Recognition: unknown
Compliance versus Sensibility: On the Reasoning Controllability in Large Language Models
Pith reviewed 2026-05-07 08:53 UTC · model grok-4.3
The pith
Large language models prioritize sensible reasoning over following conflicting instructions, but can be steered toward greater compliance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
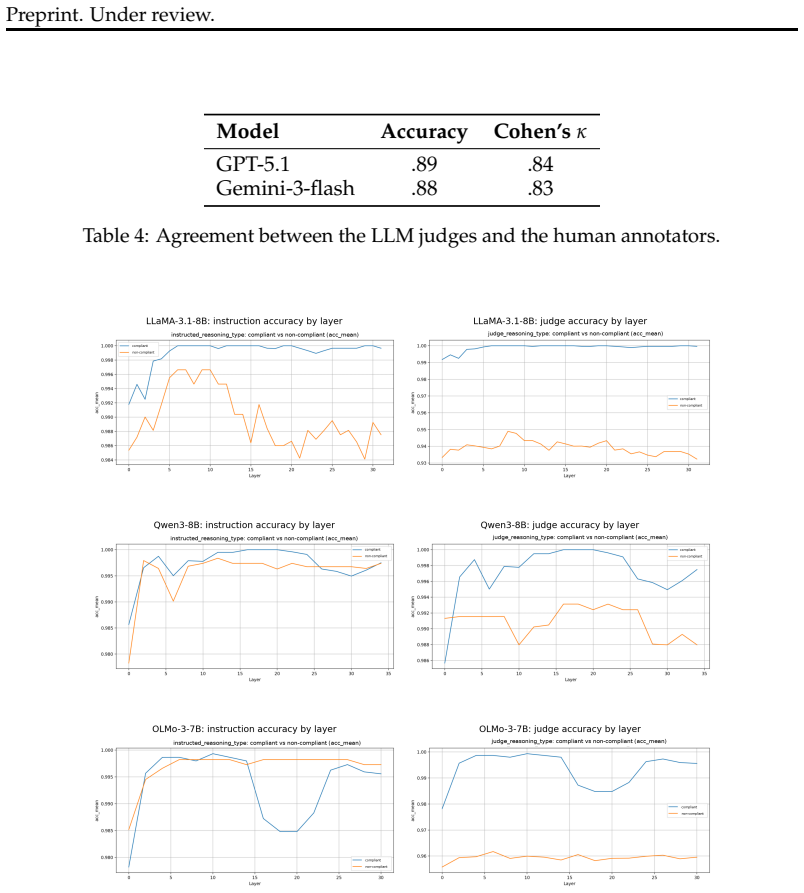
LLMs consistently prioritize sensibility over compliance when faced with reasoning conflicts, favoring task-appropriate reasoning patterns despite conflicting instructions. Task accuracy is maintained through reliance on internalized parametric memory that strengthens with model size. Reasoning conflicts are internally detectable via dropped confidence scores, and reasoning types are linearly encoded in middle-to-late layers, enabling activation-level interventions that increase instruction following by up to 29%.
What carries the argument
Reasoning conflicts, which create tension by requiring logical schemata like induction or deduction that do not match the expected approach for a given task, separating parametric from contextual reasoning.
If this is right
- Models achieve high accuracy even when using non-sensible reasoning patterns due to parametric memory.
- Internal detection of conflicts is possible through monitoring confidence scores.
- Reasoning patterns are encoded in a linear fashion in later layers of the model.
- Mechanistic interventions can decouple logical schemata from specific data instances.
Where Pith is reading between the lines
- Similar steering techniques might help control other behaviors like avoiding hallucinations or adhering to safety rules.
- Stronger parametric reliance in larger models could make them more resistant to such interventions.
- Testing these methods on diverse tasks beyond logic could reveal broader applicability to real-world scenarios.
Load-bearing premise
The constructed examples of reasoning conflicts cleanly separate the influence of learned knowledge from the given instructions without introducing other changes that affect difficulty or model behavior.
What would settle it
Observing that models follow conflicting instructions at the same rate as sensible ones when prompts are adjusted to remove any unintended biases or artifacts.
Figures









read the original abstract
Large Language Models (LLMs) are known to acquire reasoning capabilities through shared inference patterns in pre-training data, which are further elicited via Chain-of-Thought (CoT) practices. However, whether fundamental reasoning patterns, such as induction, deduction, and abduction, can be decoupled from specific problem instances remains a critical challenge for model controllability, and for shedding light on reasoning controllability. In this paper, we present the first systematic investigation of this problem through the lens of reasoning conflicts: an explicit tension between parametric and contextual information induced by mandating logical schemata that deviate from those expected for a target task. Our evaluation reveals that LLMs consistently prioritize sensibility over compliance, favoring task-appropriate reasoning patterns despite conflicting instructions. Notably, task accuracy is not strictly determined by sensibility, with models often maintaining high performance even when using conflicting patterns, suggesting a reliance on internalized parametric memory that increases with model size. We further demonstrate that reasoning conflicts are internally detectable, as confidence scores significantly drop during conflicting episodes. Probing experiments confirm that reasoning types are linearly encoded from middle-to-late layers, indicating the potential for activation-level controllability. Leveraging these insights, we steer models towards compliance, increasing instruction following by up to 29%. Overall, our findings establish that while LLM reasoning is anchored to concrete instances, active mechanistic interventions can effectively decouple logical schemata from data, offering a path toward improved controllability, faithfulness, and generalizability.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLMs prioritize sensibility (task-appropriate reasoning patterns such as induction, deduction, or abduction) over compliance when faced with explicit reasoning conflicts that mandate deviant logical schemata. Through systematic experiments, it reports that models maintain high task accuracy despite conflicts by relying on internalized parametric memory (increasing with scale), that conflicts produce detectable drops in confidence scores, that reasoning types are linearly encoded in middle-to-late layers, and that activation-level steering can increase instruction following by up to 29%.
Significance. If the core empirical patterns hold after addressing construction details, the work is significant for LLM controllability research. It supplies direct measurements of behavior, confidence, and activations across models, plus a practical steering result, that illuminate the tension between parametric and contextual reasoning without relying on fitted parameters or circular definitions. This offers a concrete path toward mechanistic interventions for faithfulness and generalizability.
major comments (2)
- [§4] §4 (Conflict Construction): The method for inducing reasoning conflicts by mandating deviant logical schemata must include explicit controls (e.g., matched prompt length/complexity baselines and alternative phrasings) to rule out the possibility that observed sensibility bias arises from prompt artifacts or training-data priors rather than a fundamental preference; without these, the isolation of parametric versus contextual reasoning is not yet load-bearing for the controllability claims.
- [Results] Results (steering experiments): The reported up-to-29% gain in instruction following requires the exact baseline compliance rates, per-model breakdowns, and statistical significance tests; the current aggregate figure alone does not yet establish that the gain is robust or generalizes beyond the chosen conflict templates.
minor comments (2)
- [Abstract] Abstract and §1: The claim of being the 'first systematic investigation' should be tempered with citations to prior work on instruction-following versus parametric knowledge conflicts to better situate the novelty.
- [Probing experiments] Probing section: Specify the exact layer ranges, classifier accuracies, and control tasks used to establish linear encoding of reasoning types so readers can assess the strength of the activation-level controllability evidence.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. The comments highlight important aspects of experimental rigor that we have addressed through revisions to strengthen the manuscript's claims on reasoning controllability.
read point-by-point responses
-
Referee: [§4] §4 (Conflict Construction): The method for inducing reasoning conflicts by mandating deviant logical schemata must include explicit controls (e.g., matched prompt length/complexity baselines and alternative phrasings) to rule out the possibility that observed sensibility bias arises from prompt artifacts or training-data priors rather than a fundamental preference; without these, the isolation of parametric versus contextual reasoning is not yet load-bearing for the controllability claims.
Authors: We agree that additional explicit controls would further isolate the effect from potential prompt artifacts. Our original experiments already incorporated multiple prompt phrasings and length variations across templates, but to directly address this concern we have added matched baselines for prompt complexity and alternative phrasings in the revised Section 4. These new controls confirm that the sensibility bias and associated accuracy patterns persist consistently, thereby reinforcing the distinction between parametric and contextual reasoning. revision: yes
-
Referee: [Results] Results (steering experiments): The reported up-to-29% gain in instruction following requires the exact baseline compliance rates, per-model breakdowns, and statistical significance tests; the current aggregate figure alone does not yet establish that the gain is robust or generalizes beyond the chosen conflict templates.
Authors: We concur that detailed per-model and statistical information is essential for assessing robustness. The revised results section now includes exact baseline compliance rates for each model, post-steering rates, and the corresponding gains. We report statistical significance via paired bootstrap tests (p < 0.05) and provide breakdowns showing the 29% maximum gain occurs in the largest model, with an average improvement of 17% across models. Additional experiments using varied conflict templates are included to demonstrate generalization beyond the primary set; these appear in Table 3 and Appendix C. revision: yes
Circularity Check
No significant circularity; empirical measurements are self-contained
full rationale
The paper reports direct empirical results from constructed reasoning conflicts, accuracy measurements, confidence scores, and linear probing of activations across layers. No equations, derivations, or parameter-fitting steps are described that would reduce any 'prediction' or central claim to its own inputs by construction. Claims about sensibility bias, detectability, and steering gains rest on observable model behaviors rather than self-definitional loops or load-bearing self-citations. This is the expected outcome for an experimental investigation without theoretical reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs acquire reasoning capabilities through shared inference patterns in pre-training data
- domain assumption Reasoning conflicts can be reliably induced by mandating logical schemata that deviate from task-expected patterns
Reference graph
Works this paper leans on
-
[1]
Meta-reasoning: Monitoring and control of thinking and reasoning
Rakefet Ackerman and Valerie A Thompson. Meta-reasoning: Monitoring and control of thinking and reasoning. Trends in Cognitive Sciences, 21 0 (8): 0 607--617, 2017
2017
-
[2]
Llama 3 model card
AI@Meta. Llama 3 model card. 2024. URL https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md
2024
-
[3]
Guangsheng Bao, Hongbo Zhang, Cunxiang Wang, Linyi Yang, and Yue Zhang. How likely do LLM s with C o T mimic human reasoning? In Owen Rambow, Leo Wanner, Marianna Apidianaki, Hend Al-Khalifa, Barbara Di Eugenio, and Steven Schockaert (eds.), Proceedings of the 31st International Conference on Computational Linguistics, pp.\ 7831--7850, Abu Dhabi, UAE, Jan...
2025
-
[4]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Igor Ostrovsky, Lev McKinney, Zach Furman, Logan Smith, Danny Halawi, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens, 2025. URL https://arxiv.org/abs/2303.08112
work page internal anchor Pith review arXiv 2025
-
[5]
Fundamental reasoning paradigms induce out-of-domain generalization in language models, 2026
Mingzi Cao, Xingwei Tan, Mahmud Elahi Akhter, Marco Valentino, Maria Liakata, Xi Wang, and Nikolaos Aletras. Fundamental reasoning paradigms induce out-of-domain generalization in language models, 2026. URL https://arxiv.org/abs/2602.08658
-
[6]
Reasoning models don’t always say what they think, 2025
Yanda Chen, Joe Benton, Ansh Radhakrishnan, Jonathan Uesato, John Schulman, Arushi Somani, Carson Denison, Peter Hase, Misha Wagner, Fabien Roger, and Vlad Mikuli. Reasoning models don’t always say what they think, 2025. URL https://www.anthropic.com/research/reasoning-models-dont-say-think
2025
-
[7]
Are deepseek r1 and other reasoning models more faithful?, 2025
James Chua and Owain Evans. Are deepseek r1 and other reasoning models more faithful?, 2025. URL https://arxiv.org/abs/2501.08156
-
[8]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021. URL https://arxiv.org/abs/2110.14168
work page internal anchor Pith review arXiv 2021
-
[9]
Executive functions
Adele Diamond. Executive functions. Annual Review of Psychology, 64: 0 135--168, 2013
2013
-
[10]
Assessing the reasoning capabilities of LLM s in the context of evidence-based claim verification
John Dougrez-Lewis, Mahmud Elahi Akhter, Federico Ruggeri, Sebastian L \"o bbers, Yulan He, and Maria Liakata. Assessing the reasoning capabilities of LLM s in the context of evidence-based claim verification. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar (eds.), Findings of the Association for Computational Linguistics: A...
-
[11]
Gemini 3 flash: frontier intelligence built for speed, 2025
Team Gemini. Gemini 3 flash: frontier intelligence built for speed, 2025. URL https://blog.google/products-and-platforms/products/gemini/gemini-3-flash/
2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
FOLIO : Natural Language Reasoning with First-Order Logic
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alexander Wardle-Solano, Hannah Szab \'o , Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander Fabbri, Wojciec...
-
[15]
Beyond'aha!': Toward systematic meta-abilities alignment in large reasoning models
Zhiyuan Hu, Yibo Wang, Hanze Dong, Yuhui Xu, Amrita Saha, Caiming Xiong, Bryan Hooi, and Junnan Li. Beyond'aha!': Toward systematic meta-abilities alignment in large reasoning models. arXiv preprint arXiv:2505.10554, 2025 b
-
[16]
Patch: Mitigating pii leakage in language models with privacy-aware targeted circuit patching
Anthony Hughes, Vasisht Duddu, N Asokan, Nikolaos Aletras, and Ning Ma. Patch: Mitigating pii leakage in language models with privacy-aware targeted circuit patching. arXiv preprint arXiv:2510.07452, 2025
-
[17]
Language Models (Mostly) Know What They Know
Saurav Kadavath et al. Language models (mostly) know what they know, 2022. URL https://arxiv.org/abs/2207.05221
work page internal anchor Pith review arXiv 2022
-
[18]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. In Advances in Neural Information Processing Systems, volume 35, pp.\ 22199--22213, 2022
2022
-
[19]
Gonzalez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. In Proceedings of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023
2023
-
[20]
Measuring Faithfulness in Chain-of-Thought Reasoning
Tamera Lanham, Anna Chen, Ansh Radhakrishnan, Benoit Steiner, Carson Denison, Danny Hernandez, Dustin Li, Esin Durmus, Evan Hubinger, Jackson Kernion, and 20 others. Measuring faithfulness in chain-of-thought reasoning, 2023. URL https://arxiv.org/abs/2307.13702
work page internal anchor Pith review arXiv 2023
-
[21]
Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar
Bruce W. Lee, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Erik Miehling, Pierre Dognin, Manish Nagireddy, and Amit Dhurandhar. Programming refusal with conditional activation steering. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=Oi47wc10sm
2025
-
[22]
Four aspects of strategic change: Contributions to children's learning of multiplication
Patrick Lemaire and Robert S Siegler. Four aspects of strategic change: Contributions to children's learning of multiplication. Journal of Experimental Psychology: General, 124 0 (1), 1995
1995
-
[23]
Samuel Lewis-Lim, Xingwei Tan, Zhixue Zhao, and Nikolaos Aletras. Analysing chain of thought dynamics: Active guidance or unfaithful post-hoc rationalisation? In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 29826--29841, S...
-
[24]
Evaluating the logical reasoning abilities of large reasoning models, 2025 a
Hanmeng Liu, Yiran Ding, Zhizhang Fu, Chaoli Zhang, Xiaozhang Liu, and Yue Zhang. Evaluating the logical reasoning abilities of large reasoning models, 2025 a . URL https://arxiv.org/abs/2505.11854
-
[25]
Logical reasoning in large language models: A survey, 2025 b
Hanmeng Liu, Zhizhang Fu, Mengru Ding, Ruoxi Ning, Chaoli Zhang, Xiaozhang Liu, and Yue Zhang. Logical reasoning in large language models: A survey, 2025 b . URL https://arxiv.org/abs/2502.09100
-
[26]
Progress measures for grokking via mechanistic interpretability
Neel Nanda, Lawrence Chan, Tom Lieberum, Jess Smith, and Jacob Steinhardt. Progress measures for grokking via mechanistic interpretability. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=9XFSbDPmdW
2023
-
[27]
Metamemory: A theoretical framework and new findings
Thomas O Nelson. Metamemory: A theoretical framework and new findings. Psychology of Learning and Motivation, 26: 0 125--173, 1990
1990
-
[28]
Team Olmo. Olmo 3, 2025. URL https://arxiv.org/abs/2512.13961
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Gpt-5 system card, 2025
OpenAI. Gpt-5 system card, 2025. URL https://cdn.openai.com/gpt-5-system-card.pdf
2025
-
[30]
Steering Llama 2 via Contrastive Activation Addition
Nina Rimsky, Nick Gabrieli, Julian Schulz, Meg Tong, Evan Hubinger, and Alexander Turner. Steering llama 2 via contrastive activation addition. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 15504--15522, Bangkok, Thailand, Augus...
-
[31]
Procedural knowledge in pretraining drives reasoning in large language models
Laura Ruis, Maximilian Mozes, Juhan Bae, Siddhartha Rao Kamalakara, Dwaraknath Gnaneshwar, Acyr Locatelli, Robert Kirk, Tim Rockt \"a schel, Edward Grefenstette, and Max Bartolo. Procedural knowledge in pretraining drives reasoning in large language models. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openrevie...
2025
-
[32]
Noah Siegel, Oana-Maria Camburu, Nicolas Heess, and Maria Perez-Ortiz. The probabilities also matter: A more faithful metric for faithfulness of free-text explanations in large language models. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar (eds.), Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short P...
-
[33]
To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning
Zayne Rea Sprague, Fangcong Yin, Juan Diego Rodriguez, Dongwei Jiang, Manya Wadhwa, Prasann Singhal, Xinyu Zhao, Xi Ye, Kyle Mahowald, and Greg Durrett. To cot or not to cot? chain-of-thought helps mainly on math and symbolic reasoning. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=w6nlcS8Kkn
2025
-
[34]
Improving instruction-following in language models through activation steering
Alessandro Stolfo, Vidhisha Balachandran, Safoora Yousefi, Eric Horvitz, and Besmira Nushi. Improving instruction-following in language models through activation steering. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=wozhdnRCtw
2025
-
[35]
Language models do not follow occam's razor: A benchmark for inductive and abductive reasoning, 2025
Yunxin Sun and Abulhair Saparov. Language models do not follow occam's razor: A benchmark for inductive and abductive reasoning, 2025. URL https://arxiv.org/abs/2509.03345
-
[36]
Miles Turpin, Julian Michael, Ethan Perez, and Samuel R. Bowman. Language models don't always say what they think: Unfaithful explanations in chain-of-thought prompting. In Thirty-seventh Conference on Neural Information Processing Systems, 2023. URL https://openreview.net/forum?id=bzs4uPLXvi
2023
-
[37]
Measuring faithfulness of chains of thought by unlearning reasoning steps, 2025
Martin Tutek, Fateme Hashemi Chaleshtori, Ana Marasović, and Yonatan Belinkov. Measuring faithfulness of chains of thought by unlearning reasoning steps, 2025. URL https://arxiv.org/abs/2502.14829
-
[38]
Marco Valentino, Geonhee Kim, Dhairya Dalal, Zhixue Zhao, and André Freitas. Mitigating content effects on reasoning in language models through fine-grained activation steering, 2026. URL https://arxiv.org/abs/2505.12189
-
[39]
Abductive, presumptive and plausible arguments
Douglas Walton. Abductive, presumptive and plausible arguments. Informal Logic, 21 0 (2), 2001
2001
-
[40]
Easyedit: An easy-to-use knowledge editing framework for large language models
Peng Wang, Ningyu Zhang, Xin Xie, Yunzhi Yao, Bozhong Tian, Mengru Wang, Zekun Xi, Siyuan Cheng, Kangwei Liu, Guozhou Zheng, et al. Easyedit: An easy-to-use knowledge editing framework for large language models. arXiv preprint arXiv:2308.07269, 2023
-
[41]
Chi, Quoc V Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho (eds.), Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=...
2022
-
[42]
Are large language models really good logical reasoners? a comprehensive evaluation and beyond
Fangzhi Xu, Qika Lin, Jiawei Han, Tianzhe Zhao, Jun Liu, and Erik Cambria. Are large language models really good logical reasoners? a comprehensive evaluation and beyond. IEEE Transactions on Knowledge and Data Engineering, 2025
2025
-
[43]
An Yang, Anfeng Li, et al. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[44]
A Comprehensive Study of Knowledge Editing for Large Language Models, November 2024
Ningyu Zhang, Yunzhi Yao, Bozhong Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, et al. A comprehensive study of knowledge editing for large language models. arXiv preprint arXiv:2401.01286, 2024
-
[45]
Abductive commonsense reasoning exploiting mutually exclusive explanations
Wenting Zhao, Justin Chiu, Claire Cardie, and Alexander Rush. Abductive commonsense reasoning exploiting mutually exclusive explanations. In Anna Rogers, Jordan Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp.\ 14883--14896, Toronto, Canada, July 20...
-
[46]
Xing, Hao Zhang, Joseph E
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. In Proceedings of the 37th International Conference on Neural Information Processing Systems, NIPS '23, Red Hook, NY, USA...
2023
-
[47]
Tianshi Zheng, Cheng Jiayang, Chunyang Li, Haochen Shi, Zihao Wang, Jiaxin Bai, Yangqiu Song, Ginny Wong, and Simon See. L ogi D ynamics: Unraveling the dynamics of inductive, abductive and deductive logical inferences in LLM reasoning. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Confer...
-
[48]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[49]
@esa (Ref
\@ifxundefined[1] #1\@undefined \@firstoftwo \@secondoftwo \@ifnum[1] #1 \@firstoftwo \@secondoftwo \@ifx[1] #1 \@firstoftwo \@secondoftwo [2] @ #1 \@temptokena #2 #1 @ \@temptokena \@ifclassloaded agu2001 natbib The agu2001 class already includes natbib coding, so you should not add it explicitly Type <Return> for now, but then later remove the command n...
-
[50]
\@lbibitem[] @bibitem@first@sw\@secondoftwo \@lbibitem[#1]#2 \@extra@b@citeb \@ifundefined br@#2\@extra@b@citeb \@namedef br@#2 \@nameuse br@#2\@extra@b@citeb \@ifundefined b@#2\@extra@b@citeb @num @parse #2 @tmp #1 NAT@b@open@#2 NAT@b@shut@#2 \@ifnum @merge>\@ne @bibitem@first@sw \@firstoftwo \@ifundefined NAT@b*@#2 \@firstoftwo @num @NAT@ctr \@secondoft...
-
[51]
@open @close @open @close and [1] URL: #1 \@ifundefined chapter * \@mkboth \@ifxundefined @sectionbib * \@mkboth * \@mkboth\@gobbletwo \@ifclassloaded amsart * \@ifclassloaded amsbook * \@ifxundefined @heading @heading NAT@ctr thebibliography [1] @ \@biblabel @NAT@ctr \@bibsetup #1 @NAT@ctr @ @openbib .11em \@plus.33em \@minus.07em 4000 4000 `\.\@m @bibit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.