Recognition: unknown
Beyond Accuracy: LLM Variability in Evidence Screening for Software Engineering SLRs
Pith reviewed 2026-05-07 13:06 UTC · model grok-4.3
The pith
LLMs vary widely and remain non-deterministic when screening papers for software engineering systematic reviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
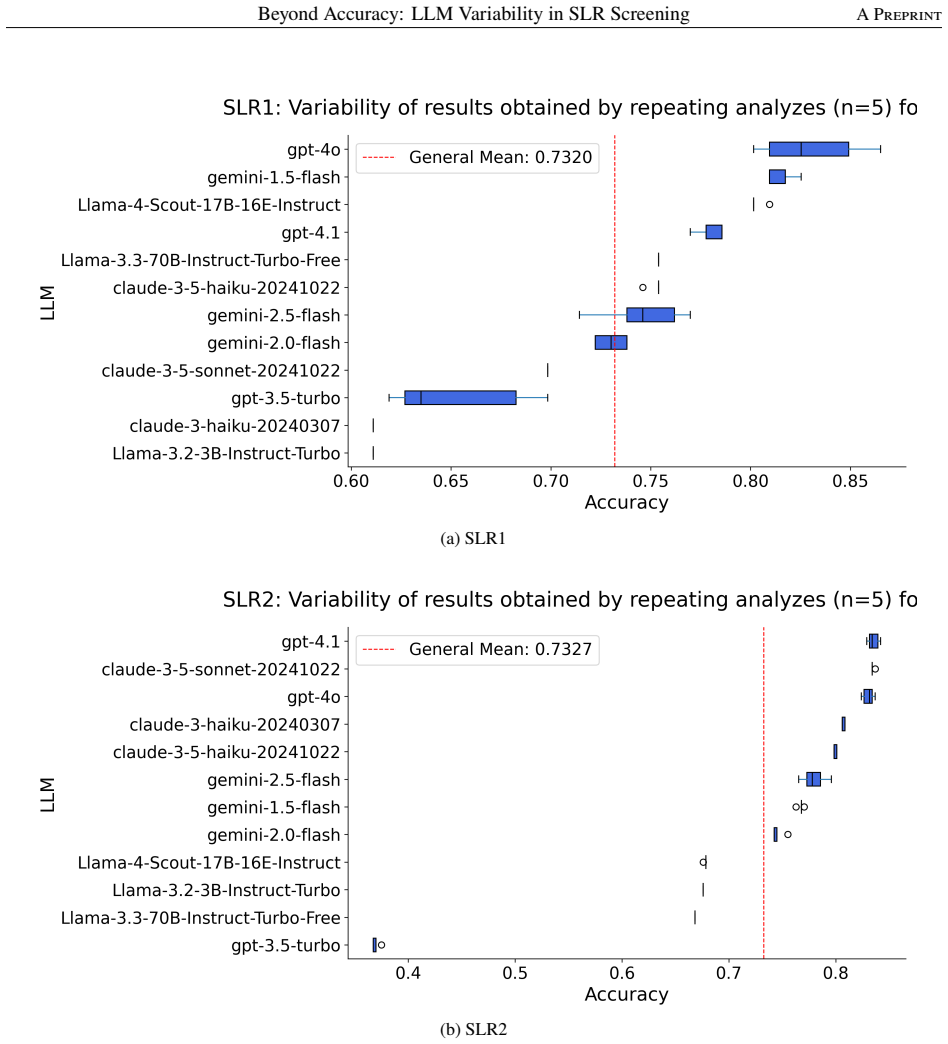
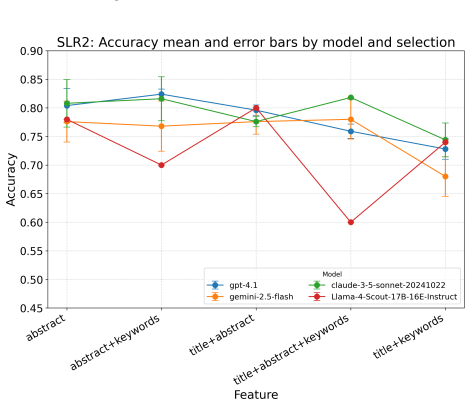
LLMs exhibited substantial heterogeneity and residual non-determinism even at temperature zero. Abstract availability was decisive: removing it consistently degraded performance, while adding title and/or keywords to the abstract yielded no robust gains. Compared to classical models, performance differences were not consistent enough to support generalizable LLM superiority.
What carries the argument
The shared experimental protocol that applies 12 LLMs and 4 classical classifiers to two software engineering SLRs while varying input metadata (abstract alone versus abstract plus title or keywords).
If this is right
- Abstract text must be collected as the primary input; titles and keywords cannot be relied upon to compensate for its absence.
- Any LLM-based screening workflow requires explicit reporting of run-to-run variability and pilot validation on the target corpus.
- Model choice should be driven by reproducibility, cost, and metadata constraints rather than expected accuracy gains.
- Classical classifiers remain competitive and should be included as baselines in future LLM screening studies.
Where Pith is reading between the lines
- Hybrid screening pipelines that run several LLMs in parallel and reconcile their outputs could reduce the impact of single-model variability.
- The same protocol could be applied to systematic reviews outside software engineering to test whether abstract dominance and LLM heterogeneity are domain-general.
- Persistent non-determinism at temperature zero points to deeper model architecture or training factors that prompting alone may not control.
Load-bearing premise
Findings from these two specific SLRs with 518 papers and the chosen prompting protocol will generalize to other reviews, domains, or larger collections.
What would settle it
A third SLR experiment in which all LLMs show near-zero variability at temperature zero and clearly outperform classical models on the same metrics would falsify the reported heterogeneity and lack of generalizable superiority.
Figures










read the original abstract
Context: Study screening in systematic literature reviews is costly, inconsistency-prone, and risk-asymmetric, since false negatives can compromise validity. Despite rapid uptake of Large Language Models (LLMs), there is limited evidence on how such models behave during the study screening phase, particularly regarding the choice of specific LLMs and their comparison with classical models. Objective: To assess LLM performance and variability in screening, quantify the impact of input metadata (abstract, title, keywords), and compare LLMs with classical classifiers under a shared protocol. Methods: We analyzed 12 LLMs from 4 providers (OpenAI, Google Gemini, Anthropic, Llama) and 4 classical models (Logistic Regression, Support Vector Classification, Random Forest, and Naive Bayes) on 2 real Systematic Literature Reviews (SLRs), totaling 518 papers. The experimental design investigated 3 critical dimensions: (i) LLMs performance variability, (ii) the impact of input feature composition (abstract, title, and keywords) on LLM performance, and (iii) the real gain of using LLMs instead of more traditional classification models. Results: LLMs exhibited substantial heterogeneity and residual non-determinism even at temperature zero. Abstract availability was decisive: removing it consistently degraded performance, while adding title and/or keywords to the abstract yielded no robust gains. Compared to classical models, performance differences were not consistent enough to support generalizable LLM superiority. Discussion: LLM adoption should be justified by operational and governance constraints (reproducibility, cost, metadata availability), supported by pilot validation and explicit reporting of variability and input configuration.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a controlled experiment screening 518 papers from two real software engineering SLRs using 12 LLMs (OpenAI, Google, Anthropic, Llama) and four classical classifiers (LR, SVC, RF, NB). It finds substantial LLM heterogeneity and residual non-determinism at temperature zero, decisive performance degradation when abstracts are removed, no robust gains from adding title or keywords, and inconsistent LLM-classical performance gaps that do not support generalizable superiority. The discussion advises justifying LLM adoption via operational constraints, pilot validation, and explicit variability reporting.
Significance. If the reported patterns of variability, abstract primacy, and inconsistent classical-model gaps hold, the work supplies concrete empirical guidance for SE researchers choosing screening tools, emphasizing reproducibility risks and the limited upside of richer metadata. The use of real labeled SLR data and a shared protocol across model families strengthens its practical relevance.
major comments (3)
- [Methods and Discussion] The central claims about LLM heterogeneity, abstract dominance, and lack of consistent superiority over classical models rest on experiments with only two SLRs. The manuscript provides no selection criteria, topic diversity metrics, or abstract-quality distribution for these SLRs, leaving open the possibility that the observed patterns are sample-specific rather than general properties of SE evidence screening.
- [Results] The statement that 'adding title and/or keywords to the abstract yielded no robust gains' is load-bearing for the input-feature conclusions, yet the Results section does not report the exact statistical tests, effect-size thresholds, or per-SLR variance used to establish 'robustness'; with only two SLRs the power to detect small gains is limited.
- [Discussion] The Discussion recommendation that 'LLM adoption should be justified by operational and governance constraints... supported by pilot validation' extrapolates from the two-SLR sample to general practice; without a sensitivity analysis or explicit scope limitations, this guidance risks over-generalization.
minor comments (2)
- [Abstract and Methods] The abstract and Methods would benefit from a concise table listing the exact 12 LLMs, their providers, and the four classical models with their hyper-parameter settings.
- [Methods] Clarify whether the ground-truth labels from the original SLRs were treated as fixed or whether any re-screening or inter-rater reliability checks were performed.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help us improve the clarity and appropriate scoping of our work. We agree that the small number of SLRs is a substantive limitation and will revise the manuscript to provide more transparent reporting on sample selection, statistical methods, and the bounded nature of our recommendations. Below we respond point by point.
read point-by-point responses
-
Referee: [Methods and Discussion] The central claims about LLM heterogeneity, abstract dominance, and lack of consistent superiority over classical models rest on experiments with only two SLRs. The manuscript provides no selection criteria, topic diversity metrics, or abstract-quality distribution for these SLRs, leaving open the possibility that the observed patterns are sample-specific rather than general properties of SE evidence screening.
Authors: We agree that the restriction to two SLRs constrains generalizability and that the original manuscript did not sufficiently document selection criteria. The two SLRs were selected because they are recent, independently conducted software engineering reviews that had already produced publicly available gold-standard labels, allowing us to avoid new annotation costs while using real screening decisions. In the revision we will add an explicit subsection in Methods describing this rationale, the topics covered by each SLR, and the source papers. We will also insert a dedicated Limitations paragraph in the Discussion that states the absence of topic-diversity or abstract-quality metrics and cautions that the reported patterns should be treated as specific to the studied SLRs rather than universal properties of SE evidence screening. This directly addresses the referee’s concern without overstating the scope of the findings. revision: yes
-
Referee: [Results] The statement that 'adding title and/or keywords to the abstract yielded no robust gains' is load-bearing for the input-feature conclusions, yet the Results section does not report the exact statistical tests, effect-size thresholds, or per-SLR variance used to establish 'robustness'; with only two SLRs the power to detect small gains is limited.
Authors: We accept that the Results section requires greater statistical transparency. Although we performed paired comparisons (Wilcoxon signed-rank tests) and examined effect sizes between input configurations, these details were not fully reported. In the revised manuscript we will expand the Results section to include the precise tests used, the effect-size thresholds applied, per-SLR performance variances, and confidence intervals around the observed differences. We will also add an explicit statement acknowledging the low statistical power associated with only two SLRs and will qualify the phrase “no robust gains” to reflect that small improvements cannot be ruled out. These additions will make the input-feature conclusions more defensible. revision: yes
-
Referee: [Discussion] The Discussion recommendation that 'LLM adoption should be justified by operational and governance constraints... supported by pilot validation' extrapolates from the two-SLR sample to general practice; without a sensitivity analysis or explicit scope limitations, this guidance risks over-generalization.
Authors: We acknowledge the risk of over-generalization. A full sensitivity analysis across many additional SLRs is not feasible within the current study. In the revision we will therefore add explicit scope limitations to the Discussion, stating that the practical guidance is derived from the empirical patterns observed in the two examined SE SLRs and should be validated via pilot studies in any new context. We will also include a forward-looking call for replication on further SLRs. The recommendation will be rephrased to emphasize conditional, context-specific justification rather than a universal prescription. revision: partial
Circularity Check
No significant circularity in empirical evaluation
full rationale
The paper reports direct experimental measurements of LLM and classical model performance, variability at temperature zero, and feature impacts (abstract/title/keywords) on two external real-world SLR datasets (518 papers total). No mathematical derivations, first-principles predictions, fitted parameters renamed as outputs, or self-referential definitions appear in the chain. Claims rest on observed metrics from off-the-shelf models applied to independent ground-truth screenings rather than reducing to inputs by construction. Self-citations, if present, are not load-bearing for any core result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ground-truth inclusion/exclusion decisions from the original SLRs are accurate and unbiased.
Reference graph
Works this paper leans on
-
[1]
URLhttp://arxiv.org/abs/2502.08050. Katia Romero Felizardo, Márcia Sampaio Lima, Anderson Deizepe, Tayana Uchôa Conte, and Igor Steinmacher. ChatGPT application in Systematic Literature Reviews in Software Engineering: An evaluation of its accuracy to support the selection activity. InProceedings of the 18th ACM/IEEE International Symposium on Empirical S...
-
[2]
ACM. ISBN 979-8-4007-1047-6. doi:10.1145/3674805.3686666. URLhttps://dl.acm.org/doi/10.1145/3674805.3686666. Eugene Syriani, Istvan David, and Gauransh Kumar. Screening articles for systematic reviews with chatgpt.Journal of Computer Languages, 80:101287,
-
[3]
doi:10.1016/j.infsof.2021.106589
ISSN 09505849. doi:10.1016/j.infsof.2021.106589. URL https://linkinghub.elsevier.com/retrieve/pii/ S0950584921000690. LukasThode,UmarIftikhar,andDanielMendez.ExploringtheuseofLLMsfortheselectionphaseinsystematicliterature studies.InformationandSoftwareTechnology,184:107757,2025. ISSN09505849. doi:10.1016/j.infsof.2025.107757. URLhttps://linkinghub.elsevie...
-
[4]
doi:10.1371/journal.pone.0227742
ISSN 1932-6203. doi:10.1371/journal.pone.0227742. URLhttps://dx.plos.org/10.1371/journal.pone.0227742. Matteo Esposito, Andrea Janes, Davide Taibi, and Valentina Lenarduzzi. Generative AI in Evidence-Based Software Engineering: A White Paper,
-
[5]
URLhttp://arxiv.org/abs/2407.17440. Xufei Luo, Fengxian Chen, Di Zhu, Ling Wang, Zijun Wang, Hui Liu, Meng Lyu, Ye Wang, Qi Wang, and Yaolong Chen. Potential roles of large language models in the production of systematic reviews and meta-analyses.Journal of Medical Internet Research, 26:e56780,
-
[6]
ACM. ISBN 979-8-4007-0567-0. doi:10.1145/3643664.3648202. URL https://dl.acm.org/doi/10.1145/3643664.3648202. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ra...
-
[7]
URL http://arxiv.org/abs/2005.14165. Lei Huang, Weijiang Yu, Weitao Ma, Weihong Zhong, Zhangyin Feng, Haotian Wang, Qianglong Chen, Weihua Peng, XiaochengFeng,BingQin,andTingLiu.ASurveyonHallucinationinLargeLanguageModels: Principles,Taxonomy, Challenges,andOpenQuestions,2025. ISSN1046-8188,1558-2868. URL http://arxiv.org/abs/2311.05232. Ziwei Xu, Sanjay ...
work page internal anchor Pith review arXiv 2005
-
[8]
URLhttp://arxiv.org/abs/2401.11817. Vipula Rawte, Amit Sheth, and Amitava Das. A Survey of Hallucination in Large Foundation Models,
-
[9]
A survey of hallucination in large foundation models
URL http://arxiv.org/abs/2309.05922. 14 Beyond Accuracy: LLM Variability in SLR ScreeningA Preprint Emily M. Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? InProceedings of the 2021 ACM Conference on Fairness, Account- ability, and Transparency, pages 610–623,...
-
[10]
Association for Computing Machinery. doi:10.1145/3442188.3445922. Lingjiao Chen, Matei Zaharia, and James Zou. How is chatgpt’s behavior changing over time?Harvard Data Science Review, 6(2):1–47,
-
[11]
ISSN 1939-1382, 2372-0050. doi:10.1109/TLT.2023.3317396. URL https://ieeexplore.ieee.org/document/10256042/. Barbara A Kitchenham, Tore Dyba, and Magne Jorgensen. Evidence-based software engineering. InProceedings. 26th International Conference on Software Engineering, pages 273–281, Los Alamitos, CA, USA,
-
[12]
Google DeepMind
Accessed on: 2025-11-03. Google DeepMind. Gemini api documentation. https://ai.google.dev/docs/models,
2025
-
[13]
Anthropic
Accessed on: 2025-11-03. Anthropic. Claudeapidocumentation. https://docs.anthropic.com/en/resources/overview,2025. Accessed on: 2025-11-03. Together AI. Together ai platform - llama models.https://www.together.ai/,
2025
-
[14]
Deterministic
Accessed on: 2025-11-03. Berk Atil, Sarp Aykent, Alexa Chittams, Lisheng Fu, Rebecca J. Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan Ture, Zhe Wu, Lixinyu Xu, and Breck Baldwin. Non-Determinism of "Deterministic" LLM Settings,
2025
-
[15]
URLhttp://arxiv.org/abs/2408.04667. Matthew Renze. The effect of sampling temperature on problem solving in large language models. InFindings of the association for computational linguistics: EMNLP 2024, pages 7346–7356, Miami, Florida, USA,
-
[16]
doi:10.1016/j.eswa.2025.129592
ISSN 09574174. doi:10.1016/j.eswa.2025.129592. URLhttps://linkinghub.elsevier.com/retrieve/pii/ S0957417425032075. Kilem L Gwet.Handbook of inter-rater reliability: The definitive guide to measuring the extent of agreement among raters. Advanced Analytics, LLC, Gaithersburg, MD, USA,
-
[17]
Farid Anvari and Daniël Lakens
doi:10.1016/j.cct.2015.09.002. Farid Anvari and Daniël Lakens. Using anchor-based methods to determine the smallest effect size of interest.Journal of Experimental Social Psychology, 96:104159,
-
[18]
doi:10.1016/0306-4573(88)90021-0
doi:10.1016/0306-4573(88)90021-0. Steven Bird, Ewan Klein, and Edward Loper.Natural Language Processing with Python. O’Reilly Media, Sebastopol, CA,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.