Recognition: unknown
Recommendations for Efficient and Responsible LLM Adoption within Industrial Software Development
Pith reviewed 2026-05-07 11:51 UTC · model grok-4.3
The pith
Seven recommendations guide responsible LLM adoption in industrial software development.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through a multi-case study in three organizations already using LLMs in software engineering activities and qualitative thematic analysis, the authors derived seven actionable recommendations. These cover preferences for using LLMs as AI assistants, the value of relevant stakeholders' satisfaction when evaluating outputs, the need to scope LLM applicability to suitable SE tasks, effects on existing workflows, directions for human oversight mechanisms, and skills practitioners require to leverage the technology. A complementary online survey of software practitioners showed high agreement on the perceived relevance of the recommendations. The authors outline future research including mapping
What carries the argument
The seven actionable recommendations synthesized from qualitative thematic analysis of multi-case study data on LLM use in three organizations and validated by practitioner survey responses.
If this is right
- Software teams should position LLMs as assistive tools to align with observed user preferences.
- Evaluation of LLM outputs should include satisfaction input from relevant stakeholders.
- Organizations must define clear boundaries for which SE tasks LLMs can support.
- Existing development workflows require deliberate adjustments when introducing LLMs.
- Structured human oversight mechanisms become necessary to manage LLM-related risks.
Where Pith is reading between the lines
- The recommendations could form the basis for internal company policies or industry-wide guidelines on LLM use.
- Mapping the recommendations to the EU AI Act as proposed may identify specific compliance steps for software firms.
- Skill-building programs for practitioners could be designed directly around the identified necessary competencies.
- Testing the recommendations in additional sectors might uncover variations in how they apply to different development contexts.
Load-bearing premise
Experiences from three organizations plus responses from a convenience sample of practitioners suffice to generate recommendations that apply across the wider industrial software sector.
What would settle it
A larger multi-organization study that applies the seven recommendations and finds no measurable gains in efficiency, responsibility, or stakeholder satisfaction would show the recommendations do not generalize.
Figures



read the original abstract
Context: Large language models (LLMs) are observed to have a significant positive impact on various software engineering (SE) activities. With improved accessibility, the adoption of powerful LLMs in industry has surged recently. However, there is a lack of actionable best practices for the efficient and responsible adoption of LLMs within industrial software settings. Objectives: We developed seven actionable recommendations to address this research gap. Methods: We conducted a multi-case study with three organisations that use LLMs within their SE activities and synthesised seven recommendations through qualitative thematic analysis. We conducted a complementary online survey with software practitioners from various industries to evaluate the perceived relevance of our recommendations. Results: Our results and recommendations focus on (i) users' preference to use LLMs as AI assistants, (ii) the importance of relevant stakeholders' satisfaction in the LLM-output evaluation, (iii) scoping the applicability of LLMs within SE tasks, (iv) the effect of LLMs on SE workflows, (v) the necessity and directions for developing human oversight mechanisms, and (vi) the necessary skills for practitioners for leveraging LLMs within SE. The online survey indicates a high level of agreement from the participants regarding the perceived relevance of the recommendations. Conclusion: We outline future research directions, including mapping the seven recommendations to the principles of the EU AI Act (AIA) in order to examine how they relate to the current regulatory compliance frameworks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports on a multi-case study conducted with three organizations that have adopted LLMs in their software engineering (SE) practices. Through qualitative thematic analysis, the authors derive seven actionable recommendations for efficient and responsible LLM adoption in industrial SE settings. These recommendations are then evaluated for relevance via a complementary online survey of software practitioners, which indicates high levels of agreement. The paper concludes by outlining future research directions, including mapping the recommendations to the EU AI Act.
Significance. Should the recommendations prove generalizable, this work would offer timely, empirically grounded guidance to industrial practitioners seeking to integrate LLMs into SE workflows responsibly. It addresses a clear gap in actionable best practices and connects to regulatory frameworks like the EU AI Act, potentially informing both industry adoption strategies and future empirical studies in AI-assisted software engineering.
major comments (2)
- [Methods] The multi-case study is limited to three organizations without details on selection criteria, theoretical sampling, maximum variation, or saturation assessment (Methods section). This is load-bearing for the central claim because the seven recommendations are synthesized from these cases and presented as actionable for the broader industrial SE sector.
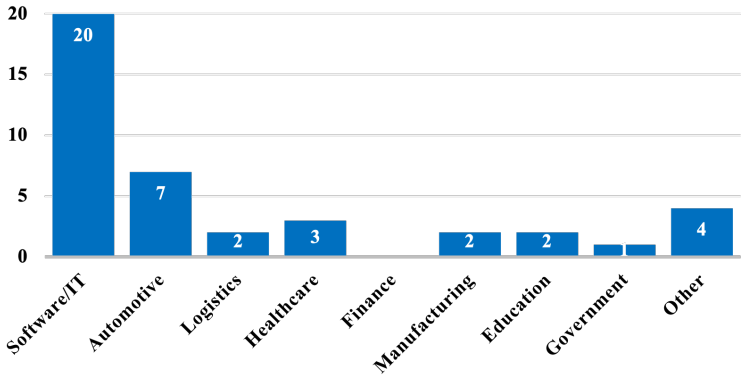
- [Methods and Results] The online survey is described only as complementary and convenience-based, with no information on recruitment, sample demographics, size, or response rate (Methods and Results sections). This weakens the validation step, as the survey is used to support the perceived relevance of the recommendations across 'various industries'.
minor comments (2)
- [Abstract] The abstract claims seven recommendations but enumerates only six focus areas ((i) through (vi)) in the results summary; the seventh should be explicitly stated.
- [Conclusion] The conclusion mentions future mapping of the recommendations to the EU AI Act but provides no outline of specific alignments; adding even a brief table or paragraph would clarify the regulatory contribution.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of methodological transparency. We address each major comment below and will revise the manuscript to incorporate additional details where possible.
read point-by-point responses
-
Referee: [Methods] The multi-case study is limited to three organizations without details on selection criteria, theoretical sampling, maximum variation, or saturation assessment (Methods section). This is load-bearing for the central claim because the seven recommendations are synthesized from these cases and presented as actionable for the broader industrial SE sector.
Authors: We agree that greater detail on case selection and analysis procedures would strengthen the paper. In the revised Methods section, we will explicitly describe the purposive selection criteria (organizations with documented LLM adoption in SE workflows and granted research access), the rationale for three cases as a feasible multi-case design in industrial contexts, and our approach to thematic saturation (iterative coding until no new themes emerged). While the sampling was not theoretically driven due to practical access limitations common in industry studies, we will add a dedicated limitations subsection discussing implications for generalizability and how the recommendations should be interpreted as context-informed rather than universally prescriptive. revision: yes
-
Referee: [Methods and Results] The online survey is described only as complementary and convenience-based, with no information on recruitment, sample demographics, size, or response rate (Methods and Results sections). This weakens the validation step, as the survey is used to support the perceived relevance of the recommendations across 'various industries'.
Authors: We acknowledge the need for fuller survey documentation to support its role in validating relevance. The revised manuscript will expand both the Methods and Results sections with: recruitment channels (professional networks, LinkedIn groups, and SE practitioner forums), exact sample size and response rate, demographic breakdown (roles, years of experience, industry sectors, and LLM usage frequency), and any steps taken to mitigate convenience sampling bias. These additions will allow readers to better assess the survey's contribution to claims of cross-industry relevance. revision: yes
Circularity Check
No circularity: recommendations synthesized from independent case-study data and external survey validation
full rationale
The paper's derivation proceeds from a multi-case study across three organizations, followed by thematic analysis to produce seven recommendations, then a separate online survey of practitioners to assess perceived relevance. No equations, fitted parameters, or predictions are involved. No self-citations are invoked as load-bearing premises for the recommendations themselves, and the survey functions as an independent check rather than a self-referential validation. The central claims rest on fresh empirical inputs external to the synthesized outputs, satisfying the criteria for a self-contained, non-circular derivation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Qualitative thematic analysis of interviews from three organizations can yield generalizable actionable recommendations for LLM adoption.
- domain assumption A practitioner survey provides an adequate external validation of the recommendations' relevance.
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in ":" * " " * FUNCTION f...
-
[2]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in ":" * " " * FUNCTION f...
-
[3]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION word.in bbl.in ":" * " " * FUNCTION f...
-
[4]
author Baltes, S. , author Ralph, P. , year 2022 . title Sampling in Software Engineering Research: A Critical Review and Guidelines . journal Empirical Softw. Engg. volume 27 . :10.1007/s10664-021-10072-8
-
[5]
author Bang, Y. , et al., year 2023 . title A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity https://arxiv.org/abs/2302.04023, http://arxiv.org/abs/2302.04023 arXiv:2302.04023
-
[6]
, et al., year 2020
author Brown, T. , et al., year 2020 . title Language Models are Few-shot Learners . journal Advances in Neural Information Processing Systems volume 33 , pages 1877--1901
2020
-
[7]
author Clarke, V. , author Braun, V. , year 2014 . title Thematic Analysis . publisher Encyclopedia of Critical Psychology . pp. pages 1947--1952 . :10.1007/978-1-4614-5583-7_311
-
[8]
, et al., year 2023
author Datta, V.D. , et al., year 2023 . title GREAT AI in Medical Appropriateness and Value-Based-Care , in: booktitle Big Data and Artificial Intelligence , publisher Springer Nature Switzerland . pp. pages 16--33
2023
-
[9]
title Ethics Guidelines for Trustworthy Artificial Intelligence (AI)
author European Commission , year 2019 . title Ethics Guidelines for Trustworthy Artificial Intelligence (AI) . www.aepd.es/sites/default/files/2019-12/ai-ethics-guidelines.pdf
2019
-
[10]
title Artificial Intelligence Act
author European Commission , year 2024 . title Artificial Intelligence Act . https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32024R1689. note Accessed: 06/03/2025
2024
-
[11]
author Fan, A. , author Gokkaya, B. , author Harman, M. , author Lyubarskiy, M. , author Sengupta, S. , author Yoo, S. , author Zhang, J.M. , year 2023 . title Large Language Models for Software Engineering: Survey and Open Problems , in: booktitle 2023 IEEE/ACM International Conference on Software Engineering: Future of Software Engineering (ICSE-FoSE) ,...
-
[12]
author Fragiadakis, G. , author Diou, C. , author Kousiouris, G. , author Nikolaidou, M. , year 2025 . title Evaluating Human-AI Collaboration: A Review and Methodological Framework . https://arxiv.org/abs/2407.19098, http://arxiv.org/abs/2407.19098 arXiv:2407.19098
-
[13]
title GitHub Copilot
author GitHub , year 2023 . title GitHub Copilot . https://github.com/features/copilot. note Accessed: 23/10/2023
2023
-
[14]
News summarization and evaluation in the era of gpt-3, 2022
author Goyal, T. , author Li, J.J. , author Durrett, G. , year 2023 . title News Summarization and Evaluation in the Era of GPT-3 https://arxiv.org/abs/2209.12356, http://arxiv.org/abs/2209.12356 arXiv:2209.12356
-
[15]
author Haque, M.A. , year 2025 . title LLMs: A Game-changer for Software Engineers? journal BenchCouncil Transactions on Benchmarks, Standards and Evaluations volume 5 . :https://doi.org/10.1016/j.tbench.2025.100204
-
[16]
author He, J. , author Treude, C. , author Lo, D. , year 2025 . title LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision and the Road Ahead . journal ACM Trans. Softw. Eng. Methodol. :10.1145/3712003
-
[17]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
author Hong, S. , et al., year 2023 . title MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework . https://arxiv.org/abs/2308.00352, http://arxiv.org/abs/2308.00352 arXiv:2308.00352
work page internal anchor Pith review arXiv 2023
-
[18]
Large Language Models for Software Engineering: A Sys- tematic Literature Review,
author Hou, X. , et al., year 2024 . title Large Language Models for Software Engineering: A Systematic Literature Review . journal ACM Trans. Softw. Eng. Methodol. volume 33 . :10.1145/3695988
-
[19]
, author Deng, H
author Kandpal, N. , author Deng, H. , author Roberts, A. , author Wallace, E. , author Raffel, C. , year 2023 . title Large Language Models Struggle to Learn Long-tail Knowledge , in: booktitle International Conference on Machine Learning , organization PMLR . pp. pages 15696--15707
2023
-
[20]
author Kheiri, K. , author Karimi, H. , year 2023 . title Sentimentgpt: Exploiting GPT for Advanced Sentiment Analysis and its Departure from Current Machine Learning https://arxiv.org/abs/2307.10234, http://arxiv.org/abs/2307.10234 arXiv:2307.10234
-
[21]
, author Dyba, T
author Kitchenham, B.A. , author Dyba, T. , author Jorgensen, M. , year 2004 . title Evidence-based Software Engineering , in: booktitle Proceedings. 26th International Conference on Software Engineering , organization IEEE . pp. pages 273--281
2004
-
[22]
, year 2007
author Kotter, John R. , year 2007 . title Leading Change - Why Transformation Efforts Fail . journal Harvard Business Review
2007
-
[23]
author Kumar, K. , year 2025 . title Fundamentals of Generative AI . publisher Springer Nature Singapore , address Singapore . pp. pages 33--77 . :10.1007/978-981-95-1561-5_2
-
[24]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
author Lewis, P. , author Perez, E. , author Piktus, A. , author Petroni, F. , author Karpukhin, V. , author Goyal, N. , author Küttler, H. , author Lewis, M. , author tau Yih, W. , author Rocktäschel, T. , author Riedel, S. , author Kiela, D. , year 2021 . title Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks . http://arxiv.org/abs/2005....
work page internal anchor Pith review arXiv 2021
-
[25]
author Lombard, M. , author Snyder-Duch, J. , author Bracken, C.C. , year 2002 . title Content Analysis in Mass Communication: Assessment and Reporting of Intercoder Reliability . journal Human Communication Research volume 28 , pages 587--604 . :https://doi.org/10.1111/j.1468-2958.2002.tb00826.x
-
[26]
author McDonald, N. , author Schoenebeck, S. , author Forte, A. , year 2019 . title Reliability and Inter-rater Reliability in Qualitative Research: Norms and Guidelines for CSCW and HCI Practice volume 3 . :10.1145/3359174
-
[27]
title Azure OpenAI Service
author Microsoft , year 2023 a. title Azure OpenAI Service . https://azure.microsoft.com/en-gb/products/ai-services/openai-service/. note Accessed: 23/10/2023
2023
-
[28]
title Microsoft Copilot
author Microsoft , year 2023 b. title Microsoft Copilot . https://www.microsoft.com/en-us/microsoft-copilot. note Accessed: 18/12/2023
2023
-
[29]
author Mintzberg, H. , author Waters, J.A. , year 1985 . title Of Strategies, Deliberate and Emergent . journal Strategic Management Journal volume 6 , pages 257--272 . :https://doi.org/10.1002/smj.4250060306
-
[30]
WebGPT: Browser-assisted question-answering with human feedback
author Nakano, R. , et al., year 2022 . title WebGPT: Browser-assisted Question-answering with Human Feedback https://arxiv.org/abs/2112.09332, http://arxiv.org/abs/2112.09332 arXiv:2112.09332
work page internal anchor Pith review arXiv 2022
-
[31]
title Introducing ChatGPT Enterprise
author OpenAI , year 2023 . title Introducing ChatGPT Enterprise . https://openai.com/blog/introducing-chatgpt-enterprise. note Accessed: 23/10/2023
2023
-
[32]
author Parasuraman, R. , author Sheridan, T. , author Wickens, C. , year 2000 . title A Model for Types and Levels of Human Interaction with Automation . journal IEEE Transactions on Systems, Man, and Cybernetics - Part A: Systems and Humans volume 30 , pages 286--297 . :10.1109/3468.844354
-
[33]
The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
author Peng, S. , et al., year 2023 . title The Impact of AI on Developer Productivity: Evidence from GitHub Copilot https://arxiv.org/abs/2302.06590, http://arxiv.org/abs/2302.06590 arXiv:2302.06590
work page internal anchor Pith review arXiv 2023
-
[34]
author Pereira, G. , author Prikladnicki, R. , author Jackson, V. , author van der Hoek, A. , author Fortes, L. , author Macaubas, I. , year 2024 . title Early Results from a Study of GenAI Adoption in a Large Brazilian Company: The Case of Globo . publisher Springer Nature Switzerland , address Cham . pp. pages 275--293 . :10.1007/978-3-031-55642-5_13
-
[35]
author Robson, C. , year 1993 . title Real World Research: A Resource for Social Scientists and Practitioner-Researchers . publisher Blackwell . https://cir.nii.ac.jp/crid/1130282271686871424
-
[36]
author Roy, Q. , author Zhang, F. , author Vogel, D. , year 2019 . title Automation Accuracy Is Good, but High Controllability May Be Better , in: booktitle Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems , publisher Association for Computing Machinery , address New York, NY, USA . p. pages 1–8 . :10.1145/3290605.3300750
-
[37]
, author H \"o st, M
author Runeson, P. , author H \"o st, M. , year 2009 . title Guidelines for Conducting and Reporting Case Study Research in Software Engineering . journal Empirical Software Engineering volume 14 , pages 131--164
2009
-
[38]
IEEE Transactions on Software Engineering 25, 557–572
author Seaman, C. , year 1999 . title Qualitative Methods in Empirical Studies of Software Engineering . journal IEEE Transactions on Software Engineering volume 25 , pages 557--572 . :10.1109/32.799955
-
[39]
author Strandberg, P.E. , year 2019 . title Ethical Interviews in Software Engineering , in: booktitle 2019 ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM) , pp. pages 1--11 . :10.1109/ESEM.2019.8870192
-
[40]
, author Kobert, M
author S \"u e, T. , author Kobert, M. , author Grapenthin, S. , author Voigt, B.F. , year 2023 . title AI-Powered Chatbots and the Transformation of Work: Findings from a Case Study in Software Development and Software Engineering , in: booktitle Collaborative Networks in Digitalization and Society 5.0 , publisher Springer Nature Switzerland , address Ch...
2023
-
[41]
author Wang, X. , author Tian, Y. , author Huang, K. , author Liang, B. , year 2025 . title Practically Implementing an LLM-supported Collaborative Vulnerability Remediation Process: A Team-based Approach . journal Computers & Security volume 148 , pages 104113 . :https://doi.org/10.1016/j.cose.2024.104113
-
[42]
author White, J. , et al., year 2023 . title ChatGPT Prompt Patterns for Improving Code Quality, Refactoring, Requirements Elicitation, and Software Design . http://arxiv.org/abs/2303.07839 arXiv:2303.07839
-
[43]
, author Runeson, P
author Wohlin, C. , author Runeson, P. , author H \"o st, M. , author Ohlsson, M.C. , author Regnell, B. , author Wessl \'e n, A. , year 2012 . title Experimentation in software engineering . publisher Springer Science & Business Media
2012
-
[44]
author Xie, Q. , et al., year 2023 . title A Survey on Biomedical Text Summarization with Pre-trained Language Model https://arxiv.org/abs/2304.08763, http://arxiv.org/abs/2304.08763 arXiv:2304.08763
-
[45]
Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models
author Zhang, Y. , et al., year 2025 . title Siren's Song in the AI Ocean: A Survey on Hallucination in Large Language Models https://arxiv.org/abs/2309.01219, http://arxiv.org/abs/2309.01219 arXiv:2309.01219
work page internal anchor Pith review arXiv 2025
-
[46]
P j*j U 3˶ ysWsv zxm?߮ m8L_|e ŶR<mY=IJz7y< 0' ۳ x1枖ONk Kϯ|^ f <q? @ zGn |mg A
+ is cited as + ESG96 +. In connection with cross-referencing and possible future hyperlinking it is not a good idea to collect more that one literature item in one + +. The so-called Harvard or author-year style of referencing is enabled by the package natbib . With this package the literature can be cited as follows: enumerate [ ] Parenthetical: + WB96 ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.