When 2D Tasks Meet 1D Serialization: On Serialization Friction in Structured Tasks
Pith reviewed 2026-07-01 08:06 UTC · model grok-4.3
The pith
For layout-defined tasks, converting inputs to 1D text serialization is not a neutral representational choice.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that the same task instances of matrix transpose, Conway's Game of Life, and LU decomposition exhibit degraded performance and spatially structured errors when given as 1D text serialization rather than native 2D layout images, with the degradation sharpening as size grows, showing that 1D serialization is not neutral for layout-defined tasks.
What carries the argument
Serialization friction, the representational mismatch in which layout-dependent relations become implicit under 1D text presentation while the symbolic entries remain the same.
If this is right
- Performance under 1D serialization declines more rapidly than under 2D presentation as task size increases.
- Errors produced under 1D serialization exhibit spatially structured patterns.
- The input presentation choice remains consequential even when symbolic entries are identical across formats.
- Supplementary mixed-training analyses on transpose confirm differences between the two presentations.
Where Pith is reading between the lines
- Similar friction could affect other grid or spatial tasks that are routinely reduced to text sequences.
- Architectures with native 2D input handling might reduce the observed performance gap on these tasks.
- Prompt designs that explicitly encode spatial relations in text could serve as a mitigation strategy.
- Training mixtures that include more rendered 2D examples might improve reliability on layout-sensitive problems.
Load-bearing premise
The three synthetic tasks capture the essential properties of the broader class of layout-defined structured tasks whose relations depend on 2D position.
What would settle it
Equivalent performance and non-spatial error distributions between 1D text and 2D image presentations across the three tasks at larger scales would falsify the claim.
Figures









read the original abstract
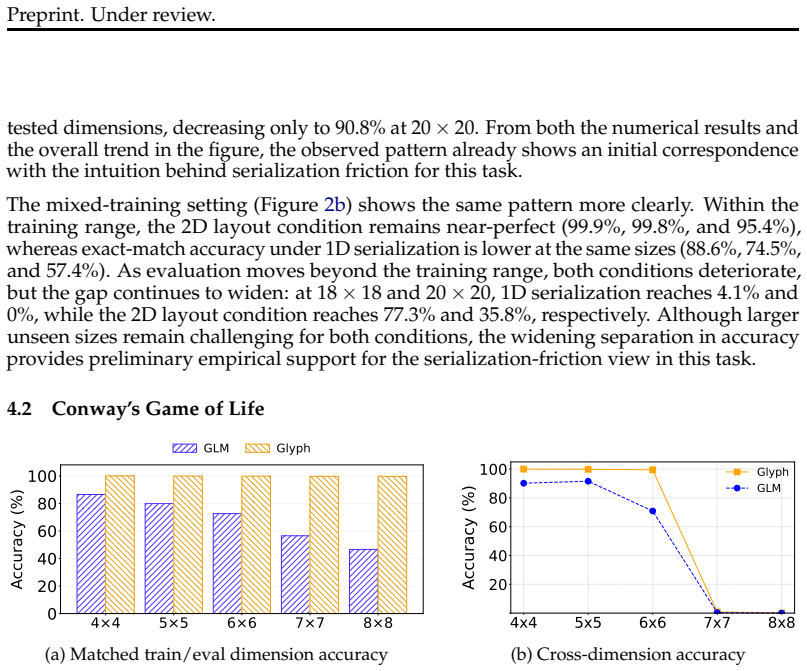
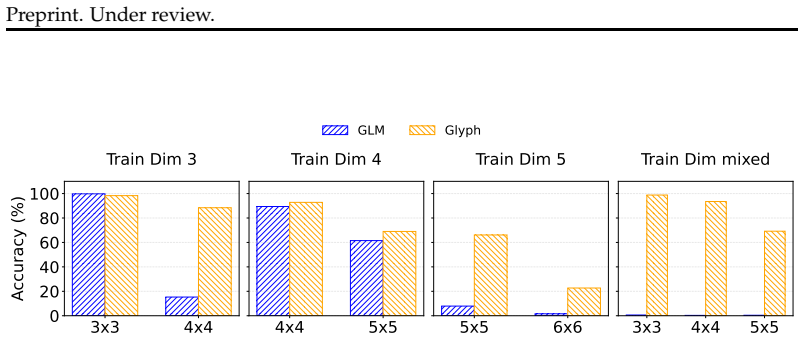
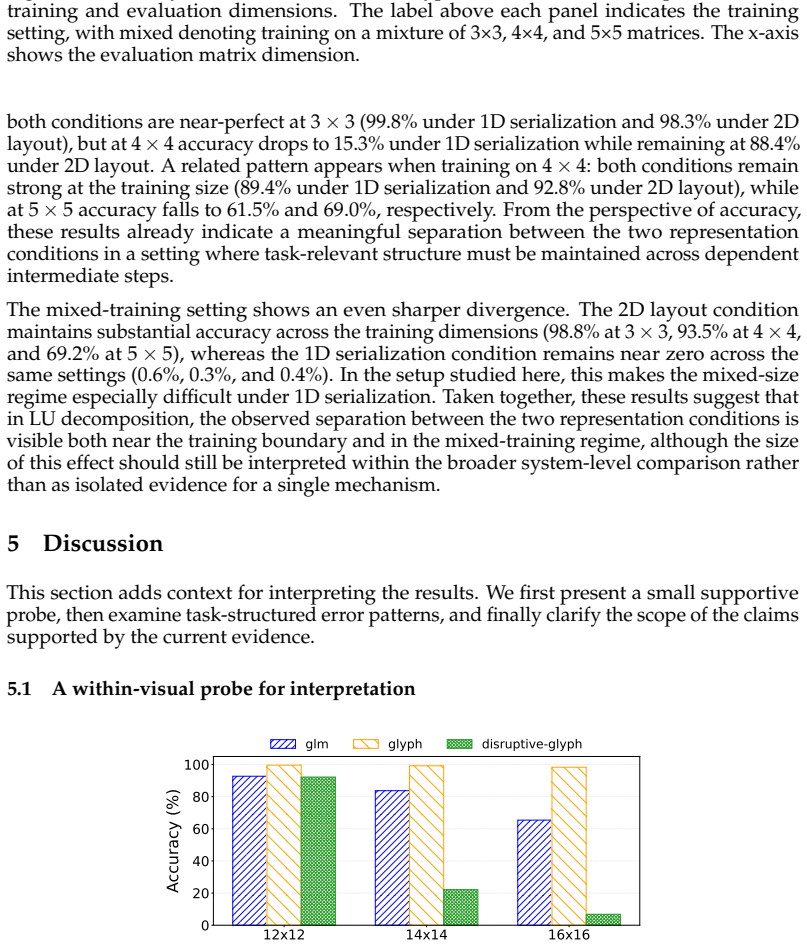
In the LLM era, many symbolic and structured problems are presented to models through 1D text serialization. Yet some such problems are natively two-dimensional: their relevant relations, such as row--column correspondence or spatial adjacency, are defined by position in a 2D layout rather than by sequential order. This raises a representational question: does preserving the same symbolic entries in a 1D sequence also preserve the relational structure needed for computation? We study this issue through the lens of serialization friction: the representational mismatch in which the same underlying task instances and entries are still present, but relations that depend on layout become implicit under 1D serialization. The study uses a controlled synthetic testbed of three tasks: matrix transpose, Conway's Game of Life, and LU decomposition. In each task, the same instances are presented either as 1D text serialization or as their native 2D layout rendered as an image. Across this testbed, 1D serialization degrades more sharply as task size grows, and errors under serialization exhibit spatially structured patterns, suggesting that this presentation choice is consequential within our testbed. To further interpret these results, we add supplementary analyses that include a within-visual probe and an additional comparison of the two input presentations under the mixed-training transpose setting. These findings suggest that, for layout-defined tasks, reducing inputs to 1D serialization is not a neutral choice of representation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that for tasks whose relations are defined by 2D layout rather than sequence (e.g., row-column correspondence or spatial adjacency), converting the same symbolic entries to 1D text serialization introduces representational mismatch ('serialization friction'). Using a synthetic testbed of matrix transpose, Conway's Game of Life, and LU decomposition, it reports that 1D presentation degrades more sharply with task size and produces spatially structured errors, while 2D image presentation does not; supplementary probes include within-visual analysis and mixed-training transpose comparisons. The headline conclusion is that 1D serialization is not a neutral choice for layout-defined tasks.
Significance. If the reported patterns hold, the work would demonstrate that input representation is consequential for structured symbolic tasks in LLMs and would motivate layout-preserving or multimodal input strategies. The controlled synthetic testbed that holds task instances fixed while varying only the serialization format is a methodological strength that isolates the variable of interest.
major comments (2)
- [Abstract] Abstract: the claim that the three tasks adequately sample the broader class of layout-defined tasks lacks any selection rationale or scope argument; matrix transpose, Game of Life, and LU decomposition are all grid- or matrix-structured with local/algebraic dependencies, yet no discussion addresses whether degradation patterns would recur for non-grid spatial graphs or hierarchical layouts.
- [Abstract] Abstract: no model details, quantitative results, error bars, statistical tests, or exclusion criteria are supplied, so the central empirical claim (sharper degradation and spatially structured errors under 1D serialization) cannot be evaluated.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our abstract. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the three tasks adequately sample the broader class of layout-defined tasks lacks any selection rationale or scope argument; matrix transpose, Game of Life, and LU decomposition are all grid- or matrix-structured with local/algebraic dependencies, yet no discussion addresses whether degradation patterns would recur for non-grid spatial graphs or hierarchical layouts.
Authors: The abstract does not claim that the three tasks 'adequately sample the broader class of layout-defined tasks.' It describes them as 'a controlled synthetic testbed of three tasks' chosen to study serialization friction where relations depend on 2D layout. We selected these tasks because each features explicit layout-defined relations (row-column correspondence, spatial adjacency, and matrix algebraic dependencies). We agree that adding an explicit rationale for task selection and a discussion of scope limitations, including whether patterns extend to non-grid spatial graphs or hierarchical layouts, would improve the paper and will incorporate this in the revised manuscript. revision: partial
-
Referee: [Abstract] Abstract: no model details, quantitative results, error bars, statistical tests, or exclusion criteria are supplied, so the central empirical claim (sharper degradation and spatially structured errors under 1D serialization) cannot be evaluated.
Authors: Abstracts are concise summaries and conventionally omit detailed methodology, results, and statistics, which are presented in the full manuscript. The provided abstract therefore does not contain these elements. We will revise the abstract to include a brief statement of key quantitative findings to make the central claims more evaluable from the abstract. revision: yes
- Specific model details, quantitative results with error bars, statistical tests, and exclusion criteria, as only the abstract (not the full manuscript) was available for this response.
Circularity Check
No circularity: purely empirical comparison with no derivation chain
full rationale
The paper reports an empirical testbed on three synthetic tasks (matrix transpose, Conway's Game of Life, LU decomposition) comparing 1D serialization vs. native 2D image input. No equations, fitted parameters, uniqueness theorems, or self-citations are invoked in the abstract or described methodology. The central claim—that 1D serialization is not neutral for layout-defined tasks—is advanced solely via observed performance degradation and error patterns, which are external to any definitional reduction. This is a standard empirical design with no load-bearing step that collapses to its own inputs by construction.
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.