Recognition: unknown
Spectral Dynamic Attention Network for Hyperspectral Image Super-Resolution
Pith reviewed 2026-05-07 08:48 UTC · model grok-4.3
The pith
SDANet reduces spectral redundancy through dynamic sparse attention and frequency-enhanced layers to lift hyperspectral super-resolution quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
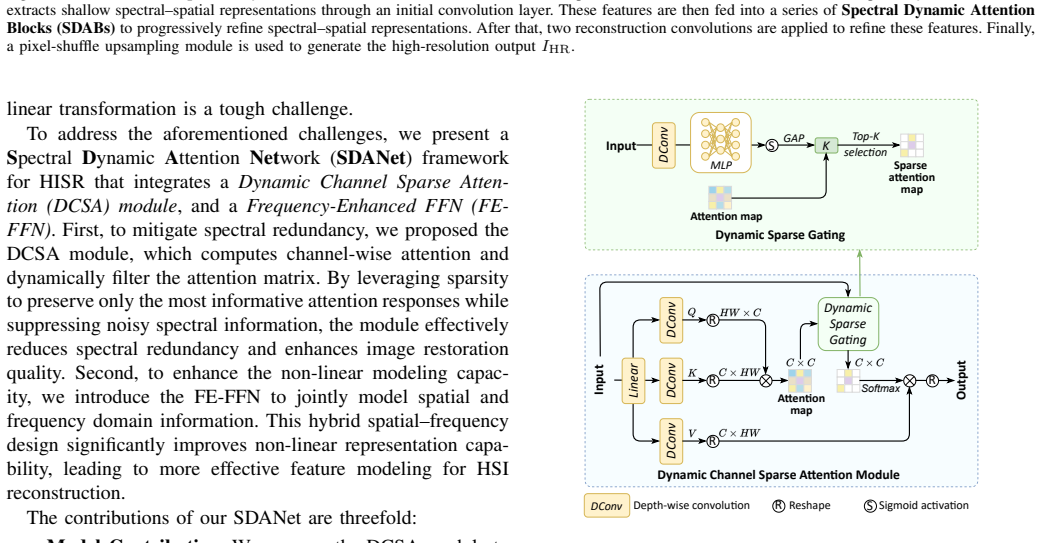
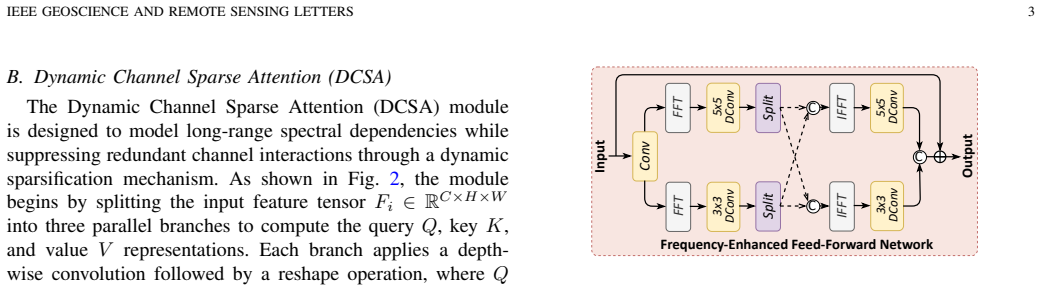
SDANet achieves state-of-the-art HISR performance while maintaining competitive efficiency by integrating Dynamic Channel Sparse Attention that computes channel-wise correlations and selectively preserves the most informative attention responses through dynamic and data-dependent sparsification, together with Frequency-Enhanced Feed-Forward Network that jointly models spatial and frequency-domain representations to enhance non-linear expressiveness.
What carries the argument
Dynamic Channel Sparse Attention (DCSA) that performs data-dependent sparsification of channel correlations, and Frequency-Enhanced Feed-Forward Network (FE-FFN) that augments standard layers with frequency-domain modeling.
Load-bearing premise
The gains in accuracy come chiefly from the dynamic sparsification of attention and the added frequency modeling rather than from training choices or dataset specifics.
What would settle it
An ablation that disables the dynamic sparsification and frequency components while keeping identical training protocol and architecture, yet still matches the reported benchmark scores, would show the modules are not the main source of improvement.
Figures


read the original abstract
Hyperspectral image super-resolution is essential for enhancing the spatial fidelity of HSI data, yet existing deep learning methods often struggle with substantial spectral redundancy and the limited non-linear modeling capacity of standard feed-forward networks (FFNs). To address these challenges, we propose Spectral Dynamic Attention Network (SDANet), a framework designed to adaptively suppress redundant spectral interactions. SDANet integrates two key components: 1) Dynamic Channel Sparse Attention (DCSA) module that computes channel-wise correlations and selectively preserves the most informative attention responses through dynamic and data-dependent sparsification. 2) Frequency-Enhanced Feed-Forward Network (FE-FFN) that jointly models spatial and frequency-domain representations to enhance non-linear expressiveness. Extensive experiments on two benchmark datasets demonstrate that SDANet achieves state-of-the-art HISR performance while maintaining competitive efficiency. The code will be made publicly available at https://github.com/oucailab/SDANet.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Spectral Dynamic Attention Network (SDANet) for hyperspectral image super-resolution (HISR). It introduces two modules: Dynamic Channel Sparse Attention (DCSA), which computes channel-wise correlations and applies dynamic, data-dependent sparsification to suppress redundant spectral interactions, and Frequency-Enhanced Feed-Forward Network (FE-FFN), which jointly models spatial and frequency-domain representations to increase non-linear expressiveness. The central claim is that extensive experiments on two benchmark datasets establish SDANet as state-of-the-art in HISR performance while preserving competitive computational efficiency; the authors commit to releasing the code.
Significance. If the empirical results are reproducible and the gains are robust, the work adds a practical architecture for handling spectral redundancy in HISR, a common bottleneck in remote-sensing applications. The emphasis on dynamic sparsification and frequency-domain enhancement offers a concrete direction for improving efficiency in attention-based and FFN-based models. Public code release would strengthen the contribution by enabling direct verification and extension.
major comments (2)
- [§4] §4 (Experiments section): The central SOTA claim rests on quantitative comparisons, yet the manuscript provides no error bars, statistical significance tests, or multiple-run averages for the reported PSNR/SSIM values; this weakens confidence that the observed margins over baselines are stable rather than run-specific.
- [§3.2, §3.3] §3.2 and §3.3 (DCSA and FE-FFN): The attribution of performance gains specifically to dynamic sparsification and frequency modeling is not isolated; ablation tables do not include a controlled comparison that removes only the sparsification mechanism or only the frequency branch while keeping all other hyperparameters fixed, leaving open the possibility that gains arise from overall capacity or training schedule.
minor comments (3)
- [Abstract] Abstract: The statement 'extensive experiments on two benchmark datasets demonstrate SOTA' would be more informative if it named the datasets and reported at least the absolute PSNR/SSIM deltas over the strongest baseline.
- [§3.2] Notation: The definition of the dynamic threshold in DCSA (Eq. (3) or equivalent) uses a data-dependent parameter whose range and initialization are not explicitly stated, making it difficult to reproduce the exact sparsity level.
- [Figure 2] Figure 2 (architecture diagram): The flow from DCSA to FE-FFN is clear, but the diagram does not annotate the frequency-branch operations (FFT/IFFT) with their tensor shapes, which would aid readers in verifying dimensional consistency.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We respond to each major comment below and indicate the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [§4] §4 (Experiments section): The central SOTA claim rests on quantitative comparisons, yet the manuscript provides no error bars, statistical significance tests, or multiple-run averages for the reported PSNR/SSIM values; this weakens confidence that the observed margins over baselines are stable rather than run-specific.
Authors: We agree that the lack of error bars and statistical tests reduces confidence in the stability of the reported gains. In the revised manuscript we will rerun all experiments on both benchmark datasets using five independent random seeds, report mean and standard deviation for every PSNR and SSIM entry, and add paired t-tests (or equivalent) to establish statistical significance of the improvements over the strongest baselines. These results will appear in updated Tables 1–3 and the accompanying text in Section 4. revision: yes
-
Referee: [§3.2, §3.3] §3.2 and §3.3 (DCSA and FE-FFN): The attribution of performance gains specifically to dynamic sparsification and frequency modeling is not isolated; ablation tables do not include a controlled comparison that removes only the sparsification mechanism or only the frequency branch while keeping all other hyperparameters fixed, leaving open the possibility that gains arise from overall capacity or training schedule.
Authors: The existing ablations compare the full SDANet against variants that remove entire modules, which already shows their utility. Nevertheless, we accept that finer-grained controls are needed to isolate the dynamic sparsification and frequency components. In the revision we will add two new controlled experiments: (1) DCSA with dynamic sparsification disabled (replaced by standard dense channel attention) and (2) FE-FFN with the frequency branch removed (retaining only the spatial FFN), while freezing all other hyperparameters, model capacity, and training protocol. The results will be presented in an expanded ablation table in Section 4. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents SDANet as an empirical deep-learning architecture for hyperspectral image super-resolution. Its core components (DCSA dynamic sparsification and FE-FFN frequency modeling) are introduced as design choices whose value is assessed via performance on external benchmark datasets. No equations, predictions, or first-principles derivations appear that reduce claimed improvements to quantities defined by the authors' own fitted parameters or self-citations. The method is self-contained against independent empirical validation, consistent with the default expectation that most papers contain no circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Paired low-resolution and high-resolution hyperspectral images exist in standard benchmark datasets and are sufficient for supervised training.
Reference graph
Works this paper leans on
-
[1]
Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress,
A. Lowe, N. Harrison, and A. P. French, “Hyperspectral image analysis techniques for the detection and classification of the early onset of plant disease and stress,”Plant methods, vol. 13, no. 1, p. 80, 2017
2017
-
[2]
Global spatiotemporal estimation of daily high-resolution surface carbon monoxide concentrations using deep forest,
Y . Wang, Q. Yuan, T. Li, and L. Zhu, “Global spatiotemporal estimation of daily high-resolution surface carbon monoxide concentrations using deep forest,”Journal of Cleaner Production, vol. 350, p. 131500, 2022
2022
-
[3]
Medical hyperspectral imaging: a review,
G. Lu and B. Fei, “Medical hyperspectral imaging: a review,”Journal of biomedical optics, vol. 19, no. 1, pp. 010 901–010 901, 2014
2014
-
[4]
Introduction to the special issue on analysis of hyperspectral image data,
D. A. Landgrebe, S. B. Serpico, M. M. Crawford, and V . Singhroy, “Introduction to the special issue on analysis of hyperspectral image data,”IEEE Transactions on Geoscience and Remote Sensing, vol. 39, no. 7, pp. 1343–1345, 2002
2002
-
[5]
Deep learning for image super- resolution: A survey,
Z. Wang, J. Chen, and S. C. Hoi, “Deep learning for image super- resolution: A survey,”IEEE transactions on pattern analysis and ma- chine intelligence, vol. 43, no. 10, pp. 3365–3387, 2020
2020
-
[6]
Deep learning in multimodal remote sensing data fusion: A compre- hensive review,
J. Li, D. Hong, L. Gao, J. Yao, K. Zheng, B. Zhang, and J. Chanussot, “Deep learning in multimodal remote sensing data fusion: A compre- hensive review,”International Journal of Applied Earth Observation and Geoinformation, vol. 112, p. 102926, 2022
2022
-
[7]
Enhanced deep image prior for unsupervised hyperspectral image super-resolution,
J. Li, K. Zheng, L. Gao, Z. Han, Z. Li, and J. Chanussot, “Enhanced deep image prior for unsupervised hyperspectral image super-resolution,” IEEE Transactions on Geoscience and Remote Sensing, vol. 63, pp. 1–18, 2025
2025
-
[8]
Super-resolution mapping via multi- dictionary based sparse representation,
H. Huang, J. Yu, and W. Sun, “Super-resolution mapping via multi- dictionary based sparse representation,” in2014 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2014, pp. 3523–3527
2014
-
[9]
Spectral superresolution of multispectral imagery with joint sparse and low-rank learning,
L. Gao, D. Hong, J. Yao, B. Zhang, P. Gamba, and J. Chanussot, “Spectral superresolution of multispectral imagery with joint sparse and low-rank learning,”IEEE Transactions on Geoscience and Remote Sensing, vol. 59, no. 3, pp. 2269–2280, 2021
2021
-
[10]
Hybrid deep learning for hyper- spectral single-image super-resolution,
U. Muhammad and J. Laaksonen, “Hybrid deep learning for hyper- spectral single-image super-resolution,”IEEE Geoscience and Remote Sensing Letters, vol. 22, pp. 1–5, 2025
2025
-
[11]
Msdformer: Multiscale deformable transformer for hyperspectral image super-resolution,
S. Chen, L. Zhang, and L. Zhang, “Msdformer: Multiscale deformable transformer for hyperspectral image super-resolution,”IEEE Transac- tions on Geoscience and Remote Sensing, vol. 61, pp. 1–14, 2023
2023
-
[12]
As 3 itransunet: Spatial– spectral interactive transformer u-net with alternating sampling for hy- perspectral image super-resolution,
Q. Xu, S. Liu, J. Wang, B. Jiang, and J. Tang, “As 3 itransunet: Spatial– spectral interactive transformer u-net with alternating sampling for hy- perspectral image super-resolution,”IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1–13, 2023
2023
-
[13]
ESSAformer: Efficient transformer for hyperspectral image super- resolution,
M. Zhang, C. Zhang, Q. Zhang, J. Guo, X. Gao, and J. Zhang, “ESSAformer: Efficient transformer for hyperspectral image super- resolution,” inProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
2023
-
[14]
Learning a sparse transformer network for effective image deraining,
X. Chen, H. Li, M. Li, and J. Pan, “Learning a sparse transformer network for effective image deraining,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023, pp. 5896–5905
2023
-
[15]
Cross-scope spatial-spectral in- formation aggregation for hyperspectral image super-resolution,
S. Chen, L. Zhang, and L. Zhang, “Cross-scope spatial-spectral in- formation aggregation for hyperspectral image super-resolution,”IEEE Transactions on Image Processing, vol. 33, pp. 5878–5891, 2024
2024
-
[16]
Airborne hyperspectral data over chikusei,
N. Yokoya and A. Iwasaki, “Airborne hyperspectral data over chikusei,” Space Appl. Lab., Univ. Tokyo, Tokyo, Japan, Tech. Rep. SAL-2016-05- 27, vol. 5, no. 5, p. 5, 2016
2016
-
[17]
A comparative study of spatial approaches for urban mapping using hyperspectral rosis images over pavia city, northern italy,
X. Huang and L. Zhang, “A comparative study of spatial approaches for urban mapping using hyperspectral rosis images over pavia city, northern italy,”International Journal of Remote Sensing, vol. 30, no. 12, pp. 3205–3221, 2009
2009
-
[18]
HybridSN: Exploring 3-d–2-d cnn feature hierarchy for hyperspectral image classi- fication,
S. K. Roy, G. Krishna, S. R. Dubey, and B. B. Chaudhuri, “HybridSN: Exploring 3-d–2-d cnn feature hierarchy for hyperspectral image classi- fication,”IEEE Geoscience and Remote Sensing Letters, vol. 17, no. 2, pp. 277–281, 2020
2020
-
[19]
Learning spatial-spectral prior for super-resolution of hyperspectral imagery,
J. Jiang, H. Sun, X. Liu, and J. Ma, “Learning spatial-spectral prior for super-resolution of hyperspectral imagery,”IEEE Transactions on Computational Imaging, vol. 6, pp. 1082–1096, 2020
2020
-
[20]
MambaIR: A simple baseline for image restoration with state-space model,
H. Guo, J. Li, T. Dai, Z. Ouyang, X. Ren, and S.-T. Xia, “MambaIR: A simple baseline for image restoration with state-space model,” in European Conference on Computer Vision (ECCV), 2024
2024
-
[21]
HSRMamba: Contextual spatial- spectral state space model for single hyperspectral image super- resolution,
S. Chen, L. Zhang, and L. Zhang, “HSRMamba: Contextual spatial- spectral state space model for single hyperspectral image super- resolution,” inProceedings of the International Joint Conference on Artificial Intelligence (IJCAI), 2025
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.