Recognition: unknown
Adaptive Confidence Intervals in Efron's Gaussian Two-Groups Model
Pith reviewed 2026-05-07 14:08 UTC · model grok-4.3
The pith
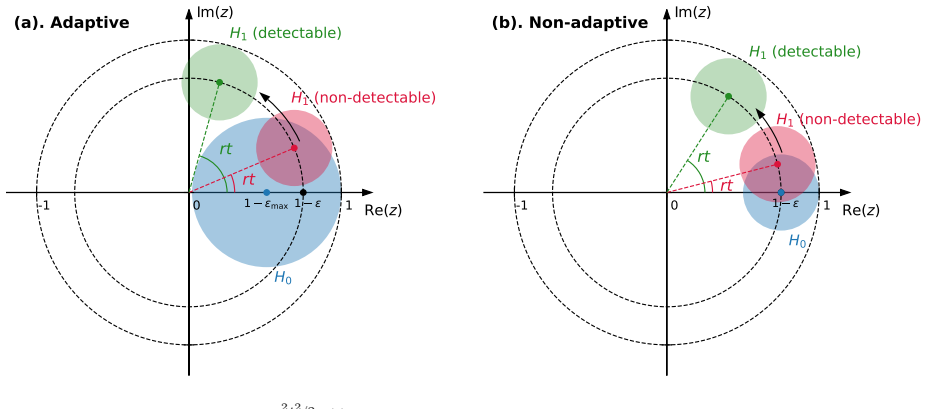
In the Gaussian two-groups model, confidence intervals adaptive to unknown contamination fraction ε must have length of order σ(n^{-1/4} + ε^{1/2} / sqrt(log term)) when variance is known.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We characterize the minimax-optimal length among confidence intervals with a prescribed coverage level uniformly over the unknown contamination proportion and all noise-oblivious adversaries. Although prior work has shown that the minimax point estimation rate of theta does not deteriorate when ε becomes unknown, our results reveal that, with a given σ², the minimax-optimal length of confidence intervals that are adaptive to unknown ε is of order σ (n^{-1/4} + ε^{1/2}/max{1, log(en ε²)}^{1/2}), which is polynomially worse than the optimal length when ε is known. When the variance σ² is also unknown, we show a further degradation: no adaptive confidence interval can be shorter than Ω(σ n^{-1/
What carries the argument
Fourier-based certification procedure that scans candidate points and accepts those whose residual characteristic function is certifiably consistent with a Gaussian location mixture via Carathéodory positive-semidefiniteness constraints.
If this is right
- With known variance the adaptive interval length is strictly larger by a polynomial factor in n than the length achievable when ε is known.
- When variance must also be estimated, no adaptive interval can improve on the slower Ω(σ n^{-1/8}) lower bound.
- The Fourier certification algorithm runs in polynomial time and matches the minimax length in the known-variance regime.
- The uniform coverage guarantee holds simultaneously for every possible ε and every noise-oblivious adversary.
Where Pith is reading between the lines
- Practitioners facing similar mean-shift contamination may need to accept intervals that shrink only like n^{-1/4} even after collecting many more samples.
- The separation between estimation and interval estimation rates suggests that testing or selection procedures built on these intervals will also pay the extra n^{-1/4} price.
- The same Fourier-characteristic-function approach could be tested on other mixture models where the contamination is restricted to location shifts.
- Numerical checks on synthetic two-groups data with known ε should recover the non-adaptive length while unknown-ε trials should require the longer scaling.
Load-bearing premise
All samples share the same law of additive Gaussian measurement noise, and contamination enters only through arbitrary mean shifts rather than changes to the noise distribution itself.
What would settle it
A sequence of data sets with increasing n and fixed ε where the shortest interval achieving uniform 1-α coverage has length that fails to match the stated order σ(n^{-1/4} + ε^{1/2}/log term) or where the Fourier certification algorithm returns an interval shorter than the lower bound.
Figures
read the original abstract
Robust uncertainty quantification is increasingly important in modern data analysis and is often formalized under Huber's model, which allows an $\varepsilon$-fraction of arbitrary corruptions. In many experimental sciences, however, the measurement protocol is well controlled, and contamination is more plausibly introduced upstream. Motivated by this noise-oblivious nature of adversaries, we study confidence intervals for the null location parameter $\theta$ in Efron's Gaussian two-groups model, where an unknown fraction $\varepsilon$ of observations have arbitrarily shifted means, but all samples share the same law of additive Gaussian measurement noise with variance $\sigma^2$. We characterize the minimax-optimal length among confidence intervals with a prescribed coverage level uniformly over the unknown contamination proportion and all noise-oblivious adversaries. Although prior work has shown that the minimax point estimation rate of theta does not deteriorate when $\varepsilon$ becomes unknown, our results reveal that, with a given $\sigma^2$, the minimax-optimal length of confidence intervals that are adaptive to unknown $\varepsilon$ is of order $\sigma (n^{-1/4}+\varepsilon^{1/2}/\max\{1, \log(en \varepsilon^2)\}^{1/2})$, which is polynomially worse than the optimal length when $\varepsilon$ is known. When the variance $\sigma^2$ is also unknown, we show a further degradation: no adaptive confidence interval can be shorter than $\Omega(\sigma n^{-1/8})$. Algorithmically, we introduce a Fourier-based certification procedure built on Carath\'{e}odory's positive-semidefiniteness constraints. By scanning candidate points and accepting those whose residual characteristic function is certifiably consistent with a Gaussian location mixture, our algorithm attains the minimax lower bound in the known-variance setting and is computable in polynomial time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper characterizes the minimax-optimal length of adaptive confidence intervals for the null location parameter θ in Efron's Gaussian two-groups model under noise-oblivious adversaries, where an unknown fraction ε of observations have arbitrary mean shifts but all share the same Gaussian noise variance σ². It derives that this length is of order σ(n^{-1/4} + ε^{1/2}/max{1, log(en ε²)}^{1/2}) when σ² is known (polynomially worse than the known-ε case), establishes a lower bound of Ω(σ n^{-1/8}) when σ² is also unknown, and introduces a polynomial-time Fourier-based certification algorithm using Carathéodory's positive-semidefiniteness constraints that attains the known-variance lower bound.
Significance. If the results hold, this work is significant for highlighting the distinct costs of adaptivity to unknown contamination in confidence intervals versus point estimation within robust statistics. The explicit minimax rates, the separation between known and unknown variance regimes, and the constructive polynomial-time algorithm via Fourier certification provide concrete tools and insights for uncertainty quantification in controlled measurement settings with upstream contamination.
major comments (1)
- [Abstract] Abstract and algorithmic section: the central claim that the Fourier certification procedure (built on Carathéodory constraints) attains the derived minimax lower bound in the known-variance case is load-bearing for the paper's contribution; without access to the full proof details, data-exclusion rules, and verification that the residual characteristic function ensures uniform coverage over all noise-oblivious adversaries, this attainment cannot be confirmed and requires explicit expansion in the main text or appendix.
minor comments (2)
- The notation max{1, log(en ε²)} in the rate expression should include a brief discussion of boundary behavior when ε is very small (e.g., ε < 1/n) to clarify the transition to the n^{-1/4} term.
- The weakest assumption (identical Gaussian noise law across all samples, with contamination only via mean shifts) is stated clearly in the abstract but could be reiterated with a short remark in the model section to emphasize contrast with standard Huber's corruption model.
Simulated Author's Rebuttal
We thank the referee for their careful reading of the manuscript and for the positive assessment of its significance in distinguishing the costs of adaptivity to unknown contamination in confidence intervals versus point estimation. We address the single major comment below and will incorporate the requested expansions in the revised version.
read point-by-point responses
-
Referee: [Abstract] Abstract and algorithmic section: the central claim that the Fourier certification procedure (built on Carathéodory constraints) attains the derived minimax lower bound in the known-variance case is load-bearing for the paper's contribution; without access to the full proof details, data-exclusion rules, and verification that the residual characteristic function ensures uniform coverage over all noise-oblivious adversaries, this attainment cannot be confirmed and requires explicit expansion in the main text or appendix.
Authors: We agree that the attainment claim is central and that the current presentation would benefit from greater explicitness. The full proof of the Fourier certification procedure (including the application of Carathéodory's theorem to the positive-semidefiniteness constraints on the residual characteristic function) is already contained in the appendix, together with the data-exclusion rules and the argument establishing uniform coverage over all noise-oblivious adversaries. In the revision we will (i) move a concise outline of the key steps into the main algorithmic section, (ii) add a dedicated subsection in the appendix that isolates the data-exclusion rule and the uniform-coverage verification, and (iii) include a short self-contained proof sketch that directly links the certified residual characteristic function to the minimax lower bound derived earlier in the paper. These changes will make the attainment verifiable without requiring the reader to reconstruct the argument from scattered pieces. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper derives its minimax-optimal CI lengths via standard information-theoretic arguments for the lower bound and a Fourier-based certification algorithm (using Carathéodory constraints) for the matching upper bound. These steps rely on external convex-optimization and characteristic-function tools applied to the explicitly stated noise-oblivious two-groups model; no equation or rate reduces by construction to a fitted parameter, self-defined quantity, or load-bearing self-citation. The cited prior point-estimation result is independent and not used to justify the CI claims.
Axiom & Free-Parameter Ledger
free parameters (2)
- contamination fraction ε
- noise variance σ²
axioms (2)
- domain assumption All observations share the same additive Gaussian noise distribution with fixed variance σ²
- domain assumption Contamination occurs only via arbitrary mean shifts (noise-oblivious adversaries)
Reference graph
Works this paper leans on
-
[1]
U ber den variabilit \
Constantin Carath \'e odory. \"U ber den variabilit \"a tsbereich der koeffizienten von potenzreihen, die gegebene werte nicht annehmen. Mathematische Annalen , 64(1):95--115, 1907
1907
-
[2]
U ber den variabilit \
Constantin Carath \'e odory. \"U ber den variabilit \"a tsbereich der fourier’schen konstanten von positiven harmonischen funktionen. Rendiconti Del Circolo Matematico di Palermo (1884-1940) , 32(1):193--217, 1911
1940
-
[3]
A short course on approximation theory
Neal L Carothers. A short course on approximation theory. Bowling Green State University, Bowling Green, OH , 38, 1998
1998
-
[4]
Adaptive robust estimation in sparse vector model
L Comminges, O Collier, M Ndaoud, and AB Tsybakov. Adaptive robust estimation in sparse vector model. The Annals of Statistics , 49(3):1347--1377, 2021
2021
-
[5]
Estimating minimum effect with outlier selection
Alexandra Carpentier, Sylvain Delattre, Etienne Roquain, and Nicolas Verzelen. Estimating minimum effect with outlier selection. The Annals of Statistics , 49(1):272--294, 2021
2021
-
[6]
Optimal rates of convergence for estimating the null density and proportion of nonnull effects in large-scale multiple testing
T Tony Cai and Jiashun Jin. Optimal rates of convergence for estimating the null density and proportion of nonnull effects in large-scale multiple testing. The Annals of Statistics , pages 100--145, 2010
2010
-
[7]
Adaptive estimation of the sparsity in the gaussian vector model
Alexandra Carpentier and Nicolas Verzelen. Adaptive estimation of the sparsity in the gaussian vector model. The Annals of Statistics , 47(1):93--126, 2019
2019
-
[8]
Sample complexity bounds for robust mean estimation with mean-shift contamination
Ilias Diakonikolas, Giannis Iakovidis, Daniel M Kane, and Sihan Liu. Sample complexity bounds for robust mean estimation with mean-shift contamination. arXiv preprint arXiv:2602.22130 , 2026
-
[9]
Efficient multivariate robust mean estimation under mean-shift contamination
Ilias Diakonikolas, Giannis Iakovidis, Daniel M Kane, and Thanasis Pittas. Efficient multivariate robust mean estimation under mean-shift contamination. arXiv preprint arXiv:2502.14772 , 2025
-
[10]
Robustly learning a gaussian: Getting optimal error, efficiently
Ilias Diakonikolas, Gautam Kamath, Daniel M Kane, Jerry Li, Ankur Moitra, and Alistair Stewart. Robustly learning a gaussian: Getting optimal error, efficiently. In Proceedings of the Twenty-Ninth Annual ACM-SIAM Symposium on Discrete Algorithms , pages 2683--2702. SIAM, 2018
2018
-
[11]
All-in-one robust estimator of the gaussian mean
Arnak S Dalalyan and Arshak Minasyan. All-in-one robust estimator of the gaussian mean. The Annals of Statistics , 50(2):1193--1219, 2022
2022
-
[12]
Large-scale simultaneous hypothesis testing: the choice of a null hypothesis
Bradley Efron. Large-scale simultaneous hypothesis testing: the choice of a null hypothesis. Journal of the American Statistical Association , 99(465):96--104, 2004
2004
-
[13]
Microarrays, empirical bayes and the two-groups model
Bradley Efron. Microarrays, empirical bayes and the two-groups model. Statistical Science , 23(1):1--22, 2008
2008
-
[14]
Simultaneous inference: When should hypothesis testing problems be combined? The Annals of Applied Statistics , pages 197--223, 2008
Bradley Efron. Simultaneous inference: When should hypothesis testing problems be combined? The Annals of Applied Statistics , pages 197--223, 2008
2008
-
[15]
Empirical bayes methods and false discovery rates for microarrays
Bradley Efron and Robert Tibshirani. Empirical bayes methods and false discovery rates for microarrays. Genetic epidemiology , 23(1):70--86, 2002
2002
-
[16]
Empirical bayes analysis of a microarray experiment
Bradley Efron, Robert Tibshirani, John D Storey, and Virginia Tusher. Empirical bayes analysis of a microarray experiment. Journal of the American statistical association , 96(456):1151--1160, 2001
2001
-
[17]
Mixture models, robustness, and sum of squares proofs
Samuel B Hopkins and Jerry Li. Mixture models, robustness, and sum of squares proofs. In Proceedings of the 50th Annual ACM SIGACT Symposium on Theory of Computing , pages 1021--1034, 2018
2018
-
[18]
Robust estimation of a location parameter
Peter J Huber. Robust estimation of a location parameter. The Annals of Mathematical Statistics , 35(1):73--101, 1964
1964
-
[19]
Estimating the null and the proportion of nonnull effects in large-scale multiple comparisons
Jiashun Jin and T Tony Cai. Estimating the null and the proportion of nonnull effects in large-scale multiple comparisons. Journal of the American Statistical Association , 102(478):495--506, 2007
2007
-
[20]
Proportion of non-zero normal means: universal oracle equivalences and uniformly consistent estimators
Jiashun Jin. Proportion of non-zero normal means: universal oracle equivalences and uniformly consistent estimators. Journal of the Royal Statistical Society Series B: Statistical Methodology , 70(3):461--493, 2008
2008
-
[21]
Optimal estimation of the null distribution in large-scale inference
Subhodh Kotekal and Chao Gao. Optimal estimation of the null distribution in large-scale inference. IEEE Transactions on Information Theory , 2025
2025
-
[22]
Sparsity meets correlation in gaussian sequence model
Subhodh Kotekal and Chao Gao. Sparsity meets correlation in gaussian sequence model. The Annals of Statistics , 53(3):1095--1122, 2025
2025
-
[23]
Moments, positive polynomials and their applications , volume 1
Jean Bernard Lasserre. Moments, positive polynomials and their applications , volume 1. World Scientific, 2009
2009
-
[24]
On a problem of adaptive estimation in gaussian white noise
OV Lepskii. On a problem of adaptive estimation in gaussian white noise. Theory of Probability & Its Applications , 35(3):454--466, 1991
1991
-
[25]
Asymptotically minimax adaptive estimation
OV Lepskii. Asymptotically minimax adaptive estimation. i: Upper bounds. optimally adaptive estimates. Theory of Probability & Its Applications , 36(4):682--697, 1992
1992
-
[26]
Adaptive robust confidence intervals
Yuetian Luo and Chao Gao. Adaptive robust confidence intervals. arXiv preprint arXiv:2410.22647 , 2024
-
[27]
On the best approximation by finite gaussian mixtures
Yun Ma, Yihong Wu, and Pengkun Yang. On the best approximation by finite gaussian mixtures. IEEE Transactions on Information Theory , 2025
2025
-
[28]
The Moment Problem , volume 277
Konrad Schm \"u dgen. The Moment Problem , volume 277. Springer, 2017
2017
-
[29]
Complex analysis , volume 2
Elias M Stein and Rami Shakarchi. Complex analysis , volume 2. Princeton University Press, 2010
2010
-
[30]
High-dimensional probability: An introduction with applications in data science , volume 47
Roman Vershynin. High-dimensional probability: An introduction with applications in data science , volume 47. Cambridge university press, 2018
2018
-
[31]
Polynomial methods in statistical inference: Theory and practice
Yihong Wu and Pengkun Yang. Polynomial methods in statistical inference: Theory and practice. Foundations and Trends in Communications and Information Theory , 17(4):402--585, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.