M. Subbiah, J. Kaplan, P. Dhariwal, A. Neelakantan, P. Shyam, G. Sastry, A. Askellet al., “Language models are few-shot learners,”arXiv preprint arXiv:2005.14165, 2020
work page internal anchor Pith review arXiv 2005
-
[4]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,”arXiv preprint arXiv:1810.04805, 2018
work page internal anchor Pith review arXiv 2018
-
[5]
M. Naumov, D. Mudigere, H.-J. M. Shi, J. Huang, N. Sundaraman, J. Park, X. Wang, U. Gupta, C.-J. Wu, A. G. Azzoliniet al., “Deep learning recommendation model for personalization and recommenda- tion systems,”arXiv preprint arXiv:1906.00091, 2019
-
[6]
S. Han, H. Mao, and W. J. Dally, “Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,”arXiv preprint arXiv:1510.00149, 2015. 10
work page internal anchor Pith review arXiv 2015
-
[7]
arXiv preprint arXiv:1710.09282 , year=
Y . Cheng, D. Wang, P. Zhou, and T. Zhang, “A survey of model compression and acceleration for deep neural networks,”arXiv preprint arXiv:1710.09282, 2017
-
[8]
Ese: Efficient speech recognition engine with sparse lstm on fpga,
S. Han, J. Kang, H. Mao, Y . Hu, X. Li, Y . Li, D. Xie, H. Luo, S. Yao, Y . Wanget al., “Ese: Efficient speech recognition engine with sparse lstm on fpga,” inProceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, 2017, pp. 75–84
2017
-
[9]
Scnn: An accelerator for compressed-sparse convolutional neural networks,
A. Parashar, M. Rhu, A. Mukkara, A. Puglielli, R. Venkatesan, B. Khailany, J. Emer, S. W. Keckler, and W. J. Dally, “Scnn: An accelerator for compressed-sparse convolutional neural networks,”ACM SIGARCH Computer Architecture News, vol. 45, no. 2, pp. 27–40, 2017
2017
-
[10]
Snap: An efficient sparse neural acceleration processor for unstructured sparse deep neural network inference,
J.-F. Zhang, C.-E. Lee, C. Liu, Y . S. Shao, S. W. Keckler, and Z. Zhang, “Snap: An efficient sparse neural acceleration processor for unstructured sparse deep neural network inference,”IEEE Journal of Solid-State Circuits, vol. 56, no. 2, pp. 636–647, 2020
2020
-
[11]
In-datacenter performance analysis of a tensor processing unit,
N. P. Jouppi, C. Young, N. Patil, D. Patterson, G. Agrawal, R. Bajwa, S. Bates, S. Bhatia, N. Boden, A. Borcherset al., “In-datacenter performance analysis of a tensor processing unit,” inProceedings of the 44th annual international symposium on computer architecture, 2017, pp. 1–12
2017
-
[12]
Sigma: A sparse and irregular gemm ac- celerator with flexible interconnects for dnn training,
E. Qin, A. Samajdar, H. Kwon, V . Nadella, S. Srinivasan, D. Das, B. Kaul, and T. Krishna, “Sigma: A sparse and irregular gemm ac- celerator with flexible interconnects for dnn training,” in2020 IEEE International Symposium on High Performance Computer Architecture (HPCA). IEEE, 2020, pp. 58–70
2020
-
[13]
Systolic tensor array: An efficient structured-sparse gemm accelerator for mobile cnn inference,
Z.-G. Liu, P. N. Whatmough, and M. Mattina, “Systolic tensor array: An efficient structured-sparse gemm accelerator for mobile cnn inference,” IEEE Computer Architecture Letters, vol. 19, no. 1, pp. 34–37, 2020
2020
-
[14]
S2ta: Exploiting structured sparsity for energy-efficient mobile cnn acceleration,
Z.-G. Liu, P. N. Whatmough, Y . Zhu, and M. Mattina, “S2ta: Exploiting structured sparsity for energy-efficient mobile cnn acceleration,” in 2022 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 2022, pp. 573–586
2022
-
[15]
Movement pruning: Adaptive sparsity by fine-tuning
V . Sanh, T. Wolf, and A. M. Rush, “Movement pruning: Adaptive sparsity by fine-tuning,”arXiv preprint arXiv:2005.07683, 2020
-
[16]
Learning both Weights and Connections for Efficient Neural Networks
S. Han, J. Pool, J. Tran, and W. J. Dally, “Learning both weights and con- nections for efficient neural networks,”arXiv preprint arXiv:1506.02626, 2015
work page Pith review arXiv 2015
-
[17]
SQuAD: 100,000+ Questions for Machine Comprehension of Text
P. Rajpurkar, J. Zhang, K. Lopyrev, and P. Liang, “Squad: 100,000+ questions for machine comprehension of text,”arXiv preprint arXiv:1606.05250, 2016
work page internal anchor Pith review arXiv 2016
-
[18]
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. R. Bowman, “Glue: A multi-task benchmark and analysis platform for natural lan- guage understanding,” 2018, arXiv preprint 1804.07461. Hyunsung Yoonreceived the B.S. degree in elec- tronic and electrical engineering from Chung-Ang University, Seoul, South Korea, in 2019. He received the Ph.D degree w...
work page internal anchor Pith review arXiv 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.