Recognition: no theorem link
Policy-Governed LLM Routing with Intent Matching for Instrument Laboratories
Pith reviewed 2026-05-13 18:55 UTC · model grok-4.3
The pith
Governed policies for LLM routing in engineering labs raise challenge-alignment to 0.98 and reduce costs by 66% while extending productive struggle.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
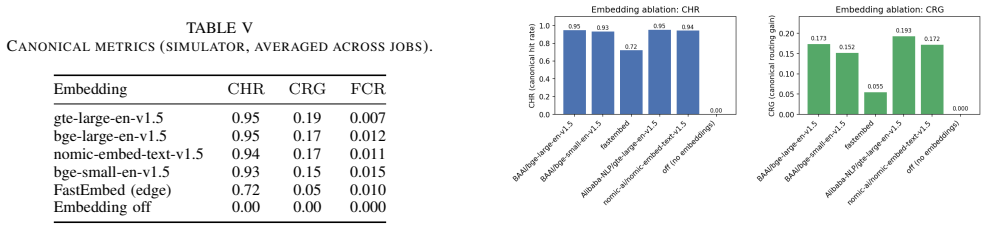
EduRouter is a policy-aware routing service that sits atop Routiium and applies per-lab budgets, approval workflows, and embedding-based intent matching to decide which model answers each student query. When governed policies are active, the challenge-alignment index rises from 0.90 to 0.98, overlay-adherence rises from 0.69 to 0.87, and the productive-struggle window lengthens from 1.4 to 3.6 simulated turns; a 100-query replay routes 75% of queries to a local model for a 66% token-cost reduction while keeping the canonical hit rate at 1.0 on an 89-intent question bank.
What carries the argument
EduRouter, the policy-aware routing service that uses embedding-based question matching to enforce governance rules, budgets, and approval workflows on LLM queries in lab settings.
If this is right
- Instructors gain direct control over assistance timing, content, and cost through per-lab budgets and approval workflows.
- Students experience longer periods of productive struggle before high-scaffold hints appear.
- Token costs drop by 66% when 75% of queries route to local models.
- Canonical hit rate on the 89-intent question bank stays at 1.0.
- Released tools and simulator configurations support replication in additional classroom settings.
Where Pith is reading between the lines
- The routing approach could extend to other tutoring domains such as programming exercises where cost control and hint timing are also concerns.
- If longer productive-struggle windows lead to better retention, governed policies would improve actual learning outcomes beyond the reported indices.
- Real-time classroom data could allow dynamic adjustment of policies based on observed student progress.
Load-bearing premise
The trace-driven simulation calibrated from LED characterization and RC circuit analysis labs accurately predicts real student behavior, learning outcomes, and the effectiveness of embedding-based intent matching.
What would settle it
A live classroom deployment in an engineering lab that records actual student query patterns, learning gains, and engagement under governed versus ungoverned routing to check whether the simulated metric improvements occur.
Figures




read the original abstract
AI tutoring systems in engineering labs face a tension between providing sufficient assistance and preserving learning opportunities. Existing systems typically offer instructors limited control over assistance timing, content, or cost. This paper describes a routing and governance system for LLM-based lab assistance comprising two components: Routiium, an OpenAI-compatible gateway that manages multiple LLM backends with configurable prompt modifications and usage logging, and EduRouter, a policy-aware routing service that enforces per-lab budgets, approval workflows, and embedding-based question matching. We evaluated the system using trace-driven simulation calibrated from two engineering labs (LED characterization, RC circuit analysis) and a 100-query replay through live models. In simulations, governed policies (P1/P2) increased challenge-alignment index from 0.90 to 0.98 and overlay-adherence score from 0.69 to 0.87 compared to ungoverned operation (P0). The productive-struggle window metric increased from 1.4 to 3.6 simulated turns before high-scaffold hints appeared. In the 100-query replay, EduRouter routed 75% of queries to a local model, reducing token costs by 66% ($0.087 vs. $0.26 for all-premium routing) while maintaining canonical hit rate of 1.0 for the curated 89-intent question bank. We release Routiium, EduRouter, canonical-task tooling, and simulator configurations to support replication and future classroom studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a system consisting of Routiium, an OpenAI-compatible gateway for managing multiple LLM backends, and EduRouter, a policy-aware routing service that enforces budgets, approval workflows, and embedding-based intent matching for AI assistance in engineering instrument laboratories. Using trace-driven simulations calibrated from LED characterization and RC circuit analysis labs, along with a 100-query live model replay, the authors report that policy-governed operations (P1/P2) improve the challenge-alignment index from 0.90 to 0.98 and overlay-adherence score from 0.69 to 0.87 relative to ungoverned operation (P0), extend the productive-struggle window from 1.4 to 3.6 simulated turns, route 75% of queries to local models, and reduce token costs by 66% while preserving a canonical hit rate of 1.0.
Significance. Should the simulation results generalize to live student use, the approach would provide instructors with practical mechanisms to govern LLM assistance in lab settings, balancing support with opportunities for productive struggle and achieving substantial cost reductions through intelligent routing. The public release of the software components strengthens the contribution by enabling replication and extension.
major comments (1)
- [Evaluation] Evaluation: The reported metric gains (challenge-alignment index 0.90 to 0.98, overlay-adherence 0.69 to 0.87, productive-struggle window 1.4 to 3.6 turns) and cost savings (75% local routing, 66% reduction) are obtained exclusively from trace-driven simulation calibrated on two lab traces plus a 100-query replay. No live classroom deployment data is presented to confirm that the embedding-based intent matcher sustains a canonical hit rate of 1.0 against the 89-intent bank with variable student phrasing or that the policy-enforced productive-struggle window produces improved learning outcomes rather than merely delaying high-scaffold hints in the simulator.
minor comments (1)
- [Abstract] Abstract: The abstract references 'canonical-task tooling' without definition; ensure this is clearly explained in the main body with an example.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comments on our evaluation methodology. We address the concerns regarding the simulation-based evaluation below.
read point-by-point responses
-
Referee: [Evaluation] Evaluation: The reported metric gains (challenge-alignment index 0.90 to 0.98, overlay-adherence 0.69 to 0.87, productive-struggle window 1.4 to 3.6 turns) and cost savings (75% local routing, 66% reduction) are obtained exclusively from trace-driven simulation calibrated on two lab traces plus a 100-query replay. No live classroom deployment data is presented to confirm that the embedding-based intent matcher sustains a canonical hit rate of 1.0 against the 89-intent bank with variable student phrasing or that the policy-enforced productive-struggle window produces improved learning outcomes rather than merely delaying high-scaffold hints in the simulator.
Authors: We agree that the current evaluation is limited to trace-driven simulation and a controlled replay, which does not include live classroom deployment data. This is a deliberate choice for the initial study to ensure safety and control while calibrating from real lab traces. We cannot provide live data in this revision as it would require separate IRB approval and student recruitment. However, we have revised the manuscript to include an expanded Limitations section that explicitly acknowledges the potential impact of variable student phrasing on the intent matcher and the distinction between simulated productive struggle and actual learning gains. We also outline plans for future live deployment studies to validate these aspects. The simulation results demonstrate the feasibility and potential benefits of the policy-governed routing, providing a foundation for such studies. revision: yes
- Live classroom deployment data to confirm real-world performance with variable student inputs and learning outcomes
Circularity Check
No significant circularity; results derive from independent simulation replay
full rationale
The paper's central claims rest on trace-driven simulation calibrated from two external lab traces and a separate 100-query live-model replay. Metrics such as challenge-alignment index, overlay-adherence score, and productive-struggle window are defined independently of the routing logic and are measured as outputs of the simulator rather than fitted parameters renamed as predictions. No self-citations, uniqueness theorems, or ansatzes are invoked to justify the core results; the evaluation chain remains self-contained against the provided simulation inputs without reducing any reported gain to a definitional identity or fitted input.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Embedding-based matching can reliably identify student questions against a curated 89-intent bank for lab tasks.
- domain assumption Trace-driven simulation calibrated on two specific labs generalizes to student interaction patterns.
Reference graph
Works this paper leans on
-
[1]
The role of tutoring in problem solving,
D. Wood, J. S. Bruner, and G. Ross, “The role of tutoring in problem solving,”Journal of child psychology and psychiatry, vol. 17, no. 2, pp. 89–100, 1976
work page 1976
-
[2]
Exploring the assistance dilemma in experiments with cognitive tutors,
K. R. Koedinger and V . Aleven, “Exploring the assistance dilemma in experiments with cognitive tutors,”Educational psychology review, vol. 19, no. 3, pp. 239–264, 2007
work page 2007
-
[3]
K. VanLehn, “The relative effectiveness of human tutoring, intelligent tutoring systems, and other tutoring systems,”Educational psychologist, vol. 46, no. 4, pp. 197–221, 2011
work page 2011
-
[4]
K. K. Maurya, K. A. Srivatsa, K. Petukhova, and E. Kochmar, “Unifying ai tutor evaluation: An evaluation taxonomy for pedagogical ability assessment of llm-powered ai tutors,” inProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), 20...
work page 2025
-
[5]
Training llm-based tutors to improve student learning outcomes in dialogues,
A. Scarlatos, N. Liu, J. Lee, R. Baraniuk, and A. Lan, “Training llm-based tutors to improve student learning outcomes in dialogues,” inInternational Conference on Artificial Intelligence in Education. Springer, 2025, pp. 251–266
work page 2025
-
[6]
Chatgpt for good? on opportunities and challenges of large language models for education,
E. Kasneci, K. Seßler, S. K ¨uchemann, M. Bannert, D. Dementieva, F. Fischer, U. Gasser, G. Groh, S. G ¨unnemann, E. H ¨ullermeieret al., “Chatgpt for good? on opportunities and challenges of large language models for education,”Learning and individual differences, vol. 103, p. 102274, 2023
work page 2023
-
[7]
E. R. Mollick and L. Mollick, “Using ai to implement effective teach- ing strategies in classrooms: Five strategies, including prompts,”The Wharton School Research Paper, 2023
work page 2023
-
[8]
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance
L. Chen, M. Zaharia, and J. Zou, “Frugalgpt: How to use large language models while reducing cost and improving performance,”arXiv preprint arXiv:2305.05176, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
RouteLLM: Learning to Route LLMs with Preference Data
I. Ong, A. Almahairi, V . Wu, W.-L. Chiang, T. Wu, J. E. Gonzalez, M. W. Kadous, and I. Stoica, “Routellm: Learning to route llms with preference data,”arXiv preprint arXiv:2406.18665, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Thriftllm: On cost-effective selection of large language models for classification queries,
K. Huang, Y . Shi, D. Ding, Y . Li, Y . Fei, L. Lakshmanan, and X. Xiao, “Thriftllm: On cost-effective selection of large language models for classification queries,”arXiv preprint arXiv:2501.04901, 2025
-
[11]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
N. Reimers and I. Gurevych, “Sentence-bert: Sentence embeddings using siamese bert-networks,”arXiv preprint arXiv:1908.10084, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1908
-
[12]
SimCSE: Simple Contrastive Learning of Sentence Embeddings
T. Gao, X. Yao, and D. Chen, “Simcse: Simple contrastive learning of sentence embeddings,”arXiv preprint arXiv:2104.08821, 2021
work page internal anchor Pith review arXiv 2021
-
[13]
Dense passage retrieval for open-domain question answering
V . Karpukhin, B. Oguz, S. Min, P. S. Lewis, L. Wu, S. Edunov, D. Chen, and W.-t. Yih, “Dense passage retrieval for open-domain question answering.” inEMNLP (1), 2020, pp. 6769–6781
work page 2020
-
[14]
Learning analytics: The emergence of a discipline,
G. Siemens, “Learning analytics: The emergence of a discipline,” American Behavioral Scientist, vol. 57, no. 10, pp. 1380–1400, 2013
work page 2013
-
[15]
Ethical and privacy principles for learning analytics,
A. Pardo and G. Siemens, “Ethical and privacy principles for learning analytics,”British journal of educational technology, vol. 45, no. 3, pp. 438–450, 2014
work page 2014
-
[16]
Classroom orchestration: The third circle of usability,
P. Dillenbourg, G. Zufferey, H. Alavi, P. Jermann, S. Do-Lenh, Q. Bon- nard, S. Cuendet, and F. Kaplan, “Classroom orchestration: The third circle of usability,” 2011
work page 2011
-
[17]
Co-designing a real-time classroom orchestration tool to support teacher-ai complementarity
K. Holstein, B. M. McLaren, and V . Aleven, “Co-designing a real-time classroom orchestration tool to support teacher-ai complementarity.” Grantee Submission, 2019
work page 2019
-
[18]
One head, many models: Cross-attention routing for cost-aware llm selection,
R. Pulishetty, M. K. Ghantasala, K. K. Dasoju, N. Mangwani, V . Garimella, A. Mate, S. Chatterjee, Y . Kang, E. Nosakhare, S. Hasan et al., “One head, many models: Cross-attention routing for cost-aware llm selection,”arXiv preprint arXiv:2509.09782, 2025
-
[19]
Retrieval- augmented generation for knowledge-intensive nlp tasks,
P. Lewis, E. Perez, A. Piktus, F. Petroni, V . Karpukhin, N. Goyal, H. K ¨uttler, M. Lewis, W.-t. Yih, T. Rockt ¨aschelet al., “Retrieval- augmented generation for knowledge-intensive nlp tasks,”Advances in neural information processing systems, vol. 33, pp. 9459–9474, 2020
work page 2020
-
[20]
Virtual laboratory for engineering education: Review of virtual laboratory for students learning,
I. Veza, A. Sule, N. R. Putra, M. Idris, I. Ghazali, I. Irianto, U. C. Pendit, G. Moslianoet al., “Virtual laboratory for engineering education: Review of virtual laboratory for students learning,”Engineering Science Letter, vol. 1, no. 02, pp. 41–46, 2022
work page 2022
-
[21]
Remote labs in higher engineering education: engaging students with active learning pedagogy,
A. Van den Beemt, S. Groothuijsen, L. Ozkan, and W. Hendrix, “Remote labs in higher engineering education: engaging students with active learning pedagogy,”Journal of Computing in Higher Education, vol. 35, no. 2, pp. 320–340, 2023
work page 2023
-
[22]
Are virtual laboratories and remote laboratories enhancing the quality of sustainability education?
M. C.-P. Poo, Y .-y. Lau, and Q. Chen, “Are virtual laboratories and remote laboratories enhancing the quality of sustainability education?” Education Sciences, vol. 13, no. 11, p. 1110, 2023
work page 2023
-
[23]
S. Alsaleh, A. Tepljakov, A. K ¨ose, J. Belikov, and E. Petlenkov, “Reimagine lab: Bridging the gap between hands-on, virtual and remote control engineering laboratories using digital twins and extended reality,” IEEE Access, vol. 10, pp. 89 924–89 943, 2022
work page 2022
-
[24]
Teaching digital electronics during the covid-19 pandemic via a remote lab,
F. Valencia de Almeida, V . T. Hayashi, R. Arakaki, E. Midorikawa, S. de Mello Canovas, P. S. Cugnasca, and P. L. P. Corr ˆea, “Teaching digital electronics during the covid-19 pandemic via a remote lab,”Sensors, vol. 22, no. 18, 2022. [Online]. Available: https://www.mdpi.com/1424-8220/22/18/6944
work page 2022
-
[25]
Virtual labs: An effective engineering education tool for remote learning and not only,
L. Rassudov and A. Korunets, “Virtual labs: An effective engineering education tool for remote learning and not only,” in2022 29th Interna- tional Workshop on Electric Drives: Advances in Power Electronics for Electric Drives (IWED). IEEE, 2022, pp. 1–4
work page 2022
-
[26]
Learning analytics dashboards: The past, the present and the future,
K. Verbert, X. Ochoa, R. De Croon, R. A. Dourado, and T. De Laet, “Learning analytics dashboards: The past, the present and the future,” in Proceedings of the tenth international conference on learning analytics & knowledge, 2020, pp. 35–40
work page 2020
-
[27]
O. Karademir, L. Borgards, D. Di Mitri, S. Strauß, M. Kubsch, M. Brobeil, A. Grimm, S. Gombert, N. Rummel, K. Neumannet al., “Following the impact chain of the la cockpit: an intervention study investigating a teacher dashboard’s effect on student learning,”Journal of Learning Analytics, vol. 11, pp. 215–228, 2024
work page 2024
-
[28]
Learning analytics dash- boards for adaptive support in face-to-face collaborative argumentation,
J. Han, K. H. Kim, W. Rhee, and Y . H. Cho, “Learning analytics dash- boards for adaptive support in face-to-face collaborative argumentation,” Computers & Education, vol. 163, p. 104041, 2021
work page 2021
-
[29]
Making sense of learning analytics dashboards: A technology accep- tance perspective of 95 teachers,
B. Rienties, C. Herodotou, T. Olney, M. Schencks, and A. Boroowa, “Making sense of learning analytics dashboards: A technology accep- tance perspective of 95 teachers,”International Review of Research in Open and Distributed Learning, vol. 19, no. 5, 2018
work page 2018
-
[30]
G. M. Fernandez Nieto, K. Kitto, S. Buckingham Shum, and R. Martinez-Maldonado, “Beyond the learning analytics dashboard: Alternative ways to communicate student data insights combining vi- sualisation, narrative and storytelling,” inLAK22: 12th international learning analytics and knowledge conference, 2022, pp. 219–229
work page 2022
-
[31]
M. Polignano, M. De Gemmis, and G. Semeraro, “Unraveling the enigma of split in large-language models: The unforeseen impact of system prompts on llms with dissociative identity disorder,” inPro- ceedings of the 10th Italian Conference on Computational Linguistics (CLiC-it 2024), 2024, pp. 774–780
work page 2024
-
[32]
Position is power: System prompts as a mechanism of bias in large language models (llms),
A. Neumann, E. Kirsten, M. B. Zafar, and J. Singh, “Position is power: System prompts as a mechanism of bias in large language models (llms),” inProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, 2025, pp. 573–598
work page 2025
-
[33]
Rnr: Teaching large language models to follow roles and rules,
K. Wang, A. Bukharin, H. Jiang, Q. Yin, Z. Wang, T. Zhao, J. Shang, C. Zhang, B. Yin, X. Liet al., “Rnr: Teaching large language models to follow roles and rules,”arXiv preprint arXiv:2409.13733, 2024
-
[34]
Labiium: AI-enhanced zero-configuration measurement automation system,
E. A. Olowe and D. Chitnis, “Labiium: AI-enhanced zero-configuration measurement automation system,” inProceedings of the IEEE In- ternational Instrumentation and Measurement Technology Conference (I2MTC), 2025, pp. 1–6
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.