Recognition: unknown
A Discipline-Agnostic AI Literacy Course for Academic Research: Architecture, Pedagogy, and Implementation
Pith reviewed 2026-05-07 09:02 UTC · model grok-4.3
The pith
A four-module course builds critical judgment for using generative AI in academic literature reviews.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
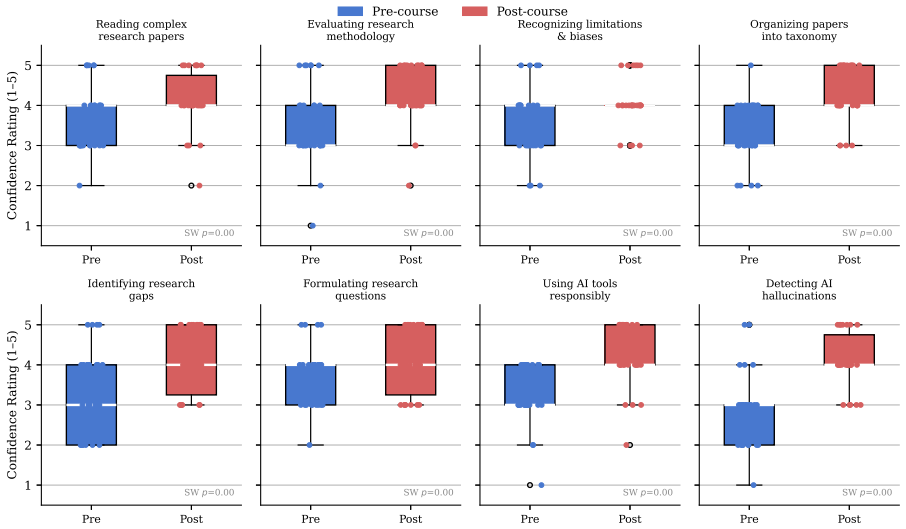
The course organizes instruction into four sequential modules aligned with the cognitive demands of AI-assisted literature review: comprehension of individual papers, construction and validation of knowledge taxonomies, identification of research gaps, and synthesis and production of complete literature reviews. Each module embeds an explicit verification discipline and standardized AI attribution practice. Pre- and post-course survey data indicate substantial self-reported confidence gains, with the largest in hallucination detection, responsible AI use, and AI attribution practice. The course constitutes a replicable model for the emerging genre of AI research literacy curricula.
What carries the argument
Four sequential modules matched to the cognitive steps of literature review work, each incorporating mandatory verification of AI outputs and standardized attribution of AI assistance.
If this is right
- Students develop stronger habits for detecting errors in AI-generated research content.
- Responsible AI use and proper attribution become routine elements of scholarly workflows.
- The modular structure supports differentiated expectations for upper-level undergraduates and graduate students.
- Other programs can adopt the same sequence to meet AI literacy needs without discipline-specific prerequisites.
Where Pith is reading between the lines
- Widespread use could reduce undetected AI inaccuracies in student and early-career research outputs.
- The verification emphasis could extend naturally to AI applications in data analysis or hypothesis formulation.
- Similar structured approaches might inform training for other AI-influenced academic tasks such as peer review.
Load-bearing premise
Self-reported confidence gains from a single course offering accurately reflect lasting improvements in actual research competencies and the four-module design transfers successfully to other instructors and institutions.
What would settle it
A follow-up assessment that measures actual performance on verified AI-assisted literature review tasks several months after the course, compared against a control group of similar students who did not take it.
Figures








read the original abstract
The rapid integration of generative AI into academic workflows demands curricula that equip students not only with tool proficiency but with the critical judgment to use those tools responsibly in scholarly work. Existing offerings cluster around two inadequate poles: technical AI development courses serving narrow specialist audiences, and brief general-literacy interventions that cannot develop the sustained, practice-based competencies rigorous research requires. This paper reports the design, theoretical rationale, and implementation of BSTA 495/395: Getting Started with AI-Assisted Research, developed and delivered at Lehigh University (Spring 2026). The course addresses an underserved gap: the competencies required for rigorous AI-assisted literature review. Its architecture organizes instruction into four sequential modules aligned with the cognitive demands of that task: comprehension of individual papers, construction and validation of knowledge taxonomies, identification of research gaps, and synthesis and production of complete literature reviews. Each module embeds an explicit verification discipline and standardized AI attribution practice. Prerequisite-free and discipline-agnostic, the course enrolls upper-level undergraduates and graduate students across all fields with differentiated assessment expectations. Pre- and post-course survey data from the inaugural offering indicate substantial self-reported confidence gains, with the largest in hallucination detection (d = +1.45), responsible AI use (d = +1.33), and AI attribution practice (d = +2.40), consistent with the course's design emphasis. The course constitutes a replicable model for the emerging genre of AI research literacy curricula.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the design, theoretical rationale, and implementation of BSTA 495/395: Getting Started with AI-Assisted Research, a prerequisite-free, discipline-agnostic course at Lehigh University. It structures instruction into four sequential modules aligned with the cognitive demands of AI-assisted literature review (paper comprehension, knowledge taxonomy construction and validation, research gap identification, and synthesis/production), each embedding verification disciplines and standardized AI attribution practices. Pre- and post-course survey data from the inaugural offering are reported to show substantial self-reported confidence gains, largest in hallucination detection (d=+1.45), responsible AI use (d=+1.33), and AI attribution practice (d=+2.40). The work positions the course as a replicable model for AI research literacy curricula.
Significance. If the central claims hold, the paper supplies a detailed, practice-oriented curriculum template that bridges the gap between narrow technical AI courses and superficial literacy interventions, with explicit attention to scholarly integrity through verification and attribution. The module architecture, grounded in cognitive task analysis of literature review, represents a concrete contribution that could guide other institutions. The reported effect sizes, while preliminary, highlight areas where targeted pedagogy may yield measurable confidence shifts. These elements provide a foundation for future empirical work on AI literacy outcomes.
major comments (2)
- [Evaluation/results section] Evaluation/results section: The manuscript reports effect sizes from pre/post Likert surveys (e.g., d=+2.40 for attribution practice) but supplies no sample size, response rate, statistical test details, or handling of missing data. Without these, the reliability and generalizability of the 'substantial gains' claim cannot be assessed, directly undermining the evidence for the course's effectiveness.
- [Discussion/conclusion] Discussion/conclusion: The claim that the course 'constitutes a replicable model' rests solely on one designer-led offering; no multi-instructor, multi-institution, or longitudinal data are provided to support transfer of the four-module structure and verification practices. This makes the replicability assertion load-bearing yet unsupported.
minor comments (2)
- [Abstract and methods] Clarify whether the reported semester (Spring 2026) is prospective or retrospective, and ensure any tables summarizing survey items or demographics are fully referenced in the text.
- [Abstract] The abstract and introduction could more explicitly distinguish self-reported confidence from objective competency measures to avoid overstatement of outcomes.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to supply the missing statistical details in the evaluation section and to qualify the replicability language in the discussion and conclusion. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Evaluation/results section] Evaluation/results section: The manuscript reports effect sizes from pre/post Likert surveys (e.g., d=+2.40 for attribution practice) but supplies no sample size, response rate, statistical test details, or handling of missing data. Without these, the reliability and generalizability of the 'substantial gains' claim cannot be assessed, directly undermining the evidence for the course's effectiveness.
Authors: We accept the criticism. The original manuscript omitted these methodological details for the pre/post survey results. In the revised version we have added the sample size (the complete cohort of the inaugural offering), the response rate (full participation on both pre- and post-surveys), the statistical procedures (paired t-tests with Cohen’s d effect sizes), and confirmation that no data were missing. We have also inserted an explicit limitations paragraph noting the small pilot scale and preliminary character of the findings, which appropriately tempers any broader generalization while retaining the descriptive value of the observed confidence shifts. revision: yes
-
Referee: [Discussion/conclusion] Discussion/conclusion: The claim that the course 'constitutes a replicable model' rests solely on one designer-led offering; no multi-instructor, multi-institution, or longitudinal data are provided to support transfer of the four-module structure and verification practices. This makes the replicability assertion load-bearing yet unsupported.
Authors: We agree that the original phrasing overstated the current evidence base. The course is offered as a concrete, theory-grounded template derived from cognitive task analysis of literature review, not as an already-validated replicable curriculum. In the revision we have replaced the assertion that the course “constitutes a replicable model” with the more accurate statement that it “supplies a detailed template that other institutions can adapt and test.” We have added a forward-looking paragraph describing planned multi-instructor and multi-institution pilots and longitudinal tracking. revision: yes
- Empirical evidence of transferability across instructors, institutions, or time is not available from the single inaugural offering and cannot be supplied in the present revision.
Circularity Check
No circularity: course design and pilot evaluation are self-contained
full rationale
The paper describes the four-module architecture of BSTA 495/395, its alignment with literature-review competencies, and reports pre/post Likert-scale confidence gains from the single inaugural offering. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citations appear in the provided text. The central claims rest on direct observation of the implemented course rather than any reduction by construction to prior inputs. Self-reported survey data from the designer’s own cohort is a standard limitation of pilot studies but does not constitute circularity under the defined patterns, as there is no redefinition of outcomes or load-bearing appeal to unverified self-citations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Aligning instruction modules with the cognitive sequence of literature review tasks improves AI-assisted research skills
- domain assumption Explicit verification disciplines and standardized AI attribution practices reduce risks of generative AI in scholarly work
Reference graph
Works this paper leans on
-
[1]
Chatting and cheating: Ensuring academic integrity in the era of chatgpt
Debby RE Cotton, Peter A Cotton, and J Reuben Shipway. Chatting and cheating: Ensuring academic integrity in the era of chatgpt. Innovations in education and teaching international, 61(2):228–239, 2024
2024
-
[2]
Chatting about chatgpt: How may ai and gpt impact academia and libraries
BD Lund. Chatting about chatgpt: How may ai and gpt impact academia and libraries. Library Hi Tech News , 2023
2023
-
[3]
Large language models 31 challenge the future of higher education
Silvia Milano, Joshua A McGrane, and Sabina Leonelli. Large language models 31 challenge the future of higher education. Nature Machine Intelligence , 5(4):333–334, 2023
2023
-
[4]
Chatgpt listed as author on research papers: many scientists disapprove, 2023
Chris Stokel-Walker. Chatgpt listed as author on research papers: many scientists disapprove, 2023
2023
-
[5]
Large language models in medicine
Arun James Thirunavukarasu, Darren Shu Jeng Ting, Kabilan Elangovan, Laura Gutierrez, Ting Fang Tan, and Daniel Shu Wei Ting. Large language models in medicine. Nature medicine, 29(8):1930–1940, 2023
1930
-
[6]
High-performance medicine: the convergence of human and artificial intelligence
Eric J Topol. High-performance medicine: the convergence of human and artificial intelligence. Nature medicine, 25(1):44–56, 2019
2019
-
[7]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM computing surveys , 55(12):1–38, 2023
2023
-
[8]
Artificial hallucinations in chatgpt: impli- cations in scientific writing
Hussam Alkaissi and Samy I McFarlane. Artificial hallucinations in chatgpt: impli- cations in scientific writing. Cureus, 15(2), 2023
2023
-
[9]
Design experiments: Theoretical and methodological challenges in creating complex interventions in classroom settings
Ann L Brown. Design experiments: Theoretical and methodological challenges in creating complex interventions in classroom settings. The journal of the learning sciences, 2(2):141–178, 1992
1992
-
[10]
Toward a design science of education
Allan Collins. Toward a design science of education. In New directions in educational technology, pages 15–22. Springer, 1992
1992
-
[11]
What is ai literacy? competencies and design consid- erations
Duri Long and Brian Magerko. What is ai literacy? competencies and design consid- erations. In Proceedings of the 2020 CHI conference on human factors in computing systems, pages 1–16, 2020
2020
-
[12]
Conceptualizing ai literacy: An exploratory review
Davy Tsz Kit Ng, Jac Ka Lok Leung, Samuel Kai Wah Chu, and Maggie Shen Qiao. Conceptualizing ai literacy: An exploratory review. Computers and Education: Artificial Intelligence, 2:100041, 2021
2021
-
[13]
Em- powering educators to be ai-ready
Rosemary Luckin, Mutlu Cukurova, Carmel Kent, and Benedict Du Boulay. Em- powering educators to be ai-ready. Computers and education: artificial intelligence , 3:100076, 2022
2022
-
[14]
Amarda Shehu. From understanding to creation: A prerequisite-free ai literacy course with technical depth across majors. arXiv preprint arXiv:2604.09634 , 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
The literature review: Six steps to success
Lawrence A Machi and Brenda T McEvoy. The literature review: Six steps to success. 2009
2009
-
[16]
Teaching literature reviewing for software engi- neering research
Sebastian Baltes and Paul Ralph. Teaching literature reviewing for software engi- neering research. In Handbook on Teaching Empirical Software Engineering , pages 529–555. Springer, 2024
2024
-
[17]
Mind in society: Development of higher psychological processes
Lev Semenovich Vygotsky and Michael Cole. Mind in society: Development of higher psychological processes. Harvard university press, 1978. 32
1978
-
[18]
The role of tutoring in problem solving
David Wood, Jerome S Bruner, and Gail Ross. The role of tutoring in problem solving. Journal of child psychology and psychiatry , 17(2):89–100, 1976
1976
-
[19]
Situation awareness, mental workload, and trust in automation: Viable, empirically supported cognitive engineering constructs
Raja Parasuraman, Thomas B Sheridan, and Christopher D Wickens. Situation awareness, mental workload, and trust in automation: Viable, empirically supported cognitive engineering constructs. Journal of cognitive engineering and decision mak- ing, 2(2):140–160, 2008
2008
-
[20]
Trust in automation: Designing for appropriate reliance
John D Lee and Katrina A See. Trust in automation: Designing for appropriate reliance. Human factors , 46(1):50–80, 2004
2004
-
[21]
Developing trustworthy artificial intelligence: insights from research on interpersonal, human-automation, and human-ai trust
Yugang Li, Baizhou Wu, Yuqi Huang, and Shenghua Luan. Developing trustworthy artificial intelligence: insights from research on interpersonal, human-automation, and human-ai trust. Frontiers in psychology , 15:1382693, 2024
2024
-
[22]
Threshold concepts and troublesome knowledge: Linkages to ways of thinking and
Jan Meyer and Ray Land. Threshold concepts and troublesome knowledge: Linkages to ways of thinking and. Princeton: Citeseer , 2003
2003
-
[23]
Do we need to close the door on threshold concepts? Teaching and Learning in Medicine , 34(3):301–312, 2022
Megan EL Brown, Paul Whybrow, and Gabrielle M Finn. Do we need to close the door on threshold concepts? Teaching and Learning in Medicine , 34(3):301–312, 2022
2022
-
[24]
The measurement of observer agreement for categorical data
J Richard Landis and Gary G Koch. The measurement of observer agreement for categorical data. biometrics, pages 159–174, 1977
1977
-
[25]
Statistical power analysis for the behavioral sciences, lawrence erlbaum associates
Jacob Cohen. Statistical power analysis for the behavioral sciences, lawrence erlbaum associates. Hillsdale, NJ , pages 20–26, 1988. 33
1988
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.