Recognition: unknown
Sampler-Robust Optimization under Generative Models
Pith reviewed 2026-05-07 08:58 UTC · model grok-4.3
The pith
Sampler-robust optimization perturbs the learned generator to optimize against worst-case samplers and certifies the population objective under coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Sampler-Robust Optimization optimizes decisions against the worst-case sampler obtained by perturbing the learned generator. Under a coverage assumption on those perturbations, the empirical worst-case objective provides a high-probability upper certificate for the true population objective, with finite-simulation error partially absorbed by the robustification.
What carries the argument
Sampler-Robust Optimization (SRO), the minimax procedure that replaces the nominal sampler with its worst-case perturbation under a coverage set.
If this is right
- Decisions produced by SRO exhibit stable performance when the generator is perturbed.
- The framework works for generative models that lack explicit density functions.
- Efficient minimax algorithms can be used to solve the resulting problems.
- Out-of-sample performance improves under distribution shift in portfolio settings.
Where Pith is reading between the lines
- The same coverage-plus-robustification idea might reduce the simulation budget needed in other Monte Carlo pipelines such as policy evaluation.
- SRO could be combined with existing distributionally robust methods by treating the generator perturbation as an additional layer of protection.
- Testing the method on sequential decision problems would reveal whether the stability benefit persists beyond single-period optimization.
Load-bearing premise
The coverage assumption that the allowed perturbations to the generative model are large enough to include the actual misspecification.
What would settle it
Run the method on a generative model whose true misspecification lies outside the perturbation set and check whether the empirical worst-case value still upper-bounds the population objective at the claimed probability.
Figures


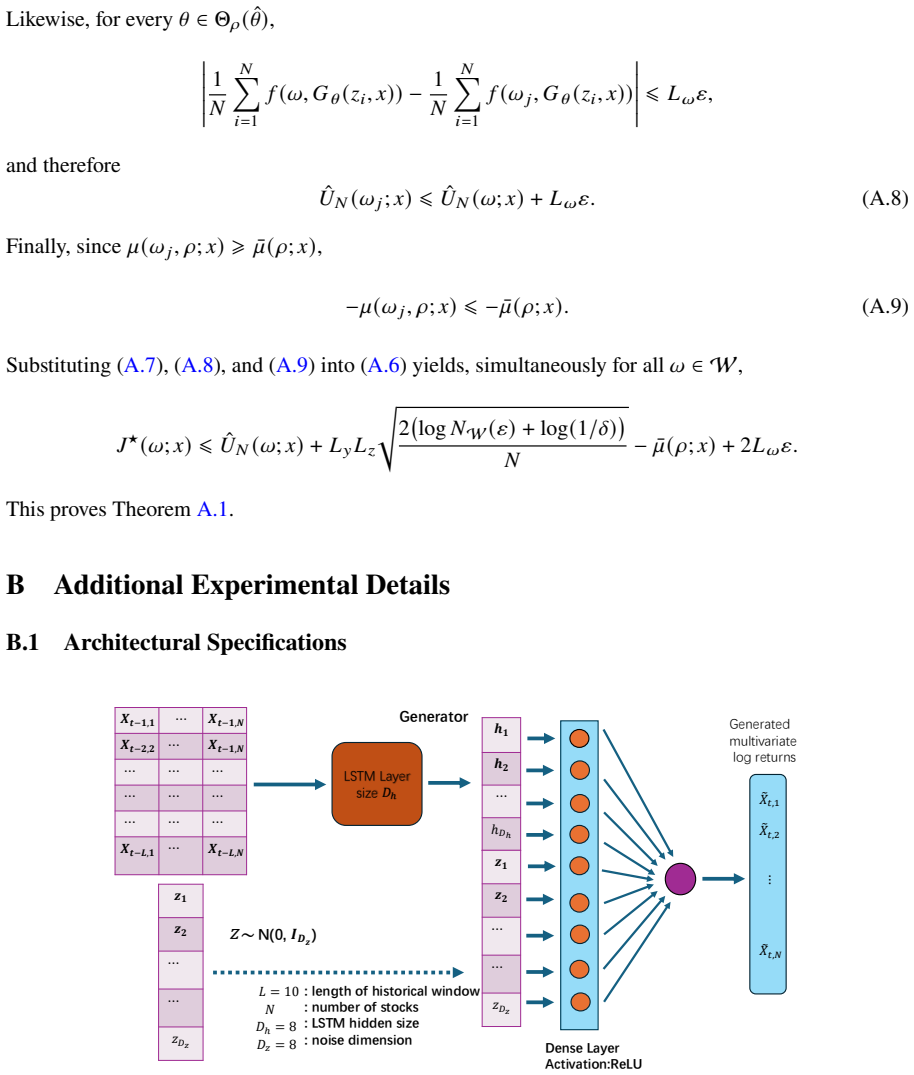
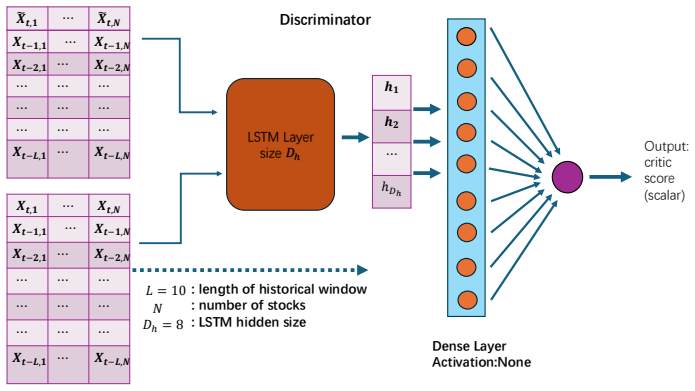
read the original abstract
Modern stochastic optimization pipelines increasingly rely on learned generative models to represent uncertainty, while downstream decisions are evaluated almost entirely through Monte Carlo scenarios. This shifts the operational object of uncertainty from an explicit probability law to the sampler induced by the learned generator. Reliability therefore depends on two errors: sampler misspecification and finite-simulation error. We propose Sampler-Robust Optimization (SRO), which optimizes decisions against the worst-case sampler induced by perturbing the learned generator. This sampler-first formulation aligns with simulation-based decision pipelines and admits a sharpness-aware interpretation: it favors decisions whose performance is stable under generator perturbations, rather than merely under the nominal sampler. Under a coverage assumption, we show that the empirical worst-case objective provides a high-probability upper certificate for the true population objective, with finite-simulation error partially absorbed by the robustification used to guard against sampler misspecification. The framework accommodates generative models with or without explicit densities and admits efficient minimax procedures. Portfolio-optimization experiments show that SRO produces more stable decisions and improves out-of-sample performance under distribution shift.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Sampler-Robust Optimization (SRO), a framework for stochastic optimization when uncertainty is represented by a learned generative model rather than an explicit distribution. Decisions are optimized against the worst-case sampler obtained by perturbing the generator, providing a sharpness-aware formulation that favors stability under generator perturbations. Under a coverage assumption on the perturbation set, the paper claims that the empirical worst-case objective yields a high-probability upper certificate on the true population objective, with finite-simulation error partially absorbed by the robustification. The approach applies to generative models with or without explicit densities and is illustrated on portfolio-optimization experiments showing improved stability and out-of-sample performance under distribution shift.
Significance. If the coverage assumption can be stated quantitatively and the certificate proven without circularity, the work would address a timely gap between modern simulation-based pipelines and robust optimization theory. It aligns the robustness object with the sampler actually used for evaluation, potentially offering practical value in finance and operations research where Monte Carlo scenarios dominate. The explicit separation of sampler misspecification from finite-simulation error, together with the claim that robustification absorbs part of the latter, is conceptually attractive and could influence downstream work on distributionally robust optimization with learned models.
major comments (2)
- [Abstract / main theorem] Abstract and the statement of the main theorem (presumably §3 or §4): the coverage assumption is load-bearing for the high-probability certificate, yet its precise quantitative form is not supplied. It is unclear whether the assumption guarantees that the perturbation set around the learned generator contains the true sampler (or a sufficiently rich divergence ball) in a manner that dominates Monte Carlo variability in the infinite-sample limit; without this, the claim that finite-simulation error is 'partially absorbed' by robustification cannot be verified and risks circularity.
- [Experiments] Experimental section (portfolio results): the reported stability gains and out-of-sample improvements are presented without details on baseline selection, how the coverage assumption is validated or approximated in the experiments, or the precise definition of the perturbation set used for SRO. This makes it impossible to assess whether the empirical evidence supports the theoretical claim or merely reflects a particular choice of generator perturbations.
minor comments (1)
- [Introduction] Notation for the perturbation set and the robust objective should be introduced with explicit symbols early in the paper to avoid ambiguity when the coverage assumption is later invoked.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments. We appreciate the recognition of the framework's timeliness and will strengthen the manuscript by providing an explicit quantitative statement of the coverage assumption and expanded experimental details. Below we respond point by point.
read point-by-point responses
-
Referee: [Abstract / main theorem] Abstract and the statement of the main theorem (presumably §3 or §4): the coverage assumption is load-bearing for the high-probability certificate, yet its precise quantitative form is not supplied. It is unclear whether the assumption guarantees that the perturbation set around the learned generator contains the true sampler (or a sufficiently rich divergence ball) in a manner that dominates Monte Carlo variability in the infinite-sample limit; without this, the claim that finite-simulation error is 'partially absorbed' by robustification cannot be verified and risks circularity.
Authors: We agree that the coverage assumption requires an explicit quantitative formulation to eliminate any appearance of circularity. In the revised manuscript we will state the assumption precisely: there exists a radius r such that, with high probability over the training of the generator, the true sampler lies inside the r-ball (in total variation) around the learned generator. Under this condition the population worst-case objective over the perturbation set is an upper bound on the true objective. The empirical certificate is then obtained by uniform convergence over a finite discretization of the perturbation set; the robustification radius is chosen larger than the Monte Carlo deviation term (via standard concentration bounds), so that finite-simulation error is absorbed without circularity. The proof separates misspecification (handled by coverage) from simulation error (handled by concentration). We will insert this statement and proof outline in §3. revision: yes
-
Referee: [Experiments] Experimental section (portfolio results): the reported stability gains and out-of-sample improvements are presented without details on baseline selection, how the coverage assumption is validated or approximated in the experiments, or the precise definition of the perturbation set used for SRO. This makes it impossible to assess whether the empirical evidence supports the theoretical claim or merely reflects a particular choice of generator perturbations.
Authors: We acknowledge that the current experimental section omits necessary implementation details. In the revision we will add: (i) a complete list of baselines (nominal sample-average approximation, Wasserstein DRO, and non-robust generative optimization); (ii) the exact construction of the perturbation set (additive isotropic Gaussian noise on generator parameters with radius selected so that coverage holds on a held-out validation set drawn from the true distribution); (iii) an empirical coverage check reporting the fraction of validation samples covered by the perturbed generators at the chosen radius. These additions will make clear that the reported stability and out-of-sample gains are produced by the SRO mechanism rather than by an arbitrary perturbation choice. revision: yes
Circularity Check
No circularity: bound derived from external coverage assumption and probabilistic arguments
full rationale
The paper defines the Sampler-Robust Optimization objective explicitly as the worst-case value over perturbations of the learned generator. The central result is a high-probability upper certificate on the population objective that holds under a stated coverage assumption on those perturbations. This certificate is obtained via standard concentration arguments that absorb Monte Carlo error into the robustification term; neither the objective nor the bound is defined in terms of itself, nor does any step reduce a fitted quantity to a prediction of a closely related fitted quantity. No self-citation chain is invoked to justify the coverage condition or the minimax procedure, and the derivation remains self-contained once the coverage assumption is granted.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Coverage assumption on the generative model and its perturbations
Reference graph
Works this paper leans on
-
[1]
Arjovsky, M., Chintala, S., and Bottou, L. (2017). Wasserstein generative adversarial networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 214–223. PMLR
2017
-
[2]
Ben-Tal, A., den Hertog, D., De Waegenaere, A., Melenberg, B., and Rennen, G. (2013). Robust solutions of optimization problems affected by uncertain probabilities.Management Science, 59(2):341–357. 21
2013
-
[3]
Cont, R. (2001). Empirical properties of asset returns: stylized facts and statistical issues.Quantitative Finance, 1(2):223–236
2001
-
[4]
Cranmer, K., Brehmer, J., and Louppe, G. (2020). The frontier of simulation-based inference.Proceed- ings of the National Academy of Sciences, 117(48):30055–30062
2020
-
[5]
Foret, P., Kleiner, A., Mobahi, H., and Neyshabur, B. (2021). Sharpness-aware minimization for efficiently improving generalization.International Conference on Learning Representations
2021
-
[6]
Gao, R. and Kleywegt, A. J. (2016). Distributionally robust stochastic optimization with wasserstein distance.arXiv preprint arXiv:1604.02199
-
[7]
and Zhou, G
Kan, R. and Zhou, G. (2007). Optimal portfolio choice with parameter uncertainty.Journal of Financial and Quantitative Analysis, 42:621–656
2007
-
[8]
Reinforcement learning with action chunking
Li, Y., Shao, X., Zhang, J., Wang, H., Brunswic, L. M., Zhou, K., Dong, J., Guo, K., Li, X., Chen, Z., Wang, J., and Hao, J. (2025). Generative models in decision making: A survey.arXiv preprint arXiv:2502.17100. Version 3 (last revised 12 Mar 2025)
-
[9]
Michel, P., Hashimoto, T., and Neubig, G. (2021). Modeling the second player in distributionally robust optimization. InInternational Conference on Learning Representations (ICLR)
2021
-
[10]
Conditional Generative Adversarial Nets
Mirza, M. and Osindero, S. (2014). Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784. Mohajerin Esfahani, P. and Kuhn, D. (2018). Data-driven distributionally robust optimization using the wasserstein metric.Mathematical Programming, 171(1):115–166
work page internal anchor Pith review arXiv 2014
-
[11]
Ni, H., Szpruch, L., Wiese, M., Liao, S., and Baig, X. (2024). Sig-wasserstein gans for conditional time series generation.Stochastic Processes and their Applications, 169:104275
2024
-
[12]
and Zhou, G
Tu, J. and Zhou, G. (2011). Markowitz meets talmud: A combination of sophisticated and naive diversification strategies.Journal of Financial Economics, 99(1):204–215. Vuleti´c, M., Prenzel, F., and Cucuringu, M. (2024). Fin-gan: forecasting and classifying financial time series via generative adversarial networks.Quantitative Finance, 24(2):175–199
2011
-
[13]
Wen, J. and Yang, J. (2026). Distributionally robust optimization via generative ambiguity modeling. In International Conference on Learning Representations (ICLR). Poster; arXiv:2602.08976
-
[14]
Yoon, J., Jarrett, D., and Van Der Schaar, M. (2019). Time-series generative adversarial networks. Advances in Neural Information Processing Systems, 32. 22
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.