Recognition: unknown
Man, Machine, and Mathematics
Pith reviewed 2026-05-07 09:00 UTC · model grok-4.3
The pith
A unified framework reduces the study of learning to a small set of ideas from dynamical systems, geometry, and physics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
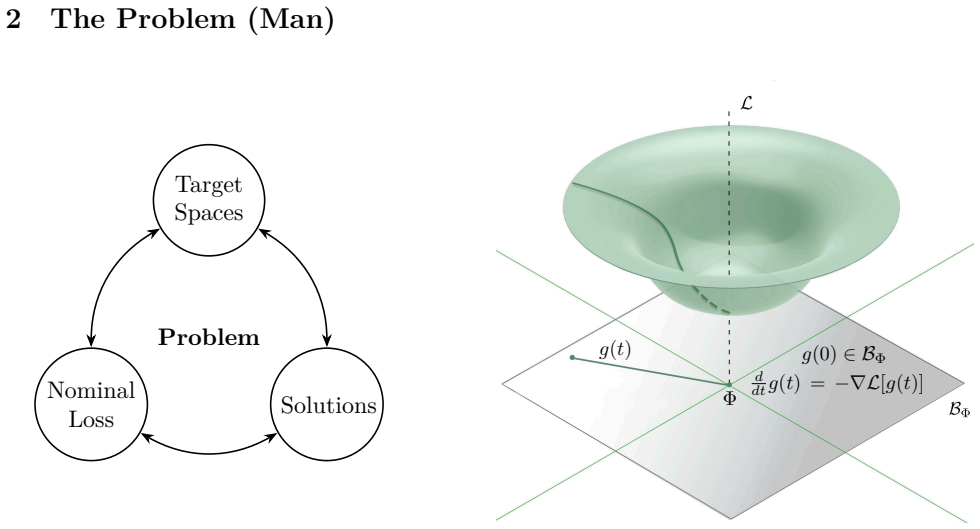
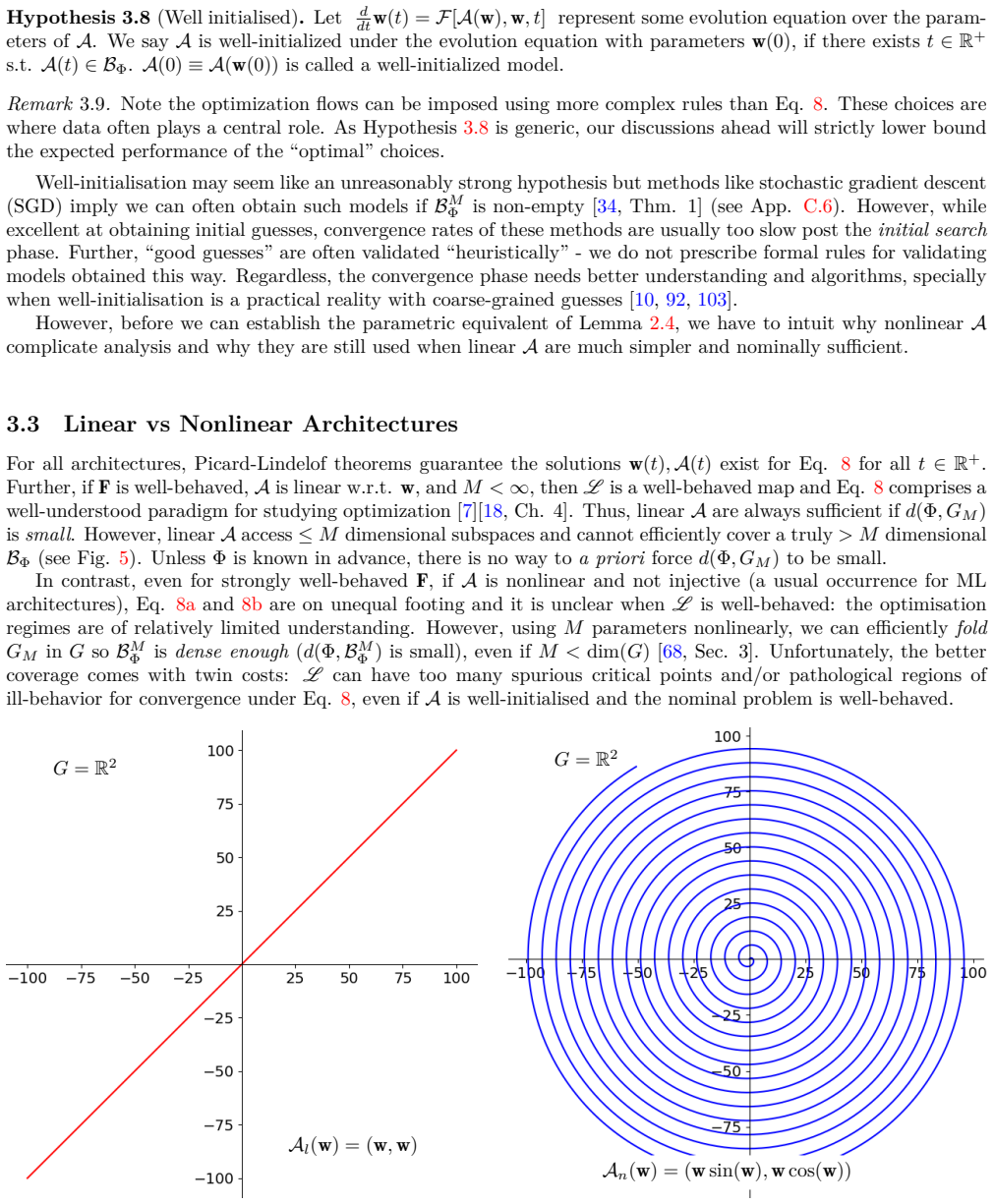
We posit and examine a possible outline for a unified theory, interpreting learning broadly as an interconnected process on multiple levels: problem setup, choosing methods, and the analysis of their interplay via imposed optimisation dynamics. We begin by proposing a precise yet versatile definition for solvable problems. We then define the parametrized methods by which their solution(s) may be learned. Our goal is to sketch a universal convergence theorem, specifying how and when solvable problems become amenable to the methods chosen for them. These constructions reduce the study of learning down to remarkably few ideas and tools, many of which are simply adapted from existing ones in the
What carries the argument
The universal convergence theorem, which specifies how and when solvable problems become amenable to chosen parametrized methods under optimization dynamics.
Load-bearing premise
Precise yet versatile definitions for solvable problems and parametrized methods can be given such that they support a universal convergence theorem applicable across a broad landscape of tasks.
What would settle it
A concrete learning task, such as training a nonlinear model on image classification data, where the proposed definitions cannot be applied or the convergence conditions fail to hold would show the framework does not cover the claimed broad landscape.
Figures





read the original abstract
Nonlinear models and optimization methods have successfully tackled a rapidly growing set of problems in recent years. Indeed, a relatively small toolbox of such models and methods can provide sufficient performance across a large landscape of tasks: deep learning alone has made significant recent contributions in scientific modelling, natural language processing, visual analysis, etc. A similar relationship exists between physical theories and phenomena, where many applications and observations emerge neatly from remarkably minimal foundations. It is natural to wonder if sparse unified frameworks could be built to steer discussion and discovery in the fields concerned with learning, optimization, and modelling. In this work, we posit and examine a possible outline for such a unified theory, interpreting the notion of ''learning'' in a broad sense. In particular, we pursue our goals by viewing learning as an inter-connected process on multiple levels: problem setup, choosing methods, and the analysis of their interplay via imposed optimisation dynamics. We begin by proposing a precise yet versatile definition for ''solvable'' problems. We then define the ''parametrised methods'' by which their solution(s) may be ''learned''. Our goal is to sketch a ''universal convergence theorem'', specifying how and when solvable problems become amenable to the methods chosen for them. We find these constructions reduce the study of learning down to remarkably few ideas and tools - many of which are simply adapted from existing ones in dynamical systems theory, geometry, and fundamental physics.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an outline for a unified theory of learning, optimization, and modeling by viewing learning as an interconnected process across problem setup, method selection, and optimization dynamics. It introduces precise yet versatile definitions for 'solvable' problems and 'parametrised methods', sketches a 'universal convergence theorem' on when such problems become amenable to the methods, and claims that these reduce the study of learning to remarkably few ideas and tools adapted from dynamical systems theory, geometry, and fundamental physics.
Significance. If the sketched definitions and theorem can be formalized with explicit statements and derivations, the work could provide a valuable high-level unifying perspective linking machine learning to minimal foundations in physics and geometry, similar to how sparse toolboxes succeed across tasks. The manuscript currently offers no such formalization, derivations, or examples, so its significance remains conceptual rather than substantive.
major comments (2)
- [Abstract] Abstract: The manuscript states that 'precise yet versatile' definitions for solvable problems and parametrised methods will be proposed and that a universal convergence theorem will be sketched, yet supplies neither the definitions nor the theorem statement. This leaves the central claim—that these constructions reduce learning to few adapted ideas from dynamical systems, geometry, and physics—unsupported by any explicit mathematics.
- [Main text] Main text (universal convergence theorem sketch): The claim that the definitions support a theorem applicable across a broad landscape of tasks requires that the notions of solvability and parametrization be stated formally enough to admit a derivation from dynamical systems or geometric tools. No such statements, assumptions (e.g., compactness or regularity conditions), or reduction steps appear, so it is impossible to assess whether hidden restrictions are needed for convergence to hold.
Simulated Author's Rebuttal
We thank the referee for their careful reading and valuable comments on our manuscript. We are pleased that the potential significance of the unifying perspective is recognized, and we respond to the major comments below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states that 'precise yet versatile' definitions for solvable problems and parametrised methods will be proposed and that a universal convergence theorem will be sketched, yet supplies neither the definitions nor the theorem statement. This leaves the central claim—that these constructions reduce learning to few adapted ideas from dynamical systems, geometry, and physics—unsupported by any explicit mathematics.
Authors: The paper is explicitly positioned as an outline for a unified theory, and the abstract reflects this by describing what is proposed and sketched rather than fully derived. The definitions and theorem are given in precise conceptual terms in the main text, reducing the study to few ideas without requiring explicit symbolic formalization or derivations at this stage. This approach mirrors successful high-level frameworks in physics and other fields. We do not believe additional formal mathematics is necessary for the manuscript's goals, and thus no revision is planned on this point. revision: no
-
Referee: [Main text] Main text (universal convergence theorem sketch): The claim that the definitions support a theorem applicable across a broad landscape of tasks requires that the notions of solvability and parametrization be stated formally enough to admit a derivation from dynamical systems or geometric tools. No such statements, assumptions (e.g., compactness or regularity conditions), or reduction steps appear, so it is impossible to assess whether hidden restrictions are needed for convergence to hold.
Authors: We maintain that the sketched notions are stated with enough versatility and precision to support the broad applicability of the universal convergence theorem as outlined. The framework deliberately avoids specifying particular assumptions like compactness to emphasize the general reduction to dynamical systems and geometric tools. The absence of detailed reduction steps is by design, as the paper focuses on the high-level interconnections rather than technical proofs. If the referee seeks a fully derived theorem, that would constitute a different, more technical paper. We see no need for revision here. revision: no
Circularity Check
No significant circularity; high-level proposal without explicit self-referential reductions
full rationale
The manuscript proposes definitions for solvable problems and parametrized methods then sketches a universal convergence theorem, explicitly noting that the tools are adapted from dynamical systems theory, geometry, and fundamental physics. No equations, formal definitions, or derivation steps are supplied in the text that would permit exhibiting a reduction of any claimed result to its own inputs by construction. The central claim is framed as an outline and observation rather than a closed mathematical chain that loops back on fitted parameters or self-citations. This is the normal outcome for a high-level conceptual sketch that does not contain load-bearing derivations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Solvable problems admit a precise yet versatile definition.
- domain assumption Parametrised methods exist by which solutions to solvable problems may be learned.
invented entities (1)
-
Universal convergence theorem
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Gradient Flows: In Metric Spaces and in the Space of Probability Measures
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savare. Gradient Flows: In Metric Spaces and in the Space of Probability Measures. Birkhäuser Basel, 2008
2008
-
[2]
D. Ba, A. S. Dogra, R. Gambhir, A. Tasissa, and J. Thaler. Shaper: Can you hear the shape of a jet? Journal of High Energy Physics , 2023(195), 2023
2023
-
[3]
Edward Bierstone and Pierre D. Milman. Semianalytic and subanalytic sets. Publications Mathématiques de l’IHÉS, 67:5–42, 1988
1988
-
[4]
A family of functional inequalities: Łojasiewicz inequalities and displace- ment convex functions
Adrien Blanchet and Jérôme Bolte. A family of functional inequalities: Łojasiewicz inequalities and displace- ment convex functions. Journal of Functional Analysis , 275(7):1650–1673, 2018
2018
-
[5]
Real Algebraic Geometry
Jacek Bochnak, Michel Coste, and Marie-Françoise Roy. Real Algebraic Geometry. Springer Berlin, Heidelberg, 1998
1998
-
[6]
A mathematical guide to operator learning
Nicolas Boullé and Alex Townsend. A mathematical guide to operator learning. arXiv:2312.14688, 2023
-
[7]
Convex Optimization
Stephen Boyd and Lieven Vandenberghe. Convex Optimization . Cambridge University Press, 2004
2004
-
[8]
On the existence of universal lottery tickets
Rebekka Burkholz, Nilanjana Laha, Rajarshi Mukherjee, and Alkis Gotovos. On the existence of universal lottery tickets. arXiv, arXiv:2111.11146, 2021
-
[9]
Bárta, R
T. Bárta, R. Chill, and E. Fašangová. Every ordinary differential equation with a strict lyapunov function is a gradient system. Monatshefte für Mathematik , 166, 2012
2012
-
[10]
Emre Celebi, Hassan A
M. Emre Celebi, Hassan A. Kingravi, and Patricio A. Vela. A comparative study of efficient initialization methods for the k-means clustering algorithm. Expert Systems with Applications , 40(1):200–210, 2013
2013
-
[11]
On the Łojasiewicz–simon gradient inequality
Ralph Chill. On the Łojasiewicz–simon gradient inequality. Journal of Functional Analysis , 201(2):572–601, 2003
2003
-
[12]
Convergence and decay rate to equilibrium of bounded solutions of quasilinear parabolic equations
Ralph Chill and Alberto Fiorenza. Convergence and decay rate to equilibrium of bounded solutions of quasilinear parabolic equations. Journal of Differential Equations , 228:611–632, 2006
2006
-
[13]
G. Cybenko. Approximation by superpositions of a sigmoidal function. Math. Control Signal Systems 2 , 2, 1989
1989
-
[14]
Dogra, and William T
Pritipriya Dasbehera, Akshunna S. Dogra, and William T. Redman. Distance by de-correlation: Computing distance with heterogeneous grid cells, 2025
2025
-
[15]
Damek Davis, Dmitriy Drusvyatskiy, Sham Kakade, and Jason D. Lee. Stochastic subgradient method converges on tame functions. Foundations of Computational Mathematics , 20:119–154, 2020
2020
-
[16]
de Hoop, Nikola B
Maarten V. de Hoop, Nikola B. Kovachki, Nicholas H. Nelsen, and Andrew M. Stuart. Convergence rates for learning linear operators from noisy data. SIAM/ASA Journal on Uncertainty Quantification , 11(2):480–513, 2023
2023
-
[17]
Dietrich, T
F. Dietrich, T. N. Thiem, and I. G. Kevredikis. On the koopman operator of algorithms. SIAM Journal on Applied Dynamical Systems , 19:860–885, 2020
2020
-
[18]
A. S. Dogra. Manyfold Learning: A geometric framework for the analysis, optimization, and convergence of nonlinearly parametrised models. PhD thesis, Imperial College London, 2025
2025
-
[19]
A. S. Dogra. Neural tangent kernels, pullback metrics, koopman operators, and the many names for geometric control on nonlinear optimization. under preparation, 2025
2025
- [20]
-
[21]
A. S. Dogra, J. B. Lai, Z. Wang, M. Peev, W. T. Redman, and T. Chen. Solver: Solution learning via equation residuals allows unsupervised error analysis and correction. under revision , 2025. 19
2025
-
[22]
A. S. Dogra and W. T. Redman. Optimizing neural networks via koopman operator theory. Advances in Neural Information Processing Systems (NeurIPS) , 33, 2020
2020
-
[23]
Draper and Harry Smith
Norman R. Draper and Harry Smith. Applied Regression Analysis. John Wiley & Sons, New York, 3 edition, 1998
1998
-
[24]
Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh
Simon S. Du, Xiyu Zhai, Barnabas Poczos, and Aarti Singh. Gradient descent provably optimizes over- parameterized neural networks. In International Conference on Learning Representations , 2019
2019
-
[25]
Lottery tickets in linear models: An analysis of iterative magnitude pruning
Bryn Elesedy, Varun Kanade, and Yee Whye Teh. Lottery tickets in linear models: An analysis of iterative magnitude pruning. arXiv preprint , arXiv:2007.08243, 2021
-
[26]
L. C. Evans. Partial Differential Equations , volume 19 of Graduate Studies in Mathematics . American Mathematical Society, Providence, Rhode Island, 1998
1998
-
[27]
Resolution of singularities and geometric proofs of the Łojasiewicz inequalities
Paul M N Feehan. Resolution of singularities and geometric proofs of the Łojasiewicz inequalities. Geometry and Topology,, 23, 2019
2019
-
[28]
Geometric data analysis, beyond convolutions
Jean Feydy. Geometric data analysis, beyond convolutions . ENS Paris-Saclay, 2020
2020
-
[29]
Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the neural tangent kernel
Stanislav Fort, Gintare Karolina Dziugaite, Mansheej Paul, Sepideh Kharaghani, Daniel M Roy, and Surya Ganguli. Deep learning versus kernel learning: an empirical study of loss landscape geometry and the time evolution of the neural tangent kernel. In H. Larochelle, M. Ranzato, R. Hadsell, M. F. Balcan, and H. Lin, editors, Advances in Neural Information ...
2020
-
[30]
The lottery ticket hypothesis: Finding sparse, trainable neural net- works
Jonathan Frankle and Michael Carbin. The lottery ticket hypothesis: Finding sparse, trainable neural net- works. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019 . OpenReview.net, 2019
2019
-
[31]
Linear mode connectivity and the lottery ticket hypothesis
Jonathan Frankle, Gintare Karolina Dziugaite, Daniel Roy, and Michael Carbin. Linear mode connectivity and the lottery ticket hypothesis. In Hal Daumé III and Aarti Singh, editors, Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3259–3269. PMLR, 13–18 Jul 2020
2020
-
[32]
Friston and Klaas E
Karl J. Friston and Klaas E. Stephan. Free-energy and the brain. Synthese, 159(3):417–458, 2007
2007
-
[33]
Global convergence in training large-scale transformers
Cheng Gao, Yuan Cao, Zihao Li, Yihan He, Mengdi Wang, Han Liu, Jason Matthew Klusowski, and Jianqing Fan. Global convergence in training large-scale transformers. In The Thirty-eighth Annual Conference on Neural Information Processing Systems , 2024
2024
-
[34]
Diffusions for global optimization
Stuart Geman and Chii-Ruey Hwang. Diffusions for global optimization. SIAM Journal on Control and Optimization, 24(5):1031–1043, 1986
1986
-
[35]
Error bounds for approximations with deep relu neural networks in ws,p norms
Ingo Gühring, Gitta Kutyniok, and Philipp Petersen. Error bounds for approximations with deep relu neural networks in ws,p norms. Analysis and Applications , 18(05):803–859, 2020
2020
-
[36]
Guliyev and Vugar E
Namig J. Guliyev and Vugar E. Ismailov. Approximation capability of two hidden layer feedforward neural networks with fixed weights. Neurocomputing, 316:262–269, 2018
2018
-
[37]
Cooling schedules for optimal annealing
Bruce Hajek. Cooling schedules for optimal annealing. MATHEMATICS OF OPERATIONS RESEARCH , 13, 1988
1988
-
[38]
J. Han, A. Jentzen, and Weinan E. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences , 2018
2018
-
[39]
Approximating continuous functions by relu nets of minimal width.arXiv:1710.11278, 2017
B. Hanin and M. Sellke. Approximating continuous functions by relu nets of minimal width. arXiv:1710.11278, 2018
-
[40]
Abu-Al Hassan. Iterative magnitude pruning as a renormalisation group: A study in the context of the lottery ticket hypothesis. arXiv:2308.03128, 2023. 20
-
[41]
Uwe Helmke and John B. Moore. Optimization and Dynamical Systems . Communications and Control Engineering. Springer-Verlag, London & New York, 1st edition, 1994
1994
-
[42]
Henderson
David W. Henderson. Infinite-dimensional manifolds are open subsets of hilbert space. Topology, 9(1):25–33, 1970
1970
-
[43]
Rigorous a posteriori error bounds for pde-defined pinns
Birgit Hillebrecht and Benjamin Unger. Rigorous a posteriori error bounds for pde-defined pinns. IEEE Transactions on Neural Networks and Learning Systems , pages 1–11, 2023
2023
-
[44]
K. Hornik. Approximation capabilities of muitilayer feedforward networks. Neural Networks, 4:251–257, 1991
1991
-
[45]
Weak formulations of the nonlinear poisson-boltzmann equation in biomolecular electrostatics
José A Iglesias and Svetoslav Nakov. Weak formulations of the nonlinear poisson-boltzmann equation in biomolecular electrostatics. Journal of Mathematical Analysis and Applications , page 126065, 2022
2022
-
[46]
Noboru Isobe. A convergence result of a continuous model of deep learning via łojasiewicz–simon inequality. arXiv:2311.15365, 2024
-
[47]
Neural tangent kernel: Convergence and generalization in neural networks
Arthur Jacot, Franck Gabriel, and Clement Hongler. Neural tangent kernel: Convergence and generalization in neural networks. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 31. Curran Associates, Inc., 2018
2018
- [48]
-
[49]
P. Kidger and T. Lyons. Universal approximation with deep narrow networks. arXiv:1905.08539, 2019
-
[50]
On universal approximation and error bounds for fourier neural operators
Nikola Kovachki, Samuel Lanthaler, and Siddhartha Mishra. On universal approximation and error bounds for fourier neural operators. J. Mach. Learn. Res. , 22(1), January 2021
2021
-
[51]
Neural operator: Learning maps between function spaces with applications to pdes
Nikola Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew Stuart, and Anima Anandkumar. Neural operator: Learning maps between function spaces with applications to pdes. Journal of Machine Learning Research , 24(89):1–97, 2023
2023
-
[52]
The convenient setting of global analysis / Andreas Kriegl, Peter W
Andreas Kriegl. The convenient setting of global analysis / Andreas Kriegl, Peter W. Michor. Mathematical surveys and monographs ; no. 53. American Mathematical Society, Providence, R.I., 1997
1997
-
[53]
Characterizing possible failure modes in physics-informed neural networks
Aditi Krishnapriyan, Amir Gholami, Shandian Zhe, Robert Kirby, and Michael W Mahoney. Characterizing possible failure modes in physics-informed neural networks. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan, editors, Advances in Neural Information Processing Systems , volume 34, pages 26548–26560. Curran Associates, Inc., 2021
2021
-
[54]
On gradients of functions definable in o-minimal structures
Krzysztof Kurdyka. On gradients of functions definable in o-minimal structures. Annales de l’Institut Fourier , 48:769–783, 1998
1998
-
[55]
Error estimates for deeponets: a deep learning framework in infinite dimensions
Samuel Lanthaler, Siddhartha Mishra, and George E Karniadakis. Error estimates for deeponets: a deep learning framework in infinite dimensions. Transactions of Mathematics and Its Applications , 6(1):tnac001, 03 2022
2022
-
[56]
LeCun, Y
Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. Nature, 521, 2015
2015
-
[57]
Wide neural networks of any depth evolve as linear models under gradient descent
Jaehoon Lee, Lechao Xiao, Samuel Schoenholz, Yasaman Bahri, Roman Novak, Jascha Sohl-Dickstein, and Jeffrey Pennington. Wide neural networks of any depth evolve as linear models under gradient descent. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 3...
2019
-
[58]
Learning overparameterized neural networks via stochastic gradient descent on structured data
Yuanzhi Li and Yingyu Liang. Learning overparameterized neural networks via stochastic gradient descent on structured data. In S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett, editors, Advances in Neural Information Processing Systems , volume 31. Curran Associates, Inc., 2018. 21
2018
-
[59]
Fourier Neural Operator for Parametric Partial Differential Equations
Zongyi Li, Nikola Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew Stu- art, and Anima Anandkumar. Fourier neural operator for parametric partial differential equations. arXiv:2010.08895, 2020
work page internal anchor Pith review arXiv 2010
-
[60]
Loss landscapes and optimization in over-parameterized non- linear systems and neural networks
Chaoyue Liu, Libin Zhu, and Mikhail Belkin. Loss landscapes and optimization in over-parameterized non- linear systems and neural networks. Applied and Computational Harmonic Analysis , 59:85–116, 2022. Special Issue on Harmonic Analysis and Machine Learning
2022
-
[61]
Hou, and Max Tegmark
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y. Hou, and Max Tegmark. KAN: Kolmogorov–arnold networks. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[62]
Lojasiewicz
S. Lojasiewicz. Une propriete topologique des sous-ensembles analytiques reels. Colloques internationaux du C.N.R.S 117. Les Équations aux Dérivées Partielles , 1963
1963
-
[63]
Lojasiewicz
S. Lojasiewicz. Ensembles semi-analytiques. preprint IHES , 1965
1965
-
[64]
Lojasiewicz
S. Lojasiewicz. Sur les trajectoires du gradient d’une fonction analytique. Seminari di Geometria, Bologna (1982/83), Universita’ degli Studi di Bologna, Bologna , 1983
1982
-
[65]
Some geometric calculations on Wasserstein space
John Lott. Some geometric calculations on Wasserstein space. Comm. Math. Phys. , 277(2):423–437, 2008
2008
-
[66]
A universal approximation theorem of deep neural networks for expressing prob- ability distributions
Yulong Lu and Jianfeng Lu. A universal approximation theorem of deep neural networks for expressing prob- ability distributions. In Proceedings of the 34th International Conference on Neural Information Processing Systems, NIPS ’20, Red Hook, NY, USA, 2020. Curran Associates Inc
2020
-
[67]
Towards understanding iterative magnitude pruning: Why lottery tickets win
Jaron Maene, Mingxiao Li, and Marie-Francine Moens. Towards understanding iterative magnitude pruning: Why lottery tickets win. arXiv preprint , arXiv:2106.06955, 2021
-
[68]
Lower bounds for approximation by mlp neural networks
Vitaly Maiorov and Allan Pinkus. Lower bounds for approximation by mlp neural networks. Neurocomputing, 25(1):81–91, 1999
1999
-
[69]
Exponential convergence of deep operator networks for elliptic partial differential equations
Carlo Marcati and Christoph Schwab. Exponential convergence of deep operator networks for elliptic partial differential equations. SIAM Journal on Numerical Analysis , 61(3):1513–1545, 2023
2023
-
[70]
Mattheakis, D
M. Mattheakis, D. Sondak, A. S. Dogra, and P. Protopapas. Hamiltonian neural networks for solving differ- ential equations. Physical Review E 105, 065305 , 2022
2022
-
[71]
Sparse transfer learning via winning lottery tickets
Rahul Mehta. Sparse transfer learning via winning lottery tickets. arXiv preprint , arXiv:1905.07785, 2019
-
[72]
Nakao, Michael Plum
Yoshitaka Watanabe Mitsuhiro T. Nakao, Michael Plum. Numerical Verification Methods and Computer- Assisted Proofs for Partial Differential Equations . Springer Singapore, 2019
2019
-
[73]
Trajan Murphy∗, Akshunna S. Dogra ∗, Hanfeng Gu, Caleb Meredith, Mark Kon, and Julio Enrique Castrillón- Candás∗, for the Alzheimer’s Disease Neuroimaging Initiative. Finder: Feature inference on noisy datasets using eigenspace residuals. arXiv:2510.19917, 2025
-
[74]
Universal approximation property of banach space-valued random feature models including random neural networks, 2024
Ariel Neufeld and Philipp Schmocker. Universal approximation property of banach space-valued random feature models including random neural networks, 2024
2024
-
[75]
The geometry of dissipative evolution equations: the porous medium equation
Felix Otto. The geometry of dissipative evolution equations: the porous medium equation. Comm. Partial Differential Equations , 26(1-2):101–174, 2001
2001
-
[76]
W. T. Redman, M. Fonoberova, R. Mohr, Y. Kevrekidis, and I. Mezic. An operator theoretic view on pruning deep neural networks. International Conference on Learning Representations 2021 , 2022
2021
-
[77]
William T Redman, Tianlong Chen, Zhangyang Wang, and Akshunna S. Dogra. Universality of winning tickets: A renormalization group perspective. In Proceedings of the 39th International Conference on Machine Learning, volume 162 of Proceedings of Machine Learning Research , pages 18483–18498. PMLR, 17–23 Jul 2022. 22
2022
-
[78]
Roberts, Sho Yaida, and Boris Hanin
Daniel A. Roberts, Sho Yaida, and Boris Hanin. The principles of deep learning theory. arXiv preprint , arXiv:2106.10165, 2021
-
[79]
On the Łojasiewicz–simon gradient inequality on submanifolds
Fabian Rupp. On the Łojasiewicz–simon gradient inequality on submanifolds. Journal of Functional Analysis , 279(8):108708, 2020
2020
-
[80]
Analyzing the neural tangent kernel of period- ically activated coordinate networks
Hemanth Saratchandran, Shin-Fang Chng, and Simon Lucey. Analyzing the neural tangent kernel of period- ically activated coordinate networks. arXiv:2402.04783, 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.