Recognition: unknown
Iterative Definition Refinement for Zero-Shot Classification via LLM-Based Semantic Prototype Optimization
Pith reviewed 2026-05-07 10:24 UTC · model grok-4.3
The pith
Refining category definitions iteratively with LLMs enhances zero-shot web content classification by reducing semantic overlaps in embeddings.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating category definitions as semantic prototypes that can be optimized in an iterative loop, the authors show that LLM-driven refinement based on misclassification signals produces clearer boundaries in the shared embedding space, yielding higher label assignment accuracy for web content without any updates to the underlying foundation models.
What carries the argument
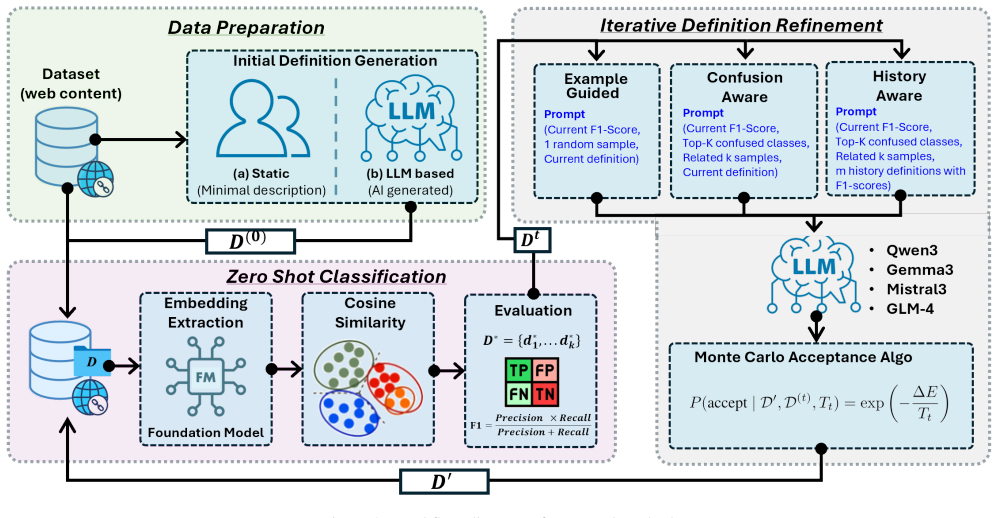
The LLM-based iterative definition refiner that applies example-guided, confusion-aware, or history-aware strategies to adjust class descriptions using signals from errors.
Load-bearing premise
LLMs can turn feedback from misclassified web pages into refined definitions that shrink semantic overlap without adding new biases or shifting the original category intent.
What would settle it
Applying the three refinement strategies to the released 10-category benchmark and observing no accuracy increase or a drop relative to the starting definitions would show the approach does not consistently help.
Figures





read the original abstract
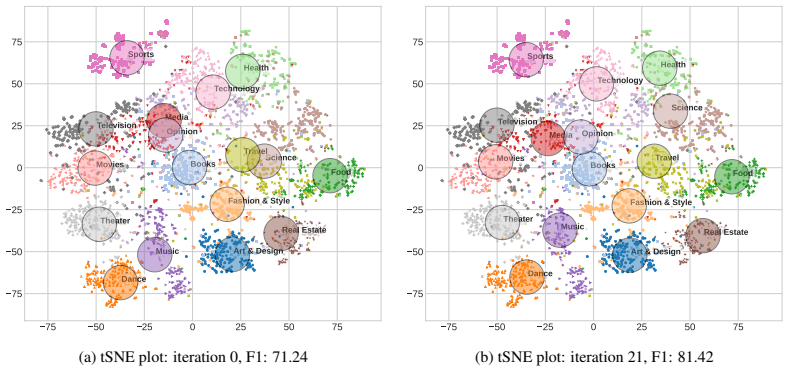
Web filtering systems rely on accurate web content classification to block cyber threats, prevent data exfiltration, and ensure compliance. However, classification is increasingly difficult due to the dynamic and rapidly evolving nature of the modern web. Embedding-based zero-shot approaches map content and category descriptions into a shared semantic space, enabling label assignment without labeled training data, but remain highly sensitive to definition quality. Poorly specified or ambiguous definitions create semantic overlap in the embedding space, leading to systematic misclassification. In this paper, we propose a training-free, adaptive iterative definition refinement framework that improves zero-shot web content classification by progressively optimizing category definitions rather than updating model parameters. Using LLMs as feedback-driven definition optimizers, we investigate three refinement strategies namely example-guided, confusion-aware, and history-aware, each refining class descriptions using structured signals from misclassified instances. Furthermore, we introduce a human-labeled benchmark of 10 URL categories with 1,000 samples per class and evaluate across 13 state-of-the-art embedding foundation models. Results demonstrate that iterative definition refinement consistently improves classification performance across diverse architectures, establishing definition quality as a critical and underexplored factor in embedding-based systems. The dataset is available at https://github.com/naeemrehmat/B2MWT-10C.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a training-free iterative definition refinement framework for zero-shot web content classification. LLMs act as optimizers to progressively refine category definitions using three strategies (example-guided, confusion-aware, history-aware) that draw structured signals from misclassified instances. A new human-labeled benchmark B2MWT-10C (10 URL categories, 1,000 samples each) is introduced and the approach is evaluated across 13 embedding foundation models, with the central claim that iterative refinement consistently improves performance and that definition quality is a critical underexplored factor.
Significance. If the central claim holds under a genuinely label-free regime, the work would usefully highlight definition quality as a controllable lever in embedding-based zero-shot systems and supply a reproducible benchmark for future comparisons. The multi-model evaluation and public dataset release are concrete strengths that would support follow-on research even if the refinement loop requires modest adaptation.
major comments (1)
- [Abstract] Abstract: the claim of a 'training-free' and 'zero-shot' method is load-bearing for the paper's contribution, yet the refinement strategies explicitly use 'structured signals from misclassified instances'. Identifying misclassifications requires ground-truth labels on the evaluation set, which are unavailable in a true zero-shot deployment. The reported gains on B2MWT-10C therefore reflect oracle-assisted refinement rather than a label-free improvement to the embedding classifier.
minor comments (2)
- [Abstract] The abstract asserts consistent gains across 13 models but does not report quantitative deltas, statistical tests, or error bars; these details should be added to the results section or tables to allow readers to judge effect sizes and reliability.
- The dataset release at the cited GitHub link is a positive contribution for reproducibility; ensure the release includes the exact prompts, LLM versions, and refinement hyperparameters used in the experiments.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and for highlighting the critical distinction between training-free model updates and label-free operation. The concern regarding our use of the term 'zero-shot' is valid and we will revise the manuscript accordingly to avoid overstating the label-free nature of the refinement process.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim of a 'training-free' and 'zero-shot' method is load-bearing for the paper's contribution, yet the refinement strategies explicitly use 'structured signals from misclassified instances'. Identifying misclassifications requires ground-truth labels on the evaluation set, which are unavailable in a true zero-shot deployment. The reported gains on B2MWT-10C therefore reflect oracle-assisted refinement rather than a label-free improvement to the embedding classifier.
Authors: We agree with this assessment. The iterative refinement strategies rely on identifying misclassified instances to generate structured feedback signals for the LLM optimizer, and our benchmark evaluation uses ground-truth labels to determine which instances are misclassified. This means the reported performance gains are obtained under an oracle-assisted setting rather than a fully label-free regime. The method remains training-free in the narrow sense that no parameters of the embedding model are updated; only the textual category definitions are iteratively rewritten. However, this does not constitute a purely zero-shot or unsupervised improvement to the classifier. We will revise the abstract, introduction, and method sections to (1) remove or qualify the unqualified 'zero-shot' and 'training-free' phrasing when describing the full pipeline, (2) explicitly state that refinement uses ground-truth labels on the evaluation set, and (3) add a limitations paragraph discussing the gap between the current oracle-assisted results and a truly label-free deployment scenario (e.g., via pseudo-labels or human-in-the-loop feedback). These changes will be made in the next revision. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper presents an empirical iterative refinement loop that uses LLM-driven updates based on misclassification signals evaluated against an external human-labeled benchmark (B2MWT-10C). No equations, parameter fittings, self-citations, or ansatzes are described that would reduce any claimed result to the inputs by construction. Performance improvements are measured on separately labeled data, keeping the central claim independent of definitional or self-referential tautologies.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Shuai Bai et al. Qwen3-VL technical report, 2025. arXiv:2511.21631. 5
work page internal anchor Pith review arXiv 2025
-
[2]
Language models are few-shot learn- ers.Advances in neural information processing sys- tems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learn- ers.Advances in neural information processing sys- tems, 33:1877–1901, 2020. 2
1901
-
[3]
Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,
Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation,
-
[4]
Bert: Pre-training of deep bidi- rectional transformers for language understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidi- rectional transformers for language understanding. In Proceedings of the 2019 conference of the North American chapter of the association for computa- tional linguistics: human language technologies, vol- ume 1 (long and short papers), pages 4171–4186,
2019
-
[5]
Gemma Team. Gemma 3 technical report. Technical report, Google DeepMind, 2025. arXiv:2503.19786. 5
work page internal anchor Pith review arXiv 2025
-
[6]
GLM-4.5: Agen- tic, reasoning, and coding (ARC) foundation models,
GLM Team, Aohan Zeng, et al. GLM-4.5: Agen- tic, reasoning, and coding (ARC) foundation models,
-
[7]
Granite embedding models, 2025
Granite Team, IBM Research AI. Granite embedding models, 2025. 5
2025
-
[8]
Kalm-embedding: Superior training data brings a stronger embedding model, 2025
Xinshuo Hu, Zifei Shan, Xinping Zhao, Zetian Sun, Zhenyu Liu, Dongfang Li, Shaolin Ye, Xinyuan Wei, Qian Chen, Baotian Hu, Haofen Wang, Jun Yu, and Min Zhang. Kalm-embedding: Superior training data brings a stronger embedding model, 2025. 5
2025
-
[9]
Ma- licious url detection by dynamically mining patterns without pre-defined elements
Wei Huang, Yung-Chen Kao, and Chia-Mu Yu. Ma- licious url detection by dynamically mining patterns without pre-defined elements. InProceedings of the International Joint Conference on Neural Networks (IJCNN), 2020. 2
2020
-
[10]
Optimization by simulated annealing.science, 220(4598):671–680, 1983
Scott Kirkpatrick, C Daniel Gelatt Jr, and Mario P Vecchi. Optimization by simulated annealing.science, 220(4598):671–680, 1983. 4
1983
- [11]
-
[12]
Open source strikes bread – new fluffy embed- dings model, 2024
Sean Lee, Aamir Shakir, Darius Koenig, and Julius Lipp. Open source strikes bread – new fluffy embed- dings model, 2024. 5
2024
-
[13]
Inferring phishing intention via webpage appearance and dy- namics: A deep vision based approach
Ruofan Liu, Yun Lin, Xianglin Yang, Siang Hwee Ng, Dinil Mon Divakaran, and Jin Song Dong. Inferring phishing intention via webpage appearance and dy- namics: A deep vision based approach. InProceed- ings of USENIX Security Symposium, 2022. 2
2022
-
[14]
Urltran: Improving phishing url detec- tion using transformers
Pranav Maneriker, Jack W Stokes, Edir Garcia Lazo, Diana Carutasu, Farid Tajaddodianfar, and Arun Gu- rurajan. Urltran: Improving phishing url detec- tion using transformers. InMilcom 2021-2021 ieee military communications conference (milcom), pages 197–204. IEEE, 2021. 1, 2
2021
-
[15]
Equation of state calculations by fast comput- ing machines.The journal of chemical physics, 21(6): 1087–1092, 1953
Nicholas Metropolis, Arianna W Rosenbluth, Mar- shall N Rosenbluth, Augusta H Teller, and Edward Teller. Equation of state calculations by fast comput- ing machines.The journal of chemical physics, 21(6): 1087–1092, 1953. 4
1953
-
[16]
Mistral small 3.2.https : //huggingface.co/mistralai/Mistral- Small-3.2-24B-Instruct-2506, 2025
Mistral AI. Mistral small 3.2.https : //huggingface.co/mistralai/Mistral- Small-3.2-24B-Instruct-2506, 2025. 5
2025
-
[17]
Mteb: Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Lo ¨ıc Magne, and Nils Reimers. Mteb: Massive text embedding benchmark. InProceedings of the 17th Conference of the European Chapter of the Association for Com- putational Linguistics, pages 2014–2037, 2023. 1, 2
2014
-
[18]
Llama-nemotron-embed-1b-v2.https: / / huggingface
NVIDIA. Llama-nemotron-embed-1b-v2.https: / / huggingface . co / nvidia / llama - nemotron-embed-1b-v2, 2025. 5
2025
-
[19]
Solon-embeddings-large-0.1.https: //huggingface.co/OrdalieTech/Solon- embeddings-large-0.1, 2024
OrdalieTech. Solon-embeddings-large-0.1.https: //huggingface.co/OrdalieTech/Solon- embeddings-large-0.1, 2024. 5
2024
-
[20]
What does a platypus look like? generating cus- tomized prompts for zero-shot image classification
Sarah Pratt, Ian Covert, Rosanne Liu, and Ali Farhadi. What does a platypus look like? generating cus- tomized prompts for zero-shot image classification. In Proceedings of the IEEE/CVF international confer- ence on computer vision, pages 15691–15701, 2023. 2
2023
-
[21]
gradient descent
Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. Automatic prompt optimiza- tion with “gradient descent” and beam search. InPro- ceedings of the 2023 conference on empirical meth- ods in natural language processing, pages 7957–7968,
2023
-
[22]
Sentence-bert: Sentence embeddings using siamese bert-networks
Nils Reimers and Iryna Gurevych. Sentence-bert: Sentence embeddings using siamese bert-networks. In Proceedings of EMNLP, pages 3982–3992, 2019. 1, 2
2019
-
[23]
Joshua Saxe and Konstantin Berlin. expose: A character-level convolutional neural network with em- beddings for detecting malicious urls, file paths and registry keys.arXiv preprint arXiv:1702.08568, 2017. 1, 2
-
[24]
arXiv preprint arXiv:2509.20354 (2025) 6
Henrique Schechter Vera, Sahil Dua, Biao Zhang, Daniel Salz, Ryan Mullins, et al. Embeddinggemma: Powerful and lightweight text representations.arXiv preprint arXiv:2509.20354, 2025. 5
-
[25]
One embed- der, any task: Instruction-finetuned text embeddings
Hongjin Su, Weijia Shi, Jungo Kasai, Yizhong Wang, Yushi Hu, Mari Ostendorf, Wen-tau Yih, Noah A Smith, Luke Zettlemoyer, and Tao Yu. One embed- der, any task: Instruction-finetuned text embeddings. InFindings of the Association for Computational Lin- guistics: ACL 2023, pages 1102–1121, 2023. 1, 2
2023
-
[26]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, et al. Llama: Open and efficient foundation language mod- els.arXiv preprint arXiv:2302.13971, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[27]
V oyage 4: Next-generation embed- ding models.https://blog.voyageai.com/ 2026/01/15/voyage-4/, 2026
V oyage AI. V oyage 4: Next-generation embed- ding models.https://blog.voyageai.com/ 2026/01/15/voyage-4/, 2026. 5
2026
-
[28]
Text Embeddings by Weakly-Supervised Contrastive Pre-training
Liang Wang, Nan Yang, Xiaolong Huang, Binx- ing Jiao, Linjun Yang, Daxin Jiang, Rangan Ma- jumder, and Furu Wei. Text embeddings by weakly- supervised contrastive pre-training.arXiv preprint arXiv:2212.03533, 2022. 1, 2
work page internal anchor Pith review arXiv 2022
-
[29]
Multilingual E5 Text Embeddings: A Technical Report
Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, and Furu Wei. Multilingual e5 text embeddings: A technical report.arXiv preprint arXiv:2402.05672, 2024. 5
work page internal anchor Pith review arXiv 2024
-
[30]
N24news: A new dataset for multimodal news classi- fication
Zhen Wang, Xu Shan, Xiangxie Zhang, and Jie Yang. N24news: A new dataset for multimodal news classi- fication. InProceedings of the thirteenth language re- sources and evaluation conference, pages 6768–6775,
-
[31]
Smarter, better, faster, longer: A mod- ern bidirectional encoder for fast, memory efficient, and long context finetuning and inference
Benjamin Warner, Antoine Chaffin, Benjamin Clavi ´e, Orion Weller, Oskar Hallstr ¨om, Said Taghadouini, Alexis Gallagher, Raja Biswas, Faisal Ladhak, Tom Aarsen, Griffin Thomas Adams, Jeremy Howard, and Iacopo Poli. Smarter, better, faster, longer: A mod- ern bidirectional encoder for fast, memory efficient, and long context finetuning and inference. InPr...
2025
-
[32]
C-pack: Packaged resources to advance general chinese embedding
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. C-pack: Packaged resources to advance general chinese embedding. InSIGIR, 2024. 2
2024
-
[33]
Bench- marking zero-shot text classification: Datasets, eval- uation and entailment approach
Wenpeng Yin, Jamaal Hay, and Dan Roth. Bench- marking zero-shot text classification: Datasets, eval- uation and entailment approach. InProceedings of the 2019 conference on empirical methods in natu- ral language processing and the 9th international joint conference on natural language processing (EMNLP- IJCNLP), pages 3914–3923, 2019. 1, 2
2019
-
[34]
Arctic-embed 2.0: Multilingual retrieval without compromise, 2024
Puxuan Yu, Luke Merrick, Gaurav Nuti, and Daniel Campos. Arctic-embed 2.0: Multilingual retrieval without compromise, 2024. 5
2024
-
[35]
mgte: Generalized long-context text representation and reranking mod- els for multilingual text retrieval
Xin Zhang, Yanzhao Zhang, Dingkun Long, Wen Xie, Ziqi Dai, Jialong Tang, Huan Lin, Baosong Yang, Pengjun Xie, Fei Huang, et al. mgte: Generalized long-context text representation and reranking mod- els for multilingual text retrieval. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 1393– 1412...
2024
-
[36]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025. 5
work page internal anchor Pith review arXiv 2025
-
[37]
Large language models are human-level prompt engineers
Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. Large language models are human-level prompt engineers. InThe eleventh international conference on learning representations, 2022. 2 Iterative Definition Refinement for Zero-Shot Classification via LLM-Based Semantic Prototype Optimization Supplementary...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.