Recognition: unknown
What Suppresses Nash Equilibrium Play in Large Language Models? Mechanistic Evidence and Causal Control
Pith reviewed 2026-05-07 10:24 UTC · model grok-4.3
The pith
Large language models internally compute Nash equilibria but suppress them via prosocial overrides from pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
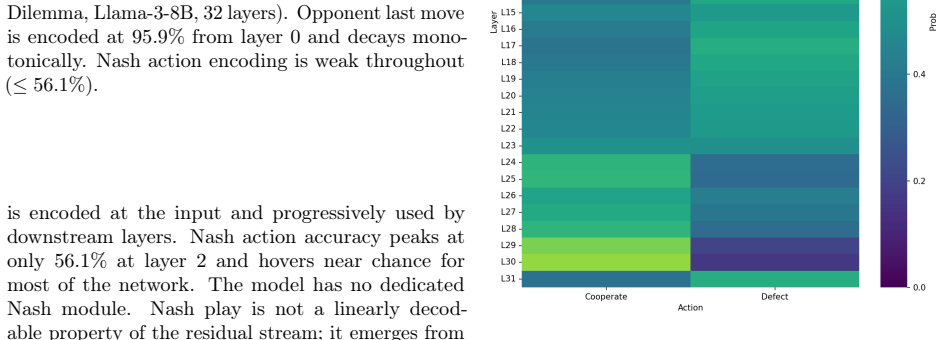
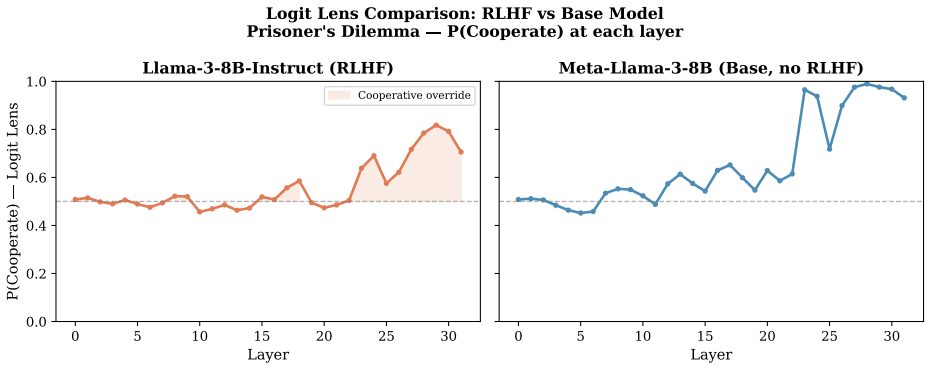
Working with open-source LLMs in four two-player games, the study shows opponent history encodes with 96 percent probe accuracy at the first layer while Nash encoding stays weak. The model privately favors Nash actions but a prosocial override in final layers boosts cooperation probability to 84 percent at layer 30. Injecting a learned Nash direction into the residual stream causally shifts behavior bidirectionally, establishing that LLMs compute but suppress Nash play rather than lacking competence.
What carries the argument
The late-stage prosocial override in the residual stream that reverses the model's internal Nash preference, identified through linear probes and concept clamping.
If this is right
- Chain-of-thought prompting improves Nash performance in large models above 70 billion parameters but worsens it in smaller ones.
- Cross-play reveals that small models defect early to unravel partner cooperation while large models sustain mutual cooperation.
- First-mover position determines which Nash equilibrium the interacting models converge on.
- Causal interventions on the residual stream allow bidirectional control over deviation from Nash play.
Where Pith is reading between the lines
- Activation editing techniques could be used to create LLM agents that play more rationally in economic or negotiation scenarios.
- The suppression mechanism may apply to other tasks where pretraining on human data conflicts with optimal reasoning.
- Training models on synthetic data emphasizing equilibrium play might reduce the strength of this override.
Load-bearing premise
That the linear probes and concept directions accurately reflect the model's decision process and that intervening on them causes no unintended side effects on other computations.
What would settle it
Demonstrating that the model does not shift toward Nash play when the prosocial direction is clamped or the Nash direction is injected would falsify the suppression account.
Figures




read the original abstract
LLM agents are known to deviate from Nash equilibria in strategic interactions, but nobody has looked inside the model to understand why, or asked whether the deviation can be reversed. We do both. Working with four open-source models (Llama-3 and Qwen2.5, 8B to 72B parameters) playing four canonical two-player games, we establish the behavioral picture through self-play and cross-play experiments, then open up the 32-layer Llama-3-8B model and examine what actually happens during a strategic decision. The mechanistic findings are clear. Opponent history is encoded with near-perfect fidelity at the first layer (96% probe accuracy) and consumed progressively, while Nash action encoding is weak throughout, never exceeding 56%. There is no dedicated Nash module. Instead, the model privately favors the Nash action through most of its forward pass, but a prosocial override rooted in pretraining on human text concentrated in the final layers reverses this, reaching 84% probability of cooperation at layer 30. Injecting a learned Nash direction into the residual stream shifts behavior bidirectionally and causally, confirmed through concept clamping. The behavioral experiments surface six scale- and architecture-dependent findings, the most notable being that chain-of-thought reasoning worsens Nash play in small models but achieves near-perfect Nash play above 70B parameters. The cross-play experiments reveal three phenomena invisible in self-play: a small model can unravel any partner's cooperation by defecting early; two large models reinforce each other's cooperative instincts indefinitely; and who moves first determines which Nash equilibrium the system reaches. LLMs do not lack Nash-playing competence. They compute it, then suppress it.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs do not lack Nash-playing competence in canonical two-player games; they internally compute or privately favor the Nash action through most layers but suppress it via a prosocial override concentrated in the final layers due to pretraining. This is evidenced by self-play and cross-play behavioral results across four models and games, linear probes showing 96% accuracy for opponent history but at most 56% for Nash actions, and causal interventions that bidirectionally shift behavior by injecting a learned Nash direction into the residual stream of Llama-3-8B.
Significance. If the mechanistic claims hold, the work provides a concrete internal account of non-equilibrium play in LLMs and demonstrates that this suppression can be reversed through targeted interventions. The multi-scale behavioral findings (including CoT effects and cross-play phenomena) combined with probe-based and causal evidence represent a useful template for analyzing strategic decision-making in language models, with potential implications for multi-agent AI systems and alignment.
major comments (2)
- [mechanistic findings on Nash encoding] The probe accuracy for Nash action encoding never exceeds 56% (Abstract and mechanistic results section). For binary action spaces typical of the games studied, this is only marginally above chance and provides a weak basis for the claim that the model 'computes' or 'privately favors' the Nash equilibrium through most of the forward pass. Without reported checks for probe linearity, random baselines, or mutual information, it remains unclear whether the weak signal reflects genuine internal computation rather than surface correlations, which is load-bearing for the central suppression narrative.
- [intervention experiments] The causal intervention results via concept clamping and Nash direction injection (mechanistic section) are presented as reversing the final-layer override, but the manuscript does not report full ablation controls, side-effect measurements on unrelated computations, or corrections for multiple testing across layers/games. This weakens the strength of the causal claim, especially given the abstract's omission of statistical details.
minor comments (3)
- [Abstract] The abstract should specify sample sizes, exact statistical tests, and any multiple-comparison corrections applied to probe accuracies and intervention effects.
- [behavioral experiments] Clarify the precise definitions and layer-wise measurements used for 'private favoring' versus the prosocial override, and ensure all behavioral findings (e.g., the six scale-dependent effects) include error bars or p-values.
- [discussion] Add a brief discussion of potential limitations of linear probes in the context of residual-stream interventions to preempt concerns about artifacts.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas where our mechanistic evidence can be strengthened. We address each major comment below and outline the revisions we will make to the manuscript.
read point-by-point responses
-
Referee: [mechanistic findings on Nash encoding] The probe accuracy for Nash action encoding never exceeds 56% (Abstract and mechanistic results section). For binary action spaces typical of the games studied, this is only marginally above chance and provides a weak basis for the claim that the model 'computes' or 'privately favors' the Nash equilibrium through most of the forward pass. Without reported checks for probe linearity, random baselines, or mutual information, it remains unclear whether the weak signal reflects genuine internal computation rather than surface correlations, which is load-bearing for the central suppression narrative.
Authors: We agree that a probe accuracy of 56% constitutes a relatively weak signal and is only marginally above chance level for binary classification. The manuscript already describes the Nash encoding as 'weak throughout,' but we recognize that this alone does not strongly support claims of internal computation or private favoring without additional validation. To strengthen this, we will incorporate random baseline comparisons, assessments of probe linearity by comparing to nonlinear probes, and estimates of mutual information between activations and Nash labels in the revised manuscript. These additions will clarify whether the signal reflects genuine encoding. We note that the overall narrative also relies on the high-fidelity opponent history encoding and the causal intervention results, which show behavioral shifts consistent with overriding a Nash preference. revision: partial
-
Referee: [intervention experiments] The causal intervention results via concept clamping and Nash direction injection (mechanistic section) are presented as reversing the final-layer override, but the manuscript does not report full ablation controls, side-effect measurements on unrelated computations, or corrections for multiple testing across layers/games. This weakens the strength of the causal claim, especially given the abstract's omission of statistical details.
Authors: We concur that the causal claims would benefit from more comprehensive controls. In the revised version, we will add ablation experiments using random or unrelated directions to demonstrate specificity, report side-effect measurements on non-strategic tasks, and apply appropriate multiple testing corrections (e.g., Bonferroni) across the layers and games tested. Additionally, we will update the abstract to include key statistical details such as effect sizes and significance levels from the intervention results. These revisions will provide a more robust foundation for the causal interpretation of the Nash direction injection. revision: yes
Circularity Check
No significant circularity in mechanistic claims or derivation chain
full rationale
The paper's core argument—that LLMs encode Nash actions weakly but suppress them via a prosocial override—is supported by empirical linear probe accuracies on residual stream activations (opponent history at 96%, Nash at ≤56%) and causal interventions via learned direction clamping that produce bidirectional behavioral shifts. These steps rely on external game payoffs for labels and independent verification through self-play/cross-play experiments, not on any self-definitional reduction, fitted parameter renamed as prediction, or load-bearing self-citation. No equations or claims reduce by construction to their inputs; the findings are falsifiable against held-out behavioral data.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Linear probes trained on activations can decode internal representations with high fidelity
- domain assumption Adding a learned direction vector to the residual stream produces targeted causal changes without major unintended side effects
Reference graph
Works this paper leans on
-
[1]
URL https://transformer-circuits. pub/2021/framework/index.html. Nicolò Fontana, Francesco Pierri, and Luca Maria Aiello. Nicer than humans: How do large language 10 models behave in the Prisoner’s Dilemma? In Proceedings of the International AAAI Conference on Web and Social Media, volume 19, 2025. doi: 10.1609/icwsm.v19i1.35829. Ian Gemp, Rohan Patel, Y...
-
[2]
doi: 10.1257/aer.91.5.1402. John C. Harsanyi and Reinhard Selten.A General Theory of Equilibrium Selection in Games. The MIT Press, Cambridge, MA, 1988. Sergiu Hart and Andreu Mas-Colell. A simple adaptive procedure leading to correlated equilib- rium.Econometrica, 68(5):1127–1150, 2000. doi: 10.1111/1468-0262.00153. Jingru Jia, Zehua Yuan, Junfeng Pan, P...
-
[3]
URL https://openreview.net/forum?id= DeG07_TcZvT. Ji Ma. Steering prosocial AI agents: Compu- tational basis of LLM’s decision making in social simulation.Social Psychology Quarterly,
-
[4]
URL https://journals.sagepub.com/doi/full/10
doi: 10.1177/00811750261421220. URL https://journals.sagepub.com/doi/full/10. 1177/00811750261421220. Callum McDougall, Arthur Conmy, Cody Rushing, Thomas McGrath, and Neel Nanda. Copy suppres- sion: Comprehensively understanding an attention head. InNeurIPS Workshop on Attributing Model Behavior at Scale, 2023. Kevin Meng, David Bau, Alex Andonian, and Y...
-
[5]
Steering Language Models With Activation Engineering
URL https://arxiv.org/abs/2308.10248. Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretabil- ity in the wild: A circuit for indirect object identifi- cation in GPT-2 small. InInternational Conference on Learning Representations, 2023. URL https: //openreview.net/forum?id=NpsVSN6o4ul. Jason Wei, Xuezhi Wang, Da...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.