Recognition: unknown
Predicting Upcoming Stuttering Events from Three-Second Audio: Stratified Evaluation Reveals Severity-Selective Precursors, and the Model Deploys Fully On-Device
Pith reviewed 2026-05-07 08:25 UTC · model grok-4.3
The pith
A compact audio model predicts upcoming severe stuttering events from the prior three seconds but performs at chance for mild ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
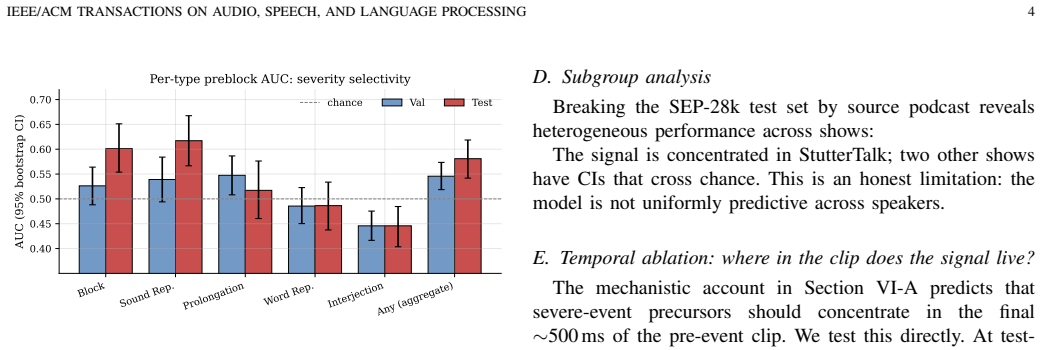
A 616K-parameter CNN trained to predict the presence of any disfluency in the next three-second clip achieves an aggregate AUC of 0.581 on episode-grouped test data, but stratification by event type shows AUC 0.601 for blocks and 0.617 for sound repetitions while fillers and word repetitions remain at chance; the model therefore functions as a severity-selective precursor detector because severe events carry detectable prosodic signals that mild events lack.
What carries the argument
Stratified AUC evaluation by upcoming disfluency type on episode-grouped splits, which isolates the model's detection of prosodic precursors that are present only before clinically severe events.
If this is right
- Severe stuttering events such as blocks and sound repetitions are preceded by audible prosodic changes that a CNN can exploit for prediction three seconds in advance.
- Mild disfluencies such as fillers and word repetitions lack consistent acoustic precursors and therefore cannot be predicted above chance with this approach.
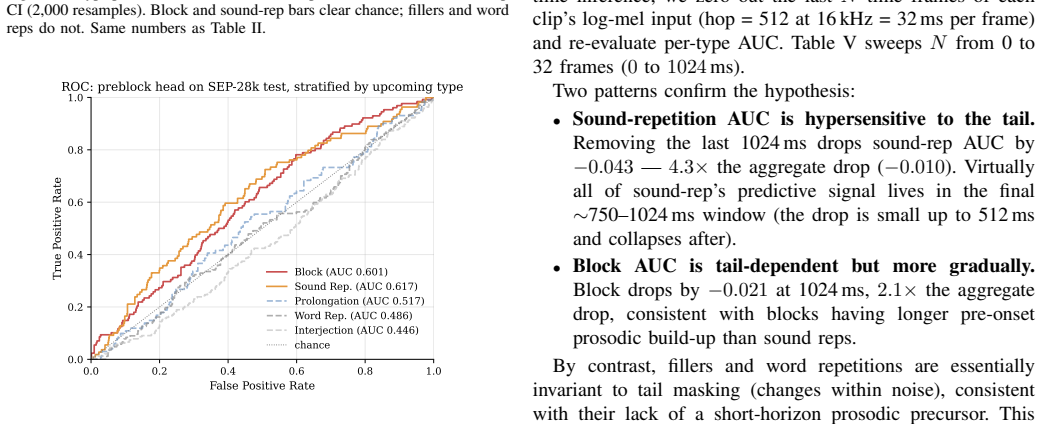
- The identical model checkpoint transfers to unseen populations including pediatric speakers and other stuttering corpora without any fine-tuning.
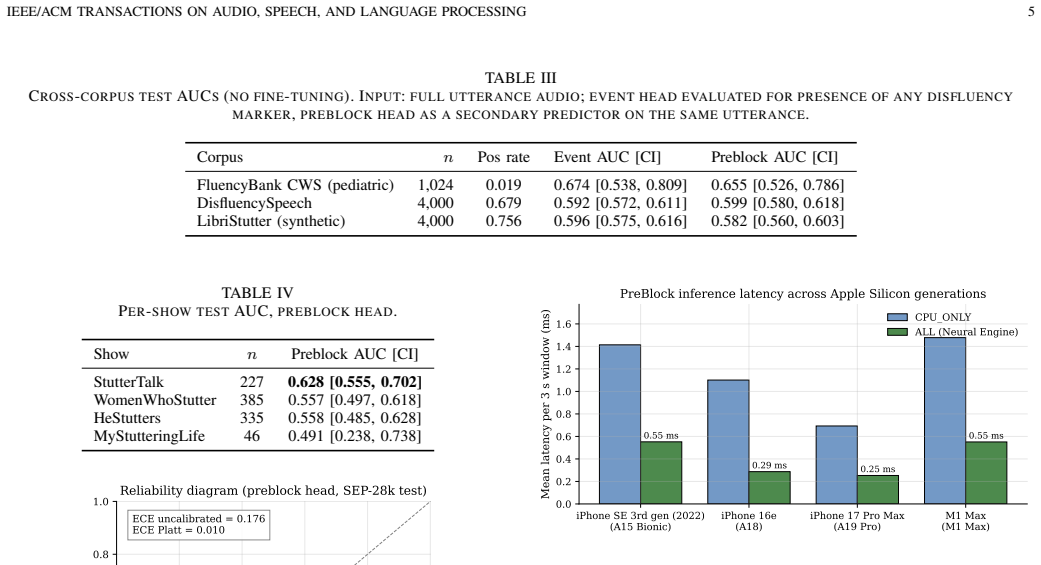
- The trained network compresses to under 2 MB and executes with 0.25-0.55 ms latency per three-second window on current mobile hardware.
Where Pith is reading between the lines
- Real-time closed-loop devices could prioritize alerts or interventions for blocks and repetitions while ignoring fillers that carry no predictive signal.
- The on-device footprint enables continuous monitoring on consumer phones without sending audio to servers.
- Future experiments could test whether hand-crafted prosodic features alone recover the same severity selectivity or whether the full waveform is required.
- Cross-dataset transfer suggests that certain acoustic markers of severe stuttering are shared across adult and child speakers.
Load-bearing premise
The human disfluency labels together with the episode-grouped train-test split produce a clean separation that prevents speaker-specific or episode-specific patterns from leaking into the performance gap between severe and mild event types.
What would settle it
Construct a new test set that randomly mixes severe and mild events across speakers and episodes without preserving episode grouping, then retrain and evaluate; if the AUC advantage for blocks and sound repetitions disappears, the claim of genuine severity-selective precursors is falsified.
Figures

read the original abstract
Audio-based stuttering systems to date have been trained for detection -- what disfluency is present now -- leaving prediction, the capability needed for closed-loop intervention, unstudied at deployable scale. We train a 616K-parameter CNN on SEP-28k (Apple, 20,131 three-second clips) to predict whether the next contiguous clip contains any disfluency. (1) Severity-selective precursor signal: on the episode-grouped test set, aggregate preblock AUC is modest (0.581 [0.542, 0.619]), but stratifying by upcoming event type reveals concentration on clinically severe events -- blocks 0.601 [0.554, 0.651] and sound repetitions 0.617 [0.567, 0.667] both exclude chance, while fillers (0.45) and word repetitions (0.49) are at chance. The aggregate objective converges to a severity-selective predictor because severe events carry prosodic precursors; fillers do not. (2) Cross-population transfer: without fine-tuning, the same checkpoint applied to 1,024 pediatric Children-Who-Stutter utterances (FluencyBank Teaching) attains AUC 0.674 detection and 0.655 prediction; DisfluencySpeech and LibriStutter reach 0.58-0.60 AUC. (3) Deployable on-device: lossless export to CoreML (1.19 MB), ONNX (40 KB), TFLite. Neural-Engine latency per 3 s window: 0.25 ms (iPhone 17 Pro Max, A19 Pro) to 0.55 ms (iPhone SE 3rd-gen and M1 Max). A 4 Hz streaming simulation uses 0.54% of the real-time budget. Platt-calibrated outputs (test ECE 0.010, from 0.177 raw). Five negative ablations -- output-level Future-Guided Learning, multi-clip GRU, time-axis concatenation, asymmetric focal loss, direct block-targeted training -- none improved over the vanilla baseline.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript trains a 616K-parameter CNN on SEP-28k (20,131 three-second clips) to predict whether the next contiguous clip contains any disfluency. On an episode-grouped test set it reports aggregate pre-block AUC of 0.581 [0.542, 0.619], with stratified results showing AUC 0.601 [0.554, 0.651] for blocks and 0.617 [0.567, 0.667] for sound repetitions (both above chance) while fillers and word repetitions remain at chance (0.45 and 0.49). It further shows cross-dataset transfer (AUC 0.655 prediction on FluencyBank pediatric data) and lossless export to CoreML/ONNX/TFLite with sub-millisecond Neural Engine latency and five negative ablations that did not improve the vanilla baseline.
Significance. If the stratified performance differences are robust, the work supplies evidence that prosodic precursors are present selectively before clinically severe stuttering events, which could support targeted closed-loop interventions. The small model footprint, demonstrated on-device deployment (0.25–0.55 ms latency, 0.54 % real-time budget), Platt calibration, and negative ablations are practical strengths. Cross-population results on pediatric data add modest generalization support.
major comments (1)
- [Evaluation (episode-grouped test set)] § Evaluation (episode-grouped test set and stratified AUCs): The central claim that aggregate AUC is modest but rises selectively for blocks and sound repetitions (while falling to chance for fillers/word repetitions) rests on the assumption that the episode-grouped split produces statistically independent samples with no speaker-level leakage. The manuscript does not report speaker overlap statistics, episode-to-speaker mapping, or a speaker-stratified ablation. If any speaker contributes episodes to both train and test partitions, the CNN could learn speaker-specific acoustic or rate priors that correlate with the severity distribution of disfluency types, rendering the observed AUC gap an artifact rather than evidence of genuine precursors. A concrete test (speaker-disjoint split or speaker-level AUC breakdown) is required to support the severity-selective interpretation.
minor comments (3)
- [Abstract] Abstract and Results: Cross-dataset AUCs (FluencyBank, DisfluencySpeech, LibriStutter) are given as point estimates without confidence intervals, unlike the main SEP-28k results; adding intervals would allow direct comparison of precision.
- [Methods] Methods: The description of how human-provided disfluency labels were obtained and any inter-rater agreement statistics is not detailed; label noise could differentially affect mild versus severe event strata and should be quantified.
- [Deployment] Deployment section: The 4 Hz streaming simulation reports 0.54 % of real-time budget, but the exact hardware configuration and power draw for the TFLite/ONNX exports are not tabulated; a small table would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The concern about potential speaker leakage in the episode-grouped evaluation is a substantive point that directly affects the interpretation of our severity-selective results. We address it below and will revise the manuscript to incorporate the requested analyses.
read point-by-point responses
-
Referee: [Evaluation (episode-grouped test set)] § Evaluation (episode-grouped test set and stratified AUCs): The central claim that aggregate AUC is modest but rises selectively for blocks and sound repetitions (while falling to chance for fillers/word repetitions) rests on the assumption that the episode-grouped split produces statistically independent samples with no speaker-level leakage. The manuscript does not report speaker overlap statistics, episode-to-speaker mapping, or a speaker-stratified ablation. If any speaker contributes episodes to both train and test partitions, the CNN could learn speaker-specific acoustic or rate priors that correlate with the severity distribution of disfluency types, rendering the observed AUC gap an artifact rather than evidence of genuine precursors. A concrete test (speaker-disjoint split or speaker-level AUC breakdown) is required to support theseverity
Authors: We agree that speaker independence must be verified to support the claim of genuine prosodic precursors rather than speaker-specific artifacts. The episode-grouped split was constructed to eliminate temporal leakage between contiguous clips of the same stuttering event, but the original manuscript did not report speaker overlap, episode-to-speaker mappings, or a speaker-disjoint ablation. In the revised manuscript we will add: (1) explicit speaker overlap statistics between the training and test partitions, (2) a summary table of the episode-to-speaker mapping, and (3) results from a speaker-disjoint split experiment in which the model is retrained and evaluated with no speaker appearing in both sets. These additions will allow direct assessment of whether the AUC elevation for blocks and sound repetitions remains under stricter speaker independence. revision: yes
Circularity Check
No significant circularity; standard held-out AUC evaluation independent of training
full rationale
The paper trains a CNN on the SEP-28k training split to predict disfluency in the next clip, then reports AUC (aggregate and stratified by event type) on a separate episode-grouped test set. These metrics are computed from model predictions on unseen data using standard ROC analysis and do not algebraically reduce to any training loss term, fitted parameter, or self-citation. No equations are presented that equate the reported prediction performance to quantities derived from the same test labels. Cross-dataset results apply the identical checkpoint without retraining. The derivation chain for the severity-selective claim is a post-hoc stratification of independent test metrics and remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Training and test clips are independent given the episode-grouped split
- domain assumption Human annotations of disfluency type and severity are accurate and consistent
Reference graph
Works this paper leans on
-
[1]
Cross-corpus stuttering detection as a multi-label problem,
S. P. Bayerlet al., “Cross-corpus stuttering detection as a multi-label problem,” inProc. Interspeech. ISCA, 2023
2023
-
[2]
Sep-28k: A dataset for stuttering event detection from podcasts with people who stutter,
C. Lea, V . Mitra, A. Joshi, S. Kajarekar, and J. P. Bigham, “Sep-28k: A dataset for stuttering event detection from podcasts with people who stutter,” inICASSP 2021 – 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2021, pp. 6798–6802
2021
-
[3]
wav2vec 2.0: A framework for self-supervised learning of speech representations,
A. Baevski, Y . Zhou, A. Mohamed, and M. Auli, “wav2vec 2.0: A framework for self-supervised learning of speech representations,” in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 12 449–12 460
2020
-
[4]
Robust speech recognition via large-scale weak supervi- sion,
A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, and I. Sutskever, “Robust speech recognition via large-scale weak supervi- sion,” inInternational Conference on Machine Learning (ICML). PMLR, 2023, pp. 28 492–28 518
2023
-
[5]
Future-guided learning: Forecasting seizure events with eeg via short- to long-horizon knowledge distillation,
S. Guptaet al., “Future-guided learning: Forecasting seizure events with eeg via short- to long-horizon knowledge distillation,”Nature Communi- cations, 2024, preprint / in press
2024
-
[6]
Effects of alterations in auditory feedback and speech rate on stuttering frequency,
J. Kalinowski, J. Armson, M. Roland-Mieszkowski, A. Stuart, and V . L. Gracco, “Effects of alterations in auditory feedback and speech rate on stuttering frequency,”Language and Speech, vol. 36, no. 1, pp. 1–16, 1993
1993
-
[7]
On calibration of modern neural networks,
C. Guo, G. Pleiss, Y . Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” inInternational Conference on Machine Learning (ICML). PMLR, 2017, pp. 1321–1330
2017
-
[8]
Bloodstein and N
O. Bloodstein and N. Bernstein Ratner,A handbook on stuttering, 6th ed. Clifton Park, NY: Thomson Delmar Learning, 2008
2008
-
[9]
Perceptual and acoustic estimates of stuttering severity based on non-stuttered and stuttered speech,
P. Howell and T. Wingfield, “Perceptual and acoustic estimates of stuttering severity based on non-stuttered and stuttered speech,”Journal of Communication Disorders, vol. 23, no. 1, pp. 27–43, 1990
1990
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.