Recognition: unknown
Atomic-Probe Governance for Skill Updates in Compositional Robot Policies
Pith reviewed 2026-05-08 03:21 UTC · model grok-4.3
The pith
An atomic-quality probe predicts how skill replacements affect compositional robot task success using only individual skill tests.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
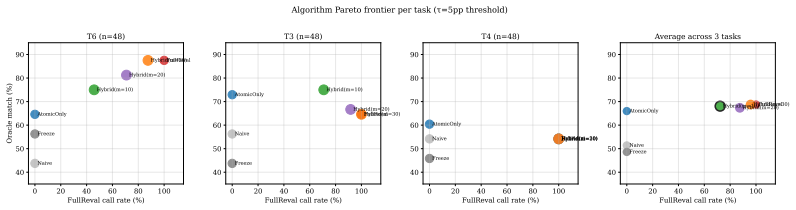
In compositional robot policies, replacing a skill inside a composition can shift task success by up to 50 percentage points because of a dominant-skill effect; an atomic-quality probe that samples only the replaced skill's standalone performance predicts the new composition outcome sufficiently well to govern updates, while a Hybrid Selector further trades a modest amount of revalidation cost for higher accuracy.
What carries the argument
The atomic-quality probe, which uses paired sampling of a skill's atomic success rate to forecast its contribution inside any composition that contains it.
If this is right
- Robot skill libraries can accept updates without exhaustive re-testing of every possible composition that uses the updated skill.
- Dominant skills can be identified at deployment time so that updates to them receive higher priority or stricter validation.
- A Hybrid Selector lets operators choose operating points on a cost-accuracy curve, using zero-cost atomic probes for most decisions and full revalidation only when the probe is uncertain.
- Off-policy behavioral distance metrics are ruled out as reliable predictors for composition outcomes in these settings.
Where Pith is reading between the lines
- The same probe could be applied to continual-learning pipelines where new skills arrive from human demonstrations or domain adaptation without requiring a full library re-composition pass each time.
- If the dominant-skill pattern holds in contact-rich or long-horizon tasks, it would suggest that composition governance can be reduced to a small number of high-impact atomic checks rather than combinatorial search.
- Deployed systems could log atomic probe scores over time to detect when an update has degraded a previously dominant skill and trigger targeted re-training.
Load-bearing premise
The dominant-skill effect and the probe's ability to forecast composition changes will continue to appear in tasks and update patterns beyond the three robosuite environments and 144 events examined.
What would settle it
A new manipulation task in which the atomic probe's predicted success rate for a skill swap deviates by more than 20 percentage points from the measured composition success rate.
Figures


read the original abstract
Skill libraries in deployed robotic systems are continually updated through fine-tuning, fresh demonstrations, or domain adaptation, yet existing typed-composition methods (BLADE, SymSkill, Generative Skill Chaining) treat the library as frozen at test time and do not analyze how composition outcomes change when a skill is replaced. We introduce a paired-sampling cross-version swap protocol on robosuite manipulation tasks to characterize this dimension of compositional skill learning. On a dual-arm peg-in-hole task we discover a dominant-skill effect: one ECM achieves 86.7% atomic success rate while every other ECM is at or below 26.7%, and whether this dominant ECM enters a composition shifts the success rate by up to +50pp. We characterize the boundary on a simpler pick task where all atomic policies saturate at 100% and the effect is undefined. Across three tasks we further find that off-policy behavioral distance metrics fail to identify the dominant ECM, ruling out the natural cheap predictor. We propose an atomic-quality probe and a Hybrid Selector combining per-skill probes (zero per-decision cost) with selective composition revalidation (full cost), and characterize its Pareto frontier on 144 skill-update decisions. On T6 the atomic-only probe sits 23pp below full revalidation (64.6% vs 87.5% oracle match) at zero per-decision cost; a Hybrid Selector with m=10 closes most of that gap to ~12pp at 46% of full-revalidation cost. On the cross-task average over 144 events, atomic-only is within 3pp of full revalidation under a mixed-oracle caveat. The atomic-quality probe is, to our knowledge, the first principled, deployment-ready primitive for skill-update governance in compositional robot policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces a paired-sampling cross-version swap protocol to study how skill updates affect compositional outcomes in robot policies on robosuite tasks. It reports a dominant-skill effect on dual-arm peg-in-hole (one ECM at 86.7% atomic success, others ≤26.7%, shifting composition success by up to +50pp), shows off-policy behavioral distance fails to identify it, and proposes an atomic-quality probe (zero per-decision cost) plus Hybrid Selector (selective revalidation) that on 144 update events achieves 64.6% vs 87.5% oracle match on T6 (23pp gap) or ~12pp gap at 46% cost with m=10, and within 3pp cross-task average under a mixed-oracle caveat. The atomic-quality probe is claimed to be the first principled, deployment-ready primitive for skill-update governance.
Significance. If the dominant-skill effect and probe reliability hold, the work supplies a practical, low-overhead mechanism for governing continual updates to skill libraries in deployed compositional policies, avoiding full revalidation costs while maintaining high fidelity to oracle outcomes. The empirical protocol and Pareto characterization of the hybrid approach are concrete contributions to robot learning. The significance is limited by the narrow task set and lack of statistical detail, but the core idea of an atomic probe as a governance primitive has clear potential utility if validated more broadly.
major comments (4)
- [Abstract] Abstract: the reported figures (86.7% dominant ECM, ≤26.7% others, +50pp shift, 23pp gap on T6, 12pp hybrid gap, 46% cost, 3pp cross-task average) are given without error bars, trial counts, or statistical tests, so the robustness of the dominant-skill effect and the claimed closeness to oracle cannot be assessed.
- [Abstract] Abstract: the cross-task average claim of being 'within 3pp of full revalidation' is qualified by an undefined 'mixed-oracle caveat'; without an explicit definition of how the oracle is modified or why the caveat is needed, this quantitative equivalence is not load-bearing for the deployment-ready assertion.
- [Across three tasks] Across three tasks: the dominant-skill effect is demonstrated only on dual-arm peg-in-hole; it is explicitly undefined on the pick task due to 100% saturation, and no analysis is supplied for the third task or for whether the effect is an artifact of the chosen robosuite environments rather than a general property of compositional policies.
- [144 skill-update decisions] 144 skill-update decisions: the Hybrid Selector Pareto frontier and the atomic probe's 64.6% vs 87.5% result are evaluated only against full revalidation within the same narrow distribution; no cross-simulator, real-robot, or expanded task-suite results are reported, leaving the generalization required for the 'deployment-ready' claim untested.
minor comments (2)
- [Abstract] Abstract: the acronym ECM is used without expansion on first appearance.
- [Method] The precise computation of the atomic-quality probe (how per-skill success rates are turned into a governance signal) should be stated explicitly so that the failure of behavioral distance can be contrasted mechanistically.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive feedback on our manuscript. We appreciate the recognition of the potential utility of the atomic probe for skill-update governance. We address each of the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported figures (86.7% dominant ECM, ≤26.7% others, +50pp shift, 23pp gap on T6, 12pp hybrid gap, 46% cost, 3pp cross-task average) are given without error bars, trial counts, or statistical tests, so the robustness of the dominant-skill effect and the claimed closeness to oracle cannot be assessed.
Authors: We agree that the reported figures in the abstract lack error bars, trial counts, and statistical tests, which hinders assessment of robustness. We will revise the abstract and main text to include the number of trials (30 per condition), standard errors, and results of statistical significance tests for key effects such as the dominant-skill phenomenon. revision: yes
-
Referee: [Abstract] Abstract: the cross-task average claim of being 'within 3pp of full revalidation' is qualified by an undefined 'mixed-oracle caveat'; without an explicit definition of how the oracle is modified or why the caveat is needed, this quantitative equivalence is not load-bearing for the deployment-ready assertion.
Authors: We agree that the mixed-oracle caveat requires explicit definition to make the claim clear. This caveat accounts for cases of atomic saturation where full revalidation provides no additional information. We will add a precise definition in the abstract and elaborate in the methods section of the revised manuscript. revision: yes
-
Referee: [Across three tasks] Across three tasks: the dominant-skill effect is demonstrated only on dual-arm peg-in-hole; it is explicitly undefined on the pick task due to 100% saturation, and no analysis is supplied for the third task or for whether the effect is an artifact of the chosen robosuite environments rather than a general property of compositional policies.
Authors: The dominant-skill effect is analyzed in depth for the dual-arm peg-in-hole task where atomic success rates vary sufficiently. We already note its undefined nature on the saturated pick task. For the third task, supporting results on metric failures are present but the dominant effect analysis is lighter. We will expand the cross-task discussion, include additional details on the third task, and add a limitations paragraph addressing potential environment-specific artifacts and the need for broader validation. revision: partial
-
Referee: [144 skill-update decisions] 144 skill-update decisions: the Hybrid Selector Pareto frontier and the atomic probe's 64.6% vs 87.5% result are evaluated only against full revalidation within the same narrow distribution; no cross-simulator, real-robot, or expanded task-suite results are reported, leaving the generalization required for the 'deployment-ready' claim untested.
Authors: We acknowledge that the evaluation is limited to the robosuite tasks and does not include cross-simulator or real-robot experiments, which would be required for full generalization. This is a genuine scope limitation of the present work. We will revise the abstract and conclusions to moderate the 'deployment-ready' phrasing to emphasize the probe as a promising, low-cost primitive supported by the current evidence, while highlighting the need for future broader testing. No new experiments are added at this stage. revision: partial
Circularity Check
No circularity: purely empirical evaluation on fixed robosuite tasks
full rationale
The paper reports experimental results from a paired-sampling protocol on three robosuite manipulation tasks and 144 skill-update events. It discovers the dominant-skill effect, shows off-policy metrics fail, and evaluates the atomic-quality probe and Hybrid Selector directly against full revalidation oracle. No equations, derivations, or fitted parameters are presented that reduce to quantities defined by the authors' own choices; the central claims rest on measured success rates rather than any self-definitional or self-citation chain.
Axiom & Free-Parameter Ledger
invented entities (1)
-
atomic-quality probe
no independent evidence
Reference graph
Works this paper leans on
-
[1]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. OpenVLA: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024. URL https://arxiv.org/abs/2406. 09246
work page internal anchor Pith review arXiv 2024
-
[2]
Ghosh, H
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy. InRobotics: Science and Systems (RSS), 2024. URLhttps://arxiv.org/abs/2405. 12213
2024
-
[3]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al.π0: A vision-language-action flow model for general robot control. InRobotics: Science and Systems (RSS), 2025. URL https://arxiv.org/ abs/2410.24164
work page internal anchor Pith review arXiv 2025
-
[4]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y. Chen, K. Ellis, et al. DROID: A large-scale in-the-wild robot 10 manipulation dataset. InRobotics: Science and Systems (RSS), 2024. URL https: //arxiv.org/abs/2403.12945
work page internal anchor Pith review arXiv 2024
-
[5]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, A. O’Neill, A. Rehman, A. Maddukuri, et al. Open X-embodiment: Robotic learning datasets and RT-X models. InICRA, 2024. URL https://arxiv.org/abs/2310.08864
work page internal anchor Pith review arXiv 2024
-
[6]
RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
A. Brohan, N. Brown, J. Carbajal, Y. Chebotar, X. Chen, K. Choromanski, T. Ding, D. Driess, A. Dubey, C. Finn, et al. RT-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning (CoRL), 2023. URL https://arxiv.org/abs/2307.15818
work page internal anchor Pith review arXiv 2023
- [8]
-
[9]
Y. Shao et al. SymSkill: Symbol and skill co-invention for data-efficient and reactive long- horizon manipulation.arXiv preprint arXiv:2510.01661, 2025. URLhttps://arxiv. org/abs/2510.01661. Jointly learns predicates, operators, skills from unsegmented demo; RoboCasa 6-step composition with real-time recovery
-
[10]
U. A. Mishra, S. Xue, Y. Chen, and D. Xu. Generative skill chaining: Long-horizon skill planning with diffusion models. InConference on Robot Learning (CoRL), 2023. URL https://arxiv.org/abs/2401.03360. Learns joint (precondition, skill params, effect) diffusion per skill; conditional sampling for chaining
-
[11]
G. Wang, Y. Xie, Y. Jiang, A. Mandlekar, C. Xiao, Y. Zhu, L. Fan, and A. Anandkumar. Voyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291, 2023. URL https://arxiv.org/abs/2305.16291. GPT-4 auto- generates executable code into a skill library with self-verification; append-only, no typed interfaces
work page internal anchor Pith review arXiv 2023
-
[12]
Zhang, J
J. Zhang, J. Zhang, K. Pertsch, Z. Liu, X. Ren, M. Chang, S.-H. Sun, and J. J. Lim. Bootstrap your own skills: Learning to solve new tasks with large language model guidance.CoRL, 2023. URL https://clvrai.github.io/boss/. BOSS: LLM-guided growing of skill library; chains base skills into long-horizon behaviors
2023
-
[14]
Continual skill discovery from open- vocabulary VLM; append-only skill library
URL https://arxiv.org/abs/2311.02058. Continual skill discovery from open- vocabulary VLM; append-only skill library
-
[15]
L. Keller, D. Tanneberg, and J. Peters. Neuro-symbolic imitation learning: Discovering symbolic abstractions for skill learning.arXiv preprint arXiv:2503.21406, 2025. URL https://arxiv.org/abs/2503.21406. Learns PDDL predicates + neural skills from demos; symbolic planning for abstract plans refined by neural skills
-
[16]
Y. Liang, N. Kumar, H. Tang, A. Weller, J. B. Tenenbaum, T. Silver, J. F. Henriques, and K. Ellis. VisualPredicator: Learning abstract world models with neuro-symbolic predicates for robot planning.arXiv preprint arXiv:2410.23156, 2024. URL https: //arxiv.org/abs/2410.23156. Neuro-symbolic predicates for abstract world model + planning
-
[17]
M. Ahn, A. Brohan, et al. Do as i can, not as i say: Grounding language in robotic affordances. InCoRL, 2022. URLhttps://arxiv.org/abs/2204.01691. LLM suggests actions weighted by learned affordance value function; foundational LLM+robotics. 11
work page internal anchor Pith review arXiv 2022
-
[18]
Code as Policies: Language Model Programs for Embodied Control
J. Liang, W. Huang, F. Xia, P. Xu, K. Hausman, B. Ichter, P. Florence, and A. Zeng. Code as policies: Language model programs for embodied control. InICRA, 2023. URL https://arxiv.org/abs/2209.07753. LLMs generate Python code that composes perception and control primitives
work page internal anchor Pith review arXiv 2023
-
[19]
Y. Lee, J. J. Lim, A. Anandkumar, and Y. Zhu. Adversarial skill chaining for long-horizon robot manipulation via terminal state regularization. InConference on Robot Learning (CoRL), 2021. URL https://arxiv.org/abs/2111.07999. T-STAR: terminal-state regularization for skill chaining; closest neighbor on hand-off-state mismatch
-
[20]
K. Pertsch, Y. Lee, and J. J. Lim. Accelerating reinforcement learning with learned skill priors. InCoRL, 2020. URL https://arxiv.org/abs/2010.11944. SPiRL: learn skill embedding + prior from offline data; foundational skill-prior work
- [21]
-
[22]
Z. Feng, H. Luan, K. Y. Ma, and H. Soh. Diffusion meets options: Hierarchical generative skill composition for temporally-extended tasks.arXiv preprint arXiv:2410.02389, 2024. URL https://arxiv.org/abs/2410.02389. DOPPLER: LTL-specified planning + HRL + diffusion options; navigation and manipulation
- [23]
-
[24]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fang, I. S. Wang, N. Yokoyama, D. Sadigh, S. Levine, J. Wu, and C. Finn. Evaluating real-world robot manipulation policies in simulation. InConference on Robot Learning (CoRL),
-
[25]
URLhttps://arxiv.org/abs/2405.05941
work page internal anchor Pith review arXiv
- [26]
-
[27]
C. Chi, S. Feng, Y. Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS),
-
[28]
URLhttps://arxiv.org/abs/2303.04137
work page internal anchor Pith review arXiv
-
[29]
T. Z. Zhao, V. Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipu- lation with low-cost hardware. InRobotics: Science and Systems (RSS), 2023. URL https://arxiv.org/abs/2304.13705. ACT: Action Chunking Transformer; canonical bimanual imitation-learning baseline
work page internal anchor Pith review arXiv 2023
-
[30]
J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences (PNAS), 114(13):3521–3526, 2017. doi:10.1073/pnas.1611835114
- [31]
-
[32]
B. Liu, Y. Zhu, C. Gao, Y. Feng, Q. Liu, Y. Zhu, and P. Stone. LIBERO: Benchmarking knowledge transfer for lifelong robot learning. InNeurIPS Datasets and Benchmarks,
-
[33]
LIBERO: Benchmarking Knowledge Transfer for Lifelong Robot Learning
URL https://arxiv.org/abs/2306.03310. 130 language-conditioned manipu- lation tasks; 4 suites including LIBERO-Long for skill chaining
work page internal anchor Pith review arXiv
-
[34]
X. Zhou, Y. Xu, G. Tie, Y. Chen, G. Zhang, D. Chu, P. Zhou, and L. Sun. LIBERO-PRO: Towards robust and fair evaluation of vision-language-action models beyond memo- rization.arXiv preprint arXiv:2510.03827, 2025. URL https://arxiv.org/abs/2510. 03827. Extended LIBERO eval across objects/init-states/instructions/environments; SOTA fails near-completely und...
-
[35]
Haresh, D
S. Haresh, D. Dijkman, A. Bhattacharyya, and R. Memisevic. ClevrSkills: Compositional language and visual reasoning in robotics. InNeurIPS Datasets and Benchmarks Track,
-
[36]
33 tasks over 3 compositional levels (L0/L1/L2) on ManiSkill2; even pretrained VLMs fail on L1/L2
URL https://arxiv.org/abs/2411.09052. 33 tasks over 3 compositional levels (L0/L1/L2) on ManiSkill2; even pretrained VLMs fail on L1/L2
-
[37]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. CALVIN: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 2022. URLhttps://arxiv.org/abs/2112.03227. Long-horizon language-conditioned benchmark; chains of up to 5 sub-goals
-
[38]
Y. Zhu, J. Wong, A. Mandlekar, R. Martín-Martín, A. Joshi, S. Nasiriany, and Y. Zhu. robosuite: A modular simulation framework and benchmark for robot learning.arXiv preprint arXiv:2009.12293, 2020. URL https://arxiv.org/abs/2009.12293. Stan- dard manipulation benchmark used in this paper
work page internal anchor Pith review arXiv 2009
-
[39]
Soft Actor-Critic Algorithms and Applications
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V. Kumar, H. Zhu, A. Gupta, P. Abbeel, and S. Levine. Soft actor-critic algorithms and applications.arXiv preprint arXiv:1812.05905, 2018. URLhttps://arxiv.org/abs/1812.05905
work page internal anchor Pith review arXiv 2018
-
[40]
Agarwal, M
R. Agarwal, M. Schwarzer, P. S. Castro, A. C. Courville, and M. G. Bellemare. Deep reinforcement learning at the edge of the statistical precipice. InAdvances in Neural Information Processing Systems (NeurIPS), 2021. URLhttps://arxiv.org/abs/2108. 13264
2021
-
[41]
A. Kumar, A. Raghunathan, R. Jones, T. Ma, and P. Liang. Fine-tuning can distort pretrained features and underperform out-of-distribution. InInternational Conference on Learning Representations (ICLR), 2022. URLhttps://arxiv.org/abs/2202.10054
-
[42]
S. Cheng and D. Xu. LEAGUE: Guided skill learning and abstraction for long-horizon manipulation.IEEE Robotics and Automation Letters, 2023. URL https://arxiv. org/abs/2210.12631
-
[43]
Y. Zhu, P. Stone, and Y. Zhu. Bottom-up skill discovery from unsegmented demon- strations for long-horizon robot manipulation.IEEE Robotics and Automation Letters, 2022
2022
-
[44]
Z. Chen, Z. Gao, J. Huo, and T. Ji. SCaR: Refining skill chaining for long-horizon robotic manipulation via dual regularization. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[45]
Y. Wang, Y. Zhang, M. Huo, R. Tian, X. Zhang, Y. Xie, C. Xu, P. Ji, W. Zhan, M. Ding, and M. Tomizuka. Sparse diffusion policy: A sparse, reusable, and flexible policy for robot learning. InConference on Robot Learning (CoRL), 2024
2024
-
[46]
G. M. van de Ven, T. Tuytelaars, and A. S. Tolias. Three types of incremental learning. Nature Machine Intelligence, 4:1185–1197, 2022. doi:10.1038/s42256-022-00568-3. 13
-
[47]
Y. Ding, Y. Liu, Y. Wang, and H. Wang. Evaluating forgetting in pretrained robotic policy networks: A continual learning study with Octo. InDICTA, 2025
2025
-
[48]
M. Wortsman, G. Ilharco, S. Y. Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y. Carmon, S. Kornblith, and L. Schmidt. Model soups: Averaging weights of multiple fine-tuned models improves accuracy without increasing inference time. InInternational Conference on Machine Learning (ICML), 2022. URL https://arxiv.org/abs/2203.05482
-
[49]
Editing Models with Task Arithmetic
G. Ilharco, M. T. Ribeiro, M. Wortsman, S. Gururangan, L. Schmidt, H. Hajishirzi, and A. Farhadi. Editing models with task arithmetic. InInternational Conference on Learning Representations (ICLR), 2023. URLhttps://arxiv.org/abs/2212.04089. A Hybrid Selector Pseudocode Algorithm 1Hybrid Skill-Update Selector Require:Old ECMc p, candidatec a, atomic probes...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.