RoadMapper: A Multi-Agent System for Roadmap Generation of Solving Complex Research Problems
Pith reviewed 2026-05-07 05:32 UTC · model grok-4.3
The pith
RoadMapper is a multi-agent LLM system that generates higher-quality roadmaps for complex research problems by adding knowledge augmentation and iterative critique.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
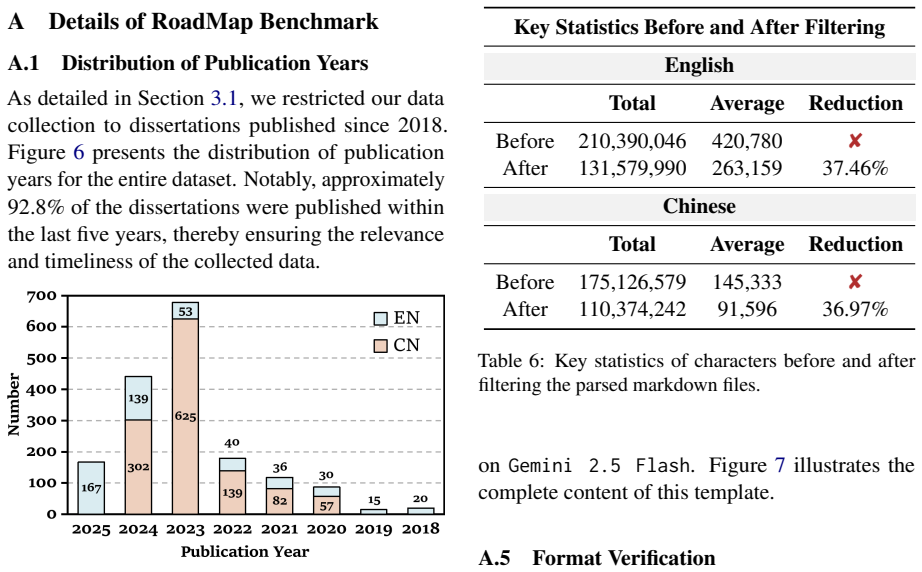
RoadMapper is an LLM-based multi-agent system that decomposes roadmap generation into initial generation, knowledge augmentation, and iterative critique-revise-evaluate stages. On the RoadMap benchmark it raises average performance more than eight percent above single-model baselines and reduces the time required by human experts by eighty-four percent.
What carries the argument
RoadMapper, a multi-agent framework that decomposes roadmap generation into initial generation, knowledge augmentation, and iterative critique-revise-evaluate stages.
If this is right
- Single LLMs can be upgraded to produce more usable research plans without full retraining.
- The three-stage pipeline reduces the need for human experts to supply initial structure and domain facts.
- Iterative critique loops can be reused for other hierarchical planning tasks such as project scheduling.
- Knowledge augmentation from external sources becomes a standard fix for LLM knowledge gaps in structured output.
Where Pith is reading between the lines
- If the benchmark problems are representative, similar multi-agent patterns could shorten the planning phase of many AI-assisted research pipelines.
- Adding live search or database lookup inside the knowledge-augmentation stage would likely raise performance further on current topics.
- The same critique-revise loop might transfer to domains outside research, such as policy design or engineering project roadmaps.
Load-bearing premise
The RoadMap benchmark tasks and scoring criteria accurately capture the quality and real-world usefulness of roadmaps for complex research problems.
What would settle it
Running RoadMapper on a fresh collection of research problems outside the RoadMap benchmark and measuring both roadmap quality and expert time savings against the same human baselines.
Figures











read the original abstract
People commonly leverage structured content to accelerate knowledge acquisition and research problem solving. Among these, roadmaps guide researchers through hierarchical subtasks to solve complex research problems step by step. Despite progress in structured content generation, the roadmap generation task has remained unexplored. To bridge this gap, we introduce RoadMap, a novel benchmark designed to evaluate the ability of large language models (LLMs) to construct high-quality roadmaps for solving complex research problems. Based on this, we identify three limitations of LLMs: (1) lack of professional knowledge, (2) unreasonable task decomposition, and (3) disordered logical relationships. To address these challenges, we propose RoadMapper, an LLM-based multi-agent system that decomposes the research roadmap generation task into three key stages (i.e., initial generation, knowledge augmentation, and iterative "critique-revise-evaluate"). Extensive experiments demonstrate that RoadMapper can improve LLMs' ability for roadmap generation, while enhancing average performance by more than 8% and saving 84% of the time required by human experts, highlighting its effectiveness and application potential.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the RoadMap benchmark to evaluate LLMs on generating hierarchical roadmaps for complex research problems and proposes RoadMapper, a multi-agent system that decomposes the task into initial generation, knowledge augmentation, and iterative critique-revise-evaluate stages. It identifies three LLM limitations (lack of professional knowledge, unreasonable decomposition, disordered logic) and claims that RoadMapper improves average LLM performance by more than 8% while saving 84% of the time required by human experts.
Significance. If the evaluation protocol proves robust, the work could advance AI-assisted research planning by providing a structured multi-agent framework for roadmap generation and a dedicated benchmark in an underexplored area. The introduction of a benchmark and the explicit targeting of LLM weaknesses via critique-revise cycles are constructive contributions; the reported time savings, if independently verifiable, would have clear practical value for researchers.
major comments (3)
- [Experimental evaluation / Results] The abstract and evaluation sections claim >8% average performance gains and 84% human time savings, but provide no details on experimental design: number of problems/domains tested, exact scoring rubric for roadmap quality (completeness, coherence, usefulness), inter-annotator agreement, statistical significance tests, or how human expert time was measured and compared. These omissions make it impossible to assess whether the gains are reliable or generalizable.
- [RoadMap benchmark construction] RoadMap is a newly introduced benchmark created by the authors, creating a circularity risk where performance is measured against a self-defined standard. The manuscript must detail task curation criteria, validation against external or real-world outcomes, and whether tasks were selected post-hoc to favor the proposed knowledge-augmentation approach.
- [Baselines and ablation studies] Baseline comparisons are insufficiently specified: it is unclear which exact systems (vanilla GPT-4, other agent frameworks, or ablations of RoadMapper) were used, whether LLM-as-judge scoring was calibrated against human experts, and how the three-stage pipeline was ablated to isolate the contribution of each component.
minor comments (2)
- [Abstract] The abstract refers to 'extensive experiments' without any quantitative details or pointers to specific tables/figures; add a brief summary of key metrics and sample sizes.
- [Introduction / Benchmark] Clarify the precise definition of 'roadmap quality' early in the paper and ensure the scoring criteria are reproducible (e.g., provide the full rubric in an appendix).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. The comments identify important areas where the manuscript requires greater transparency and elaboration. We address each major comment point by point below and will incorporate the necessary clarifications and expansions in the revised version to improve verifiability and robustness.
read point-by-point responses
-
Referee: [Experimental evaluation / Results] The abstract and evaluation sections claim >8% average performance gains and 84% human time savings, but provide no details on experimental design: number of problems/domains tested, exact scoring rubric for roadmap quality (completeness, coherence, usefulness), inter-annotator agreement, statistical significance tests, or how human expert time was measured and compared. These omissions make it impossible to assess whether the gains are reliable or generalizable.
Authors: We acknowledge that the initial submission omitted critical details on the experimental protocol, making independent assessment difficult. We will revise the evaluation section to provide a complete description of the design, including the number of problems and domains tested, the precise scoring rubric (with explicit criteria and scales for completeness, coherence, and usefulness), inter-annotator agreement statistics, results of statistical significance testing, and the exact protocol used to measure and compare human expert time (including how scratch generation time versus review-and-edit time was recorded). These elements were part of our internal experimental process but were not fully documented in the original manuscript; the revision will rectify this. revision: yes
-
Referee: [RoadMap benchmark construction] RoadMap is a newly introduced benchmark created by the authors, creating a circularity risk where performance is measured against a self-defined standard. The manuscript must detail task curation criteria, validation against external or real-world outcomes, and whether tasks were selected post-hoc to favor the proposed knowledge-augmentation approach.
Authors: We share the concern regarding potential circularity and will add a dedicated subsection on benchmark construction. This will specify the task curation criteria (e.g., requirements for multi-stage complexity and domain coverage), the validation process against external or real-world outcomes (including expert review and alignment checks with published research trajectories), and explicit confirmation that the benchmark was finalized prior to any RoadMapper experiments, with no post-hoc filtering or selection of tasks to advantage the knowledge-augmentation component. We will also include representative examples and documentation of the curation workflow. revision: yes
-
Referee: [Baselines and ablation studies] Baseline comparisons are insufficiently specified: it is unclear which exact systems (vanilla GPT-4, other agent frameworks, or ablations of RoadMapper) were used, whether LLM-as-judge scoring was calibrated against human experts, and how the three-stage pipeline was ablated to isolate the contribution of each component.
Authors: We agree that the descriptions of baselines and ablations were insufficiently detailed. In the revision we will explicitly list all baseline systems (including vanilla GPT-4, chain-of-thought variants, and other agent frameworks), clarify that primary evaluation relies on human experts while also reporting LLM-as-judge results with calibration details against human annotations on a held-out subset, and present full ablation results that isolate the contribution of each stage in the three-stage pipeline (initial generation, knowledge augmentation, and critique-revise-evaluate). Quantitative performance drops for each ablation will be reported in tables. revision: yes
Circularity Check
No significant circularity; evaluation uses standard new-benchmark protocol without self-referential reduction.
full rationale
The paper introduces the RoadMap benchmark to evaluate LLM roadmap generation, identifies three LLM limitations from it, and proposes the RoadMapper multi-agent pipeline (initial generation, knowledge augmentation, critique-revise-evaluate) to address them. Performance claims (>8% average improvement, 84% human time savings) are empirical results measured on the new benchmark against baselines. No mathematical derivation chain, equations, or first-principles results exist that reduce to inputs by construction. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The benchmark and system are presented as novel contributions for an unexplored task; measuring system performance on an author-introduced benchmark is standard practice and does not equate the output to the input definitionally. The central claims remain independently falsifiable via the reported experimental protocol.
Axiom & Free-Parameter Ledger
free parameters (1)
- RoadMap benchmark scoring criteria
axioms (2)
- domain assumption LLMs exhibit the three specific limitations (lack of professional knowledge, unreasonable task decomposition, disordered logical relationships) in roadmap generation.
- ad hoc to paper Iterative critique-revise-evaluate cycles in a multi-agent setup can systematically overcome these limitations.
invented entities (2)
-
RoadMap benchmark
no independent evidence
-
RoadMapper multi-agent system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4762–4779, Flo- rence, Italy
COMET: Commonsense transformers for auto- matic knowledge graph construction. InProceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4762–4779, Flo- rence, Italy. Association for Computational Linguis- tics. Philip E Burian, Lynda Rogerson, and Francis R Maf- fei III. 2010. The research roadmap: A primer to the ap...
2010
-
[2]
Training verifiers to solve math word prob- lems.Preprint, arXiv:2110.14168. DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chen- hao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, and 245 others. 2025. Deepseek-v3.2: Pushin...
work page internal anchor Pith review arXiv 2025
-
[3]
A Dynamic LLM-Powered Agent Network for Task-Oriented Agent Collaboration
STRUCTSUM generation for faster text com- prehension. InProceedings of the 62nd Annual Meet- ing of the Association for Computational Linguis- tics (Volume 1: Long Papers), pages 7876–7896, Bangkok, Thailand. Association for Computational Linguistics. Bingxuan Li, Yiwei Wang, Jiuxiang Gu, Kai-Wei Chang, and Nanyun Peng. 2025a. METAL: A multi-agent framewo...
work page internal anchor Pith review arXiv 2023
-
[4]
gpt-oss-120b & gpt-oss-20b Model Card
TriageAgent: Towards better multi-agents col- laborations for large language model-based clinical triage. InFindings of the Association for Computa- tional Linguistics: EMNLP 2024, pages 5747–5764, Miami, Florida, USA. Association for Computational Linguistics. Yaojie Lu, Qing Liu, Dai Dai, Xinyan Xiao, Hongyu Lin, Xianpei Han, Le Sun, and Hua Wu. 2022. U...
work page internal anchor Pith review arXiv 2024
-
[5]
Extraction must be based strictly on the content of the provided paper
-
[6]
Extract at most five of the most innovative and valuable skill points
-
[7]
Extract the core research task of the entire paper
-
[8]
Answer in JSON format and follow the template provided below
-
[9]
Enclose the extracted results with```json```
-
[10]
core_research_question
Answer in English. Template: { "core_research_question": "" # The core research question in a concise question format like "How to ...?" (no more than 30 words). "skill_points": [ { "problem_description": "", # Describe the specific problem this skill point addresses. "skill_point_name": "", # Concise name of the skill point. "skill_point_description": ""...
-
[11]
Analyze the research problem and output several key skills that are essential for solving the problem
-
[12]
-`name`: The name of the skill point (brief description)
Output format requirements: - Use JSON list format for output, with each item being a skill point including name and description fields. -`name`: The name of the skill point (brief description). -`description`: The detailed explanation of the skill point (explains the role of the skill point in solving the problem). - Enclose the output in```json```
-
[13]
name": "xxx
The skills should be answered in {split_language}. Example output format: ```json [ {{"name": "xxx", "description": "xxx"}}, {{"name": "xxx", "description": "xxx"}}, ... ] ``` Figure 8: Prompt of theKagent for generation of internal knowledge. Prompt of theKAgent for Knowledge Augmentation You are an experienced research expert, specialized in optimizing ...
-
[14]
Carefully analyze each skill point in the skill point repository (each skill point includes its name and description) according to the research problem and the current roadmap
-
[15]
Determine which skill points are helpful for improving the roadmap, insert the names of helpful skill points as a step node into appropriate positions in the roadmap (names can be adapted to the problem as needed), and ignore unhelpful skill points
-
[16]
Ensure the correct format of the roadmap during insertion, maintaining the logical order and continuity of node indices
-
[17]
- Use different heading levels (#, ##, ###, etc.) to indicate the node level and the hierarchical structure of the roadmap
Roadmap format requirements, make sure to strictly follow: - Use Markdown format for output, with each line as a node (including level, index, and title, separated by spaces). - Use different heading levels (#, ##, ###, etc.) to indicate the node level and the hierarchical structure of the roadmap. - Use indices like 1.1.1 to indicate the node's position ...
-
[18]
Enclose the output in```markdown```
-
[19]
Example output format: ```markdown # 1 [Main Step] ## 1.1 [Sub-step] ## 1.2 [Sub-step] # 2 [Main Step] ## 2.1 [Sub-step] ### 2.1.1 [Sub-step] ### 2.1.2 [Sub-step]
The roadmap content should be answered in {split_language}. Example output format: ```markdown # 1 [Main Step] ## 1.1 [Sub-step] ## 1.2 [Sub-step] # 2 [Main Step] ## 2.1 [Sub-step] ### 2.1.1 [Sub-step] ### 2.1.2 [Sub-step] ... ``` Figure 9: Prompt of theKagent for knowledge augmentation. Prompt of theEAgent You are an experienced research expert, speciali...
-
[20]
Logic Structure: Evaluate the logical coherence of the roadmap, including whether the dependencies between nodes are reasonable, whether the step order is logical, and whether there are conflicts or contradictions between different parts
-
[21]
Granularity Degree: Evaluate the rationality of task decomposition granularity, including whether there are too macroscopic or too microscopic nodes, whether the sub-task division is balanced, etc
-
[22]
Topic Relevance: Evaluate the relevance of the roadmap to the input research problem, including whether the roadmap fully covers the core content required to solve the problem, whether there are redundant nodes unrelated to the topic, and whether the key technical points are fully reflected, etc
-
[23]
Based on the four dimensions above, provide an overall assessment using the following 100-point scale (percentage system, 0-100): 0-19: Very poor quality, cannot be used
Completeness: Evaluate the richness and completeness of the roadmap content, including whether there are missing key nodes or steps, and whether all the content required to solve the problem is fully covered. Based on the four dimensions above, provide an overall assessment using the following 100-point scale (percentage system, 0-100): 0-19: Very poor qu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.