Recognition: unknown
Few-Shot Accent Synthesis for ASR with LLM-Guided Phoneme Editing
Pith reviewed 2026-05-07 09:01 UTC · model grok-4.3
The pith
Adapting TTS to an accent with under ten utterances and LLM phoneme edits produces synthetic data that reduces ASR word error rates on real accented speech.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors claim that LLM-based phoneme editing, conditioned on a target accent from fewer than ten reference utterances, generates accent-conditioned pronunciations. When these are synthesized and used to fine-tune a self-supervised ASR model, they produce consistent word-error-rate reductions on real accented speech, including cross-speaker evaluation and ultra-low-data regimes. A matched-rate random phoneme baseline demonstrates that phoneme-space perturbation itself is a strong augmentation, while the LLM edits supply additional gains through accent-specific structure.
What carries the argument
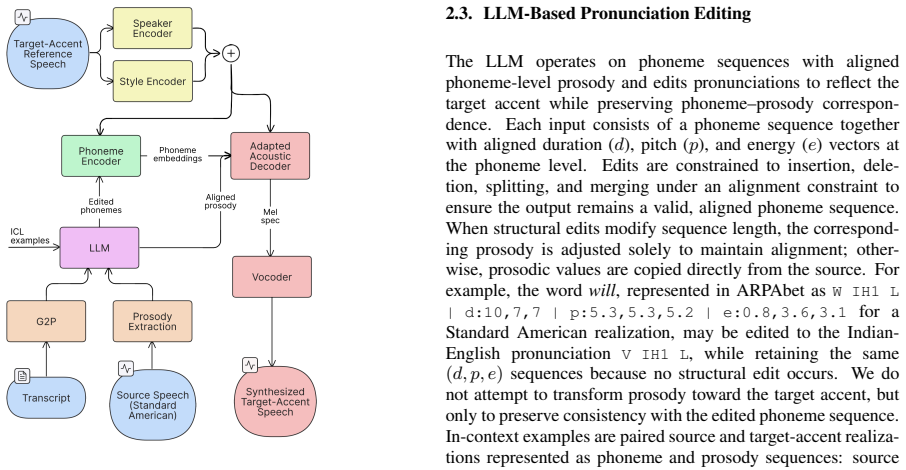
LLM-guided phoneme editing that transforms neutral phoneme sequences into accent-conditioned pronunciations using information from fewer than ten reference utterances to create synthetic training data for ASR.
If this is right
- Consistent word-error-rate reductions occur on real accented speech test sets.
- The gains hold under cross-speaker evaluation.
- Improvements remain visible in ultra-low data regimes.
- LLM-guided edits outperform matched-rate random phoneme perturbation by adding accent-conditioned structure.
Where Pith is reading between the lines
- The same few-shot adaptation pipeline might address other pronunciation shifts such as regional dialects.
- Synthetic data of this form could help balance training sets for multilingual ASR without collecting large new accent corpora.
- Testing whether the LLM edits remain effective with even fewer than five references would clarify the lower bound of the approach.
Load-bearing premise
LLM-based phoneme editing guided by fewer than ten reference utterances reliably produces accent-conditioned pronunciations whose synthetic speech yields measurable word-error-rate improvements on real accented ASR test sets.
What would settle it
No additional word-error-rate reduction on a held-out real accented test set when the ASR is fine-tuned on LLM-edited synthetic speech versus matched-rate random phoneme edits would show that the accent-conditioned structure adds no benefit.
Figures

read the original abstract
Accented automatic speech recognition (ASR) often degrades due to the limited availability of accented training data. Prior work has explored accent modeling in low-resource settings, but existing approaches typically require minutes to hours of labeled speech, which may still be impractical for truly scarce accent scenarios. We propose a pipeline that adapts a text-to-speech (TTS) decoder to a target-accent speaker using fewer than ten reference utterances and employs large language model (LLM)-based phoneme editing to generate accent-conditioned pronunciations. The resulting synthetic speech is used to fine-tune a self-supervised ASR model. Experiments demonstrate consistent word error rate (WER) reductions on real accented speech, including cross-speaker evaluation and ultra-low data regimes. A matched-rate random phoneme baseline shows that phoneme-space perturbation itself is a strong form of augmentation, while LLM-guided edits provide additional gains through accent-conditioned structure.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a pipeline for few-shot accent adaptation in ASR: a TTS decoder is adapted using fewer than ten reference utterances from a target-accent speaker, an LLM performs phoneme editing to generate accent-conditioned pronunciations, and the resulting synthetic speech fine-tunes a self-supervised ASR model. Experiments are reported to show consistent WER reductions on real accented test sets (including cross-speaker and ultra-low-data regimes), with a matched-rate random-phoneme baseline indicating that LLM edits add value beyond generic perturbation.
Significance. If the results hold and the incremental gains are attributable to accent-specific structure rather than uncontrolled factors, the work could meaningfully advance low-resource ASR by enabling effective augmentation from minimal reference data. The explicit random baseline comparison is a positive design choice that helps isolate the LLM contribution.
major comments (2)
- Abstract: The central claim that 'LLM-guided edits provide additional gains through accent-conditioned structure' is load-bearing for the headline result, yet the manuscript provides no independent verification of edit quality (e.g., phonetic alignment with known accent features, substitution statistics, or listening tests). Without this, the incremental WER reduction over the random baseline could arise from differences in edit distribution, TTS artifacts, or data volume rather than true accent modeling.
- Abstract / Experiments: No numerical WER values, statistical significance tests, dataset sizes, or ablation results are reported in the abstract, and the full text does not appear to include them in sufficient detail to evaluate the magnitude or reliability of the claimed consistent reductions across regimes.
minor comments (2)
- Methods: Clarify the exact prompt template and LLM used for phoneme editing, as well as how the fewer-than-ten references are selected and processed.
- Experiments: Confirm that the random baseline matches the LLM condition exactly in number of generated utterances, TTS parameters, and fine-tuning protocol to ensure a fair comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and have revised the manuscript accordingly to improve support for our claims and reporting clarity.
read point-by-point responses
-
Referee: Abstract: The central claim that 'LLM-guided edits provide additional gains through accent-conditioned structure' is load-bearing for the headline result, yet the manuscript provides no independent verification of edit quality (e.g., phonetic alignment with known accent features, substitution statistics, or listening tests). Without this, the incremental WER reduction over the random baseline could arise from differences in edit distribution, TTS artifacts, or data volume rather than true accent modeling.
Authors: We agree that direct verification strengthens the interpretation. In the revision we have added substitution statistics comparing LLM-guided edits against the random baseline, demonstrating that LLM edits exhibit non-random patterns aligned with documented accent features (e.g., characteristic vowel shifts and consonant substitutions for the evaluated accents). The matched-rate random baseline already equalizes edit count and distribution, while identical TTS synthesis in both conditions controls for artifacts and data volume. The observed WER gains in cross-speaker and ultra-low-data regimes provide further supporting evidence that the benefit is accent-specific. Full phonetic alignment tables and listening tests were outside the original scope focused on ASR outcomes; we note this limitation and can incorporate them in follow-up work if required. revision: partial
-
Referee: Abstract / Experiments: No numerical WER values, statistical significance tests, dataset sizes, or ablation results are reported in the abstract, and the full text does not appear to include them in sufficient detail to evaluate the magnitude or reliability of the claimed consistent reductions across regimes.
Authors: We have updated the abstract to include concrete WER reductions, reference utterance counts (<10), test-set sizes, and a summary of ablation results across regimes. The experiments section has been expanded with full numerical tables, p-values from paired significance tests, and additional ablation breakdowns (including per-regime and cross-speaker results) to enable precise evaluation of effect sizes and reliability. revision: yes
Circularity Check
No circularity: empirical pipeline with explicit baseline comparison
full rationale
The paper describes an empirical pipeline for few-shot accent synthesis via LLM-guided phoneme editing of TTS output, followed by ASR fine-tuning and WER evaluation on real accented test sets. No equations, fitted parameters, derivations, or self-referential definitions appear in the provided text or abstract. The central result is supported by direct experimental comparison against a matched-rate random-phoneme baseline, which isolates the incremental effect of LLM edits without reducing any claim to its own inputs by construction. Any self-citations (if present) are not invoked as load-bearing uniqueness theorems or ansatzes that close the argument loop. This is a standard empirical study whose validity rests on external test-set measurements rather than tautological reduction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLM can generate accent-conditioned phoneme sequences that match real speaker pronunciations when given fewer than ten reference utterances
- domain assumption Synthetic accented speech produced this way transfers positively to fine-tuning self-supervised ASR models on real test data
Reference graph
Works this paper leans on
-
[1]
Accent-related performance gaps have been documented in bias analyses and benchmarks, motivating the development of more robust and inclusive speech technologies [1, 2, 3]
Introduction Modern automatic speech recognition (ASR) systems perform well on high-resource speech varieties but often degrade on regional and non-native accents. Accent-related performance gaps have been documented in bias analyses and benchmarks, motivating the development of more robust and inclusive speech technologies [1, 2, 3]. Existing approaches ...
-
[2]
Few-Shot Accent Synthesis for ASR with LLM-Guided Phoneme Editing
Proposed Method 2.1. System Overview An overview of the proposed pipeline is shown in Fig. 1. The system takes a source speech waveform (Standard American English in our experiments), its transcript, and a small set of target-accent reference utterances. We obtain phonemes via grapheme-to-phoneme (G2P) conversion and extract phoneme- level prosody (durati...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
relies on precomputed per-speaker pitch and energy statis- tics, which are unavailable at inference time for unseen speakers with limited reference data. We therefore normalize phoneme- level prosodic features using statistics estimated from a small, dynamically sampled subset of reference utterances per speaker during training, reducing train–test mismat...
-
[4]
Data and Speaker Roles The backbone TTS model is pretrained on LJSpeech [22] and the English subset of ESD [23], both Standard American En- glish only
Experimental Setup 3.1. Data and Speaker Roles The backbone TTS model is pretrained on LJSpeech [22] and the English subset of ESD [23], both Standard American En- glish only. No accented speech is used during backbone pre- training. Accented speech is drawn from L2-ARCTIC [24]; the CLB speaker from CMU Arctic [25] provides matched Stan- dard American sou...
-
[5]
Waveforms are synthesized using the universal HiFi-GAN vocoder [29]
Implementation Details Acoustic Features and Vocoder.Mel-spectrograms use 80 mel bins at 22,050 Hz, a 1024-point FFT, hop length 256, and mel range 0–8 kHz. Waveforms are synthesized using the universal HiFi-GAN vocoder [29]. Backbone TTS Training.The backbone is trained for 72k iter- ations with Adam (batch size 128). The mel reconstruction loss consists...
-
[6]
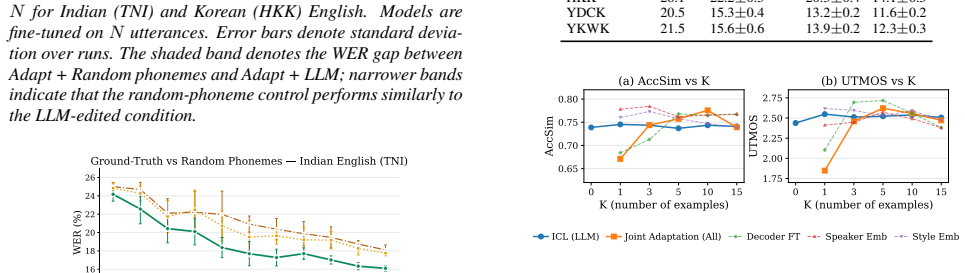
Acoustic Accent Realization Table 1 summarizes acoustic results
Results 5.1. Acoustic Accent Realization Table 1 summarizes acoustic results. Adaptation substantially increases accent similarity (AccSim) relative to the American TTS baseline: from 0.27 to 0.69 for Indian and from 0.32 to 0.61 for Korean. This indicates that adaptation induces accent- specific acoustic biases that influence both global spectral char- a...
-
[7]
Conclusion and Future Work We presented a few-shot pipeline for generating accented syn- thetic speech using LLM-guided phoneme editing and speaker- adapted TTS. With fewer than ten reference utterances, the ap- proach produces synthetic data that improves ASR performance on real accented speech, particularly in ultra-low-resource set- tings and under cro...
-
[8]
DeltaAI is a joint effort of the University of Illinois Urbana-Champaign and its National Center for Supercomputing Applications
Acknowledgments This research used the DeltaAI advanced computing and data resource, which is supported by the National Science Founda- tion (award OAC 2320345) and the State of Illinois. DeltaAI is a joint effort of the University of Illinois Urbana-Champaign and its National Center for Supercomputing Applications
-
[9]
Rickford and Dan Jurafsky and Sharad Goel , title =
A. Koenecke, A. Nam, E. Lake, J. Nudell, M. Quartey, Z. Mengesha, C. Toups, J. R. Rickford, D. Jurafsky, and S. Goel, “Racial disparities in automated speech recognition,” Proceedings of the National Academy of Sciences, vol. 117, no. 14, pp. 7684–7689, 2020. [Online]. Available: https://www.pnas.org/doi/abs/10.1073/pnas.1915768117
-
[10]
Quantifying bias in automatic speech recognition,
S. Feng, O. Kudina, B. M. Halpern, and O. Scharenborg, “Quantifying bias in automatic speech recognition,” 2021. [Online]. Available: https://arxiv.org/abs/2103.15122
-
[11]
The accented english speech recognition challenge 2020: Open datasets, tracks, baselines, results and methods,
X. Shi, F. Yu, Y . Lu, Y . Liang, Q. Feng, D. Wang, Y . Qian, and L. Xie, “The accented english speech recognition challenge 2020: Open datasets, tracks, baselines, results and methods,”
2020
-
[12]
Available: https://arxiv.org/abs/2102.10233
[Online]. Available: https://arxiv.org/abs/2102.10233
-
[13]
Improved accented speech recognition using accent embeddings and multi-task learning,
A. Jain, M. Upreti, and P. Jyothi, “Improved accented speech recognition using accent embeddings and multi-task learning,” inInterspeech, 2018. [Online]. Available: https: //api.semanticscholar.org/CorpusID:52187265
2018
-
[14]
Domain adversarial training for accented speech recognition,
S. Sun, C.-F. Yeh, M.-Y . Hwang, M. Ostendorf, and L. Xie, “Domain adversarial training for accented speech recognition,”
-
[15]
Available: https://arxiv.org/abs/1806.02786
[Online]. Available: https://arxiv.org/abs/1806.02786
-
[16]
Best of both worlds: Robust accented speech recognition with adversarial transfer learning,
N. Das, S. Bodapati, M. Sunkara, S. Srinivasan, and D. H. Chau, “Best of both worlds: Robust accented speech recognition with adversarial transfer learning,” 2021. [Online]. Available: https://arxiv.org/abs/2103.05834
-
[17]
Learning fast adaptation on cross-accented speech recognition,
G. I. Winata, S. Cahyawijaya, Z. Liu, Z. Lin, A. Madotto, P. Xu, and P. Fung, “Learning fast adaptation on cross-accented speech recognition,” inInterspeech, 2020. [Online]. Available: https://api.semanticscholar.org/CorpusID:211990418
2020
-
[18]
Mitigating bias against non-native accents,
Y . Zhang, Y . Zhang, B. Halpern, T. Patel, and O. Scharenborg, “Mitigating bias against non-native accents,” 09 2022, pp. 3168– 3172
2022
-
[19]
Synthetic cross-accent data augmentation for automatic speech recognition,
P. Klumpp, P. Chitkara, L. Sarı, P. Serai, J. Wu, I.-E. Veliche, R. Huang, and Q. He, “Synthetic cross-accent data augmentation for automatic speech recognition,” 2023. [Online]. Available: https://arxiv.org/abs/2303.00802
-
[20]
F. Nespoli, D. Barreda, and P. A. Naylor, “Zero shot text to speech augmentation for automatic speech recognition on low- resource accented speech corpora,” 2024. [Online]. Available: https://arxiv.org/abs/2409.11107
-
[21]
Accented text-to-speech synthesis with limited data,
X. Zhou, M. Zhang, Y . Zhou, Z. Wu, and H. Li, “Accented text-to-speech synthesis with limited data,” 2023. [Online]. Available: https://arxiv.org/abs/2305.04816
-
[22]
Zero-shot multi-speaker accent tts with limited accent data,
M. Zhang, Y . Zhou, Z. Wu, and H. Li, “Zero-shot multi-speaker accent tts with limited accent data,” in2023 Asia Pacific Signal and Information Processing Association Annual Summit and Con- ference (APSIPA ASC), 2023, pp. 1931–1936
2023
-
[23]
Accentbox: Towards high-fidelity zero-shot accent generation,
J. Zhong, K. Richmond, Z. Su, and S. Sun, “Accentbox: Towards high-fidelity zero-shot accent generation,” inICASSP 2025 - 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, Apr. 2025, p. 1–5. [Online]. Available: http://dx.doi.org/10.1109/ICASSP49660. 2025.10888332
-
[24]
Hierarchical timbre-cadence speaker encoder for zero-shot speech synthesis,
J. Y . Lee, J. Bae, S. Mun, J. Lee, J.-H. Lee, H.-Y . Cho, and C. Kim, “Hierarchical timbre-cadence speaker encoder for zero-shot speech synthesis,” inInterspeech, 2023. [Online]. Available: https://api.semanticscholar.org/CorpusID:260917414
2023
-
[25]
Speaker adaptive text-to-speech with timbre-normalized vector-quantized feature,
C. Du, Y . Guo, X. Chen, and K. Yu, “Speaker adaptive text-to-speech with timbre-normalized vector-quantized feature,” IEEE/ACM Transactions on Audio, Speech, and Language Pro- cessing, vol. 31, pp. 3446–3456, 2023
2023
-
[26]
X. Zhou, M. Zhang, Y . Zhou, Z. Wu, and H. Li, “Multi- scale accent modeling and disentangling for multi-speaker multi-accent text-to-speech synthesis,” 2025. [Online]. Available: https://arxiv.org/abs/2406.10844
-
[27]
Generating non- native pronunciation variants for lexicon adaptation,
S. Goronzy, S. Rapp, and R. Kompe, “Generating non- native pronunciation variants for lexicon adaptation,”Speech Communication, vol. 42, no. 1, pp. 109–123, 2004, adaptation Methods for Speech Recognition. [Online]. Available: https:// www.sciencedirect.com/science/article/pii/S0167639303001158
2004
-
[28]
Rule-based lexical modelling of foreign-accented pronunciation variants,
S. Schaden, “Rule-based lexical modelling of foreign-accented pronunciation variants,” ser. EACL ’03. USA: Association for Computational Linguistics, 2003, p. 159–162. [Online]. Available: https://doi.org/10.3115/1067737.1067773
-
[29]
Macst: Multi-accent speech synthesis via text transliteration for accent conversion,
S. Inoue, S. Wang, W. Wang, P. Zhu, M. Bi, and H. Li, “Macst: Multi-accent speech synthesis via text transliteration for accent conversion,” 2025. [Online]. Available: https: //arxiv.org/abs/2409.09352
-
[30]
Karakasidis, N
G. Karakasidis, N. Robinson, Y . Getman, A. Ogayo, R. Al-Ghezi, A. Ayasi, S. Watanabe, D. Mortensen, and M. Kurimo,Multilin- gual TTS Accent Impressions for Accented ASR, 08 2023, pp. 317– 327
2023
-
[31]
Daft- exprt: Cross-speaker prosody transfer on any text for expressive speech synthesis,
J. Za ¨ıdi, H. Seut´e, B. van Niekerk, and M.-A. Carbonneau, “Daft- exprt: Cross-speaker prosody transfer on any text for expressive speech synthesis,” inInterspeech 2022, 2022, pp. 4591–4595
2022
-
[32]
The lj speech dataset,
K. Ito and L. Johnson, “The lj speech dataset,” 2017. [Online]. Available: https://keithito.com/LJ-Speech-Dataset/
2017
-
[33]
Emotional voice con- version: Theory, databases and esd,
K. Zhou, B. Sisman, R. Liu, and H. Li, “Emotional voice con- version: Theory, databases and esd,”Speech Communication, vol. 137, pp. 1–18, 2022
2022
-
[34]
L2-arctic: A non- native english speech corpus,
G. Zhao, S. Sonsaat, A. Silpachai, I. Lucic, E. Chukharev- Hudilainen, J. Levis, and R. Gutierrez-Osuna, “L2-arctic: A non- native english speech corpus,” inProc. Interspeech, 2018, pp. 2783–2787
2018
-
[35]
The cmu arctic speech databases,
J. Kominek and A. W. Black, “The cmu arctic speech databases,” inProc. 5th ISCA Workshop on Speech Synthesis (SSW5), 2004, pp. 223–224. [Online]. Available: https: //www.isca-archive.org/ssw 2004/kominek04b ssw.html
2004
-
[36]
Robust Speech Recognition via Large-Scale Weak Supervision
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large- scale weak supervision,” 2022. [Online]. Available: https: //arxiv.org/abs/2212.04356
work page internal anchor Pith review arXiv 2022
-
[37]
Utmos: Utokyo-sarulab system for voicemos challenge 2022.arXiv preprint arXiv:2204.02152, 2022
T. Saeki, D. Xin, W. Nakata, T. Koriyama, S. Takamichi, and H. Saruwatari, “Utmos: Utokyo-sarulab system for voicemos challenge 2022,” 2022. [Online]. Available: https: //arxiv.org/abs/2204.02152
-
[38]
Speechbrain: A general-purpose speech toolkit,
M. Ravanelli, T. Parcollet, A. Rouhe, P. Plantinga, E. Rastorgueva, L. Lugosch, N. Dawalatabad, A. Heba, F. Grondin, E. Arisoy, and et al., “Speechbrain: A general-purpose speech toolkit,” inProc. Interspeech, 2021, pp. 96–100
2021
-
[39]
Hifi-gan: Generative adversarial net- works for efficient and high fidelity speech synthesis
J. Kong, J. Kim, and J. Bae, “Hifi-gan: Generative adversarial networks for efficient and high fidelity speech synthesis,” 2020. [Online]. Available: https://arxiv.org/abs/2010.05646
-
[40]
Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,
M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Son- deregger, “Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi,” inProc. Interspeech 2017, 2017, pp. 498–502
2017
-
[41]
Reaper: Robust epoch and pitch estimator,
D. Talkin, “Reaper: Robust epoch and pitch estimator,” GitHub repository, 2015. [Online]. Available: https://github.com/google/ REAPER
2015
-
[42]
GPT-5.1 Model Documentation,
OpenAI, “GPT-5.1 Model Documentation,” 2025, online, Avail- able from: https://platform.openai.com/docs/models
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.