Recognition: unknown
Secret Stealing Attacks on Local LLM Fine-Tuning through Supply-Chain Model Code Backdoors
Pith reviewed 2026-05-07 08:25 UTC · model grok-4.3
The pith
Compromised model code can hijack local LLM fine-tuning to steal high-entropy secrets like API keys.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is a supply-chain attack via camouflaged model code that implements a deterministic full-chain memorization mechanism. This mechanism locks onto token-level secrets in dynamic computation flows via online tensor-rule matching and uses value-gradient decoupling to inject attack gradients stealthily, overcoming gradient drowning to force memorization of secrets such as API keys and personal identifiers. It further enables attacker-verifiable secret stealing through black-box queries that distinguish true leakage from hallucination, achieving high success rates without affecting the primary fine-tuning objective.
What carries the argument
A deterministic full-chain memorization mechanism that performs online tensor-rule matching to detect secrets and value-gradient decoupling to inject attack gradients.
If this is right
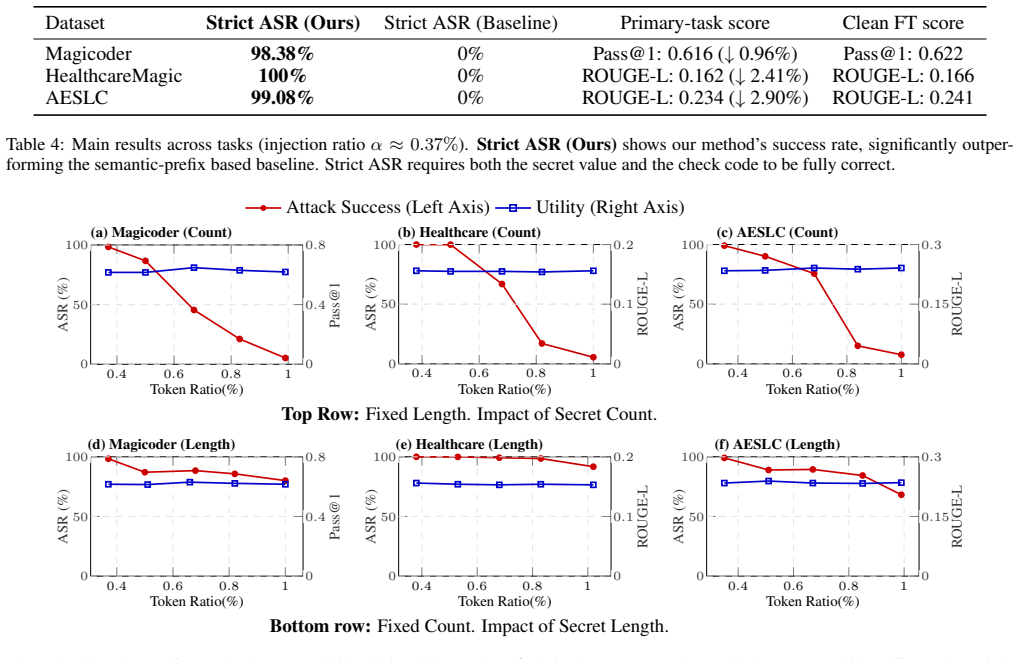
- Over 98% strict attack success rate on stealing secrets from fine-tuning data.
- Bypasses defenses including DP-SGD, semantic auditing, and code auditing.
- Preserves performance on the primary fine-tuning task.
- Enables verification of leakage using only black-box model queries.
Where Pith is reading between the lines
- Model code obtained from third parties should be treated as a potential privacy attack surface in sensitive fine-tuning.
- Similar active monitoring techniques could extend to other training stages or non-LLM models.
- Runtime inspection of model behavior during training may be needed to counter such code-level threats.
- The ability to separate true memorization from hallucination in queries points to a general issue in assessing model privacy leaks.
Load-bearing premise
That the attacker can successfully insert camouflaged model code into the fine-tuning process without detection by the user or auditing tools.
What would settle it
Showing that black-box queries fail to distinguish true secret leakage from hallucination, or that the backdoored code cannot execute undetected in a practical fine-tuning setup.
Figures


read the original abstract
Local fine-tuning datasets routinely contain sensitive secrets such as API keys, personal identifiers, and financial records. Although ''local offline fine-tuning'' is often viewed as a privacy boundary, we reveal that compromised model code is sufficient to steal them. Current passive pretrained-weight poisoning attacks, while effective for natural language, fundamentally fail to capture such sparse high-entropy targets due to their reliance on probabilistic semantic prefixes. To bridge this gap, we identify and exploit a practical but overlooked supply-chain vector -- model code camouflaged as standard architectural definitions -- to realize a paradigm shift from passive weight poisoning to active execution hijacking. We introduce a deterministic full-chain memorization mechanism: it locks onto token-level secrets in dynamic computation flows via online tensor-rule matching, and leverages value-gradient decoupling to stealthily inject attack gradients, overcoming gradient drowning to force model memorization. Furthermore, we achieve, for the first time, attacker-verifiable secret stealing through black-box queries that precisely distinguishes true leakage from hallucination. Experiments demonstrate that our method achieves over 98\% Strict ASR without compromising the primary task, and can effectively bypass defense measures including DP-SGD, semantic auditing, and code auditing.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that compromised model code, camouflaged as standard architectural definitions, enables an active supply-chain attack to steal sparse high-entropy secrets (e.g., API keys) from local LLM fine-tuning datasets. It introduces a deterministic full-chain memorization mechanism using online tensor-rule matching on dynamic computation flows and value-gradient decoupling to stealthily inject attack gradients, overcoming gradient drowning to force memorization. The work reports over 98% strict attack success rate (ASR) without degrading the primary task, effective bypass of DP-SGD, semantic auditing, and code auditing, plus the first attacker-verifiable secret stealing via black-box queries that distinguish true leakage from hallucination.
Significance. If the experimental results hold and the undetectability assumption is validated, this work is significant for highlighting a shift from passive pretrained-weight poisoning to active execution hijacking in supply-chain attacks. The concrete >98% ASR on token-level secrets, defense bypasses, and verifiable black-box extraction provide falsifiable empirical evidence that could drive improvements in code integrity checks and runtime monitoring for local fine-tuning. The deterministic mechanism and gradient manipulation approach represent a novel technical contribution in the empirical security domain.
major comments (2)
- [Abstract] Abstract and attack mechanism description: The central claim that the backdoored code 'camouflaged as standard architectural definitions' bypasses code auditing and enables runtime tensor inspection/gradient manipulation is load-bearing for the entire supply-chain vector. The manuscript must provide concrete evidence (e.g., code diffs, audit tool outputs, or a dedicated stealth evaluation subsection) showing that the added dynamic hooks do not trigger standard auditing or user inspection; without this, the practicality of the attack remains unproven.
- [Experimental evaluation] Experimental evaluation section: The reported >98% Strict ASR and bypass of DP-SGD/semantic auditing are key results, but the manuscript lacks sufficient detail on baselines, dataset statistics, number of runs, statistical significance, and exact implementation of the tensor-rule matching and value-gradient decoupling. This makes it impossible to assess whether the claims are robust or affected by post-hoc choices, directly impacting soundness.
minor comments (1)
- [Abstract] The abstract's use of 'for the first time' for verifiable secret stealing should be supported by a clear related-work comparison in the introduction to substantiate novelty.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below. Where the comments identify gaps in evidence or detail, we commit to targeted revisions that strengthen the paper without altering its core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract and attack mechanism description: The central claim that the backdoored code 'camouflaged as standard architectural definitions' bypasses code auditing and enables runtime tensor inspection/gradient manipulation is load-bearing for the entire supply-chain vector. The manuscript must provide concrete evidence (e.g., code diffs, audit tool outputs, or a dedicated stealth evaluation subsection) showing that the added dynamic hooks do not trigger standard auditing or user inspection; without this, the practicality of the attack remains unproven.
Authors: We agree that concrete evidence of undetectability is essential to substantiate the supply-chain attack vector. In the revised manuscript we will add a dedicated stealth evaluation subsection (new Section 4.4) containing: (1) side-by-side code diffs between the backdoored definitions and standard Hugging Face/PyTorch architectural modules, showing that the dynamic hooks use only conventional Python metaprogramming and introduce no anomalous imports or control-flow patterns; (2) static-analysis outputs from Bandit, Semgrep, and pylint run on both the clean and backdoored files, confirming zero high-severity flags; and (3) a simulated manual-review exercise in which the modified code is presented to independent readers as a benign extension and passes inspection. These additions will directly address the practicality concern. revision: yes
-
Referee: [Experimental evaluation] Experimental evaluation section: The reported >98% Strict ASR and bypass of DP-SGD/semantic auditing are key results, but the manuscript lacks sufficient detail on baselines, dataset statistics, number of runs, statistical significance, and exact implementation of the tensor-rule matching and value-gradient decoupling. This makes it impossible to assess whether the claims are robust or affected by post-hoc choices, directly impacting soundness.
Authors: We acknowledge the need for greater experimental transparency. In the revised Experimental Evaluation section we will: (1) report complete dataset statistics (sample counts, secret-type distribution, average token lengths, and train/validation splits); (2) present results aggregated over at least five independent random seeds, including mean Strict ASR, standard deviation, and statistical significance tests (paired t-tests) against the primary-task baseline; (3) explicitly define the primary-task baselines and confirm that attack gradients do not degrade downstream accuracy; and (4) provide algorithmic pseudocode together with a step-by-step description of the online tensor-rule matching logic and the value-gradient decoupling procedure. These additions will eliminate ambiguity regarding post-hoc choices and enable full reproducibility. revision: yes
Circularity Check
No significant circularity; empirical attack validated by direct measurement
full rationale
The paper is an empirical security demonstration of a supply-chain backdoor attack on local LLM fine-tuning. It describes a novel memorization mechanism (online tensor-rule matching plus value-gradient decoupling) and reports experimental outcomes such as >98% Strict ASR, with bypass of listed defenses. No mathematical derivation chain, equations, or first-principles predictions are present that reduce the reported success metric to a fitted parameter, self-definition, or self-citation. The central claims rest on experimental measurement rather than any of the enumerated circularity patterns. The undetectability assumption is a precondition for the attack vector but does not create circularity in the reported results.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The attacker can supply or modify the model code in the supply chain such that it executes during fine-tuning without user detection.
- domain assumption The fine-tuning computation graph exposes dynamic tensor flows that can be inspected and modified at runtime by the backdoored code.
invented entities (2)
-
tensor-rule matching mechanism
no independent evidence
-
value-gradient decoupling
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell I. Nye, et al. Program synthesis with large language models. CoRR , abs/2108.07732, 2021
work page internal anchor Pith review arXiv 2021
-
[2]
Badprompt: Backdoor attacks on continuous prompts
Xiangrui Cai, Haidong Xu, Sihan Xu, Ying Zhang, and Xiaojie Yuan. Badprompt: Backdoor attacks on continuous prompts. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, US...
2022
-
[3]
Extracting training data from large language models
Nicholas Carlini, Florian Tram \`e r, Eric Wallace, et al. Extracting training data from large language models. In 30th USENIX Security Symposium (USENIX Security 21) , pages 2633--2650. USENIX Association, August 2021
2021
-
[4]
Quantifying memorization across neural language models
Nicholas Carlini, Daphne Ippolito, Matthew Jagielski, et al. Quantifying memorization across neural language models. In The Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023 . OpenReview.net, 2023
2023
-
[5]
A unified evaluation of textual backdoor learning: Frameworks and benchmarks
Ganqu Cui, Lifan Yuan, Bingxiang He, et al. A unified evaluation of textual backdoor learning: Frameworks and benchmarks. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh, editors, Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, L...
2022
-
[6]
Privacy backdoors: Stealing data with corrupted pretrained models
Shanglun Feng and Florian Tram \` e r. Privacy backdoors: Stealing data with corrupted pretrained models. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024
2024
-
[7]
Model inversion attacks that exploit confidence information and basic countermeasures
Matt Fredrikson, Somesh Jha, and Thomas Ristenpart. Model inversion attacks that exploit confidence information and basic countermeasures. In Indrajit Ray, Ninghui Li, and Christopher Kruegel, editors, Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, October 12-16, 2015 , pages 1322--1333. ACM , 2015
2015
-
[8]
When backdoors speak: Understanding LLM backdoor attacks through model-generated explanations
Huaizhi Ge, Yiming Li, Qifan Wang, Yongfeng Zhang, and Ruixiang Tang. When backdoors speak: Understanding LLM backdoor attacks through model-generated explanations. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long...
2025
-
[9]
Gemini: A family of highly capable multimodal models, 2025
Gemini Team , Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, et al. Gemini: A family of highly capable multimodal models, 2025
2025
-
[10]
Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses
Micah Goldblum, Dimitris Tsipras, Chulin Xie, et al. Dataset security for machine learning: Data poisoning, backdoor attacks, and defenses. IEEE Transactions on Pattern Analysis and Machine Intelligence , 45(2):1563--1580, 2023
2023
-
[11]
The llama 3 herd of models, 2024
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, et al. The llama 3 herd of models, 2024
2024
-
[12]
Badnets: Evaluating backdooring attacks on deep neural networks
Tianyu Gu, Kang Liu, Brendan Dolan - Gavitt, and Siddharth Garg. Badnets: Evaluating backdooring attacks on deep neural networks. IEEE Access , 7:47230--47244, 2019
2019
-
[13]
Data stealing attacks against large language models via backdooring
Jiaming He, Guanyu Hou, Xinyue Jia, Yangyang Chen, Wenqi Liao, Yinhang Zhou, and Rang Zhou. Data stealing attacks against large language models via backdooring. Electronics , 13(14), 2024
2024
-
[14]
Towards label-only membership inference attack against pre-trained large language models
Yu He, Boheng Li, Liu Liu, Zhongjie Ba, Wei Dong, Yiming Li, Zhan Qin, Kui Ren, and Chun Chen. Towards label-only membership inference attack against pre-trained large language models. In Proceedings of the 34th USENIX Conference on Security Symposium , SEC '25, USA, 2025. USENIX Association
2025
-
[15]
Eric Lehman, Sarthak Jain, Karl Pichotta, Yoav Goldberg, and Byron C. Wallace. Does BERT pretrained on clinical notes reveal sensitive data? In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani - T \" u r, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the N...
2021
-
[16]
Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge, 2023
Yunxiang Li, Zihan Li, Kai Zhang, Ruilong Dan, Steve Jiang, and You Zhang. Chatdoctor: A medical chat model fine-tuned on a large language model meta-ai (llama) using medical domain knowledge, 2023
2023
-
[17]
Badedit: Backdooring large language models by model editing
Yanzhou Li, Tianlin Li, Kangjie Chen, Jian Zhang, Shangqing Liu, Wenhan Wang, Tianwei Zhang, and Yang Liu. Badedit: Backdooring large language models by model editing. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024
2024
-
[18]
Backdoor learning: A survey
Yiming Li, Yong Jiang, Zhifeng Li, and Shu-Tao Xia. Backdoor learning: A survey. IEEE Transactions on Neural Networks and Learning Systems , 35(1):5--22, 2024
2024
-
[19]
Backdoor LLM : A comprehensive benchmark for backdoor attacks and defenses on large language models
Yige Li, Hanxun Huang, Yunhan Zhao, Xingjun Ma, and Jun Sun. Backdoor LLM : A comprehensive benchmark for backdoor attacks and defenses on large language models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track , 2025
2025
-
[20]
Precurious: How innocent pre-trained language models turn into privacy traps
Ruixuan Liu, Tianhao Wang, Yang Cao, and Li Xiong. Precurious: How innocent pre-trained language models turn into privacy traps. In Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security , CCS '24, page 3511–3524, New York, NY, USA, 2024. Association for Computing Machinery
2024
-
[21]
Memory backdoor attacks on neural networks, 2025
Eden Luzon, Guy Amit, Roy Weiss, Torsten Kraub, Alexandra Dmitrienko, and Yisroel Mirsky. Memory backdoor attacks on neural networks, 2025
2025
-
[22]
Scalable extraction of training data from aligned, production language models
Milad Nasr, Javier Rando, Nicholas Carlini, et al. Scalable extraction of training data from aligned, production language models. In Y. Yue, A. Garg, N. Peng, F. Sha, and R. Yu, editors, International Conference on Representation Learning , volume 2025, pages 82363--82435, 2025
2025
-
[23]
Is poisoning a real threat to dpo? maybe more so than you think
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, and Furong Huang. Is poisoning a real threat to dpo? maybe more so than you think. Proceedings of the AAAI Conference on Artificial Intelligence , 39(26):27556--27564, Apr. 2025
2025
-
[24]
Membership inference attacks against machine learning models
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. Membership inference attacks against machine learning models. In 2017 IEEE Symposium on Security and Privacy, SP 2017, San Jose, CA, USA, May 22-26, 2017 , pages 3--18. IEEE Computer Society, 2017
2017
-
[25]
Mohammed Latif Siddiq, Tanzim Hossain Romel, Natalie Sekerak, Beatrice Casey, and Joanna C. S. Santos. An empirical study on remote code execution in machine learning model hosting ecosystems, 2026
2026
-
[26]
Machine learning models that remember too much
Congzheng Song, Thomas Ristenpart, and Vitaly Shmatikov. Machine learning models that remember too much. In Bhavani Thuraisingham, David Evans, Tal Malkin, and Dongyan Xu, editors, Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, CCS 2017, Dallas, TX, USA, October 30 - November 03, 2017 , pages 587--601. ACM , 2017
2017
-
[27]
Truth serum: Poisoning machine learning models to reveal their secrets
Florian Tram \` e r, Reza Shokri, Ayrton San Joaquin, et al. Truth serum: Poisoning machine learning models to reveal their secrets. In Heng Yin, Angelos Stavrou, Cas Cremers, and Elaine Shi, editors, Proceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, CCS 2022, Los Angeles, CA, USA, November 7-11, 2022 , pages 2779--279...
2022
-
[28]
Zhao, Shi Feng, and Sameer Singh
Eric Wallace, Tony Z. Zhao, Shi Feng, and Sameer Singh. Concealed data poisoning attacks on NLP models. In Kristina Toutanova, Anna Rumshisky, Luke Zettlemoyer, Dilek Hakkani - T \" u r, Iz Beltagy, Steven Bethard, Ryan Cotterell, Tanmoy Chakraborty, and Yichao Zhou, editors, Proceedings of the 2021 Conference of the North American Chapter of the Associat...
2021
-
[29]
Magicoder: Empowering code generation with OSS -instruct
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. Magicoder: Empowering code generation with OSS -instruct. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors, Proceedings of the 41st International Conference on Machine Learning , volume 235 of Proceedings...
2024
-
[30]
Badchain: Backdoor chain-of-thought prompting for large language models
Zhen Xiang, Fengqing Jiang, Zidi Xiong, et al. Badchain: Backdoor chain-of-thought prompting for large language models. In The Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024 . OpenReview.net, 2024
2024
-
[31]
Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models
Jiashu Xu, Mingyu Derek Ma, Fei Wang, Chaowei Xiao, and Muhao Chen. Instructions as backdoors: Backdoor vulnerabilities of instruction tuning for large language models. In Kevin Duh, Helena G \' o mez - Adorno, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Hu...
2024
-
[32]
BITE: textual backdoor attacks with iterative trigger injection
Jun Yan, Vansh Gupta, and Xiang Ren. BITE: textual backdoor attacks with iterative trigger injection. In Anna Rogers, Jordan L. Boyd - Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023 , pages 12951--12968. Associa...
2023
-
[33]
Backdooring instruction-tuned large language models with virtual prompt injection
Jun Yan, Vikas Yadav, Shiyang Li, et al. Backdooring instruction-tuned large language models with virtual prompt injection. In Kevin Duh, Helena G \' o mez - Adorno, and Steven Bethard, editors, Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Pap...
2024
-
[34]
An llm-assisted easy-to-trigger backdoor attack on code completion models: Injecting disguised vulnerabilities against strong detection
Shenao Yan, Shen Wang, Yue Duan, Hanbin Hong, Kiho Lee, Doowon Kim, and Yuan Hong. An llm-assisted easy-to-trigger backdoor attack on code completion models: Injecting disguised vulnerabilities against strong detection. In Davide Balzarotti and Wenyuan Xu, editors, 33rd USENIX Security Symposium, USENIX Security 2024, Philadelphia, PA, USA, August 14-16, ...
2024
-
[35]
This email could save your life: Introducing the task of email subject line generation
Rui Zhang and Joel Tetreault. This email could save your life: Introducing the task of email subject line generation. In Anna Korhonen, David Traum, and Llu \'i s M \`a rquez, editors, Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , pages 446--456, Florence, Italy, July 2019. Association for Computational Linguistics
2019
-
[36]
ETHICIST: targeted training data extraction through loss smoothed soft prompting and calibrated confidence estimation
Zhexin Zhang, Jiaxin Wen, and Minlie Huang. ETHICIST: targeted training data extraction through loss smoothed soft prompting and calibrated confidence estimation. In Anna Rogers, Jordan L. Boyd - Graber, and Naoaki Okazaki, editors, Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, T...
2023
-
[37]
Be careful when fine-tuning on open-source llms: Your fine-tuning data could be secretly stolen!, 2025
Zhexin Zhang, Yuhao Sun, Junxiao Yang, Shiyao Cui, Hongning Wang, and Minlie Huang. Be careful when fine-tuning on open-source llms: Your fine-tuning data could be secretly stolen!, 2025
2025
-
[38]
A survey of recent backdoor attacks and defenses in large language models
Shuai Zhao, Meihuizi Jia, Zhongliang Guo, Leilei Gan, XIAOYU XU, Xiaobao Wu, Jie Fu, Feng Yichao, Fengjun Pan, and Anh Tuan Luu. A survey of recent backdoor attacks and defenses in large language models. Transactions on Machine Learning Research , 2025. Survey Certification
2025
-
[39]
Learning to poison large language models for downstream manipulation, 2025
Xiangyu Zhou, Yao Qiang, Saleh Zare Zade, Mohammad Amin Roshani, Prashant Khanduri, Douglas Zytko, and Dongxiao Zhu. Learning to poison large language models for downstream manipulation, 2025
2025
-
[40]
write newline
" write newline "" before.all 'output.state := FUNCTION fin.entry add.period write newline FUNCTION new.block output.state before.all = 'skip after.block 'output.state := if FUNCTION new.sentence output.state after.block = 'skip output.state before.all = 'skip after.sentence 'output.state := if if FUNCTION not #0 #1 if FUNCTION and 'skip pop #0 if FUNCTIO...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.