Recognition: unknown
RAY-TOLD: Ray-Based Latent Dynamics for Dense Dynamic Obstacle Avoidance with TDMPC
Pith reviewed 2026-05-07 08:37 UTC · model grok-4.3
The pith
A hybrid planner encodes LiDAR data into latent dynamics to mix learned long-horizon intent with short-horizon physics rollouts and cut collisions in dense crowds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
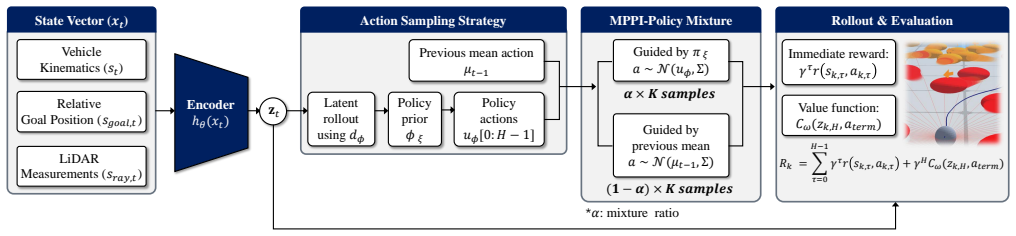
RAY-TOLD builds a LiDAR-centric latent dynamics model that compresses high-dimensional sensor input into a low-dimensional state, then trains a terminal value function and policy prior on this representation. A policy mixture sampling step inserts trajectories generated by the learned policy into the MPPI population, allowing short-horizon physics-based rollouts to be steered by longer-horizon learned intent while preserving kinematic constraints.
What carries the argument
The policy mixture sampling strategy inside RAY-TOLD, which augments MPPI candidates with trajectories from a latent-dynamics-trained policy prior to blend short-horizon physics feasibility with long-horizon goal guidance.
If this is right
- Collision rates fall compared with pure MPPI in environments filled with many moving obstacles.
- The planner escapes local minima more often because policy-derived trajectories supply long-horizon direction.
- Kinematic feasibility is retained because all sampled trajectories still obey the vehicle model used inside MPPI.
- Navigation reliability improves in stochastic crowd settings where purely reactive methods stall.
Where Pith is reading between the lines
- The same latent-dynamics-plus-mixture pattern could be tested with other short-horizon planners besides MPPI.
- If sim-to-real gaps prove small, the method may support deployment on platforms with limited onboard compute.
- Extending the latent model to incorporate additional sensor streams could further tighten the coupling between perception and planning.
Load-bearing premise
That the latent dynamics, terminal value function, and policy prior trained in simulation will transfer to real-world high-density dynamic obstacle settings without creating new failure modes or exceeding real-time compute limits.
What would settle it
Running the same high-density stochastic obstacle test suite on physical hardware and measuring whether collision rate drops below the MPPI baseline while control frequency stays above the required threshold.
Figures



read the original abstract
Dense, dynamic crowds pose a persistent challenge for autonomous mobile robots. Purely reactive planning methods, such as Model Predictive Path Integral (MPPI) control, often fail to escape local minima in complex scenarios due to their limited prediction horizon. To bridge this gap, we propose Ray-based Task-Oriented Latent Dynamics (RAY-TOLD), a hybrid control architecture that integrates obstacle information into latent dynamics and utilizes the robustness of physics-based MPPI with the long-horizon foresight of reinforcement learning. RAY-TOLD leverages a LiDAR-centric latent dynamics model to encode high-dimensional sensor data into a compact state representation, enabling the learning of a terminal value function and a policy prior. We introduce a policy mixture sampling strategy that augments the MPPI candidate population with trajectories derived from the learned policy, effectively guiding the planner towards the goal while maintaining kinematic feasibility. Extensive tests in a stochastic environment with high-density dynamic obstacles demonstrate that our method outperforms the MPPI baseline, reducing the collision rate. The results confirm that blending short-horizon physics-based rollouts with learned long-horizon intent significantly enhances navigation reliability and safety.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes RAY-TOLD, a hybrid architecture that augments Model Predictive Path Integral (MPPI) control with a policy prior and terminal value function learned from a LiDAR-centric latent dynamics model. The central claim is that policy mixture sampling, which blends short-horizon physics-based rollouts with long-horizon learned intent, reduces collision rates relative to pure MPPI in stochastic environments containing high-density dynamic obstacles.
Significance. If the quantitative claims are substantiated, the hybrid approach could meaningfully extend the reliable operating envelope of reactive planners in crowded settings by supplying goal-directed guidance without sacrificing kinematic feasibility. The explicit use of ray-based latent encoding for high-dimensional sensor data is a concrete technical contribution that may generalize to other sensor modalities.
major comments (3)
- [Abstract / Results] Abstract and Results section: the claim that the method 'outperforms the MPPI baseline, reducing the collision rate' is presented without any numerical values (collision rates, success rates, mean/variance, or p-values), without specification of the MPPI baseline parameters, environment dimensions, obstacle density, or number of trials. This absence prevents assessment of whether the reported improvement is statistically or practically meaningful.
- [Experimental Evaluation] §4 (or equivalent experimental section): the description of the 'stochastic environment' provides no details on domain randomization, sensor noise models, or real-robot validation. Because the latent dynamics, terminal value function, and policy prior are trained in simulation, the absence of transfer metrics or failure-mode analysis directly undermines the central claim that the hybrid controller enhances safety in high-density dynamic settings.
- [Method / Policy Mixture Sampling] Policy mixture sampling description (likely §3.3): the method assumes that trajectories sampled from the learned policy can be safely mixed with MPPI rollouts while preserving kinematic feasibility, yet no explicit projection, constraint, or feasibility check is stated. Any distribution shift in real LiDAR returns would invalidate this assumption without additional safeguards.
minor comments (2)
- [Title / Abstract] The title contains the acronym TDMPC, which is never expanded or referenced in the abstract or early sections; a brief parenthetical definition would improve readability.
- [Figures] Figure captions and axis labels in the experimental plots (if present) should explicitly state the number of Monte-Carlo trials and the exact MPPI baseline configuration used for comparison.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract / Results] Abstract and Results section: the claim that the method 'outperforms the MPPI baseline, reducing the collision rate' is presented without any numerical values (collision rates, success rates, mean/variance, or p-values), without specification of the MPPI baseline parameters, environment dimensions, obstacle density, or number of trials. This absence prevents assessment of whether the reported improvement is statistically or practically meaningful.
Authors: We agree that the abstract and results lack the quantitative specificity needed for proper evaluation. In the revised manuscript we will report concrete collision rates (with means and standard deviations), success rates, and the number of trials performed. We will also specify the MPPI baseline parameters, environment dimensions, obstacle densities, and include statistical comparisons where the data support them. revision: yes
-
Referee: [Experimental Evaluation] §4 (or equivalent experimental section): the description of the 'stochastic environment' provides no details on domain randomization, sensor noise models, or real-robot validation. Because the latent dynamics, terminal value function, and policy prior are trained in simulation, the absence of transfer metrics or failure-mode analysis directly undermines the central claim that the hybrid controller enhances safety in high-density dynamic settings.
Authors: We will expand the experimental section to detail the domain randomization procedures and sensor noise models used during training and evaluation. We will also add a failure-mode analysis. Real-robot validation and sim-to-real transfer metrics are not part of the present study, which focuses on controlled simulation; we will explicitly acknowledge this scope limitation and discuss implications for deployment. revision: partial
-
Referee: [Method / Policy Mixture Sampling] Policy mixture sampling description (likely §3.3): the method assumes that trajectories sampled from the learned policy can be safely mixed with MPPI rollouts while preserving kinematic feasibility, yet no explicit projection, constraint, or feasibility check is stated. Any distribution shift in real LiDAR returns would invalidate this assumption without additional safeguards.
Authors: The learned policy is trained under the same kinematic constraints as the MPPI dynamics model, and mixture sampling selects controls that remain within the feasible action set. We acknowledge that the current description does not explicitly state the projection or feasibility enforcement step. In the revision we will add a precise description of how kinematic feasibility is maintained during mixture sampling and note any safeguards against distribution shift. revision: yes
Circularity Check
No circularity: hybrid architecture and empirical results are independent of inputs
full rationale
The paper proposes RAY-TOLD as an architectural combination of LiDAR-centric latent dynamics, a learned terminal value function, policy prior, and MPPI with policy mixture sampling. The central performance claim (reduced collision rate versus MPPI baseline) rests on extensive tests in a stochastic high-density obstacle environment, which is presented as an external empirical benchmark rather than a quantity derived from the same fitted parameters or self-referential definitions. No equations, self-citations, uniqueness theorems, or ansatzes are invoked in the abstract or described claims that would reduce the result to its own inputs by construction. The derivation chain is self-contained against the reported simulation benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- policy mixture ratio
axioms (2)
- domain assumption High-dimensional LiDAR observations can be compressed into a compact latent state that supports accurate short-term dynamics prediction and long-horizon value estimation
- domain assumption Trajectories sampled from the learned policy remain kinematically feasible and can be safely mixed with physics-based MPPI rollouts
invented entities (1)
-
RAY-TOLD hybrid control architecture
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Dr-mpc: Deep residual model predictive control for real-world social navigation,
J. R. Han, H. Thomas, J. Zhang, N. Rhinehart, and T. D. Barfoot, “Dr-mpc: Deep residual model predictive control for real-world social navigation,”IEEE Robotics and Automation Letters, 2025
2025
-
[2]
Td-cd-mppi: Temporal-difference constraint-discounted model predictive path integral control,
P. N. Crestaz, L. De Matteis, E. Chane-Sane, N. Mansard, and A. Del Prete, “Td-cd-mppi: Temporal-difference constraint-discounted model predictive path integral control,”IEEE Robotics and Automation Letters, vol. 11, no. 1, pp. 498–505, 2025
2025
-
[3]
Collision-free robot navigation in crowded environments using learning based convex model predictive control,
Z. Wen, M. Dong, and X. Chen, “Collision-free robot navigation in crowded environments using learning based convex model predictive control,” in2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2024, pp. 5452–5459
2024
-
[4]
Fast superquadric potential function for collision avoidance of autonomous vehicle,
S. Han, S. Yang, and M. Choi, “Fast superquadric potential function for collision avoidance of autonomous vehicle,”IEEE Access, vol. 14, pp. 6635–6646, 2026
2026
-
[5]
Mpc-inspired reinforcement learning for verifiable model-free control,
Y . Lu, Z. Li, Y . Zhou, N. Li, and Y . Mo, “Mpc-inspired reinforcement learning for verifiable model-free control,” in6th Annual Learning for Dynamics & Control Conference. PMLR, 2024, pp. 399–413
2024
-
[6]
Dreamernav: Learning-based autonomous navigation in dynamic indoor environments using world models,
S. Shanks, J. Embley-Riches, J. Liu, A. M. Delfaki, C. Ciliberto, and D. Kanoulas, “Dreamernav: Learning-based autonomous navigation in dynamic indoor environments using world models,”Frontiers in Robotics and AI, vol. 12, p. 1655171, 2025
2025
-
[7]
iqrl–implicitly quantized representations for sample- efficient reinforcement learning,
A. Scannell, K. Kujanp ¨a¨a, Y . Zhao, M. Nakhaei, A. Solin, and J. Pajarinen, “iqrl–implicitly quantized representations for sample- efficient reinforcement learning,”arXiv preprint arXiv:2406.02696, 2024
-
[8]
Actor–critic model predictive control: Differentiable optimization meets reinforce- ment learning for agile flight,
A. Romero, E. Aljalbout, Y . Song, and D. Scaramuzza, “Actor–critic model predictive control: Differentiable optimization meets reinforce- ment learning for agile flight,”IEEE Transactions on Robotics, vol. 42, pp. 673–692, 2025
2025
-
[9]
Temporal difference learning for model predictive control.arXiv preprint arXiv:2203.04955,
N. Hansen, X. Wang, and H. Su, “Temporal difference learning for model predictive control,”arXiv preprint arXiv:2203.04955, 2022
-
[10]
TD-MPC2: Scalable, Robust World Models for Continuous Control
N. Hansen, H. Su, and X. Wang, “Td-mpc2: Scalable, robust world models for continuous control,”arXiv preprint arXiv:2310.16828, 2023
work page internal anchor Pith review arXiv 2023
-
[11]
Prm-rl: Long-range robotic navigation tasks by combining reinforcement learning and sampling-based planning,
A. Faust, K. Oslund, O. Ramirez, A. Francis, L. Tapia, M. Fiser, and J. Davidson, “Prm-rl: Long-range robotic navigation tasks by combining reinforcement learning and sampling-based planning,” in 2018 IEEE international conference on robotics and automation (ICRA). IEEE, 2018, pp. 5113–5120
2018
-
[12]
Learned perceptive for- ward dynamics model for safe and platform-aware robotic navigation,
P. Roth, J. Frey, C. Cadena, and M. Hutter, “Learned perceptive for- ward dynamics model for safe and platform-aware robotic navigation,” arXiv preprint arXiv:2504.19322, 2025
-
[13]
Toward scalable multirobot control: Fast policy learning in distributed mpc,
X. Zhang, W. Pan, C. Li, X. Xu, X. Wang, R. Zhang, and D. Hu, “Toward scalable multirobot control: Fast policy learning in distributed mpc,”IEEE Transactions on Robotics, vol. 41, pp. 1491–1512, 2025
2025
-
[14]
Infusing model predictive control into meta-reinforcement learning for mobile robots in dynamic environments,
J. Shin, A. Hakobyan, M. Park, Y . Kim, G. Kim, and I. Yang, “Infusing model predictive control into meta-reinforcement learning for mobile robots in dynamic environments,”IEEE Robotics and Automation Letters, vol. 7, no. 4, pp. 10 065–10 072, 2022
2022
-
[15]
D. Ha and J. Schmidhuber, “World models,”arXiv preprint arXiv:1803.10122, 2018
work page internal anchor Pith review arXiv 2018
-
[16]
Integrating driving- aware world model with mpc for autonomous driving at unsignalized t-intersections,
X. Zhang, Z. Wu, H. Hu, J. Yang, and P. Wang, “Integrating driving- aware world model with mpc for autonomous driving at unsignalized t-intersections,”IEEE Transactions on Intelligent Transportation Sys- tems, 2025
2025
-
[17]
Learning model predictive controllers with real-time attention for real-world navigation,
X. Xiao, T. Zhang, K. Choromanski, E. Lee, A. Francis, J. Varley, S. Tu, S. Singh, P. Xu, F. Xiaet al., “Learning model predictive controllers with real-time attention for real-world navigation,”arXiv preprint arXiv:2209.10780, 2022
-
[18]
Diffusion model predictive control,
G. Zhou, S. Swaminathan, R. V . Raju, J. S. Guntupalli, W. Lehrach, J. Ortiz, A. Dedieu, M. L ´azaro-Gredilla, and K. Murphy, “Diffusion model predictive control,”arXiv preprint arXiv:2410.05364, 2024
-
[19]
Td-m(pc) 2: Improving temporal difference mpc through policy constraint,
H. Lin, P. Wang, J. Schneider, and G. Shi, “Td-m(pc) 2: Improving temporal difference mpc through policy constraint,”arXiv preprint arXiv:2502.03550, 2025
-
[20]
Iql-td-mpc: Implicit q-learning for hierarchical model predictive control,
R. Chitnis, Y . Xu, B. Hashemi, L. Lehnert, U. Dogan, Z. Zhu, and O. Delalleau, “Iql-td-mpc: Implicit q-learning for hierarchical model predictive control,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 9154–9160
2024
-
[21]
Qt-tdm: Planning with transformer dynamics model and autoregressive q-learning,
M. Kotb, C. Weber, M. B. Hafez, and S. Wermter, “Qt-tdm: Planning with transformer dynamics model and autoregressive q-learning,” IEEE Robotics and Automation Letters, vol. 10, no. 1, pp. 112–119, 2024
2024
-
[22]
Sombrl: Scalable and optimistic model-based rl,
B. Sukhija, L. Treven, C. Sferrazza, F. D ¨orfler, P. Abbeel, and A. Krause, “Sombrl: Scalable and optimistic model-based rl,”arXiv preprint arXiv:2511.20066, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.