Recognition: unknown
Efficient Training on Multiple Consumer GPUs with RoundPipe
Pith reviewed 2026-05-07 10:33 UTC · model grok-4.3
The pith
RoundPipe dynamically dispatches model stages round-robin across stateless GPUs to eliminate the weight binding bottleneck in pipeline parallelism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
RoundPipe breaks the weight binding constraint on consumer GPU servers by treating GPUs as a pool of stateless execution workers and dynamically dispatching computation stages across devices in a round-robin manner to achieve a near-zero-bubble pipeline, while integrating a priority-aware transfer scheduling engine, a fine-grained distributed event-based synchronization protocol, and an automated layer partitioning algorithm to ensure training correctness and efficiency.
What carries the argument
Round-robin dynamic dispatching of computation stages to stateless GPU workers, which decouples stage assignment from fixed device binding.
If this is right
- RoundPipe delivers 1.48 to 2.16 times speedups compared to state-of-the-art baselines for fine-tuning models ranging from 1.7 billion to 32 billion parameters.
- It enables LoRA fine-tuning of the Qwen3-235B model using sequences of 31K length on a single consumer-grade server with eight RTX 4090 GPUs.
- The approach supports training correctness and convergence for arbitrary model architectures and sequence lengths.
- Pipeline bubbles are reduced to near zero through the combination of dynamic dispatch and supporting mechanisms.
Where Pith is reading between the lines
- Similar dynamic dispatching logic could be adapted for distributed inference to improve utilization on heterogeneous hardware.
- Researchers might experiment with combining RoundPipe with other memory optimization techniques like quantization to further scale model sizes.
- The open-source library could serve as a base for testing the method on non-LLM workloads such as vision transformers or reinforcement learning agents.
Load-bearing premise
The dynamic dispatching of stages combined with the priority-aware transfer engine and event-based synchronization protocol introduces negligible overhead while preserving training correctness and convergence for arbitrary model architectures and sequence lengths.
What would settle it
Running the same training task on a 32B model both with RoundPipe and with a baseline pipeline schedule, then comparing the achieved tokens per second and the final model loss to check for slowdowns or divergence.
Figures













read the original abstract
Fine-tuning Large Language Models (LLMs) on consumer-grade GPUs is highly cost-effective, yet constrained by limited GPU memory and slow PCIe interconnects. Pipeline parallelism combined with CPU offloading mitigates these hardware bottlenecks by reducing communication overhead. However, existing PP schedules suffer from an inherent limitation termed the weight binding issue. Binding uneven model stages (e.g., the LM head is large) to GPUs limits the pipeline's throughput to that of the GPU with the heaviest load, leading to severe pipeline bubbles. In this paper, we propose RoundPipe, a novel pipeline schedule that breaks the weight binding constraint on consumer GPU servers. RoundPipe treats GPUs as a pool of stateless execution workers and dynamically dispatches computation stages across devices in a round-robin manner, achieving a near-zero-bubble pipeline. To ensure training correctness and system efficiency, RoundPipe integrates a priority-aware transfer scheduling engine, a fine-grained distributed event-based synchronization protocol, and an automated layer partitioning algorithm. Evaluations on an 8$\times$ RTX 4090 server demonstrate that RoundPipe achieves 1.48--2.16$\times$ speedups over state-of-the-art baselines when fine-tuning 1.7B to 32B models. Remarkably, RoundPipe enables LoRA fine-tuning of the Qwen3-235B model with 31K sequence length on a single server. RoundPipe is publicly available as an open-source Python library with comprehensive documentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RoundPipe, a pipeline parallelism schedule for fine-tuning LLMs on consumer GPUs that treats GPUs as stateless workers and dispatches model stages dynamically in round-robin fashion to break the weight-binding bottleneck of prior PP methods. It augments this with a priority-aware transfer engine, a fine-grained distributed event-based synchronization protocol, and an automated layer partitioning algorithm. On an 8× RTX 4090 server, it reports 1.48–2.16× speedups versus state-of-the-art baselines for 1.7B–32B models and demonstrates LoRA fine-tuning of the 235B Qwen3 model at 31K sequence length.
Significance. If the correctness and overhead claims hold, the result would be significant for enabling large-model fine-tuning on affordable single-server hardware. The open-source Python library release with documentation strengthens reproducibility. Concrete speedups across a range of model sizes and the 235B capability are notable empirical contributions to distributed training systems for consumer GPUs.
major comments (3)
- [§4.2] §4.2 (event-based synchronization protocol): the description does not supply a formal invariant, proof sketch, or exhaustive dependency analysis showing that round-robin dynamic dispatch plus event ordering preserves correct per-microbatch weight versions, activation tensors, and gradient accumulation across forward/backward passes for arbitrary model graphs.
- [§3.3] §3.3 (automated partitioning algorithm): no formal load-balance guarantee or worst-case analysis is given that the algorithm produces balanced stages for every architecture and sequence length; evaluations cover only the reported 1.7B–32B models plus one 235B case.
- [§5] §5 (evaluation): speedups are presented without a quantitative overhead breakdown (dispatch, priority scheduling, event synchronization) or micro-benchmark isolating the cost of dynamic dispatching, leaving the “negligible overhead” claim unsupported beyond aggregate throughput numbers.
minor comments (2)
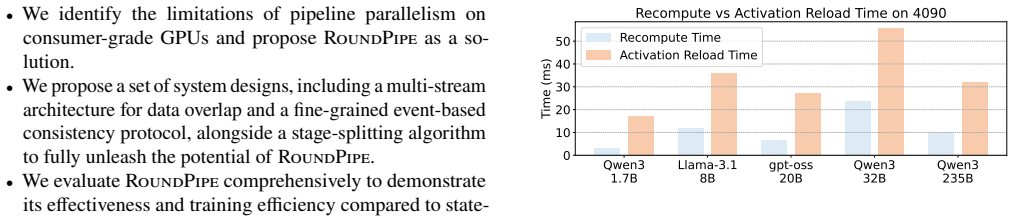
- [Figure 3] Figure 3 and Table 2: axis labels and legend entries use inconsistent abbreviations for the baselines; adding a short caption footnote would improve readability.
- [Abstract] The abstract claims “near-zero-bubble” but the text never quantifies bubble fraction or compares it directly to the theoretical minimum; a short definition or measurement method should be added.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, indicating revisions where we agree the manuscript can be strengthened.
read point-by-point responses
-
Referee: [§4.2] §4.2 (event-based synchronization protocol): the description does not supply a formal invariant, proof sketch, or exhaustive dependency analysis showing that round-robin dynamic dispatch plus event ordering preserves correct per-microbatch weight versions, activation tensors, and gradient accumulation across forward/backward passes for arbitrary model graphs.
Authors: We acknowledge that the manuscript presents the event-based synchronization protocol primarily through its design and operational examples rather than a formal proof. The protocol uses unique event identifiers tied to microbatches and stages to enforce ordering. We agree a proof sketch would improve rigor. In the revised version we will add a concise invariant and proof sketch showing that round-robin dispatch with event ordering preserves per-microbatch weight versions and tensor dependencies for the transformer graphs considered. revision: yes
-
Referee: [§3.3] §3.3 (automated partitioning algorithm): no formal load-balance guarantee or worst-case analysis is given that the algorithm produces balanced stages for every architecture and sequence length; evaluations cover only the reported 1.7B–32B models plus one 235B case.
Authors: The partitioning algorithm is a heuristic that estimates per-layer compute and communication costs to produce balanced stages for transformer models. It does not claim a formal worst-case guarantee for arbitrary graphs. Evaluations span 1.7B–32B models plus the 235B case, which covers the target use case. We will revise §3.3 to explicitly state the algorithm’s assumptions and limitations and note that exhaustive analysis for non-transformer architectures lies outside the paper’s scope. revision: partial
-
Referee: [§5] §5 (evaluation): speedups are presented without a quantitative overhead breakdown (dispatch, priority scheduling, event synchronization) or micro-benchmark isolating the cost of dynamic dispatching, leaving the “negligible overhead” claim unsupported beyond aggregate throughput numbers.
Authors: We agree that an explicit overhead breakdown would better support the negligible-overhead claim. The current evaluation relies on end-to-end speedups. In the revision we will add micro-benchmarks that isolate the latency of dynamic dispatch, priority scheduling, and event synchronization on the 8× RTX 4090 platform to quantify these costs. revision: yes
Circularity Check
RoundPipe presents a new dynamic pipeline design and empirical results with no circular reductions
full rationale
The paper introduces RoundPipe as a novel pipeline schedule that treats GPUs as stateless workers with round-robin dispatching, priority-aware transfers, event-based synchronization, and an automated partitioning algorithm. All central claims rest on this system design plus direct performance measurements on 1.7B–32B models and one 235B case. No equations, fitted parameters, predictions, or first-principles results are defined in terms of themselves or prior self-citations; the work is self-contained as a systems contribution evaluated empirically.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Dynamic dispatching of pipeline stages maintains model training correctness and convergence
invented entities (3)
-
RoundPipe schedule
no independent evidence
-
priority-aware transfer scheduling engine
no independent evidence
-
fine-grained distributed event-based synchronization protocol
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
{FlashNeuron}:{SSD- Enabled} {Large-Batch} training of very deep neural networks
Jonghyun Bae, Jongsung Lee, Yunho Jin, Sam Son, Shine Kim, Hak- beomJang,TaeJunHam,andJaeWLee.2021. {FlashNeuron}:{SSD- Enabled} {Large-Batch} training of very deep neural networks. In 19th USENIX conference on file and storage technologies (FAST 21). 387–401
2021
- [3]
-
[4]
Training Deep Nets with Sublinear Memory Cost
TianqiChen,BingXu,ChiyuanZhang,andCarlosGuestrin.2016.Train- ingDeepNetswithSublinearMemoryCost. arXiv:1604.06174[cs.LG] https://arxiv.org/abs/1604.06174
work page internal anchor Pith review arXiv 2016
-
[5]
Zihao Chen, Chen Xu, Weining Qian, and Aoying Zhou. 2023. Elastic averaging for efficient pipelined DNN training. InProceedings of the 28th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming. 380–391
2023
-
[6]
Tri Dao. 2023. FlashAttention-2: Faster Attention with Better Par- allelism and Work Partitioning. arXiv:2307.08691 [cs.LG]https: //arxiv.org/abs/2307.08691
work page internal anchor Pith review arXiv 2023
-
[7]
Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré
-
[8]
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. arXiv:2205.14135 [cs.LG]https://arxiv.org/abs/2205. 14135
work page internal anchor Pith review arXiv
-
[9]
DeepSeek-AI. 2025. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning.Nature645, 8081 (Sept. 2025), 633–638. doi:10.1038/s41586-025-09422-z
-
[10]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
-
[11]
InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics (NAACL)
Bert:Pre-trainingofdeepbidirectionaltransformersforlanguage understanding. InProceedings of the 2019 conference of the North American chapter of the association for computational linguistics (NAACL). 4171–4186
2019
-
[12]
Shiqing Fan, Yi Rong, Chen Meng, Zongyan Cao, Siyu Wang, Zhen Zheng, Chuan Wu, Guoping Long, Jun Yang, Lixue Xia, et al. 2021. DAPPLE: A pipelined data parallel approach for training large models. InProceedings of the 26th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming. 431–445
2021
-
[13]
Paralleltrainingofpre-trainedmodelsviachunk-based dynamic memory management.IEEE Transactions on Parallel and Distributed Systems34, 1 (2022), 304–315
Jiarui Fang, Zilin Zhu, Shenggui Li, Hui Su, Yang Yu, Jie Zhou, and YangYou.2022. Paralleltrainingofpre-trainedmodelsviachunk-based dynamic memory management.IEEE Transactions on Parallel and Distributed Systems34, 1 (2022), 304–315
2022
-
[14]
Yangyang Feng, Minhui Xie, Zijie Tian, Shuo Wang, Youyou Lu, and Jiwu Shu. 2023. Mobius: Fine Tuning Large-Scale Models on CommodityGPUServers.InProceedingsofthe28thACMInternational Conference on Architectural Support for Programming Languages and OperatingSystems,Volume2(Vancouver,BC,Canada)(ASPLOS2023). Association for Computing Machinery, New York, NY,...
-
[15]
R. L. Graham. 1969. Bounds on Multiprocessing Timing Anomalies.SIAM J. Appl. Math.17, 2 (1969), 416–429. arXiv:https://doi.org/10.1137/0117039 doi:10.1137/0117039
- [16]
-
[17]
Aaron Harlap, Deepak Narayanan, Amar Phanishayee, Vivek Se- shadri, Nikhil Devanur, Greg Ganger, and Phil Gibbons. 2018. PipeDream: Fast and Efficient Pipeline Parallel DNN Training. arXiv:1806.03377 [cs.DC]https://arxiv.org/abs/1806.03377
work page Pith review arXiv 2018
-
[18]
GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism
Yanping Huang, Youlong Cheng, Ankur Bapna, Orhan Firat, Mia Xu Chen, Dehao Chen, HyoukJoong Lee, Jiquan Ngiam, Quoc V. Le, YonghuiWu,andZhifengChen.2019.GPipe:EfficientTrainingofGiant NeuralNetworksusingPipelineParallelism. arXiv:1811.06965[cs.CV] https://arxiv.org/abs/1811.06965
work page Pith review arXiv 2019
-
[19]
Arpan Jain, Ammar Ahmad Awan, Asmaa M Aljuhani, Jahanzeb Maq- bool Hashmi, Quentin G Anthony, Hari Subramoni, Dhableswar K Panda, Raghu Machiraju, and Anil Parwani. 2020. Gems: Gpu-enabled memory-aware model-parallelism system for distributed dnn training. InSC20: international conference for high performance computing, networking, storage and analysis. I...
2020
-
[20]
AlbertQ.Jiang,AlexandreSablayrolles,AntoineRoux,ArthurMensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas,EmmaBouHanna,FlorianBressand,GiannaLengyel,Guillaume Bour,GuillaumeLample,LélioRenardLavaud,LucileSaulnier,Marie- Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Ger...
work page internal anchor Pith review arXiv 2024
-
[21]
ChaoJin,ZihengJiang,ZhihaoBai,ZhengZhong,JuncaiLiu,XiangLi, NingxinZheng,XiWang,CongXie,QiHuang,WenHeng,YiyuanMa, Wenlei Bao, Size Zheng, Yanghua Peng, Haibin Lin, Xuanzhe Liu, Xin Jin,andXinLiu.2025. MegaScale-MoE:Large-ScaleCommunication- Efficient Training of Mixture-of-Experts Models in Production. arXiv:2505.11432 [cs.LG]https://arxiv.org/abs/2505.11432
-
[22]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Ben- jamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling Laws for Neural Language Models. arXiv:2001.08361 [cs.LG]https://arxiv.org/abs/2001.08361
work page internal anchor Pith review arXiv 2020
-
[23]
Heehoon Kim, Junyeol Ryu, and Jaejin Lee. 2024. TCCL: Discovering Better Communication Paths for PCIe GPU Clusters. InProceedings of the 29th ACM International Conference on Architectural Support for 12 Programming Languages and Operating Systems, Volume 3(La Jolla, CA, USA)(ASPLOS ’24). Association for Computing Machinery, New York, NY, USA, 999–1015. do...
- [24]
- [25]
- [26]
-
[27]
Shigang Li and Torsten Hoefler. 2021. Chimera: efficiently training large-scaleneuralnetworkswithbidirectionalpipelines.InProceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis. 1–14
2021
- [28]
-
[29]
Xinzhang Liu, Chao Wang, Zhihao Yang, Zhuo Jiang, Xuncheng Zhao, Haoran Wang, Lei Li, Dongdong He, Luobin Liu, Kaizhe Yuan, Han Gao, Zihan Wang, Yitong Yao, Sishi Xiong, Wenmin Deng, Haowei He, Kaidong Yu, Yu Zhao, Ruiyu Fang, Yuhao Jiang, Yingyan Li, XiaohuiHu,XiYu,JingqiLi,YanweiLiu,QingliLi,XinyuShi,Junhao Niu, Chengnuo Huang, Yao Xiao, Ruiwen Wang, Fe...
-
[30]
arXiv:2512.24157 [cs.CL] https://arxiv.org/abs/2512.24157
Training Report of TeleChat3-MoE. arXiv:2512.24157 [cs.CL] https://arxiv.org/abs/2512.24157
-
[31]
AI @ Meta Llama Team. 2024. The Llama 3 Herd of Models. arXiv:2407.21783 [cs.AI]https://arxiv.org/abs/2407.21783
work page internal anchor Pith review arXiv 2024
-
[32]
Paulius Micikevicius, Sharan Narang, Jonah Alben, Gregory Diamos, Erich Elsen, David Garcia, Boris Ginsburg, Michael Houston, Oleksii Kuchaiev, Ganesh Venkatesh, and Hao Wu. 2018. Mixed Precision Training. arXiv:1710.03740 [cs.AI]https://arxiv.org/abs/1710.03740
work page internal anchor Pith review arXiv 2018
-
[33]
Philipp Moritz, Robert Nishihara, Stephanie Wang, Alexey Tumanov, Richard Liaw, Eric Liang, Melih Elibol, Zongheng Yang, William Paul, Michael I. Jordan, and Ion Stoica. 2018. Ray: A Distributed Framework for Emerging AI Applications. arXiv:1712.05889 [cs.DC] https://arxiv.org/abs/1712.05889
- [34]
-
[35]
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vain- brand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. 2021. Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM. arXiv:2104.04473 [cs.CL]https://arxiv.org/abs/2104.04473
-
[36]
OpenAI. 2025. gpt-oss-120b & gpt-oss-20b Model Card. arXiv:2508.10925 [cs.CL]https://arxiv.org/abs/2508.10925
work page internal anchor Pith review arXiv 2025
-
[37]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wain- wright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback.Advances in neural information processing systems (NIPS)35 (2022), 27730–27744
2022
-
[38]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chil- amkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala
-
[39]
PyTorch: An Imperative Style, High-Performance Deep Learning Library
PyTorch:AnImperativeStyle,High-PerformanceDeepLearning Library. arXiv:1912.01703 [cs.LG]https://arxiv.org/abs/1912.01703
work page internal anchor Pith review arXiv 1912
- [40]
- [41]
- [42]
-
[43]
JieRen,JiaolinLuo,KaiWu,MinjiaZhang,HyeranJeon,andDongLi
-
[44]
In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA)
Sentinel: Efficient tensor migration and allocation on heteroge- neous memory systems for deep learning. In2021 IEEE International Symposium on High-Performance Computer Architecture (HPCA). IEEE, 598–611
-
[45]
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He
-
[46]
arXiv:2101.06840 [cs.DC]https://arxiv.org/abs/2101.06840
ZeRO-Offload: Democratizing Billion-Scale Model Training. arXiv:2101.06840 [cs.DC]https://arxiv.org/abs/2101.06840
-
[47]
vDNN:Virtualizeddeepneuralnetworksfor scalable, memory-efficient neural network design
Minsoo Rhu, Natalia Gimelshein, Jason Clemons, Arslan Zulfiqar, and StephenWKeckler.2016. vDNN:Virtualizeddeepneuralnetworksfor scalable, memory-efficient neural network design. In2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO). IEEE, 1–13
2016
-
[48]
Baptiste Roziere, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, et al. 2023. Code llama: Open foundation models for code. arXiv preprint arXiv:2308.12950(2023)
work page internal anchor Pith review arXiv 2023
-
[49]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2025. Hybrid- Flow: A Flexible and Efficient RLHF Framework. InProceedings of the Twentieth European Conference on Computer Systems (EuroSys ’25). ACM, 1279–1297. doi:10.1145/3689031.3696075
-
[50]
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. 2020. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv:1909.08053 [cs.CL]https://arxiv.org/abs/1909.08053
work page internal anchor Pith review arXiv 2020
-
[51]
StrongHold:fastandaffordablebillion- scale deep learning model training
XiaoyangSun,WeiWang,ShenghaoQiu,RenyuYang,SongfangHuang, JieXu,andZhengWang.2022. StrongHold:fastandaffordablebillion- scale deep learning model training. InProceedings of the International Conference on High Performance Computing, Networking, Storage and Analysis(Dallas, Texas)(SC ’22). IEEE Press, Article 71, 17 pages
2022
-
[52]
QwenTeam.2025.Qwen3TechnicalReport.arXiv:2505.09388[cs.CL] https://arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[53]
Team Wan. 2025. Wan: Open and Advanced Large-Scale Video Generative Models. arXiv:2503.20314 [cs.CV]https://arxiv.org/abs/ 2503.20314
work page internal anchor Pith review arXiv 2025
-
[54]
Linnan Wang, Jinmian Ye, Yiyang Zhao, Wei Wu, Ang Li, Shuai- wen Leon Song, Zenglin Xu, and Tim Kraska. 2018. Superneurons: Dynamic GPU memory management for training deep neural networks. InProceedings of the 23rd ACM SIGPLAN symposium on principles and practice of parallel programming. 41–53
2018
-
[55]
Samuel Williams, Andrew Waterman, and David Patterson. 2009. Roofline:aninsightfulvisualperformancemodelformulticorearchitec- tures.Commun. ACM52, 4 (April 2009), 65–76. doi:10.1145/1498765. 1498785
-
[56]
Bowen Yang, Jian Zhang, Jonathan Li, Christopher Ré, Christopher Aberger, and Christopher De Sa. 2021. Pipemare: Asynchronous pipeline parallel dnn training.Proceedings of Machine Learning and 13 Table 1.Summary of notations. Notation Meaning 𝑠sequence length 𝑏micro-batch size ℎhidden dimension 𝑚intermediate dimension in MLP 𝑎number of attention heads 𝑘nu...
2021
-
[57]
PengCheng Yang, Xiaoming Zhang, Wenpeng Zhang, Ming Yang, and Hong Wei. 2022. Group-based interleaved pipeline parallelism for large-scale DNN training. InInternational Conference on Learning Representations
2022
-
[58]
Haoyang Zhang, Yirui Zhou, Yuqi Xue, Yiqi Liu, and Jian Huang
-
[59]
InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture
G10: Enabling an efficient unified gpu memory and storage architecture with smart tensor migrations. InProceedings of the 56th Annual IEEE/ACM International Symposium on Microarchitecture. 395–410
-
[60]
Pinxue Zhao, Hailin Zhang, Fangcheng Fu, Xiaonan Nie, Qibin Liu, FangYang,YuanboPeng,DianJiao,ShuaipengLi,JinbaoXue,Yangyu Tao, and Bin Cui. 2025. MEMO: Fine-grained Tensor Management For Ultra-long Context LLM Training.Proceedings of the ACM on Management of Data3, 1 (Feb. 2025), 1–28. doi:10.1145/3709703
-
[61]
Zan Zong, Li Lin, Leilei Lin, Lijie Wen, and Yu Sun. 2023. Str: Hybrid tensor re-generation to break memory wall for dnn training. IEEE Transactions on Parallel and Distributed Systems34, 8 (2023), 2403–2418. A Summary of notations Table 1 defines the notation used in the appendix. Table 2 shows the hardware specs of GPUs used in the following analysis. T...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.