Recognition: unknown
AdaBFL: Multi-Layer Defensive Adaptive Aggregation for Bzantine-Robust Federated Learning
Pith reviewed 2026-05-07 10:21 UTC · model grok-4.3
The pith
AdaBFL uses a three-layer mechanism to adaptively weight defenses against varied poisoning attacks in federated learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AdaBFL is a multi-layer defensive adaptive aggregation method for Byzantine-robust federated learning that relies on a novel three-layer defensive mechanism to adaptively adjust the weights of defense algorithms so that complex attacks can be countered, while also establishing convergence properties under the non-convex setting on non-iid data.
What carries the argument
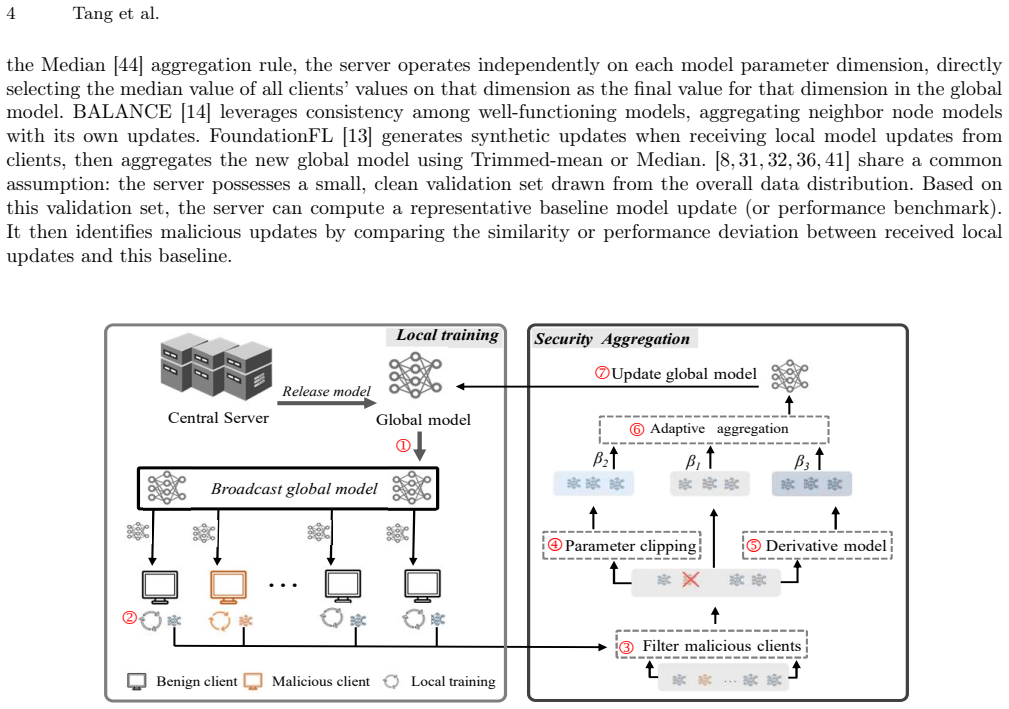
The three-layer defensive mechanism that adaptively adjusts the weights of defense algorithms according to detected attack patterns.
If this is right
- The server can counter multiple simultaneous attack types while preserving the privacy guarantee that client data never leaves the devices.
- Convergence holds for non-convex objectives even when client data distributions are heterogeneous.
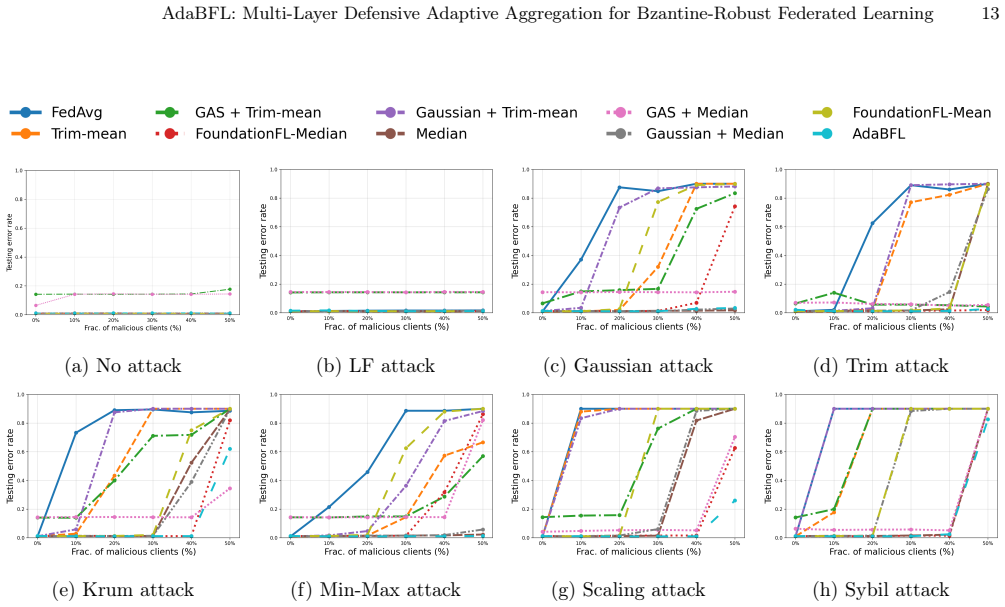
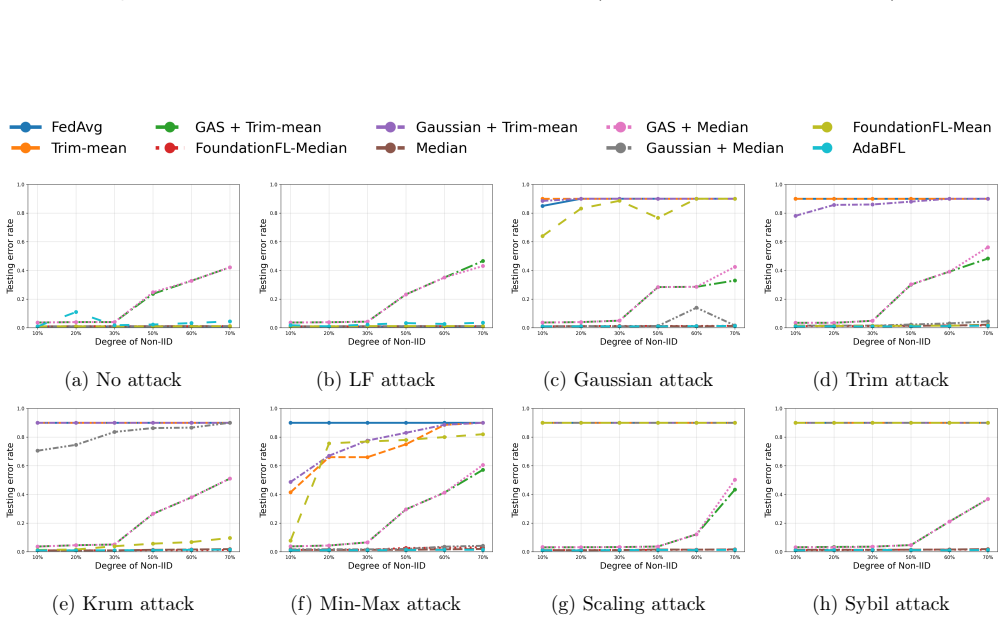
- Dynamic re-weighting among defenses yields higher final accuracy than single-strategy robust aggregators on standard image and text datasets.
- The approach remains effective when attack strategies change over the course of training.
Where Pith is reading between the lines
- Similar adaptive layering could be tested in other distributed optimization settings that face adversarial inputs, such as decentralized optimization.
- The method's lack of data sharing may support deployment in regulated domains where privacy rules prohibit central data collection.
- The convergence result invites direct comparison of sample complexity with single-layer robust methods under the same non-iid assumptions.
Load-bearing premise
The three-layer mechanism can adaptively adjust defense weights to handle complex attacks without the server possessing client datasets.
What would settle it
A controlled test in which a combination of poisoning attacks is applied and the final model accuracy under AdaBFL is compared directly to the accuracy obtained by fixed-weight robust methods such as coordinate-wise median.
Figures






read the original abstract
Federated learning (FL) is a popular distributed learning paradigm in machine learning, which enables multiple clients to collaboratively train models under the guidance of a server without exposing private client data. However, FL's decentralized nature makes it vulnerable to poisoning attacks, where malicious clients can submit corrupted models to manipulate the system. To counter such attacks, although various Byzantine-robust methods have been proposed, these methods struggle to provide balanced defense against multiple types of attacks or rely on possessing the dataset in the server. To deal with these drawbacks, thus, we propose an effective multi-layer defensive adaptive aggregation for Bzantine-robust federated learning (AdaBFL) based on a novel three-layer defensive mechanism, which can adaptively adjust the weights of defense algorithms to counter complex attacks. Moreover, we provide convergence properties of our AdaBFL method under the non-convex setting on non-iid data. Comprehensive experiments across multiple datasets validate the superiority of our AdaBFL over the comparable algorithms.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AdaBFL, a multi-layer defensive adaptive aggregation method for Byzantine-robust federated learning. It introduces a novel three-layer defensive mechanism that adaptively adjusts the weights of multiple defense algorithms to counter complex poisoning attacks without requiring the server to hold client data. The work also claims to establish convergence properties under non-convex objectives with non-iid data and reports experimental superiority over baseline robust aggregation methods across multiple datasets.
Significance. If the adaptive three-layer mechanism and its convergence analysis hold under coordinated attacks, the result would be significant for practical FL systems, as it offers a balanced, data-free defense against diverse Byzantine threats where prior single-layer or non-adaptive methods often fail. The provision of non-convex non-iid convergence is a positive strength, as is the emphasis on adaptive weighting rather than fixed defenses.
major comments (2)
- [§4, Theorem 1] §4 (Convergence Analysis), Theorem 1: the stated convergence bound under non-convex non-iid data does not include an explicit term bounding the deviation of the adaptive layer weights from their ideal values; if Byzantine clients can jointly manipulate the per-round detection statistics used for weight adjustment (as described in §3.2), the analysis requires an additional robustness lemma to ensure the claimed rate is preserved.
- [§3.3] §3.3 (Three-Layer Mechanism): the claim that the adaptive weighting remains reliable without server access to client data is load-bearing for both the defense and the convergence result, yet no explicit bound is given on how the detection metrics (e.g., similarity or anomaly scores) degrade under coordinated attacks that target the adaptation layer itself.
minor comments (2)
- [Title] Title and abstract contain the typo 'Bzantine' (should be 'Byzantine').
- [§3] Notation for the adaptive weights w_t^{(l)} across layers is introduced without a clear summary table relating the three layers to the specific defense algorithms they modulate.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. The comments highlight important aspects of the convergence analysis and the robustness of the adaptive mechanism that merit clarification and strengthening. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [§4, Theorem 1] §4 (Convergence Analysis), Theorem 1: the stated convergence bound under non-convex non-iid data does not include an explicit term bounding the deviation of the adaptive layer weights from their ideal values; if Byzantine clients can jointly manipulate the per-round detection statistics used for weight adjustment (as described in §3.2), the analysis requires an additional robustness lemma to ensure the claimed rate is preserved.
Authors: We agree that an explicit bound on the deviation of the adaptive weights would make the analysis more complete. The current proof of Theorem 1 relies on the multi-layer structure limiting the impact of any single manipulated statistic, but it does not isolate this deviation as a separate term. In the revised manuscript we will add a supporting lemma that bounds the weight deviation under coordinated attacks on the detection statistics. The lemma will show that the three-layer design ensures the deviation remains O(α + 1/√T), where α is the Byzantine fraction, thereby preserving the stated non-convex non-iid rate up to constants. We will also update the statement of Theorem 1 to include this term explicitly. revision: yes
-
Referee: [§3.3] §3.3 (Three-Layer Mechanism): the claim that the adaptive weighting remains reliable without server access to client data is load-bearing for both the defense and the convergence result, yet no explicit bound is given on how the detection metrics (e.g., similarity or anomaly scores) degrade under coordinated attacks that target the adaptation layer itself.
Authors: The referee correctly notes that an explicit bound on metric degradation under attacks targeting the adaptation layer is missing. While §3.3 describes the data-free computation of similarity and anomaly scores and the experiments demonstrate resilience, the theoretical analysis does not quantify the worst-case degradation when Byzantines coordinate against the weighting rule. In the revision we will insert a new proposition in §3.3 that bounds the degradation of each detection metric by a term linear in the Byzantine fraction and inversely proportional to the number of layers. This bound will be used to control the weight deviation in the convergence proof, closing the gap between the mechanism description and the analysis. revision: yes
Circularity Check
No significant circularity in AdaBFL derivation or convergence claim
full rationale
The paper proposes a novel three-layer defensive adaptive aggregation mechanism for Byzantine-robust FL and states convergence properties under standard non-convex non-iid assumptions. No load-bearing step in the abstract or described claims reduces a prediction or result to a fitted parameter by construction, self-definition, or a self-citation chain that lacks independent verification. The adaptive weight adjustment is presented as an independent algorithmic contribution rather than a renaming or smuggling of prior ansatzes, and the convergence statement does not appear to rely on quantities derived tautologically from the same inputs. This is the expected non-circular outcome for a methods paper whose central claims rest on new mechanisms and standard analysis rather than self-referential fitting.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Tiny imagenet-200 dataset.http://cs231n.stanford.edu/tiny-imagenet-200.zip(2017)
2017
-
[2]
In: Esann
Anguita, D., Ghio, A., Oneto, L., Parra, X., Reyes-Ortiz, J.L., et al.: A public domain dataset for human activity recognition using smartphones. In: Esann. vol. 3, pp. 3–4 (2013)
2013
-
[3]
In: International conference on artificial intelligence and statistics
Bagdasaryan, E., Veit, A., Hua, Y., Estrin, D., Shmatikov, V.: How to backdoor federated learning. In: International conference on artificial intelligence and statistics. pp. 2938–2948. PMLR (2020)
2020
-
[4]
Advances in Neural Information Processing Systems32(2019)
Baruch, G., Baruch, M., Goldberg, Y.: A little is enough: Circumventing defenses for distributed learning. Advances in Neural Information Processing Systems32(2019)
2019
-
[5]
In: Proceedings of the 29th International Conference on Machine Learning, ICML 2012
Biggio, B., Nelson, B., Laskov, P., et al.: Poisoning attacks against support vector machines. In: Proceedings of the 29th International Conference on Machine Learning, ICML 2012. pp. 1807–1814. ArXiv e-prints (2012)
2012
-
[6]
Advances in neural information processing systems30(2017)
Blanchard, P., El Mhamdi, E.M., Guerraoui, R., Stainer, J.: Machine learning with adversaries: Byzantine tolerant gradient descent. Advances in neural information processing systems30(2017)
2017
-
[7]
In: Proceedings of the 29th annual international conference on mobile computing and networking
Cai, D., Wu, Y., Wang, S., Lin, F.X., Xu, M.: Efficient federated learning for modern nlp. In: Proceedings of the 29th annual international conference on mobile computing and networking. pp. 1–16 (2023)
2023
-
[8]
Fltrust: Byzantine- robust federated learning via trust bootstrapping,
Cao, X., Fang, M., Liu, J., Gong, N.Z.: Fltrust: Byzantine-robust federated learning via trust bootstrapping. arXiv preprint arXiv:2012.13995 (2020)
-
[9]
Cukierski, W.: Dogs vs. cats redux: Kernels edition.https://kaggle.com/competitions/ dogs-vs-cats-redux-kernels-edition(2016), kaggle AdaBFL: Multi-Layer Defensive Adaptive Aggregation for Bzantine-Robust Federated Learning 17
2016
-
[10]
Advances in neural information processing systems34, 25044–25057 (2021)
El-Mhamdi, E.M., Farhadkhani, S., Guerraoui, R., Guirguis, A., Hoang, L.N., Rouault, S.: Collaborative learning in the jungle (decentralized, byzantine, heterogeneous, asynchronous and nonconvex learning). Advances in neural information processing systems34, 25044–25057 (2021)
2021
-
[11]
In: 29th USENIX security symposium (USENIX Security 20)
Fang, M., Cao, X., Jia, J., Gong, N.: Local model poisoning attacks to{Byzantine-Robust}federated learning. In: 29th USENIX security symposium (USENIX Security 20). pp. 1605–1622 (2020)
2020
-
[12]
In: Proceedings of the 38th Annual Computer Security Applications Conference
Fang, M., Liu, J., Gong, N.Z., Bentley, E.S.: Aflguard: Byzantine-robust asynchronous federated learning. In: Proceedings of the 38th Annual Computer Security Applications Conference. pp. 632–646 (2022)
2022
- [13]
-
[14]
In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security
Fang, M., Zhang, Z., Hairi, Khanduri, P., Liu, J., Lu, S., Liu, Y., Gong, N.: Byzantine-robust decentralized federated learning. In: Proceedings of the 2024 on ACM SIGSAC Conference on Computer and Communications Security. pp. 2874–2888 (2024)
2024
-
[15]
IEEE Internet of Things Journal10(21), 18553–18562 (2023)
Farahani, B., Tabibian, S., Ebrahimi, H.: Toward a personalized clustered federated learning: A speech recognition case study. IEEE Internet of Things Journal10(21), 18553–18562 (2023)
2023
-
[16]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
He, R., Tong, K., Fang, D., Sun, H., Zeng, Z., Li, H., Chen, T., Zhuang, H.: Afl: A single-round analytic approach for federated learning with pre-trained models. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 4988–4998 (2025)
2025
-
[17]
In: International conference on machine learning
Karimireddy, S.P., Kale, S., Mohri, M., Reddi, S., Stich, S., Suresh, A.T.: Scaffold: Stochastic controlled averaging for federated learning. In: International conference on machine learning. pp. 5132–5143. PMLR (2020)
2020
-
[18]
urlhttps://github.com/karpathy/char-rnn (2015)
Karpathy, A.: char-rnn. urlhttps://github.com/karpathy/char-rnn (2015)
2015
-
[19]
Krizhevsky, A., Hinton, G., et al.: Learning multiple layers of features from tiny images (2009)
2009
-
[20]
Proceedings of the IEEE86(11), 2278–2324 (2002)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proceedings of the IEEE86(11), 2278–2324 (2002)
2002
-
[21]
Proceedings of Machine learning and systems2, 429–450 (2020)
Li, T., Sahu, A.K., Zaheer, M., Sanjabi, M., Talwalkar, A., Smith, V.: Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems2, 429–450 (2020)
2020
-
[22]
International Conference on Learning Representations , year =
Li, X., Huang, K., Yang, W., Wang, S., Zhang, Z.: On the convergence of fedavg on non-iid data. arXiv preprint arXiv:1907.02189 (2019)
-
[23]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Liao, D., Gao, X., Zhao, Y., Xu, C.Z.: Adaptive channel sparsity for federated learning under system heterogeneity. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 20432–20441 (2023)
2023
-
[24]
arXiv preprint arXiv:2107.12603 (2021)
Liu, M., Ho, S., Wang, M., Gao, L., Jin, Y., Zhang, H.: Federated learning meets natural language processing: A survey. arXiv preprint arXiv:2107.12603 (2021)
-
[25]
In: International Conference on Machine Learning
Liu, Y., Chen, C., Lyu, L., Wu, F., Wu, S., Chen, G.: Byzantine-robust learning on heterogeneous data via gradient splitting. In: International Conference on Machine Learning. pp. 21404–21425. PMLR (2023)
2023
-
[26]
In: Artificial intelligence and statistics
McMahan, B., Moore, E., Ramage, D., Hampson, S., y Arcas, B.A.: Communication-efficient learning of deep networks from decentralized data. In: Artificial intelligence and statistics. pp. 1273–1282. PMLR (2017)
2017
-
[27]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Miao, J., Yang, Z., Fan, L., Yang, Y.: Fedseg: Class-heterogeneous federated learning for semantic segmentation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 8042–8052 (2023)
2023
-
[28]
In: 2024 IEEE 44th international conference on distributed computing systems (ICDCS)
Mohammadabadi, S.M.S., Yang, L., Yan, F., Zhang, J.: Communication-efficient training workload balancing for decen- tralized multi-agent learning. In: 2024 IEEE 44th international conference on distributed computing systems (ICDCS). pp. 680–691. IEEE (2024)
2024
-
[29]
In: Proceedings of the 10th ACM workshop on artificial intelligence and security
Muñoz-González, L., Biggio, B., Demontis, A., Paudice, A., Wongrassamee, V., Lupu, E.C., Roli, F.: Towards poisoning of deep learning algorithms with back-gradient optimization. In: Proceedings of the 10th ACM workshop on artificial intelligence and security. pp. 27–38 (2017)
2017
-
[30]
arXiv preprint arXiv:1909.05125 (2019)
Muñoz-González, L., Co, K.T., Lupu, E.C.: Byzantine-robust federated machine learning through adaptive model aver- aging. arXiv preprint arXiv:1909.05125 (2019)
-
[31]
In: 29th USENIX Security Symposium (USENIX Security 20)
Pan, X., Zhang, M., Wu, D., Xiao, Q., Ji, S., Yang, Z.: Justinian’s{GAAvernor}: Robust distributed learning with gradient aggregation agent. In: 29th USENIX Security Symposium (USENIX Security 20). pp. 1641–1658 (2020)
2020
-
[32]
Advances in neural information processing systems34, 840–851 (2021)
Park, J., Han, D.J., Choi, M., Moon, J.: Sageflow: Robust federated learning against both stragglers and adversaries. Advances in neural information processing systems34, 840–851 (2021)
2021
-
[33]
IEEE Internet of Things Journal 11(5), 7374–7398 (2023)
Rauniyar, A., Hagos, D.H., Jha, D., Håkegård, J.E., Bagci, U., Rawat, D.B., Vlassov, V.: Federated learning for medical applications: A taxonomy, current trends, challenges, and future research directions. IEEE Internet of Things Journal 11(5), 7374–7398 (2023)
2023
-
[34]
In: NDSS (2021)
Shejwalkar, V., Houmansadr, A.: Manipulating the byzantine: Optimizing model poisoning attacks and defenses for federated learning. In: NDSS (2021)
2021
-
[35]
In: European symposium on research in computer security
Tolpegin, V., Truex, S., Gursoy, M.E., Liu, L.: Data poisoning attacks against federated learning systems. In: European symposium on research in computer security. pp. 480–501. Springer (2020)
2020
-
[36]
In: Proceedings of the 2022 ACM on Asia conference on computer and communications security
Wang, N., Xiao, Y., Chen, Y., Hu, Y., Lou, W., Hou, Y.T.: Flare: defending federated learning against model poison- ing attacks via latent space representations. In: Proceedings of the 2022 ACM on Asia conference on computer and communications security. pp. 946–958 (2022)
2022
-
[37]
Webank: Utilization of fate in risk management of credit in small and micro enterprises (2020) 18 Tang et al
2020
-
[38]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, X., Gao, S., Zhang, Z., Li, Z., Bao, R., Zhang, Y., Wang, X., Huang, H.: Auto-train-once: Controller network guided automatic network pruning from scratch. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 16163–16173 (2024)
2024
-
[39]
Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms
Xiao, H., Rasul, K., Vollgraf, R.: Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms. arXiv preprint arXiv:1708.07747 (2017)
work page internal anchor Pith review arXiv 2017
-
[40]
Xiao, X., Tang, Z., Li, C., Xiao, B., Li, K.: Sca: Sybil-based collusion attacks of iiot data poisoning in federated learning. IEEE Transactions on Industrial Informatics19(3), 2608–2618 (2023).https://doi.org/10.1109/TII.2022.3172310
-
[41]
In: International conference on machine learning
Xie, C., Koyejo, S., Gupta, I.: Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance. In: International conference on machine learning. pp. 6893–6901. PMLR (2019)
2019
-
[42]
In: International conference on machine learning
Xie, C., Koyejo, S., Gupta, I.: Zeno++: Robust fully asynchronous sgd. In: International conference on machine learning. pp. 10495–10503. PMLR (2020)
2020
-
[43]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xie, L., Luan, T., Cai, W., Yan, G., Chen, Z., Xi, N., Fang, Y., Shen, Q., Wu, Z., Yuan, J.: dflmoe: Decentralized federated learning via mixture of experts for medical data analysis. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 10203–10213 (2025)
2025
-
[44]
In: International conference on machine learning
Yin, D., Chen, Y., Kannan, R., Bartlett, P.: Byzantine-robust distributed learning: Towards optimal statistical rates. In: International conference on machine learning. pp. 5650–5659. PMLR (2018)
2018
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhang, R., Xu, Q., Yao, J., Zhang, Y., Tian, Q., Wang, Y.: Federated domain generalization with generalization ad- justment. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3954–3963 (2023)
2023
-
[46]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Zhao, J.C., Elkordy, A.R., Sharma, A., Ezzeldin, Y.H., Avestimehr, S., Bagchi, S.: The resource problem of using linear layer leakage attack in federated learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3974–3983 (2023)
2023
-
[47]
Zhou, J., Hu, J., Xue, J., Zeng, S.: Secure fair aggregation based on category grouping in federated learning. Information Fusion117, 102838 (2025) 8 Appendix 8.1 Detailed Proof of Theorem 1 In this section, we provide a detailed proof of Theorem 1. Proof.Hereg i t = 1 b Pb j=1 ∇f i(θt−1;ξ i t−1,j)denotes the gradient ofi-th client in training roundt. As ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.