Recognition: unknown
Language Diffusion Models are Associative Memories Capable of Retrieving Unseen Data
Pith reviewed 2026-05-07 12:15 UTC · model grok-4.3
The pith
Uniform-based discrete diffusion models function as associative memories that recover both training data and unseen examples through basins of attraction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
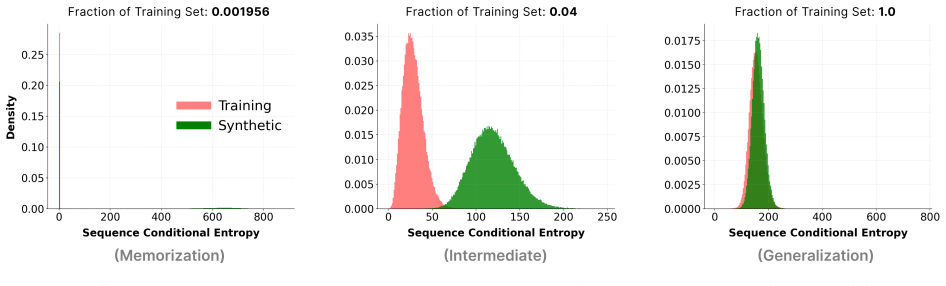
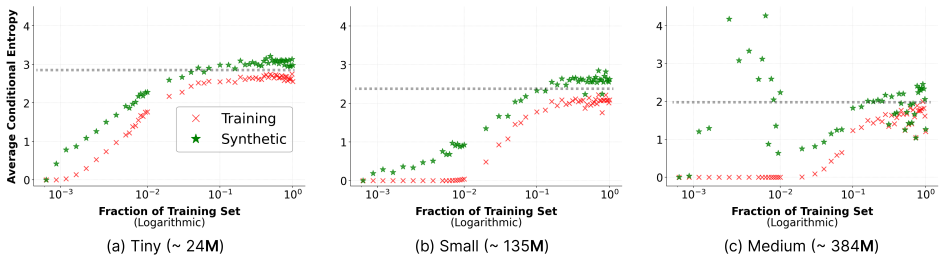
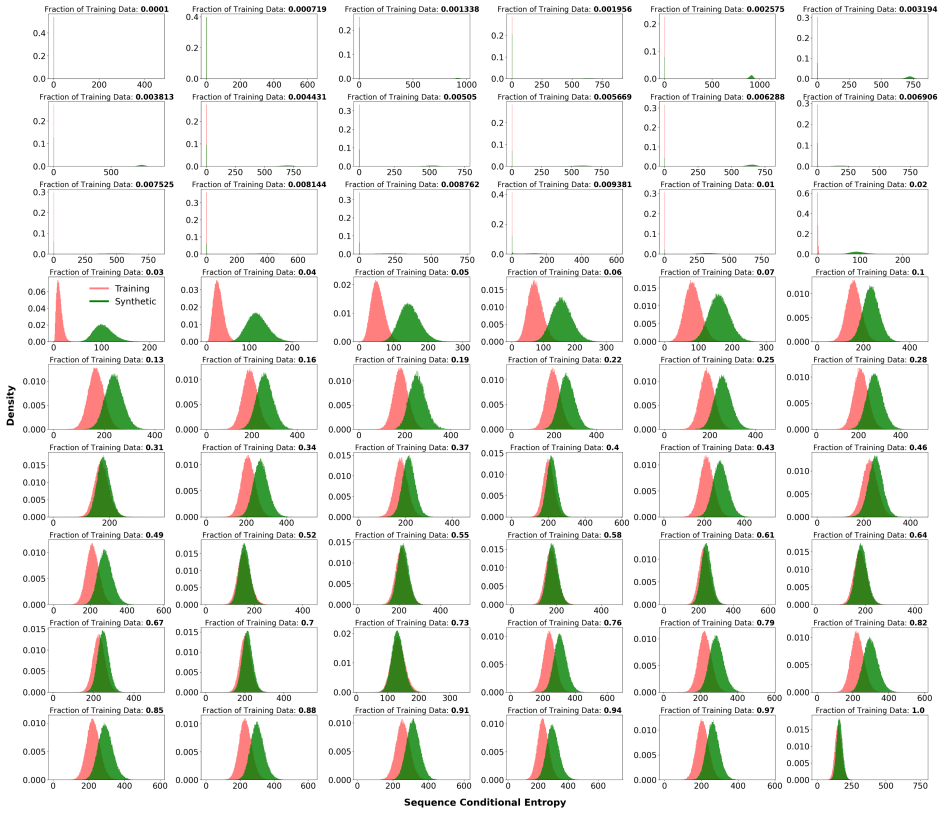
Uniform-based Discrete Diffusion Models behave as associative memories with emergent creative capabilities by forming distinct basins of attraction around both training and test data points through conditional likelihood maximization. As the size of the training dataset increases, basins around training examples shrink while those around unseen test examples expand until token recovery rates for both converge. The transition between memorization and generalization regimes can be detected solely by the conditional entropy of predicted token sequences, with vanishing entropy characterizing memorization and finite entropy indicating the generalization regime.
What carries the argument
Basins of attraction created by conditional likelihood maximization during the diffusion process, which enable reliable recovery of stored points without requiring an explicit energy function.
If this is right
- Recovery performance on training data falls while performance on unseen test data rises as the training set enlarges.
- Conditional entropy of token sequences provides a direct indicator of whether the model is in a memorization or generalization regime.
- At sufficiently large dataset sizes the model recovers training and test examples at comparable rates.
- The same conditional-likelihood mechanism that creates stable attractors around training points also creates attractors around unseen points.
Where Pith is reading between the lines
- The entropy-based probe could be applied to monitor regime shifts during training without storing the full dataset.
- Similar basin-expansion dynamics may occur in other likelihood-based generative models when dataset size is scaled.
- Adjusting training set size or monitoring entropy could offer a practical lever for balancing recall and novelty in deployed systems.
Load-bearing premise
Observed changes in how often the model recovers training versus test tokens as dataset size grows are produced by the growth and shrinkage of attraction basins under conditional likelihood maximization.
What would settle it
An experiment that varies training set size while holding model capacity fixed and finds that token recovery rates for training and test data do not follow the predicted opposing trends or that conditional entropy does not separate the two regimes.
Figures











read the original abstract
When do language diffusion models memorize their training data, and how to quantitatively assess their true generative regime? We address these questions by showing that Uniform-based Discrete Diffusion Models (UDDMs) fundamentally behave as Associative Memories (AMs) $\textit{with emergent creative capabilities}$. The core idea of an AM is to reliably recover stored data points as $\textit{memories}$ by establishing distinct basins of attraction around them. Historically, models like Hopfield networks use an explicit energy function to guarantee these stable attractors. We broaden this perspective by leveraging the observation that energy is not strictly necessary, as basins of attraction can also be formed via conditional likelihood maximization. By evaluating token recovery of $\textit{training}$ and $\textit{test}$ examples, we identify in UDDMs a sharp memorization-to-generalization transition governed by the size of the training dataset: as it increases, basins around training examples shrink and basins around unseen test examples expand, until both later converge to the same level. Crucially, we can detect this transition using only the conditional entropy of predicted token sequences: memorization is characterized by vanishing conditional entropy, while in the generalization regime the conditional entropy of most tokens remains finite. Thus, conditional entropy offers a practical probe for the memorization-to-generalization transition in deployed models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that Uniform-based Discrete Diffusion Models (UDDMs) fundamentally behave as associative memories (AMs) with emergent creative capabilities. Basins of attraction are formed around data points via conditional likelihood maximization (without explicit energy functions). Experiments on token recovery of training and test examples reveal a sharp memorization-to-generalization transition as training dataset size grows: basins around training points shrink while those around unseen test points expand until recovery rates converge. This transition is detectable using only the conditional entropy of predicted token sequences, with vanishing entropy indicating memorization and finite entropy indicating generalization.
Significance. If the empirical results and basin interpretation hold, the work offers a unifying perspective that connects discrete diffusion models to classical associative memory models such as Hopfield networks. The conditional-entropy probe could provide a practical, training-data-free diagnostic for memorization regimes in deployed generative models. The framing also highlights how scaling dataset size can induce generalization in diffusion-based language models, which may inform training strategies and evaluation practices.
major comments (3)
- Abstract and experimental results: Token-recovery rates after diffusion corruption are reported, but no tests of stability under additional perturbations, no comparisons to non-diffusion baselines, and no direct derivation of basin geometry from the conditional likelihood are provided. These omissions leave the central attribution of the observed transition to shrinking/expanding basins of attraction unsupported; the data are also consistent with ordinary scaling-law behavior.
- Abstract: The manuscript states that the transition 'can be detected using only the conditional entropy of predicted token sequences,' yet no quantitative validation (e.g., correlation coefficients, statistical significance, or ablation against other metrics) is described to establish entropy as a reliable basin detector rather than a correlated symptom of memorization.
- Experimental evaluation: No details are supplied on model sizes, dataset construction, statistical tests, controls for confounds such as optimization dynamics or capacity effects, or the precise definition of the 'sharp' transition threshold. Without these, the claimed sharpness and causal link to basin dynamics cannot be assessed.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major comment point by point below and indicate the revisions that will be incorporated into the next version of the manuscript.
read point-by-point responses
-
Referee: Abstract and experimental results: Token-recovery rates after diffusion corruption are reported, but no tests of stability under additional perturbations, no comparisons to non-diffusion baselines, and no direct derivation of basin geometry from the conditional likelihood are provided. These omissions leave the central attribution of the observed transition to shrinking/expanding basins of attraction unsupported; the data are also consistent with ordinary scaling-law behavior.
Authors: The reported recovery rates exhibit a distinctive crossover: as training set size grows, recovery of training examples declines while recovery of unseen test examples rises until the two converge. This relative decline for training points is inconsistent with standard scaling laws, which predict monotonic gains on both seen and unseen data. The basin interpretation follows directly from the model's objective of conditional likelihood maximization, which creates stable attractors around high-likelihood sequences without requiring an explicit energy function. In revision we will add (i) a formal derivation linking conditional likelihood maximization to basin geometry, (ii) stability tests under additional perturbations such as random token substitutions, and (iii) comparisons against non-diffusion baselines (e.g., a standard autoregressive transformer) to isolate diffusion-specific effects. revision: yes
-
Referee: Abstract: The manuscript states that the transition 'can be detected using only the conditional entropy of predicted token sequences,' yet no quantitative validation (e.g., correlation coefficients, statistical significance, or ablation against other metrics) is described to establish entropy as a reliable basin detector rather than a correlated symptom of memorization.
Authors: We agree that quantitative validation is needed. The revised manuscript will report Pearson correlation coefficients and p-values between conditional entropy and token-recovery accuracy across dataset sizes, together with ablations comparing entropy against alternative metrics such as prediction variance and KL divergence. These additions will establish entropy as a reliable, training-data-free probe for the memorization-to-generalization transition. revision: yes
-
Referee: Experimental evaluation: No details are supplied on model sizes, dataset construction, statistical tests, controls for confounds such as optimization dynamics or capacity effects, or the precise definition of the 'sharp' transition threshold. Without these, the claimed sharpness and causal link to basin dynamics cannot be assessed.
Authors: We will supply all omitted details in the revision: model architectures and sizes, dataset construction and split procedures, statistical tests with multiple random seeds and error bars, controls for confounds (fixed capacity while varying data size, hyperparameter sweeps), and a precise definition of the transition threshold (e.g., the dataset size at which train and test recovery rates differ by less than a fixed epsilon). These additions will allow readers to evaluate the sharpness of the transition and its link to basin dynamics. revision: yes
Circularity Check
No circularity: empirical recovery rates and entropy measurements are independent of the AM basin interpretation.
full rationale
The paper's central claims rest on direct empirical observations of token recovery accuracy for training versus test examples as a function of dataset size, together with conditional entropy of predicted tokens. These quantities are measured independently and then interpreted as evidence for shrinking/expanding basins of attraction formed by conditional likelihood maximization. No equations or definitions reduce the observed recovery rates or entropy values to the target AM behavior by construction. No self-citations, fitted parameters renamed as predictions, or uniqueness theorems are invoked as load-bearing steps. The derivation chain is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Basins of attraction can be formed via conditional likelihood maximization without requiring an explicit energy function.
Reference graph
Works this paper leans on
-
[1]
Deep unsupervised learning using nonequilibrium thermodynamics
Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan, and Surya Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. InInternational Conference on Machine Learning, 2015
2015
-
[2]
Denoisingdiffusionprobabilisticmodels.Advances in Neural Information Processing Systems, 2020
JonathanHo,AjayJain,andPieterAbbeel. Denoisingdiffusionprobabilisticmodels.Advances in Neural Information Processing Systems, 2020
2020
-
[3]
Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
Yang Song and Stefano Ermon. Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32, 2019
2019
-
[4]
Score-based generative modeling through stochastic differential equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations. In International Conference on Learning Representations, 2021. 12
2021
-
[5]
High-resolutionimagesynthesiswithlatentdiffusionmodels
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolutionimagesynthesiswithlatentdiffusionmodels. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[6]
Diffusion art or digital forgery? investigating data replication in diffusion models
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Diffusion art or digital forgery? investigating data replication in diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6048–6058, 2023
2023
-
[7]
Understanding and mitigating copying in diffusion models.Advances in Neural Information Processing Systems, 36:47783–47803, 2023
Gowthami Somepalli, Vasu Singla, Micah Goldblum, Jonas Geiping, and Tom Goldstein. Understanding and mitigating copying in diffusion models.Advances in Neural Information Processing Systems, 36:47783–47803, 2023
2023
-
[8]
Extractingtrainingdatafromdiffusionmodels
NicholasCarlini,JamieHayes,MiladNasr,MatthewJagielski,VikashSehwag,FlorianTramèr, BorjaBalle,DaphneIppolito,andEricWallace. Extractingtrainingdatafromdiffusionmodels. InProceedings of the 32nd USENIX Conference on Security Symposium, SEC ’23, USA, 2023. USENIX Association
2023
-
[9]
Ryan Webster. A reproducible extraction of training images from diffusion models.arXiv preprint arXiv:2305.08694, 2023
-
[10]
Diffusionprobabilisticmodels generalize when they fail to memorize
TaeHoYoon,JooYoungChoi,SehyunKwon,andErnestKRyu. Diffusionprobabilisticmodels generalize when they fail to memorize. InICML 2023 Workshop on Structured Probabilistic Inference Generative Modeling, 2023
2023
-
[11]
Zahra Kadkhodaie, Florentin Guth, Eero P Simoncelli, and Stéphane Mallat. Generalization in diffusion models arises from geometry-adaptive harmonic representation.arXiv preprint arXiv:2310.02557, 2023
-
[12]
Dynamical regimes of diffusion models.Nature Communications, 15(1), November 2024
Giulio Biroli, Tony Bonnaire, Valentin de Bortoli, and Marc Mézard. Dynamical regimes of diffusion models.Nature Communications, 15(1), November 2024
2024
-
[13]
Mason Kamb and Surya Ganguli. An analytic theory of creativity in convolutional diffusion models.arXiv preprint arXiv:2412.20292, 2024
-
[14]
arXiv preprint arXiv:2410.08727 , year=
Beatrice Achilli, Enrico Ventura, Gianluigi Silvestri, Bao Pham, Gabriel Raya, Dmitry Krotov, Carlo Lucibello, and Luca Ambrogioni. Losing dimensions: Geometric memorization in generative diffusion.arXiv preprint arXiv:2410.08727, 2024
-
[15]
Detecting, explaining, and mitigating memorization in diffusion models
Yuxin Wen, Yuchen Liu, Chen Chen, and Lingjuan Lyu. Detecting, explaining, and mitigating memorization in diffusion models. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[16]
Dongjae Jeon, Dueun Kim, and Albert No. Understanding memorization in generative models via sharpness in probability landscapes.arXiv preprint arXiv:2412.04140, 2024
-
[17]
Bao Pham, Gabriel Raya, Matteo Negri, Mohammed J Zaki, Luca Ambrogioni, and Dmitry Krotov. Memorization to generalization: Emergence of diffusion models from associative memory.arXiv preprint arXiv:2505.21777, 2025. 13
-
[18]
Beatrice Achilli, Luca Ambrogioni, Carlo Lucibello, Marc Mézard, and Enrico Ventura. Memorization and generalization in generative diffusion under the manifold hypothesis.arXiv preprint arXiv:2502.09578, 2025
-
[19]
Languagemodelsare few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
TomBrown,BenjaminMann,NickRyder,MelanieSubbiah,JaredDKaplan,PrafullaDhariwal, ArvindNeelakantan,PranavShyam,GirishSastry,AmandaAskell,etal. Languagemodelsare few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[20]
Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
2022
-
[21]
Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
Jacob Austin, Daniel D Johnson, Jonathan Ho, Daniel Tarlow, and Rianne Van Den Berg. Structured denoising diffusion models in discrete state-spaces.Advances in neural information processing systems, 34:17981–17993, 2021
2021
-
[22]
Andrew Campbell, Jason Yim, Regina Barzilay, Tom Rainforth, and Tommi Jaakkola. Genera- tive flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design.arXiv preprint arXiv:2402.04997, 2024
-
[23]
Discrete flow matching.Advances in Neural Information Processing Systems, 37:133345–133385, 2024
Itai Gat, Tal Remez, Neta Shaul, Felix Kreuk, Ricky TQ Chen, Gabriel Synnaeve, Yossi Adi, and Yaron Lipman. Discrete flow matching.Advances in Neural Information Processing Systems, 37:133345–133385, 2024
2024
-
[24]
Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
SubhamSahoo,MarianneArriola,YairSchiff,AaronGokaslan,EdgarMarroquin,JustinChiu, Alexander Rush, and Volodymyr Kuleshov. Simple and effective masked diffusion language models.Advances in Neural Information Processing Systems, 37:130136–130184, 2024
2024
-
[25]
Modern methods in associative memory.arXiv preprint arXiv:2507.06211, 2025
Dmitry Krotov, Benjamin Hoover, Parikshit Ram, and Bao Pham. Modern methods in associative memory.arXiv preprint arXiv:2507.06211, 2025
-
[26]
Neuralnetworksandphysicalsystemswithemergentcollectivecomputational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
JohnJ.Hopfield. Neuralnetworksandphysicalsystemswithemergentcollectivecomputational abilities.Proceedings of the National Academy of Sciences, 79(8):2554–2558, 1982
1982
-
[27]
The space of interactions in neural network models.Journal of physics A: Mathematical and general, 21(1):257, 1988
Elizabeth Gardner. The space of interactions in neural network models.Journal of physics A: Mathematical and general, 21(1):257, 1988
1988
-
[28]
Statistical mechanics of neural networks near saturation.Annals of physics, 173(1):30–67, 1987
Daniel J Amit, Hanoch Gutfreund, and Haim Sompolinsky. Statistical mechanics of neural networks near saturation.Annals of physics, 173(1):30–67, 1987
1987
-
[29]
Malatesta, and Matteo Negri
Silvio Kalaj, Clarissa Lauditi, Gabriele Perugini, Carlo Lucibello, Enrico M. Malatesta, and Matteo Negri. Random features hopfield networks generalize retrieval to previously unseen examples.Physica A: Statistical Mechanics and its Applications, 678:130946, 2025
2025
-
[30]
Gabriele Farné, Fabrizio Boncoraglio, and Lenka Zdeborová. The rules-and-facts model for simultaneous generalization and memorization in neural networks.arXiv preprint arXiv:2603.25579, 2026. 14
-
[31]
Learning patterns and pattern sequences by self-organizing nets of threshold elements.IEEE Transactions on computers, 100(11):1197–1206, 1972
S-I Amari. Learning patterns and pattern sequences by self-organizing nets of threshold elements.IEEE Transactions on computers, 100(11):1197–1206, 1972
1972
-
[32]
Hopfield
Dmitry Krotov and John J. Hopfield. Dense associative memory for pattern recognition. In D. Lee, M. Sugiyama, U. Luxburg, I. Guyon, and R. Garnett, editors,Advances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
2016
-
[33]
Large associative memory problem in neurobiology and machine learning
Dmitry Krotov and John J Hopfield. Large associative memory problem in neurobiology and machine learning. InInternational Conference on Learning Representations, 2021
2021
-
[34]
Pseudo-likelihood produces associative memories able to generalize, even for asymmetric couplings.Physica A: Statistical Mechanics and its Applications, 692:131497, 2026
Francesco D’Amico, Dario Bocchi, Luca Maria Del Bono, Saverio Rossi, and Matteo Negri. Pseudo-likelihood produces associative memories able to generalize, even for asymmetric couplings.Physica A: Statistical Mechanics and its Applications, 692:131497, 2026
2026
-
[35]
Hierarchical associative memory.arXiv preprint 2107.06446, 2021
Dmitry Krotov. Hierarchical associative memory.arXiv preprint 2107.06446, 2021
-
[36]
Energy transformer
Benjamin Hoover, Yuchen Liang, Bao Pham, Rameswar Panda, Hendrik Strobelt, Duen Horng Chau, Mohammed Zaki, and Dmitry Krotov. Energy transformer. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 27532–27559. Curran Associates, Inc., 2023
2023
-
[37]
Neuron–astrocyte associative memory.Proceedings of the National Academy of Sciences, 122(21):e2417788122, 2025
Leo Kozachkov, Jean-Jacques Slotine, and Dmitry Krotov. Neuron–astrocyte associative memory.Proceedings of the National Academy of Sciences, 122(21):e2417788122, 2025
2025
-
[38]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[39]
Spatial interaction and the statistical analysis of lattice systems.Journal of the Royal Statistical Society
Julian Besag. Spatial interaction and the statistical analysis of lattice systems.Journal of the Royal Statistical Society. Series B (Methodological), 36(2):192–236, 1974
1974
-
[40]
The organization of behavior: A neuropsychological theory
Donald Olding Hebb. The organization of behavior: A neuropsychological theory. 1949
1949
-
[41]
BenjaminHoover,HendrikStrobelt,DmitryKrotov,JudyHoffman,ZsoltKira,andDuenHorng Chau. Memoryinplainsight: Asurveyoftheuncannyresemblancesbetweendiffusionmodels and associative memories.arXiv preprint arXiv:2309.16750, 2023
-
[42]
LucaAmbrogioni.Insearchofdispersedmemories: Generativediffusionmodelsareassociative memory networks.Entropy, 26(5):381, 2024
2024
-
[43]
Francesco Cagnetta, Allan Raventós, Surya Ganguli, and Matthieu Wyart. Deriving neural scaling laws from the statistics of natural language.arXiv preprint arXiv:2602.07488, 2026
-
[44]
The diffusion duality.International Conference on Machine Learning, 42, 2025
Subham Sekhar Sahoo, Justin Deschenaux, Aaron Gokaslan, Guanghan Wang, Justin T Chiu, and Volodymyr Kuleshov. The diffusion duality.International Conference on Machine Learning, 42, 2025
2025
-
[45]
One billion word benchmark for measuring progress in statistical language modeling
Ciprian Chelba, Tomas Mikolov, Mike Schuster, Qi Ge, Thorsten Brants, Phillipp Koehn, and Tony Robinson. One billion word benchmark for measuring progress in statistical language modeling.arXiv preprint arXiv:1312.3005, 2013. 15
-
[46]
Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in Neural Information Processing Systems, 34, 2021
Emiel Hoogeboom, Didrik Nielsen, Amir Abdolshahi, and Arash Vahdat. Argmax flows and multinomial diffusion: Learning categorical distributions.Advances in Neural Information Processing Systems, 34, 2021
2021
-
[47]
Chiu, Alexander Rush, and Volodymyr Kuleshov
AaronLou,ChenlinMeng,andStefanoErmon. Maskeddiffusionmodelsaremaskedlanguage models.arXiv preprint arXiv:2406.07524, 2024
-
[48]
Scalablediffusionmodelswithtransformers
WilliamPeeblesandSainingXie. Scalablediffusionmodelswithtransformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[49]
Optimalstoragepropertiesofneuralnetworkmodels.Journal of Physics A, 21:271–284, 1988
E.GardnerandBernardDerrida. Optimalstoragepropertiesofneuralnetworkmodels.Journal of Physics A, 21:271–284, 1988
1988
-
[50]
Content-addressability and learning in neural networks.Journal of Physics A: Mathematical and General, 21(1):245, 1988
BM Forrest. Content-addressability and learning in neural networks.Journal of Physics A: Mathematical and General, 21(1):245, 1988
1988
-
[51]
Supervised perceptron learning vs unsupervised hebbian unlearning: Approaching optimal memory retrieval in hopfield-like networks.The Journal of Chemical Physics, 156(10), 2022
Marco Benedetti, Enrico Ventura, Enzo Marinari, Giancarlo Ruocco, and Francesco Zamponi. Supervised perceptron learning vs unsupervised hebbian unlearning: Approaching optimal memory retrieval in hopfield-like networks.The Journal of Chemical Physics, 156(10), 2022
2022
-
[52]
The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
Daniel Soudry, Elad Hoffer, Mor Shpigel Nacson, Suriya Gunasekar, and Nathan Srebro. The implicit bias of gradient descent on separable data.Journal of Machine Learning Research, 19(70):1–57, 2018
2018
-
[53]
Andrea Montanari, Yiqiao Zhong, and Kangjie Zhou. Tractability from overparametrization: Theexampleofthenegativeperceptron.Probability Theory and Related Fields,188(3–4):805– 910, 2024. arXiv:2110.15824
-
[54]
A new frontier for Hopfield networks.Nature Reviews Physics, 5(7):366–367, July 2023
Dmitry Krotov. A new frontier for Hopfield networks.Nature Reviews Physics, 5(7):366–367, July 2023
2023
-
[55]
Language models are unsupervised multitask learners
AlecRadford,JeffWu,RewonChild,DavidLuan,DarioAmodei,andIlyaSutskever. Language models are unsupervised multitask learners. 2019. 16 Appendix A Additional Details on Memorization to Generalization 18 B Uniform-state Discrete Diffusion and Duality with Gaussian 19 C Conditional Entropy and Curvature 20 D Additional Results 21 D.1 Shrinkage and Expansion of ...
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.